

- ¿Qué es Qwen3-Next-80B-A3B: Conceptos básicos, puntos de referencia y aspectos destacados
- Cómo acceder a Qwen3-Next-80B-A3B: Despliegue local
- Cómo acceder a Qwen3-Next-80B-A3B: Instancia de GPU
- Cómo acceder a Qwen3-Next-80B-A3B: Acceso por API
- Cómo acceder a Qwen3-Next-80B-A3B: Integraciones de terceros
- Conclusión
Qwen3-Next-80B-A3B es un modelo de lenguaje grande recién lanzado que trae actualizaciones importantes a la serie Qwen3. Con mejoras significativas en arquitectura y eficiencia, sus capacidades en razonamiento, codificación y comprensión de contexto largo han avanzado rápidamente, posicionándolo como uno de los modelos más competitivos de su clase.
En este artículo, obtendrás una visión clara de lo que hace que Qwen3-Next-80B-A3B sea destacado y aprenderás las diferentes formas en que puedes empezar a usarlo, ya sea de forma local, con instancias de GPU o mediante API.
¿Qué es Qwen3-Next-80B-A3B: Conceptos básicos, puntos de referencia y aspectos destacados
Qwen3-Next-80B-A3B está construido con 80 mil millones de parámetros, pero solo se activan alrededor de 3 mil millones a la vez gracias a su arquitectura MoE (Mezcla de Expertos) altamente dispersa. Esta configuración permite al modelo ofrecer un rendimiento de alto nivel evitando la computación adicional que suelen tener los modelos de este tamaño. En la práctica, Qwen3-Next-80B-A3B logra una eficiencia extrema tanto en entrenamiento como en inferencia, lo que lo hace lo suficientemente potente para razonamientos complejos y a la vez amigable con los recursos para despliegues en el mundo real.
| Característica | Detalle |
| Parámetro | 80B en total y 3B activados |
| Expertos | 512 en total con 10 activados por token (1 compartido) |
| Arquitectura | Mezcla de Expertos de Alta Dispersión (MoE) |
| Longitud de contexto | 262.144 de forma nativa, ampliable hasta 1.010.000 tokens |
| Modo | Pensamiento/No pensamiento (2 modelos separados) |
| Multimodal | Solo texto |
| Licencia | Apache 2.0 |
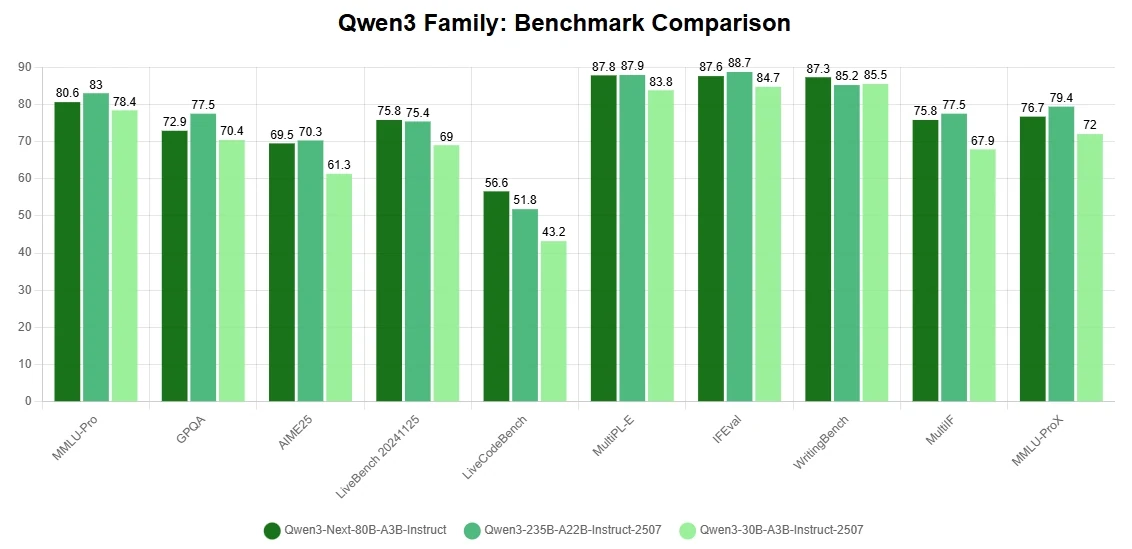
Aspectos destacados clave
- Avances arquitectónicos para reducir costos de entrenamiento: Construido con un mecanismo de atención híbrido, una estructura de Mezcla de Expertos altamente dispersa y optimizaciones de entrenamiento orientadas a la estabilidad, además de predicción de múltiples tokens para una inferencia más rápida. Estas innovaciones permiten que Qwen3-Next-80B-A3B iguale o incluso supere al denso Qwen3-32B en rendimiento mientras consume menos del 10% de su costo de entrenamiento (horas de GPU).
