

當複雜智能體編碼、長推理或多步驟困難任務的輸出品質比單位成本更重要時,請選擇 DeepSeek V4 Pro;當你需要相同的 1,048,576 token 上下文視窗、相同的 393,216 token 最大輸出限制,以及一條成本更低的 API 路徑來應付高流量或延遲敏感工作負載時,請選擇 DeepSeek V4 Flash。兩種模型都可透過 Novita AI 的 OpenAI 相容 LLM API 取得,但它們的定價與定位指向不同的生產角色。
DeepSeek V4 Pro vs DeepSeek V4 Flash:快速比較
模型適用場景
| 欄位 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| 最佳用途 | 複雜智能體工作流程、專業級軟體開發、困難推理 | 高並發應用、輕量工作負載、成本敏感的生產流量 |
| 決策原則 | 當失敗成本高時使用 | 當請求量或延遲更關鍵時使用 |
API 與限制
| 欄位 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| 模型 ID | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| 可用性 | 可用,無伺服器 LLM | 可用,無伺服器 LLM |
| 上下文視窗 | 1,048,576 tokens | 1,048,576 tokens |
| 最大輸出 tokens | 393,216 tokens | 393,216 tokens |
| 輸入 / 輸出模態 | 文字輸入,文字輸出 | 文字輸入,文字輸出 |
| API 請求路徑 | OpenAI 相容的聊天補全 | OpenAI 相容的聊天補全 |
價格概覽
| 欄位 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| 輸入定價 | 每 1M tokens $1.60 | 每 1M tokens $0.14 |
| 輸出定價 | 每 1M tokens $3.20 | 每 1M tokens $0.28 |
| 快取讀取定價 | 每 1M tokens $0.135 | 每 1M tokens $0.028 |
功能備註
| 欄位 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| 列舉功能 | 無伺服器、函數呼叫、結構化輸出、推理 | 無伺服器、函數呼叫、結構化輸出、推理 |
| 實務提示 | 將最困難的提示路由至 Pro | 使用 Flash 處理可擴展的基線流量 |
Pro 和 Flash 之間有什麼改變?
最重要的改變不是上下文長度或基本的聊天補全存取權。在 Novita AI 上,兩種模型都列出了 1,048,576 token 上下文視窗、393,216 最大輸出 tokens、文字輸入、文字輸出、無伺服器交付、函數呼叫、結構化輸出和推理支援。
實際差異在於定位和價格。DeepSeek V4 Pro 模型頁面將 Pro 描述為適用於複雜智能體工作流程、專業軟體開發、推理密集型評估和困難編碼任務的旗艦選項。DeepSeek V4 Flash 模型頁面則將 Flash 定位為適用於快速、經濟的 API 服務、高並發、低延遲和大規模輕量工作負載的輕量選項。
這為開發者提供了一個明確的路由模式:
- 當一個錯誤答案的成本超過額外 token 價格時使用 Pro:自動化程式碼變更、長時間除錯會話、倉庫級分析、規劃和困難推理。
- 當成本和回應速度塑造產品體驗時使用 Flash:聊天輔助、初步分類、摘要、提取、路由和重複的生產呼叫。
