

Qwen3-Next-80B-A3B est un grand modèle linguistique nouvellement publié qui apporte des mises à jour majeures à la série Qwen3. Grâce à des améliorations significatives de son architecture et de son efficacité, ses capacités en matière de raisonnement, de codage et de compréhension de contexte long ont progressé rapidement, ce qui en fait l’un des modèles les plus compétitifs de sa catégorie.
Dans cet article, vous découvrirez ce qui fait la particularité de Qwen3-Next-80B-A3B et apprendrez les différentes façons de commencer à l’utiliser : que ce soit en local, via des instances GPU ou par API.
Qu’est-ce que Qwen3-Next-80B-A3B : bases, benchmarks et points forts
Qwen3-Next-80B-A3B est construit avec 80 milliards de paramètres, mais seulement environ 3 milliards sont activés à la fois grâce à son architecture MoE (Mixture-of-Experts) très éparse. Cette configuration permet au modèle d’offrir des performances de haut niveau tout en évitant les calculs supplémentaires généralement associés aux modèles de cette taille. En pratique, Qwen3-Next-80B-A3B atteint une efficacité extrême à la fois pour l’entraînement et l’inférence, ce qui le rend suffisamment puissant pour des raisonnements complexes tout en étant adapté aux déploiements dans le monde réel.
| Fonctionnalité | Détail |
| Paramètre | 80B au total et 3B activés |
| Experts | 512 au total avec 10 activés par jeton (1 partagé) |
| Architecture | Mélange d’experts à haute sparsité (MoE) |
| Longueur de contexte | 262 144 nativement, extensible jusqu’à 1 010 000 jetons |
| Mode | Réflexion/Non-réflexion (2 modèles distincts) |
| Multimodal | Texte uniquement |
| Licence | Apache 2.0 |
Points forts clés
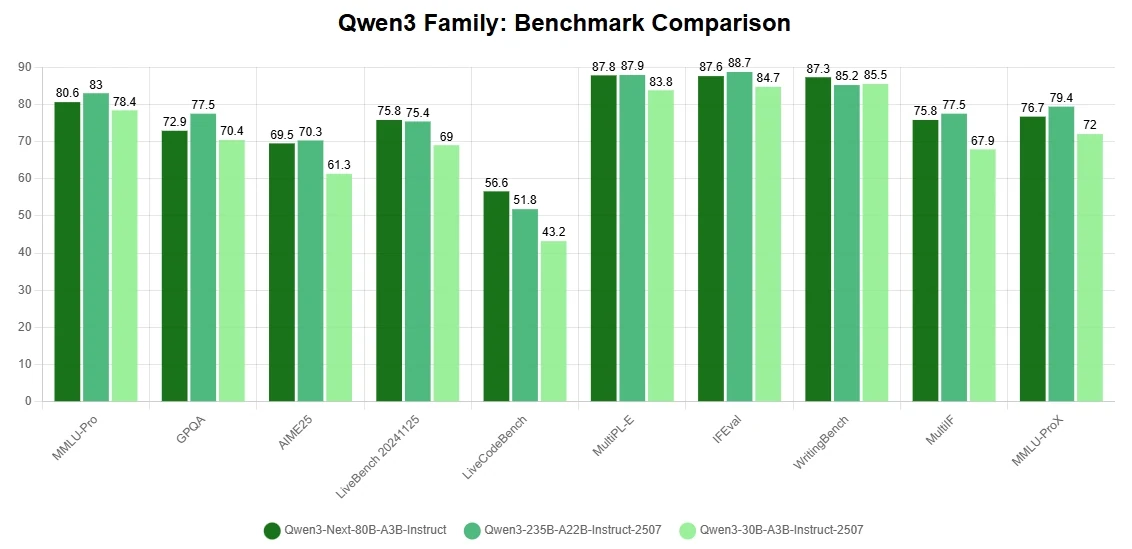
- Percées architecturales pour réduire les coûts d’entraînement : Construit avec un mécanisme d’attention hybride, une structure de mélange d’experts très éparse et des optimisations d’entraînement orientées stabilité, ainsi qu’une prédiction multi-jetons pour une inférence plus rapide. Ces innovations permettent à Qwen3-Next-80B-A3B d’égaler voire de surpasser le dense Qwen3-32B en termes de performances tout en consommant moins de 10 % de ses coûts d’entraînement (heures GPU).