- Eficiencia extrema en inferencia de contexto largo: Al manejar secuencias de más de 32K tokens, el modelo ofrece un rendimiento más de 10 veces superior al de configuraciones convencionales. Esto se traduce en una eficiencia excepcional tanto en entrenamiento como en inferencia, reduciendo los costos computacionales sin comprometer la precisión.
- Capacidades de razonamiento y codificación de primer nivel: Destaca en puntos de referencia avanzados de razonamiento y codificación, ubicándose entre los modelos abiertos más fuertes disponibles. Esto posiciona a Qwen3-Next-80B-A3B como una opción versátil tanto para investigación como para aplicaciones de nivel de producción.
Cómo acceder a Qwen3-Next-80B-A3B: Despliegue local
Ejecutar Qwen3-Next-80B-A3B de forma local te da el máximo control y seguridad de los datos. Tú eres el dueño del entorno, puedes ajustar el modelo libremente y mantener todo en las instalaciones.
- Ventajas: Control total, ideal para datos sensibles, flexibilidad de investigación.
- Desventajas: Requisitos de hardware extremadamente altos (los 80B de parámetros exigen GPU potentes), tiempo de configuración largo y costos de mantenimiento continuos.
Ejecutar Qwen3-Next-80B-A3B de forma local te da libertad, pero a un costo muy alto en hardware y tiempo, requiriendo típicamente al menos GPU A100 o H100. Por eso muchos desarrolladores recurren a instancias de GPU, una forma más inteligente de obtener la misma potencia sin la sobrecarga.
Cómo acceder a Qwen3-Next-80B-A3B: Instancia de GPU
Ejecutar Qwen3-Next-80B-A3B a través de instancias de GPU en la nube ofrece un equilibrio práctico entre rendimiento y accesibilidad.
Ventajas:
