

随着小型企业寻求采用 AI 来处理文档解析、客户支持、视觉自动化或编码辅助等任务,在 Qwen3-VL-235B-A22B 和 GLM 4.5V 等强大的开源模型之间做出选择可能会让人不知所措。它们的性能、成本、可访问性和部署难度之间究竟有什么区别?
本文将从 架构、应用能力、性能基准、定价和访问方法 等方面进行对比,为您提供清晰的决策路径,帮助您找到最适合业务的模型。无论您是在构建智能工作流、本地部署还是调用 API,本指南都能帮助您做出明智、自信的选择。
Qwen3-VL-235B-A22B 和 GLM 4.5V 能为您的企业真正做些什么?
想知道哪个模型最适合您的工作流程?
Qwen3-VL-235B-A22B 和 GLM 4.5V 均在 Novita AI 上提供免费在线演示!
| 应用领域 | Qwen3-VL-235B-A22B | GLM 4.5V | 谁胜出 |
|---|---|---|---|
| GUI 交互 | 操作 PC/手机界面,理解界面元素,调用工具。 | 支持屏幕阅读和基本桌面操作。 | 可能持平 |
| 视觉转代码生成 | ✅ 将截图/视频转换为 HTML、CSS、JS、Draw.io 图表。 | ❌ 未披露视觉转代码能力。 | Qwen 胜 |
| 3D 与空间推理 | ✅ 高级:识别物体位置、遮挡、视角;支持 3D 接地。 | ⚠️ 处理跨图像的空间布局,无 3D 接地或具身 AI。 | Qwen 胜 |
| 视频理解 | ✅ 处理长达数小时的视频,支持 256K–1M token 上下文;细粒度时间分析。 | ⚠️ 支持事件分割,但可能受限于 66K token 窗口。 | Qwen 胜 |
| 视觉识别范围 | ✅ 训练为“识别一切”:名人、动漫、珍稀物种、地标、标志、古代文本。 | ⚠️ 场景分析能力强,但未声称识别小众/珍稀实体。 | Qwen 胜 |
| OCR/文本提取 | ✅ 32 种语言,在模糊/倾斜下表现稳健,支持稀有和古代字符及结构化布局。 | ⚠️ 能良好提取长文档,但缺乏语言和稀有文本广度。 | Qwen 胜 |
| 文本理解 | ✅ 可与纯 LLM 媲美;流畅的视觉-文本融合,无理解损失。 | ✅ 强大的生成器,配有“推理模式”开关;语言质量高。 | 可能持平 |
| 易用性 | 通过 API 或演示提供。 | 通过 API 或演示以及支持图像、PDF、视频等的 桌面助手 提供。 | GLM 胜 |
Qwen3-VL-235B-A22B 和 GLM 4.5V 在架构上有何不同?
Qwen3-VL 作为“重量级”选项,优先考虑规模和信息容量:其 235B 总参数、256K(可扩展至 1M)token 上下文窗口以及专门的推理变体使其成为大规模任务的理想选择。
相比之下,GLM 4.5V 强调在不牺牲性能的情况下实现灵活性和效率。其更紧凑的 106B 参数设计、128K token 上下文窗口以及带有可切换“思维模式”的统一模型在速度和深度之间取得了平衡。
| 对比维度 | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|
| 模型大小与 MoE 架构 | 总参数:235B 每次输入激活参数:22B |
总参数:106B 每次输入激活参数:12B |
| 上下文窗口容量 | 原生:256K tokens 可扩展至:1M tokens |
原生:128K tokens |
| 推理与指令模式 | 支持 思维模式 开关,允许用户在快速响应和深度推理之间进行平衡。 | 支持 思维模式 开关,允许用户在快速响应和深度推理之间进行平衡。 |
| 视觉处理 | 基于 ViT 的编码器 + 文本解码器 增强:Interleaved-MRoPE(视频推理),融合视觉特征 |
基于 ViT 的编码器 + 文本解码器 增强:用于视觉-语言融合的清洁适配器 |
| 速度 | 延迟在 1.8-2 秒 | 延迟在 0.3-1.5 秒 |
| 硬件要求 | 8 块 NVIDIA H200 GPU。 | 在 16 位精度下,单块 80GB GPU(如一块 NVIDIA A100/H100 80GB) |
那么,哪个模型性能更好:Qwen3-VL-235B-A22B 还是 GLM 4.5V?