- 當你的應用程式能夠將「困難提示」與「標準提示」分離時,可以同時使用兩者。Flash 可以處理大部分基線流量,而 Pro 則保留用於升級或高階工作流程。
如果你已經閱讀過 DeepSeek V4 Flash 上線指南,請將此頁面視為決策層:它關於何時選擇每個 API,而不是重複上線設定。
Novita AI 上的價格比較
目前 Novita AI 模型頁面的定價顯示兩種模型之間存在巨大的成本差距:
DeepSeek V4 Pro 定價
| 欄位 | 數值 |
| 輸入價格 | 每 1M tokens $1.60 |
| 輸出價格 | 每 1M tokens $3.20 |
| 快取讀取輸入價格 | 每 1M tokens $0.135 |
| 使用時機 | 複雜推理、智能體編碼或高失敗成本任務 |
DeepSeek V4 Flash 定價
| 欄位 | 數值 |
| 輸入價格 | 每 1M tokens $0.14 |
| 輸出價格 | 每 1M tokens $0.28 |
| 快取讀取輸入價格 | 每 1M tokens $0.028 |
| 使用時機 | 高流量、延遲敏感或成本敏感的生產流量 |
對於輸入和輸出 tokens,Pro 的價格約為 Flash 列示價格的 11.4 倍。這並不表示 Flash 總是更好的商業選擇;而是表示 Pro 應該用在其預期品質優勢足以證明較高單位成本合理的地方。
一個簡單的生產策略效果很好:
- 對於具有明確指令、短評估標準和低失敗成本的高流量提示,預設使用 Flash。
- 當使用者要求困難編碼、多步驟推理、長上下文合成或高風險答案時,升級至 Pro。
- 在改變生產路由之前,先對一組代表性的提示進行影子測試。比較輸出品質、重試次數、使用者接受度、總 tokens、延遲和失敗案例,而不僅僅是每個 token 的價格。
定價可能變動,因此在發布定價敏感的工作流程或報價前,請檢查當前的模型頁面。
基準測試與性能訊號
來自 Artificial Analysis 的基準測試數據顯示,品質導向與吞吐量導向的使用之間存在明顯的取捨。DeepSeek V4 Pro 報告了較高的智慧分數,而 DeepSeek V4 Flash 則報告了更強的速度和成本指標。這些結果應被視為決策輸入,而非通用排名。
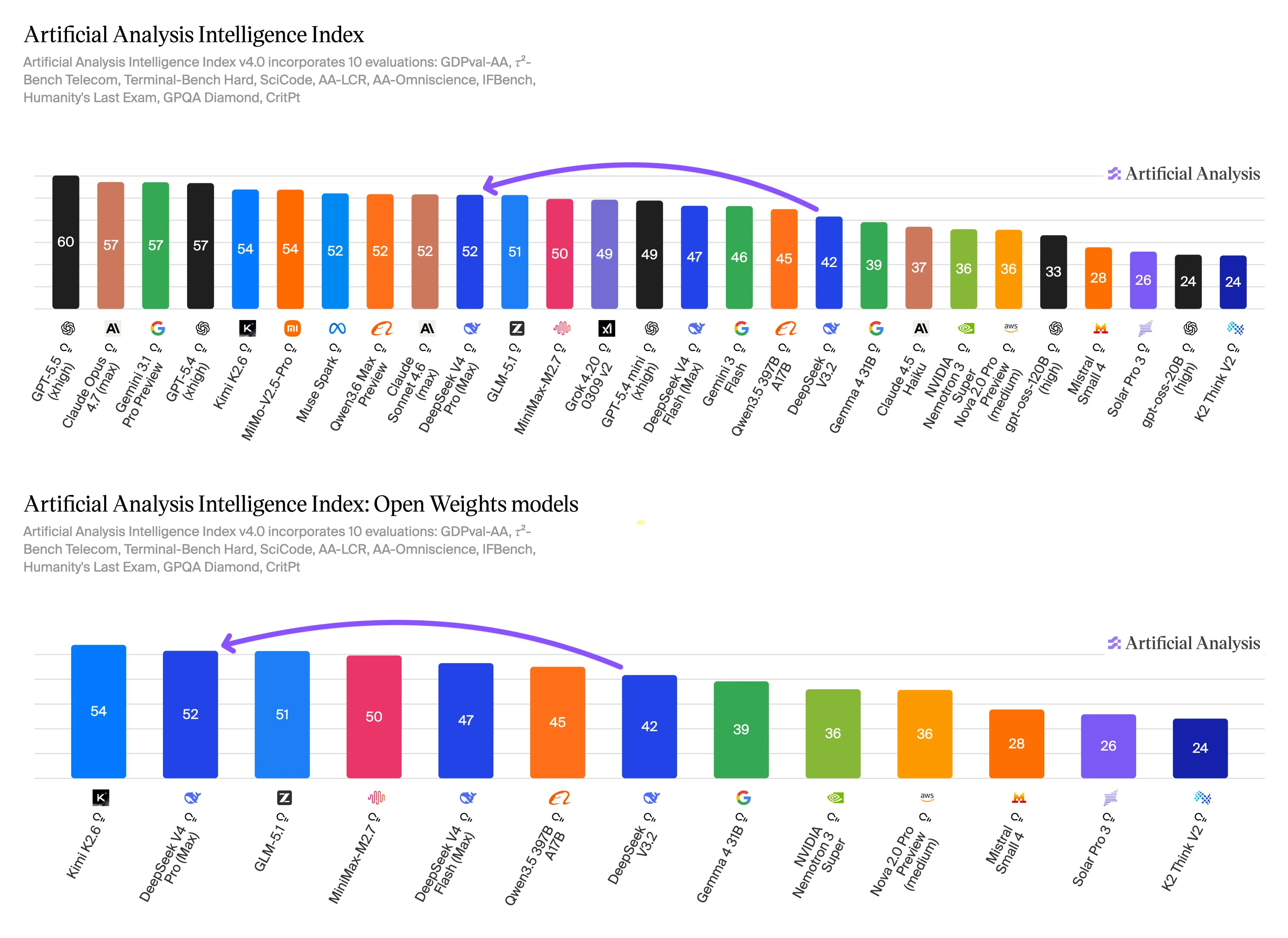
Intelligence Index v4.0 涵蓋了智能體工作、終端與編碼任務、長上下文推理、知識、指令遵循、科學推理及相關品質測試的評估。此評估範圍在此相關,因為這些類別與選擇 Pro 的主要原因重疊:更困難的多步驟工作,其中較高品質的答案可以證明較高單位成本的合理性。
Flash 在相同的基準測試規模上仍具競爭力,其速度和價格設定使其成為運行許多相似提示的生產路徑的實用選項。使用 Flash 進行初步摘要、分類、提取、支援輔助或路由。當提示模糊、需要更深層推理、涉及大型程式碼庫或具有高失敗成本時,升級至 Pro。
在將一個模型替換為另一個模型之前,請在兩個 API 上運行你自己的提示集。追蹤接受的答案、重試率、延遲、總 token 成本、結構化輸出可靠性和工具呼叫行為。基準測試建議從哪裡開始,但生產路由應遵循你的實際工作負載。
如何在 Novita AI 上存取兩個 API
兩個模型都使用 Novita AI 的 OpenAI 相容 LLM API。模型 ID 是你在 Pro 和 Flash 之間切換時需要更改的欄位。
步驟 1:確認模型 ID 和可用性
在部署前使用當前的模型頁面:
- DeepSeek V4 Pro API 與 Playground:
