

يعد Qwen3-Next-80B-A3B نموذج لغة كبير تم إصداره حديثًا ويجلب تحديثات كبيرة لسلسلة Qwen3. مع تحسينات كبيرة في البنية والكفاءة، تطورت قدراته في الاستدلال والبرمجة وفهم السياقات الطويلة بسرعة كبيرة، مما يجعله أحد أكثر النماذج تنافسية في فئته.
في هذا المقال، ستحصل على نظرة واضحة على ما يميز Qwen3-Next-80B-A3B وتتعلم الطرق المختلفة التي يمكنك من خلالها البدء في استخدامه—سواء محليًا، أو عبر مثيلات GPU، أو عبر API.
ما هو Qwen3-Next-80B-A3B: الأساسيات، معايير الأداء وأبرز الميزات
تم بناء Qwen3-Next-80B-A3B بـ 80 مليار معامل، لكن يتم تنشيط حوالي 3 مليار فقط في كل مرة بفضل بنية MoE شديدة التفرق. يسمح هذا الإعداد للنموذج بتقديم أداء عالي المستوى مع تجنب الحسابات الإضافية المرتبطة عادةً بالنماذج بهذا الحجم. في الممارسة العملية، يحقق Qwen3-Next-80B-A3B كفاءة قصوى في كل من التدريب والاستدلال، مما يجعله قويًا بدرجة كافية للاستدلال المعقد وموفرًا للموارد للنشر في العالم الحقيقي.
| الميزة | التفاصيل |
| المعامل | 80 مليار إجمالاً و 3 مليار منشط |
| الخبراء | 512 إجمالاً مع تنشيط 10 لكل رمز (1 مشترك) |
| البنية | مزيج الخبراء شديد التفرق (MoE) |
| طول السياق | 262,144 رمزًا بشكل أصلي ويمكن تمديده حتى 1,010,000 رمز |
| الوضع | تفكير / غير تفكير (نموذجان منفصلان) |
| متعدد الوسائط | نصي فقط |
| الرخصة | Apache 2.0 |
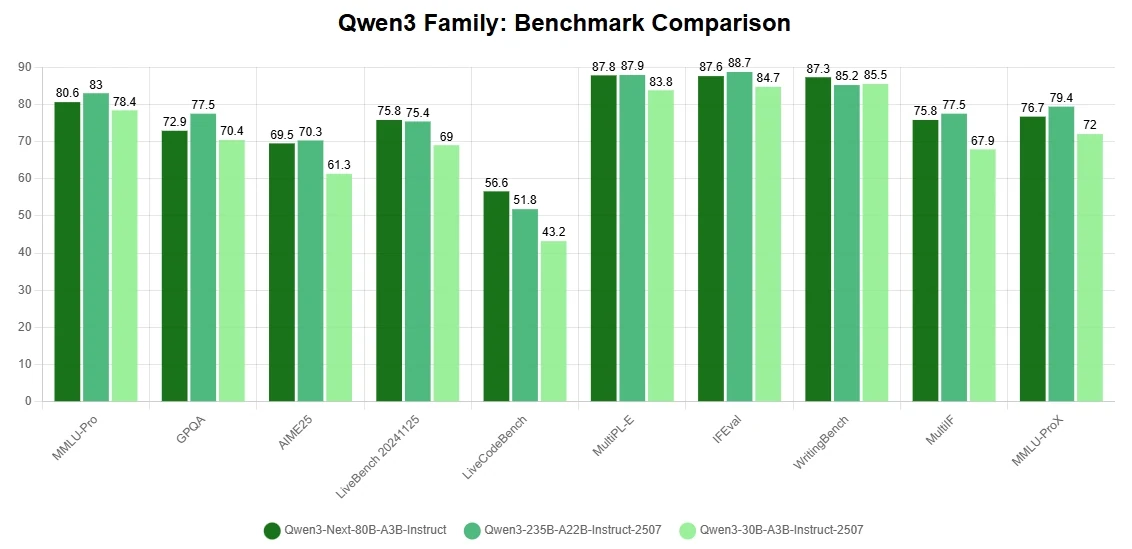
أبرز الميزات
- اختراقات معمارية لتقليل تكلفة التدريب: تم بناؤه باستخدام آلية انتباه هجينة، وبنية مزيج خبراء شديدة التفرق، وتحسينات تدريب موجهة للاستقرار، بالإضافة إلى تنبؤ متعدد الرموز لاستدلال أسرع. تتيح هذه الابتكارات لـ Qwen3-Next-80B-A3B مطابقة أو حتى التفوق على النموذج الكثيف Qwen3-32B في الأداء مع استهلاك أقل من 10% من تكلفة تدريبه (ساعات GPU).