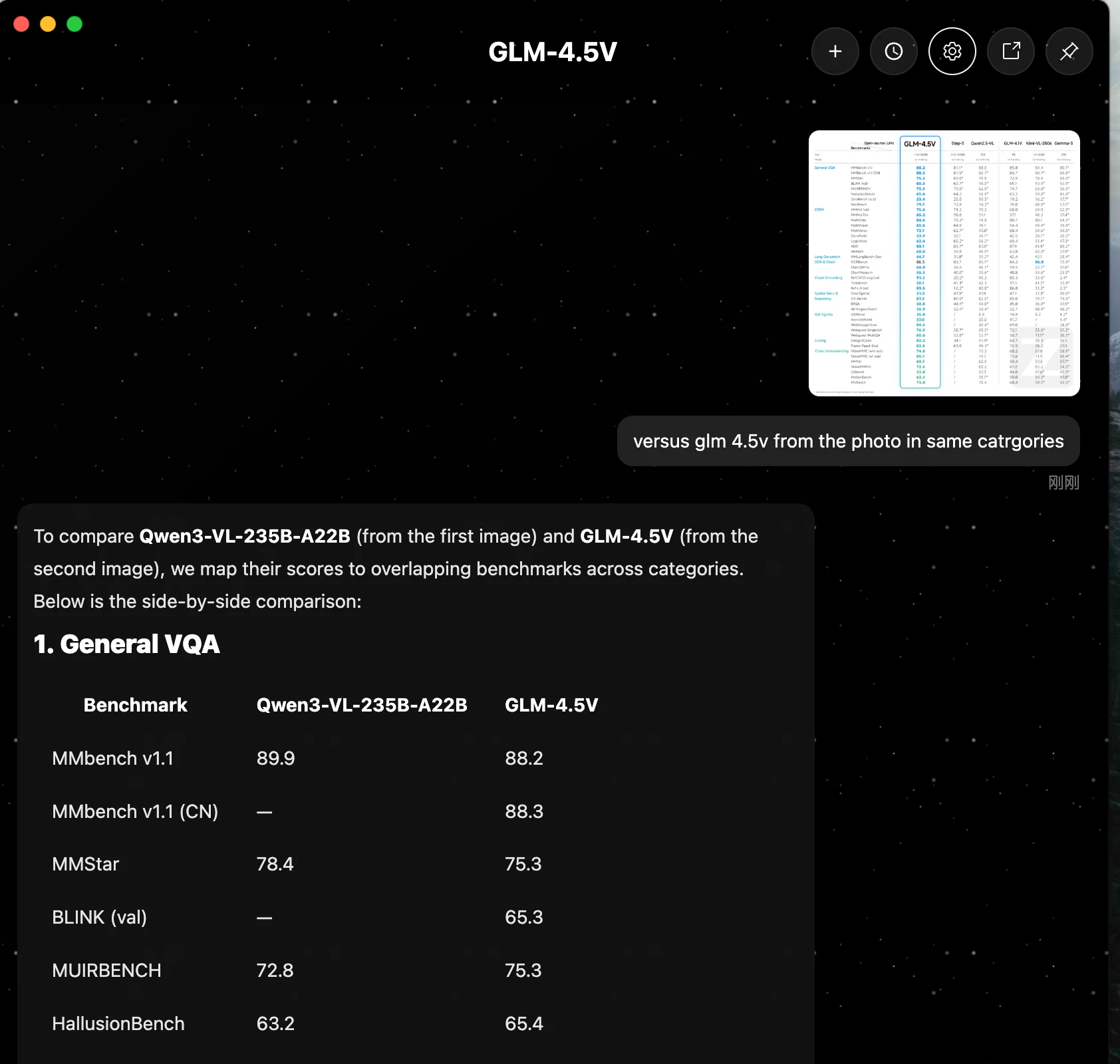
Qwen3-VL-235B-A22B 在核心推理、文档处理和代码生成方面通常处于领先地位。GLM 4.5V 在多项任务中表现接近,但在所列基准测试中均未超越 Qwen。
| 类别 | 基准测试 | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|---|
| 1. 通用 VQA | MMbench v1.1 | 89.9 | 88.2 |
| MMStar | 78.4 | 75.3 | |
| MUIRBENCH | 72.8 | 75.3 | |
| HallusionBench | 63.2 | 65.4 | |
| 2. STEM 与谜题 | MMMU (val) | 78.7 | 75.4 |
| MMMU Pro | 68.1 | 65.2 | |
| MathVista | 84.9 | 84.6 | |
| MathVision | 66.5 | 65.6 | |
| MathVerse | 72.5 | 72.1 | |
| AI2D | 89.7 | 88.1 | |
| 3. 长文档与 OCR/图表 | MMLongBench-Doc | 57.0 | 44.7 |
| OCRBench | 920.0* | 86.5 | |
| 4. 编码 | Design2Code | 92.0 | 82.2 |
| 5. 视频理解 | VideoMME (w/o sub) | 79.2 | 74.6 |
您还可以使用 Novita AI 的 API 密钥 免费 访问 GLM 的桌面助手——无需付款,与官方网站不同!