deepseek/deepseek-v4-pro - DeepSeek V4 Flash API 與 Playground:
deepseek/deepseek-v4-flash
Novita AI 列出模型端點也可用於檢查可用的模型物件和欄位,例如模型 ID、定價欄位、標題、描述和上下文大小。
步驟 2:使用 OpenAI 相容的基礎 URL
Novita AI 的 API 參考文件列出了 OpenAI 相容端點:
https://api.novita.ai/openai
對於聊天補全,端點為:
https://api.novita.ai/openai/v1/chat/completions
請求需要在 Authorization 標頭中包含 bearer token。
步驟 3:針對兩個模型運行相同的提示
從一個代表實際流量的小型評估集開始:簡單提示、長上下文提示、編碼提示、工具型提示、提取提示和容易失敗的提示。
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "針對 LLM 聊天 API,總結批次處理與串流之間的取捨。"
}
],
"max_tokens": 500,
"temperature": 0.2
}'
然後只切換模型 ID:
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "針對 LLM 聊天 API,總結批次處理與串流之間的取捨。"
}
],
"max_tokens": 500,
"temperature": 0.2
}'
步驟 4:比較生產訊號
針對每個提示類別,記錄:
- 完成品質與正確性
- 輸出格式可靠性
- 工具或函數呼叫行為(如果你的應用程式依賴它)
- 總輸入和輸出 tokens
- 在預期並發下的延遲
- 重試率和降級率
- 使用者可見的接受率或編輯率
如果你計劃將標準請求路由至 Flash,並將升級請求路由至 Pro,這點尤其重要。
最佳使用案例:何時選擇每個模型
選擇 DeepSeek V4 Pro 處理複雜工作
當任務需要更深層推理或更強的智能體行為時使用 Pro:
- 程式碼庫分析、程式碼審查和重構計劃
- 需要跨多個檔案推理的自主編碼智能體
- 長上下文除錯或事件分析
- 高失敗成本的多步驟規劃
- 數學、STEM 或競賽程式設計風格的推理
- 答案品質比單位成本更重要的高階使用者工作流程
當讀者想要更多關於將 Pro 用於長上下文工作負載的細節時,DeepSeek V4 Pro 長上下文指南是更好的內部後續閱讀。
選擇 DeepSeek V4 Flash 處理可擴展的產品流量
當工作負載受益於較低的單位價格和更輕量級的服務時使用 Flash:
- 高流量聊天和輔助功能
- 分類、路由、提取和摘要
- 初步程式碼解釋或文件任務
- 具有許多相似提示的支援工作流程
- 可用 Flash 降級至 Pro 的後台處理
- 延遲和成本是核心使用者體驗限制的應用程式
對於選擇 Flash 作為預設模型的開發者來說,DeepSeek V4 Flash on Novita AI 指南是自然的配套設定。
避免盲目切換
不要僅僅因為兩個模型共享上下文長度和端點存取就進行切換。在遷移之前,請驗證新模型是否保留了:
- 在生產範例上的提示行為
- JSON 或結構化輸出形狀
- 工具呼叫引數和失敗行為
- 在預期並發下的延遲
- 考慮重試和較長輸出後的總成本
- 護欄、拒絕行為和邊緣情況處理
對於許多系統而言,最佳答案不是 Pro 或 Flash,而是同時使用兩者的路由策略。
開發者遷移注意事項