- Efficacité extrême pour l’inférence de contexte long : Lors du traitement de séquences de plus de 32 000 jetons, le modèle offre un débit plus de 10 fois supérieur à celui des configurations classiques. Cela se traduit par une efficacité exceptionnelle à la fois pour l’entraînement et l’inférence, réduisant les coûts de calcul sans compromettre la précision.
- Capacités de raisonnement et de codage de premier plan : Il excelle sur les benchmarks de raisonnement avancé et de codage, se classant parmi les modèles ouverts les plus performants disponibles. Cela fait de Qwen3-Next-80B-A3B un choix polyvalent à la fois pour la recherche et les applications de niveau production.
Comment accéder à Qwen3-Next-80B-A3B : Déploiement local
Exécuter Qwen3-Next-80B-A3B en local vous offre un contrôle maximal et une sécurité des données. Vous possédez l’environnement, pouvez effectuer un affinage librement et conserver l’ensemble des données sur site.
- Avantages : Contrôle total, idéal pour les données sensibles, flexibilité pour la recherche.
- Inconvénients : Exigences matérielles extrêmement élevées (les 80B de paramètres nécessitent des GPU puissants), temps de configuration long et coûts de maintenance permanents.
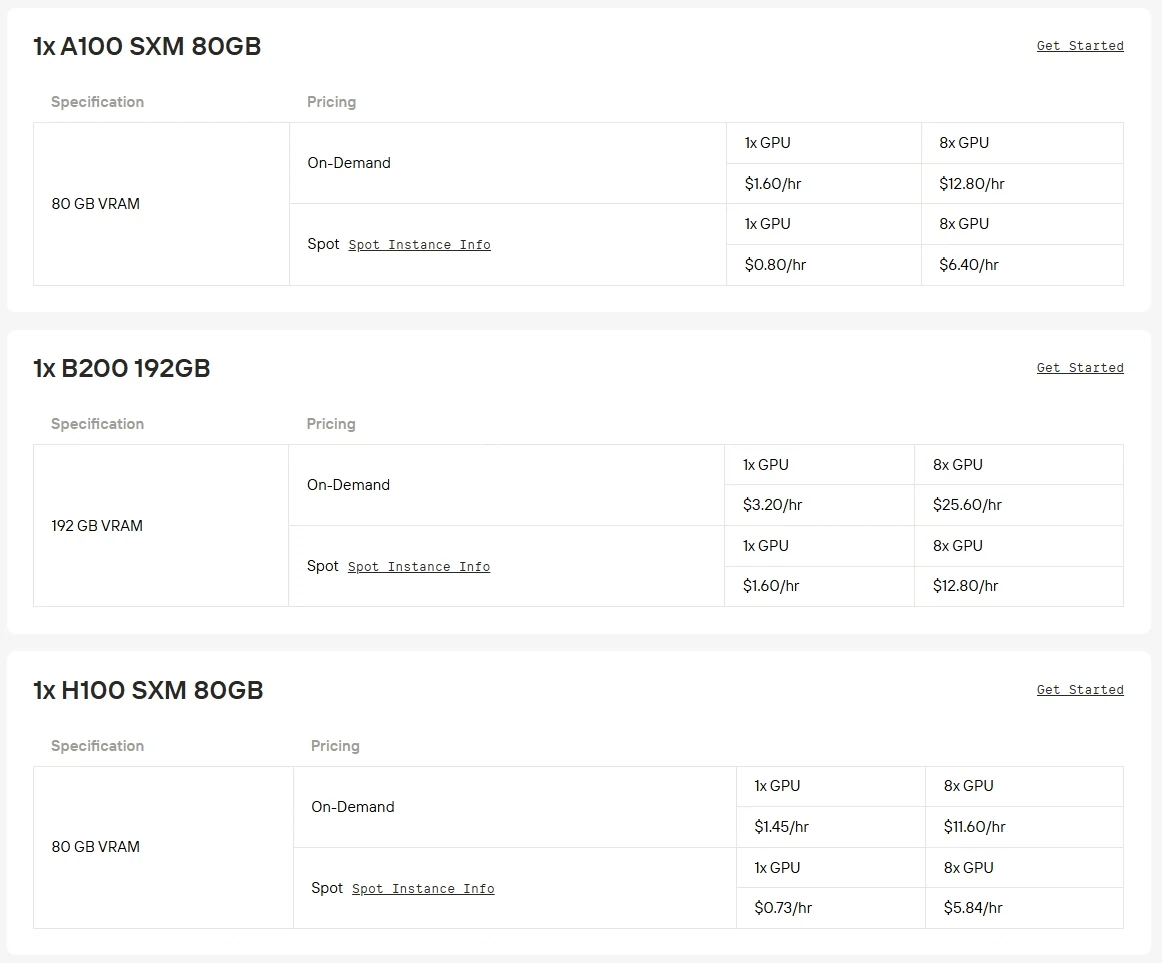
Exécuter Qwen3-Next-80B-A3B en local vous offre une liberté, mais au prix d’un coût élevé en matériel et en temps : il nécessite généralement au moins des GPU A100 ou H100. C’est pourquoi de nombreux développeurs se tournent vers les instances GPU, une voie plus intelligente pour obtenir la même puissance sans les surcoûts.
Comment accéder à Qwen3-Next-80B-A3B : Instances GPU
Exécuter Qwen3-Next-80B-A3B via des instances GPU cloud offre un équilibre pratique entre performance et accessibilité.
Avantages :
- Pas besoin d’investir dans du matériel onéreux sur site
- Mise à l’échelle élastique avec des performances quasi locales