- كفاءة قصوى في استدلال السياقات الطويلة: عند التعامل مع تسلسلات تتجاوز 32 ألف رمز، يقدم النموذج معدل إنتاج أعلى بأكثر من 10 أضعاف مقارنة بالإعدادات التقليدية. يترجم هذا إلى كفاءة استثنائية في كل من التدريب والاستدلال، مع خفض تكاليف الحساب دون المساس بالدقة.
- قدرات استدلال وبرمجة من الفئة الأولى: يتفوق في معايير الاستدلال المتقدم والبرمجة، ويحتل مرتبة بين أقوى النماذج المفتوحة المتاحة. هذا يضع Qwen3-Next-80B-A3B كخيار متعدد الاستخدامات لكل من البحث والتطبيقات الإنتاجية.
كيفية الوصول إلى Qwen3-Next-80B-A3B: النشر المحلي
تشغيل Qwen3-Next-80B-A3B محليًا يمنيك أقصى درجة من التحكم وأمان البيانات. أنت تملك البيئة، ويمكنك ضبط النموذج بحرية، وتحتفظ بكل شيء محليًا.
- المزايا: تحكم كامل، الأفضل للبيانات الحساسة، مرونة في البحث.
- العيوب: متطلبات عتاد مرتفعة للغاية (تتطلب معاملات 80 مليار GPU قوية)، وقت إعداد طويل، وتكاليف صيانة مستمرة.
تشغيل Qwen3-Next-80B-A3B محليًا يمنيك حرية، لكن بتكلفة باهظة في العتاد والوقت—عادةً ما يتطلب على الأقل وحدات معالجة رسوميات من فئة A100 أو H100. لهذا السبب يلجأ العديد من المطورين إلى مثيلات GPU—وهي طريقة أذكى للحصول على نفس القوة دون النفقات العامة.
كيفية الوصول إلى Qwen3-Next-80B-A3B: مثيلات GPU
تشغيل Qwen3-Next-80B-A3B عبر مثيلات GPU السحابية يوفر توازنًا عمليًا بين الأداء وسهولة الوصول.
المزايا:
- لا حاجة للاستثمار في عتاد محلي باهظ الثمن
- توسيع مرن مع أداء قريب من الأداء المحلي
- إعداد أسرع وصيانة أسهل مقارنة بالبيئات المحلية بالكامل
