

O Qwen3-Next-80B-A3B é um modelo de linguagem grande recém-lançado que traz atualizações importantes para a série Qwen3. Com melhorias significativas em arquitetura e eficiência, suas capacidades em raciocínio, programação e compreensão de contexto longo avançaram rapidamente, posicionando-o como um dos modelos mais competitivos de sua categoria.
Neste artigo, você terá uma visão clara do que faz o Qwen3-Next-80B-A3B se destacar e aprenderá as diferentes formas de começar a usá-lo — seja localmente, com instâncias de GPU ou por meio de API.
O que é o Qwen3-Next-80B-A3B: Fundamentos, Benchmark e Destaques
O Qwen3-Next-80B-A3B é construído com 80 bilhões de parâmetros, mas apenas cerca de 3 bilhões são ativados por vez graças à sua arquitetura MoE (Mixture-of-Experts) altamente esparsa. Essa configuração permite que o modelo entregue desempenho de alto nível enquanto evita o cálculo extra geralmente associado a modelos desse tamanho. Na prática, o Qwen3-Next-80B-A3B alcança eficiência extrema tanto no treinamento quanto na inferência, sendo poderoso o suficiente para raciocínio complexo, mas amigável em termos de recursos para implantação no mundo real.
| Recurso | Detalhe |
| Parâmetro | 80B no total e 3B ativados |
| Especialista | 512 no total, com 10 ativados por token (1 compartilhado) |
| Arquitetura | Mixture-of-Experts (MoE) de Alta Esparsidade |
| Comprimento de Contexto | 262.144 nativamente e extensível até 1.010.000 tokens |
| Modo | Pensamento/Não Pensamento (2 modelos separados) |
| Multimodal | Apenas texto |
| Licença | Apache 2.0 |
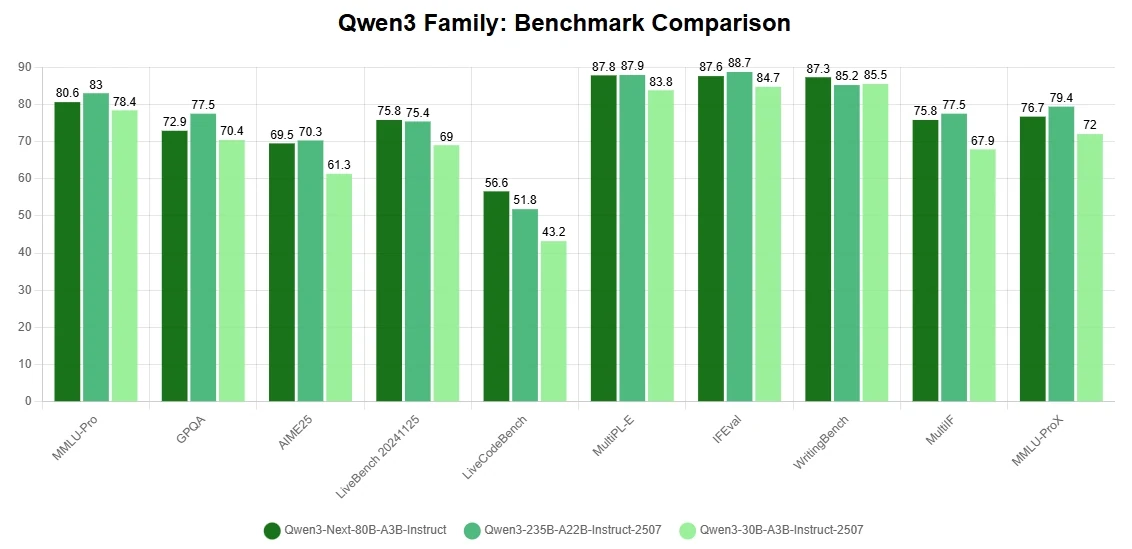
Principais Destaques
- Inovações Arquiteturais para Reduzir Custo de Treinamento: Construído com um mecanismo de atenção híbrido, uma estrutura de Mixture-of-Experts altamente esparsa e otimizações de treinamento voltadas para estabilidade, além de previsão de múltiplos tokens para inferência mais rápida. Essas inovações permitem que o Qwen3-Next-80B-A3B iguale ou até supere o Qwen3-32B denso em desempenho, consumindo menos de 10% do seu custo de treinamento (horas de GPU).