- Configuration plus rapide et maintenance plus facile par rapport à des environnements entièrement locaux
Inconvénients :
- Nécessite toujours une certaine gestion de l’environnement (chargement des poids du modèle, configuration des environnements d’exécution, surveillance de l’inférence)
Exigences matérielles : Qwen3-Next-80B-A3B est un modèle de 80B de paramètres qui nécessite des GPU puissants tels que A100, H100 ou H200 pour une inférence efficace. L’exécuter sur des GPU grand public est généralement impraticable en raison des limitations de VRAM et de débit.
Novita AI propose désormais une puissance GPU de niveau entreprise avec jusqu’à 50 % de réduction, rendant les modèles à grande échelle comme Qwen3-Next-80B-A3B plus accessibles que jamais. Cliquez sur le bouton ci-dessous pour essayer immédiatement !
Essayez les GPU Novita AI maintenant !
D’autres options de GPU performants tels que RTX 5090, RTX 6000 Ada sont également disponibles sur Novita AI avec une facturation flexible à un prix compétitif.

Pour rendre le déploiement tout aussi efficace, Novita AI propose également des modèles prêts à l’emploi qui éliminent la complexité de la configuration en supprimant la mise en place manuelle.
Les modèles préconfigurés offrent des environnements optimisés avec des paramètres validés, des variables d’environnement prédéfinies et des configurations conteneurisées : vous pouvez donc les lancer instantanément avec DeepSeek, LLaMA et d’autres frameworks de pointe. Pour les utilisateurs avancés, la prise en charge de modèles personnalisés assure une flexibilité maximale grâce à des scripts personnalisés, des piles personnalisées et des optimisations affinées.
Si vous préférez éviter complètement le déploiement et la gestion d’infrastructure, l’accès API de Novita AI offre le moyen le plus simple et le plus rentable d’exécuter Qwen3-Next-80B-A3B.