العيوب:
- لا يزال يتطلب بعض إدارة البيئة (تحميل أوزان النموذج، تهيئة أوقات التشغيل، مراقبة الاستدلال)
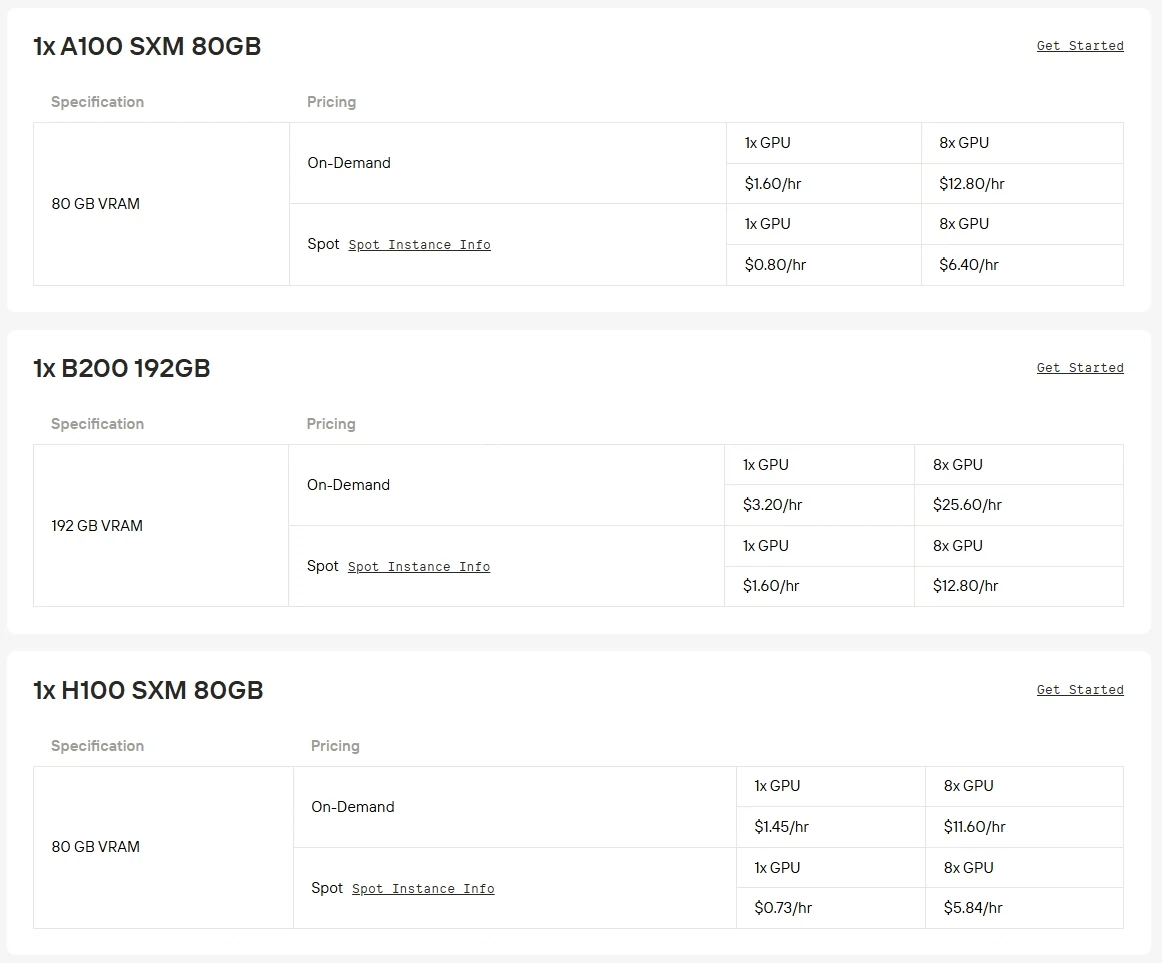
متطلبات العتاد: يعد Qwen3-Next-80B-A3B نموذجًا بمعاملات 80 مليار يتطلب وحدات معالجة رسوميات قوية مثل A100 أو H100 أو H200 لاستدلال فعال. عادةً ما يكون تشغيله على وحدات معالجة الرسوميات الاستهلاكية غير عملي بسبب قيود ذاكرة الوصول العشوائي للرسوميات (VRAM) ومعدل الإنتاج.
تقدم Novita AI الآن قوة GPU من الفئة Enterprise بخصم يصل إلى 50%، مما يجعل النماذج واسعة النطاق مثل Qwen3-Next-80B-A3B أكثر سهولة في الوصول من أي وقت مضى. انقر على الزر أدناه لتجربتها على الفور!
جرب وحدات GPU من Novita AI الآن!
تتوفر أيضًا خيارات إضافية من وحدات GPU عالية الأداء مثل RTX 5090 و RTX 6000 Ada على Novita AI مع فواتير مرنة بسعر تنافسي.

لجعل النشر فعالاً بنفس القدر، توفر Novita AI أيضًا قوالب جاهزة للاستخدام تزيل تعقيدات الإعداد عن طريق التخلص من الإعداد اليدوي.
تقدم القوالب المُعدة مسبقًا بيئات محسنة مع معايير تم التحقق منها، ومتغيرات بيئة مُعدة مسبقًا، وتكوينات مُحاطة—بحيث يمكنك الإطلاق فورًا مع DeepSeek و LLaMA وأطر العمل المتطورة الأخرى. بالنسبة للمستخدمين المتقدمين، يضمن دعم القوالب المخصصة أقصى درجة من المرونة من خلال النصوص البرمجية المخصصة، ومكدسات مخصصة، وتحسينات دقيقة.
إذا كنت تفضل تجنب النشر وإدارة البنية التحتية تمامًا، يوفر الوصول إلى API من Novita AI الطريقة الأكثر خلوًا من المتاعب والأكثر كفاءة من حيث التكلفة لتشغيل Qwen3-Next-80B-A3B.