- No es necesario invertir en hardware local caro
- Escalabilidad elástica con un rendimiento casi local
- Configuración más rápida y mantenimiento más sencillo en comparación con entornos completamente locales
Desventajas:
- Aún requiere cierta gestión del entorno (cargar los pesos del modelo, configurar tiempos de ejecución, monitorear la inferencia)
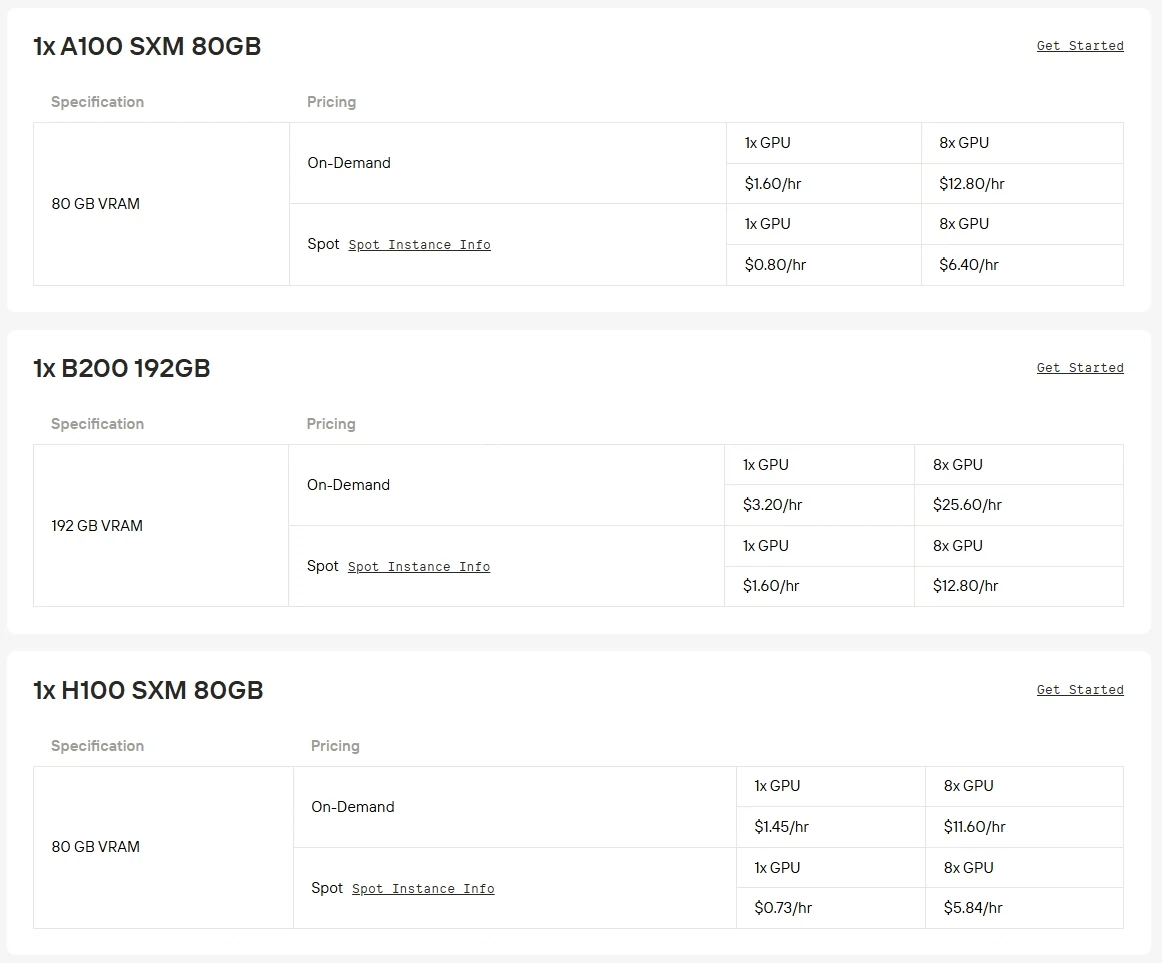
Requisitos de hardware: Qwen3-Next-80B-A3B es un modelo de 80B de parámetros que exige GPU potentes como A100, H100 o H200 para una inferencia eficiente. Ejecutarlo en GPU de consumo es típicamente poco práctico debido a las limitaciones de VRAM y rendimiento.
Novita AI ahora ofrece potencia de GPU de nivel empresarial con hasta un 50% de descuento, haciendo que modelos a gran escala como Qwen3-Next-80B-A3B sean más accesibles que nunca. Haz clic en el botón de abajo para probarlo de inmediato!
¡Prueba las GPU de Novita AI ahora!
También hay más opciones de GPU de alta demanda como RTX 5090, RTX 6000 Ada disponibles en Novita AI con facturación flexible a un precio competitivo.

Para que el despliegue sea igual de eficiente, Novita AI también proporciona plantillas listas para usar que eliminan la complejidad de la configuración al evitar la configuración manual.
Las Plantillas preconfiguradas ofrecen entornos optimizados con parámetros validados, variables de entorno preestablecidas y configuraciones en contenedores, para que puedas lanzar instancias al instante con DeepSeek, LLaMA y otros frameworks de vanguardia. Para usuarios avanzados, la Compatibilidad con plantillas personalizadas garantiza la máxima flexibilidad mediante scripts personalizados, stacks personalizados y optimizaciones ajustadas.