Comment accéder à Qwen3-Next-80B-A3B : Accès API
Option 1 : Intégration API directe
L’API de Novita AI offre des performances de niveau entreprise : une latence très faible de 0,85 sec et un débit élevé de 189,6 tps (jetons par seconde), associés à une tarification transparente à seulement 0,15 $ par million de jetons d’entrée et 1,50 $ par million de jetons de sortie, ce qui en fait un outil à la fois rapide et rentable pour les développeurs à grande échelle.

Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Qwen3-Next gratuitement !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres du compte », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fonctionnalités de la plateforme :
- Point de terminaison compatible OpenAI :
/v3/openaipour une intégration transparente - Paramètres flexibles : Contrôlez la génération avec la température, top-p, les pénalités et plus encore
- Prise en charge du streaming : Choisissez entre des réponses en streaming ou par lots
- Sélection de modèle : Accédez aux variantes instruct et thinking
Option 2 : Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes d’agents qui tirent parti de l’efficacité de Qwen3-Next via l’infrastructure de Novita AI :
- Compatibilité avec le SDK OpenAI Agents : Utilisez le SDK OpenAI Agents avec le point de terminaison de Novita pour les flux de travail d’agents
- Capacités des agents : Concevez des systèmes qui bénéficient de la sparsité extrême et des performances de contexte long
- Intégration simple : Pointez le SDK vers
https://api.novita.ai/v3/openai
Comment accéder à Qwen3-Next-80B-A3B : Intégrations tierces
- Intégration de frameworks : Accédez à Qwen3-Next-80B-A3B via LangChain, Dify et Langflow
- Outils de développement : Compatible avec les outils standard OpenAI, notamment Trae, Claude Code, Qwen Code, Cline et Cursor
- Écosystème Hugging Face : Intégrez-le dans les Spaces et les pipelines via l’API de Novita AI
Conclusion
Qwen3-Next-80B-A3B représente une nouvelle génération d’IA à grande échelle, excellant dans les capacités d’appel d’outils et le raisonnement avancé sur des tâches très complexes. Pourtant, la façon dont vous y accédez conditionne votre expérience concrète : le déploiement local offre un contrôle total mais nécessite un matériel extrêmement puissant ; les instances GPU constituent un équilibre entre puissance et flexibilité ; et l’accès API offre la voie d’intégration la plus rapide et la plus fluide.
Avec Novita AI, ces trois options sont disponibles sous un même toit, soutenues par des tarifs compétitifs, des modèles prêts à l’emploi et une infrastructure mondiale. Que vous soyez un chercheur, une startup ou une entreprise, Novita AI rend le déploiement de Qwen3-Next-80B-A3B à la fois pratique et rentable.
Questions fréquemment posées
Quelles sont les principales améliorations de Qwen3-Next-80B-A3B ?
Qwen3-Next-80B-A3B adopte une conception de mélange d’experts ultra-sparse avec 80 milliards de paramètres au total mais seulement 3 milliards actifs pendant l’inférence. Cette efficacité lui permet de surpasser le Qwen3-32B tout en consommant moins d’un dixième des ressources d’entraînement. Son architecture révolutionnaire, dotée d’une attention hybride, d’une sparsité MoE de 1:50 et d’une prédiction multi-jetons, se traduit par une inférence plus de 10 fois plus rapide, en particulier sur les tâches de contexte long.
Quel matériel est nécessaire pour exécuter Qwen3-Next-80B-A3B en local ?
Le déploiement local de Qwen3-Next-80B-A3B nécessite généralement des GPU NVIDIA A100, H100 ou H200, car les GPU grand public n’ont pas la VRAM et le débit nécessaires.
Combien coûte l’utilisation de Qwen3-Next-80B-A3B via l’API de Novita AI ?
L’utilisation de l’API de Qwen3-Next-80B-A3B est facturée de manière transparente à 0,15 $ par million de jetons d’entrée et 1,50 $ par million de jetons de sortie sur Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA grâce à notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle vos projets.