如果你正在兩個模型之間遷移,模型 ID 是第一個需要更新的欄位:
| 方向 | 變更 |
| Flash 到 Pro | 對於較困難的提示,將 deepseek/deepseek-v4-flash 替換為 deepseek/deepseek-v4-pro。 |
| Pro 到 Flash | 對於成本敏感的基線提示,將 deepseek/deepseek-v4-pro 替換為 deepseek/deepseek-v4-flash。 |
| 混合路由 | 保留兩個 ID,並根據任務難度、帳戶層級或評估分數進行路由。 |
遷移檢查清單:
- 在 Novita AI 模型頁面上確認當前模型的可用性。
- 在改變成本假設之前確認當前定價。
- 保持與本指南範例相同的基礎 URL 和聊天補全端點。
- 運行一組代表性的提示回歸測試。
- 按任務類型比較輸出品質,而不僅僅是總勝率。
- 追蹤 token 使用量、延遲、重試次數和降級率。
- 保留一個可將流量切換回先前模型 ID 的回滾計劃。
最終建議
對於大多數團隊來說,DeepSeek V4 Flash 應該是高流量生產環境中第一個測試的模型,因為它列出了遠低於 Pro 的輸入、輸出和快取讀取定價,同時在 Novita AI 上保持了與 Pro 相同的可見上下文和最大輸出限制。
DeepSeek V4 Pro 應保留用於那些品質、推理深度或智能體編碼可靠性的商業價值高於較高 token 價格的任務。如果你的產品同時包含常規和困難的提示,請將常規請求路由至 Flash,並在評估確認拆分後將較困難的請求升級至 Pro。
常見問題
DeepSeek V4 Pro 和 DeepSeek V4 Flash 之間的主要區別是什麼?
在 Novita AI 上,本指南中使用的可見上下文限制、最大輸出限制、模態和聊天補全請求路徑都是相同的。主要區別在於定位和價格:Pro 是品質優先的選項,適用於複雜推理和智能體編碼;而 Flash 是成本較低的選項,適用於高流量和延遲敏感的用途。
這兩個模型都在 Novita AI 上可用嗎?
是的。Novita AI 有 deepseek/deepseek-v4-pro 和 deepseek/deepseek-v4-flash 的模型頁面,並且兩者都被列為無伺服器 LLM 模型。
DeepSeek V4 Flash 比 DeepSeek V4 Pro 便宜嗎?
截至 2026 年 6 月 9 日,目前的 Novita AI 模型頁面列出 Flash 的價格為每 1M 輸入 tokens $0.14 和每 1M 輸出 tokens $0.28,而 Pro 的價格為每 1M 輸入 tokens $1.60 和每 1M 輸出 tokens $3.20。
我應該從 Flash 升級到 Pro 嗎?
僅在 Flash 無法滿足你在複雜編碼、長上下文推理或高失敗成本任務上的品質目標時,將特定工作負載升級至 Pro。在比較真實提示、總成本、延遲和失敗案例之前,不要升級所有流量。
兩個模型可以使用相同的聊天補全端點嗎?
是的。Novita AI 的模型頁面為兩個模型都列出了 chat/completions,API 參考文件記錄了位於 /openai/v1/chat/completions 的 OpenAI 相容聊天補全端點。
基準測試是否證明 Pro 總是優於 Flash?
不是。報告的基準測試數據顯示 Pro 具有較高的 Intelligence Index 分數,而 Flash 則顯示較高的輸出速度、較低的首個 token 延遲和較低的列示 token 價格。對於較困難的推理或編碼任務使用 Pro,並測試 Flash 用於高流量產品流量。