- Eficiência Extrema na Inferência de Contexto Longo: Ao lidar com sequências acima de 32K tokens, o modelo entrega uma produtividade mais de 10× maior do que configurações convencionais. Isso se traduz em eficiência excepcional tanto no treinamento quanto na inferência, reduzindo custos computacionais sem comprometer a precisão.
- Capacidades de Raciocínio e Programação de Primeira Linha: Se destaca em benchmarks de raciocínio avançado e programação, figurando entre os modelos abertos mais fortes disponíveis. Isso posiciona o Qwen3-Next-80B-A3B como uma escolha versátil tanto para pesquisa quanto para aplicações de nível de produção.
Como Acessar o Qwen3-Next-80B-A3B: Implantação Local
Executar o Qwen3-Next-80B-A3B localmente oferece controle máximo e segurança de dados. Você é dono do ambiente, pode fazer fine-tuning livremente e manter tudo no local.
- Vantagens: Controle total, ideal para dados sensíveis, flexibilidade de pesquisa.
- Desvantagens: Requisitos de hardware extremamente altos (80B de parâmetros exigem GPUs potentes), tempo de configuração longo e custos de manutenção contínuos.
Executar o Qwen3-Next-80B-A3B localmente oferece liberdade, mas com um custo elevado em hardware e tempo — geralmente exigindo pelo menos GPUs A100 ou H100. É por isso que muitos desenvolvedores recorrem a instâncias de GPU: uma forma mais inteligente de obter o mesmo poder sem os custos adicionais.
Como Acessar o Qwen3-Next-80B-A3B: Instância de GPU
Executar o Qwen3-Next-80B-A3B por meio de instâncias de GPU em nuvem oferece um equilíbrio prático entre desempenho e acessibilidade.
Vantagens:
- Não há necessidade de investir em hardware local caro
- Escalonamento elástico com desempenho próximo ao local