كيفية الوصول إلى Qwen3-Next-80B-A3B: الوصول عبر API
الخيار 1: تكامل API مباشر
يقدم API من Novita AI أداءً من الفئة Enterprise—تأخير منخفض جدًا يبلغ 0.85 ثانية ومعدل إنتاج مرتفع يبلغ 189.6 رمزًا في الثانية—مع تسعير شفاف يبلغ فقط 0.15 دولار لكل مليون رمز إدخال و 1.50 دولار لكل مليون رمز إخراج، مما يجعله سريعًا وموفرًا للتكلفة للمطورين على نطاق واسع.

الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

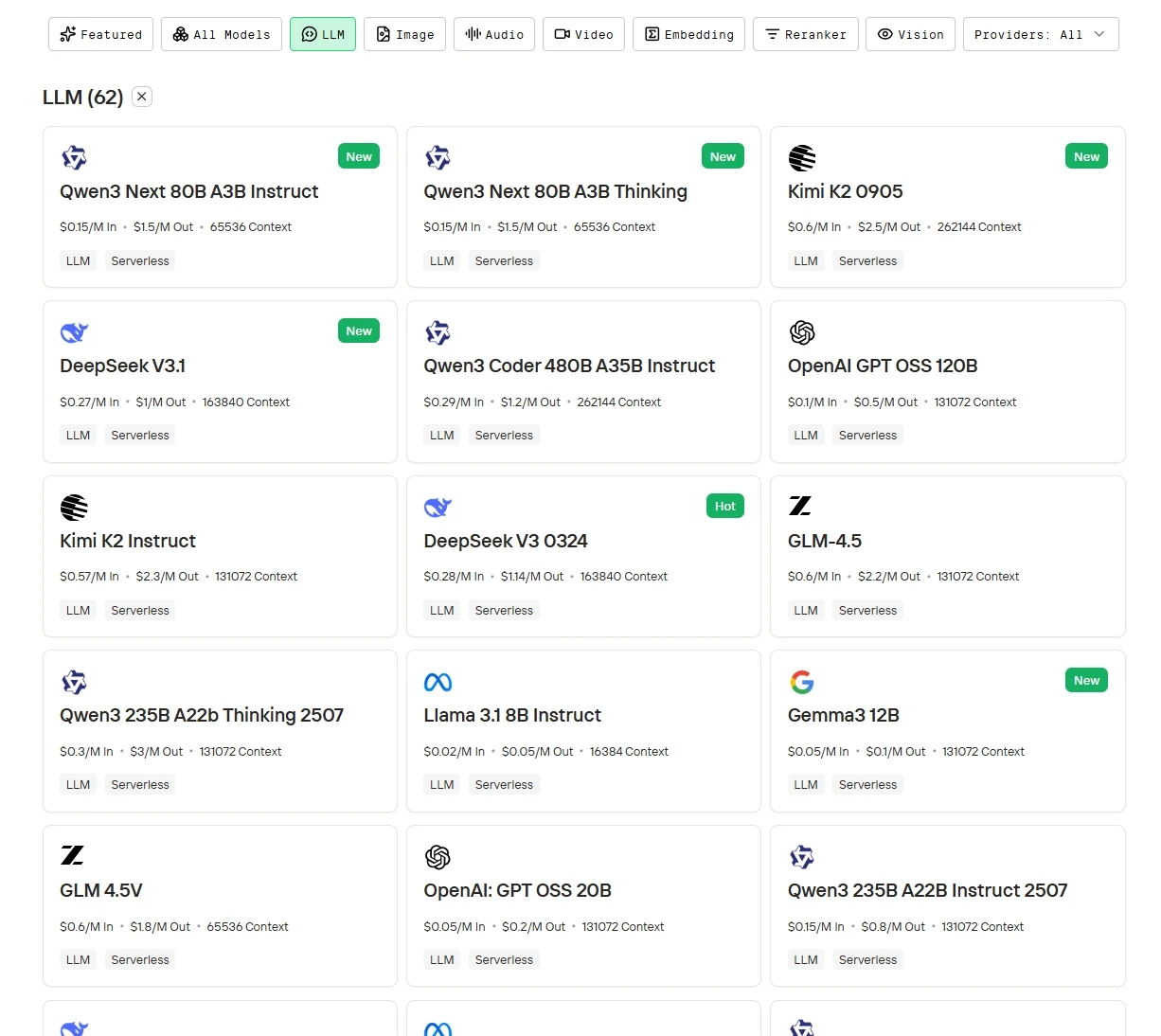
الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
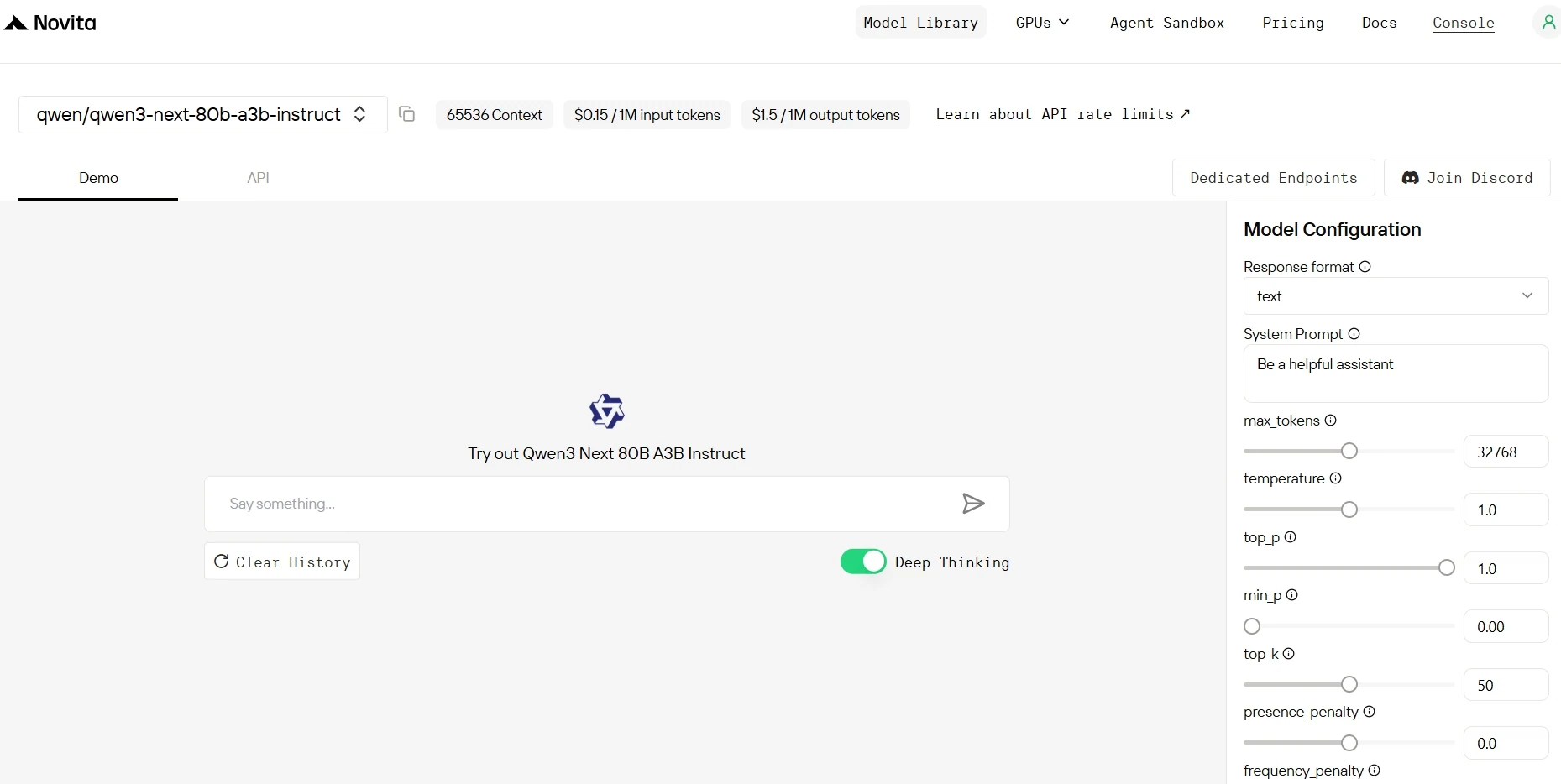
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “إعدادات الحساب”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع نموذج اللغة الكبير من Novita AI. هذا مثال على استخدام API لإكمال المحادثات لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
ميزات المنصة:
- نقطة نهاية متوافقة مع OpenAI:
/v3/openaiللتكامل السلس - معايير مرنة: تحكم في التوليد باستخدام درجة الحرارة، top-p، العقوبات، والمزيد
- دعم البث: اختر بين الاستجابات المتدفقة أو المجمعة
- اختيار النموذج: الوصول إلى كلا النموذجين المُوجه والتفكير
الخيار 2: سير عمل متعدد الوكلاء باستخدام OpenAI Agents SDK