Si prefieres evitar por completo el despliegue y la gestión de infraestructura, el acceso por API de Novita AI ofrece la forma más sin complicaciones y rentable de ejecutar Qwen3-Next-80B-A3B.
Cómo acceder a Qwen3-Next-80B-A3B: Acceso por API
Opción 1: Integración directa por API
La API de Novita AI ofrece rendimiento de nivel empresarial: una latencia muy baja de 0,85 segundos y un alto rendimiento de 189,6 tps, junto con precios transparentes de solo $0,15 por 1M de tokens de entrada y $1,50 por 1M de tokens de salida, lo que la hace rápida y rentable para desarrolladores a escala.

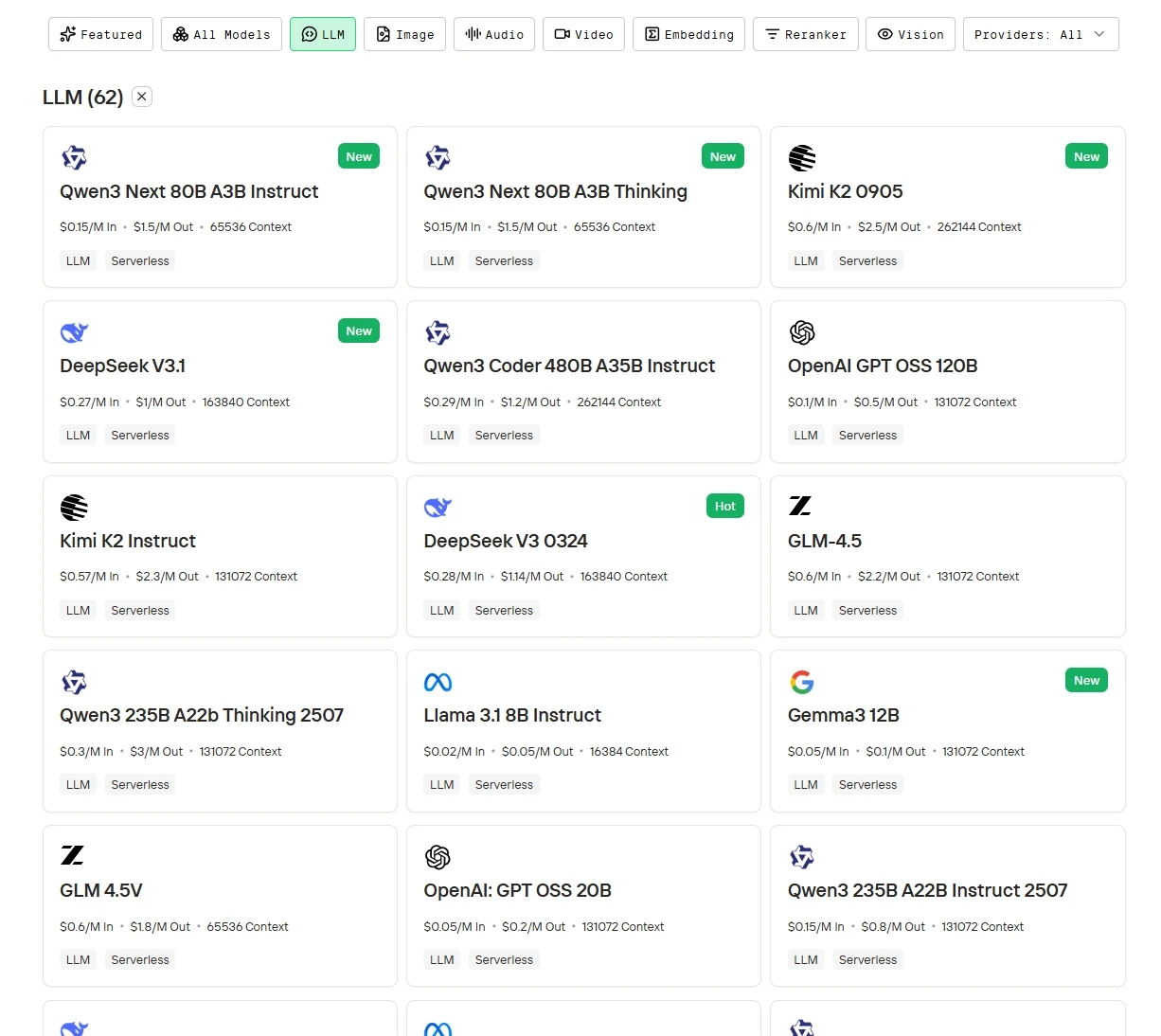
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando en la página de “Configuración de la cuenta”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con el LLM de Novita AI. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Características de la plataforma:
- Endpoint compatible con OpenAI:
/v3/openaipara una integración perfecta - Parámetros flexibles: Controla la generación con temperatura, top-p, penalizaciones y más
- Soporte de transmisión: Elige entre respuestas por transmisión o por lotes
- Selección de modelos: Accede a variantes de instrucción y de pensamiento
Opción 2: Flujos de trabajo de múltiples agentes con OpenAI Agents SDK
Construye sistemas de agentes que aprovechen la eficiencia de Qwen3-Next a través de la infraestructura de Novita AI:
- Compatibilidad con OpenAI Agents SDK: Usa el OpenAI Agents SDK con el endpoint de Novita para flujos de trabajo de agentes
- Capacidades de agentes: Diseña sistemas que se beneficien de la dispersión extrema y el rendimiento de contexto largo
- Integración sencilla: Apunta el SDK a
https://api.novita.ai/v3/openai
Cómo acceder a Qwen3-Next-80B-A3B: Integraciones de terceros
- Integración con frameworks: Accede a Qwen3-Next-80B-A3B a través de LangChain, Dify y Langflow
- Herramientas de desarrollo: Compatible con herramientas estándar de OpenAI, incluyendo Trae, Claude Code, Qwen Code, Cline y Cursor
- Ecosistema de Hugging Face: Integra en Spaces y pipelines a través de la API de Novita AI