- Configuração mais rápida e manutenção mais fácil em comparação com ambientes totalmente locais
Desvantagens:
- Ainda exige alguma gestão de ambiente (carregar pesos do modelo, configurar tempos de execução, monitorar a inferência)
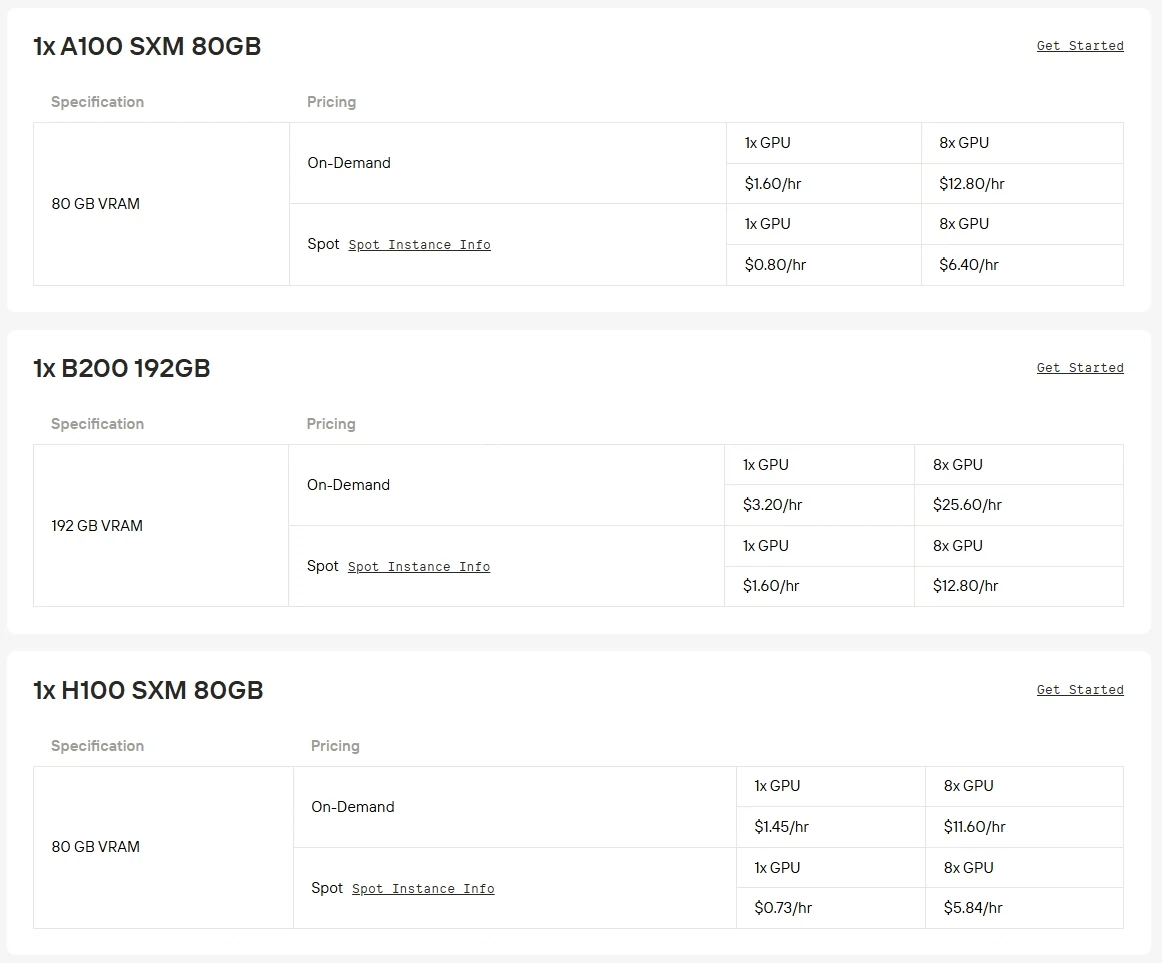
Requisitos de Hardware: O Qwen3-Next-80B-A3B é um modelo de 80B de parâmetros que exige GPUs potentes como A100, H100 ou H200 para inferência eficiente. Executá-lo em GPUs de consumo geral é praticamente inviável devido a limitações de VRAM e produtividade.
A Novita AI agora oferece poder de GPU de nível empresarial com até 50% de desconto, tornando modelos de grande escala como o Qwen3-Next-80B-A3B mais acessíveis do que nunca. Clique no botão abaixo para experimentar agora mesmo!
Experimente as GPUs da Novita AI Agora !
Mais opções de GPUs de alta demanda, como RTX 5090, RTX 6000 Ada, também estão disponíveis na Novita AI com faturamento flexível a um preço competitivo.

Para tornar a implantação igualmente eficiente, a Novita AI também fornece modelos prontos para uso que removem a complexidade da configuração, eliminando a necessidade de configuração manual.
Os Modelos Pré-configurados oferecem ambientes otimizados com parâmetros validados, variáveis de ambiente pré-definidas e configurações em contêineres — para que você possa iniciar instantaneamente com DeepSeek, LLaMA e outras estruturas de ponta. Para usuários avançados, o Suporte a Modelos Personalizados garante flexibilidade máxima por meio de scripts personalizados, pilhas customizadas e otimizações de ajuste fino.
Se você prefere evitar completamente a implantação e a gestão de infraestrutura, o acesso via API da Novita AI oferece a forma mais livre de problemas e com melhor custo-benefício de executar o Qwen3-Next-80B-A3B.