ابنِ أنظمة وكلاء تستفيد من كفاءة Qwen3-Next من خلال بنية Novita AI التحتية:
- توافق مع OpenAI Agents SDK: استخدم OpenAI Agents SDK مع نقطة نهاية Novita لسير عمل الوكلاء
- قدرات الوكلاء: صمم أنظمة تستفيد من التفرق الشديد وأداء السياقات الطويلة
- تكامل بسيط: وجه SDK إلى
https://api.novita.ai/v3/openai
كيفية الوصول إلى Qwen3-Next-80B-A3B: تكاملات طرف ثالث
- تكامل الأطر: الوصول إلى Qwen3-Next-80B-A3B عبر LangChain، Dify، و Langflow
- أدوات التطوير: متوافق مع أدوات معيار OpenAI بما في ذلك Trae، Claude Code، Qwen Code، Cline، و Cursor
- نظام Hugging Face البيئي: التكامل في المساحات وخطوط الأنابيب عبر API من Novita AI
الخاتمة
يمثل Qwen3-Next-80B-A3B جيلًا جديدًا من الذكاء الاصطناعي واسع النطاق، حيث يتفوق في قدرات استدعاء الأدوات والاستدلال المتقدم عبر المهام شديدة التعقيد. لكن طريقة وصولك إليه تشكل تجربتك في العالم الحقيقي: يوفر النشر المحلي تحكمًا كاملاً لكنه يتطلب عتادًا قويًا للغاية؛ وتوفر مثيلات GPU توازنًا بين القوة والمرونة؛ ويوفر الوصول عبر API الطريق الأسرع والأكثر سلاسة للتكامل.