Conclusión
Qwen3-Next-80B-A3B representa una nueva generación de IA a gran escala, destacándose en capacidades de llamada a herramientas y razonamiento avanzado en tareas altamente complejas. Sin embargo, la forma en que accedas a él da forma a tu experiencia en el mundo real: el despliegue local ofrece control total pero requiere hardware extremo; las instancias de GPU logran un equilibrio entre potencia y flexibilidad; y el acceso por API proporciona la ruta más rápida y sin complicaciones para la integración.
Con Novita AI, las tres opciones están disponibles bajo un mismo techo, respaldadas por precios competitivos, plantillas listas para usar y una infraestructura global. Tanto si eres un investigador, una startup o una empresa, Novita AI hace que el despliegue de Qwen3-Next-80B-A3B sea práctico y rentable.
Preguntas frecuentes
¿Cuáles son las mejoras clave de Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B adopta un diseño de Mezcla de Expertos ultra disperso con 80 mil millones de parámetros totales, pero solo 3 mil millones activos durante la inferencia. Esta eficiencia le permite superar a Qwen3-32B mientras consume menos de una décima parte de los recursos de entrenamiento. Su arquitectura revolucionaria, que cuenta con Atención Híbrida, dispersión MoE 1:50 y Predicción de Múltiples Tokens, se traduce en una inferencia más de 10 veces más rápida, especialmente en tareas de contexto largo.
¿Qué hardware se requiere para ejecutar Qwen3-Next-80B-A3B de forma local?
El despliegue local de Qwen3-Next-80B-A3B requiere típicamente GPU NVIDIA A100, H100 o H200, ya que las GPU de consumo no tienen la VRAM y el rendimiento necesarios.
¿Cuánto cuesta usar Qwen3-Next-80B-A3B a través de la API de Novita AI?
El uso de la API de Qwen3-Next-80B-A3B se factura de forma transparente a $0,15 por 1M de tokens de entrada y $1,50 por 1M de tokens de salida en Novita AI.
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, además de proporcionar una nube de GPU asequible y fiable para construir y escalar.