Como Acessar o Qwen3-Next-80B-A3B: Acesso via API
Opção 1: Integração Direta via API
A API da Novita AI oferece desempenho de nível empresarial — latência muito baixa de 0,85s e alta produtividade de 189,6 tps — juntamente com preços transparentes de apenas $0,15 por 1M de tokens de entrada e $1,50 por 1M de tokens de saída, tornando-a rápida e com ótimo custo-benefício para desenvolvedores em escala.

Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Experimente o Qwen3-Next Gratuitamente!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que melhor atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página de “Configurações da Conta”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Recursos da Plataforma:
- Endpoint compatível com OpenAI:
/v3/openaipara integração perfeita - Parâmetros flexíveis: Controle a geração com temperatura, top-p, penalidades e mais
- Suporte a streaming: Escolha entre respostas de streaming ou em lote
- Seleção de modelo: Acesse as variantes instruct e de pensamento
Opção 2: Fluxos de Trabalho Multiagente com o OpenAI Agents SDK
Construa sistemas de agentes que aproveitem a eficiência do Qwen3-Next por meio da infraestrutura da Novita AI:
- Compatibilidade com o OpenAI Agents SDK: Use o OpenAI Agents SDK com o endpoint da Novita para fluxos de trabalho de agentes
- Capacidades de agentes: Projete sistemas que se beneficiem da esparsidade extrema e do desempenho de contexto longo
- Integração simples: Aponte o SDK para
https://api.novita.ai/v3/openai
Como Acessar o Qwen3-Next-80B-A3B: Integrações de Terceiros
- Integração com Frameworks: Acesse o Qwen3-Next-80B-A3B por meio do LangChain, Dify e Langflow
- Ferramentas de Desenvolvimento: Compatível com ferramentas padrão OpenAI, incluindo Trae, Claude Code, Qwen Code, Cline e Cursor
- Ecossistema Hugging Face: Integre em Spaces e pipelines por meio da API da Novita AI
Conclusão
O Qwen3-Next-80B-A3B representa uma nova geração de IA em grande escala, se destacando em capacidades de chamada de ferramentas e raciocínio avançado em tarefas altamente complexas. No entanto, a forma como você o acessa molda sua experiência no mundo real: a implantação local oferece controle total, mas exige hardware extremo; as instâncias de GPU atingem um equilíbrio entre poder e flexibilidade; e o acesso via API oferece o caminho mais rápido e perfeito para integração.
Com a Novita AI, as três opções estão disponíveis em um só lugar — com suporte de preços competitivos, modelos prontos para uso e infraestrutura global. Se você é um pesquisador, uma startup ou uma empresa, a Novita AI torna a implantação do Qwen3-Next-80B-A3B prática e com bom custo-benefício.
Perguntas Frequentes
Quais são as principais melhorias do Qwen3-Next-80B-A3B?
O Qwen3-Next-80B-A3B adota um design de Mixture-of-Experts ultra-esparso com 80 bilhões de parâmetros no total, mas apenas 3 bilhões ativos durante a inferência. Essa eficiência permite que ele supere o Qwen3-32B consumindo menos de um décimo dos recursos de treinamento. Sua arquitetura inovadora — com Atenção Híbrida, esparsidade MoE de 1:50 e Previsão de Múltiplos Tokens — se traduz em uma inferência mais de 10 vezes mais rápida, especialmente em tarefas de contexto longo.
Qual hardware é necessário para executar o Qwen3-Next-80B-A3B localmente?
A implantação local do Qwen3-Next-80B-A3B geralmente requer GPUs NVIDIA A100, H100 ou H200, pois GPUs de consumo não possuem a VRAM e a produtividade necessárias.
Quanto custa usar o Qwen3-Next-80B-A3B por meio da API da Novita AI?
O uso da API do Qwen3-Next-80B-A3B é faturado de forma transparente a $0,15 por 1M de tokens de entrada e $1,50 por 1M de tokens de saída na Novita AI
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma forma fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