مع Novita AI، تتوفر جميع الخيارات الثلاث تحت سقف واحد—مدعومة بتسعير تنافسي، وقوالب جاهزة للاستخدام، وبنية تحتية عالمية. سواء كنت باحثًا، أو شركة ناشئة، أو مؤسسة كبيرة، تجعل Novita AI نشر Qwen3-Next-80B-A3B عمليًا وموفرًا للتكلفة.
الأسئلة الشائعة
ما هي أبرز التحسينات في Qwen3-Next-80B-A3B؟
يتبنى Qwen3-Next-80B-A3B تصميم مزيج خبراء فائق التفرق مع 80 مليار معامل إجمالي لكن 3 مليار فقط منشطة أثناء الاستدلال. تتيح هذه الكفاءة له التفوق على Qwen3-32B مع استهلاك أقل من عشر الموارد التدريبية. تترجم بنيته التحتية الرائدة—التي تتميز بانتباه هجين، وتفرق MoE بنسبة 1:50، وتنبؤ متعدد الرموز— إلى استدلال أسرع بأكثر من 10 أضعاف، خاصة في مهام السياقات الطويلة.
ما هو العتاد المطلوب لتشغيل Qwen3-Next-80B-A3B محليًا؟
يتطلب النشر المحلي لـ Qwen3-Next-80B-A3B عادةً وحدات معالجة رسوميات من NVIDIA من فئة A100 أو H100 أو H200، حيث تفتقر وحدات معالجة الرسوميات الاستهلاكية إلى ذاكرة الوصول العشوائي للرسوميات (VRAM) ومعدل الإنتاج اللازمين.
كم تكلفة استخدام Qwen3-Next-80B-A3B عبر API من Novita AI؟
يتم محاسبة استخدام API لـ Qwen3-Next-80B-A3B بشكل شفاف بسعر 0.15 دولار لكل مليون رمز إدخال و 1.50 دولار لكل مليون رمز إخراج على Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.