该桌面应用专为 GLM 系列多模态模型设计(GLM-4.5V,兼容 GLM-4.1V),支持与文本、图像、视频、PDF、PPT 等进行交互式对话。它连接到 GLM 多模态 API,可在各种场景下实现智能服务。
设置:
模型名称:zai-org/glm-4.5v
API URL:https://api.novita.ai/openai
端点:/v1/chat/completions
API 密钥:来自 Novita AI
如何廉价且快速地访问 Qwen3-VL-235B-A22B 和 GLM 4.5V?
Novita AI 提供 Qwen3-VL API,支持 131K 上下文窗口,输入每百万 token 0.98 美元,输出每百万 token 3.95 美元。同时提供 GLM-4.6V API,支持 208K 上下文窗口,输入每百万 token 0.60 美元,输出每百万 token 2.20 美元,支持结构化输出和函数调用。
1. Web 界面(初学者最简单)
2. API 访问(面向开发者)
步骤 1:登录并访问模型库
登录您的账户,点击 模型库 按钮。

步骤 2:选择您的模型
浏览可用选项,选择适合您需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的功能。
步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按照图中指示复制 API 密钥。

步骤 5:安装 API
使用特定于您编程语言的包管理器安装 API。
安装后,将所需的库导入到您的开发环境中。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是针对 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. 本地部署(高级用户)
要求:
- Qwen3-VL-235B-A22B:8 块 NVIDIA H200 GPU。
- GLM 4.5V:在 16 位精度下,单块 80GB GPU(如一块 NVIDIA A100/H100 80GB)
安装步骤:
- 从 HuggingFace 或 ModelScope 下载模型权重
- 选择推理框架:支持 vLLM 或 SGLang
- 遵循部署指南,参考官方 GitHub 仓库
4. 集成
使用 CLI,如 Trae、Claude Code、Qwen Code
如果您想使用 Novita AI 的顶级模型(如 Qwen3-Coder、Kimi K2、DeepSeek R1)在本地环境或 IDE 中进行 AI 编码辅助,过程很简单:获取 API 密钥、安装工具、配置环境变量,然后开始编码。
有关详细的设置命令和示例,请查看官方教程:
- Trae:如何在 IDE 中访问 AI 模型的分步指南
- Claude Code:如何在 Windows、Mac 和 Linux 上的 Claude Code 中使用 Kimi-K2
- Qwen Code:如何在 Qwen Code 中使用 OpenAI 兼容 API(60 秒设置!)
使用 OpenAI Agents SDK 构建多智能体工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建高级多智能体系统:
- 即插即用: 在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支持交接、路由和工具使用: 设计能够委派、分类或运行函数的智能体,全部由 Novita AI 的模型驱动。
- Python 集成: 只需将 SDK 端点设置为
https://api.novita.ai/v3/openai并使用您的 API 密钥。
在第三方平台上连接 API
OpenAI 兼容 API: 享受与 Cline 和 Cursor 等工具的无缝迁移和集成,这些工具专为 OpenAI API 标准设计。
Hugging Face: 通过 Novita AI 端点在 Spaces、管道或 Transformers 库中使用模型。
智能体与编排框架: 通过官方连接器和逐步集成指南,轻松将 Novita AI 与 Continue、AnythingLLM、LangChain、Dify 和 Langflow 等合作伙伴平台连接。
Qwen3-VL-235B-A22B 在高级推理、视觉编码、多语言 OCR 和长上下文处理方面表现出明显优势,使其成为处理高要求工作流和多模态任务的首选。
GLM 4.5V 虽然在原始性能上稍显逊色,但更加轻量,并且 提供桌面助手,推理速度更快,即插即用性更广——尤其适合开发者和初创企业。对于大多数用例,Qwen3-VL-235B-A22B 适合深度与复杂性,而 GLM 4.5V 在易用性和灵活性方面表现卓越。
常见问题解答
GLM 4.5V 可以离线或在浏览器外使用吗?
是的,GLM 4.5V 支持 免费桌面助手(通过 Novita AI),允许用户在本地与文本、图像、视频和 PDF 交互——这是 Qwen3-VL-235B-A22B 原生不提供的功能。
试用 Qwen3-VL-235B-A22B 和 GLM 4.5V 最便宜、最快的方式是什么?
Qwen3-VL API:131K 上下文,输入每百万 token 0.98 美元,输出每百万 token 3.95 美元
GLM-4.6V API:208K 上下文,输入每百万 token 0.60 美元,输出每百万 token 2.20 美元,支持结构化输出和函数调用
在基准评估中,哪个模型表现更好——Qwen3-VL-235B-A22B 还是 GLM 4.5V?
Qwen3-VL-235B-A22B 在 STEM 推理(如 MMMU)、长文档分析(MMLongBench-Doc)、OCR(OCRBench)和编码(Design2Code)等类别中持续获得比 GLM 4.5V 更高的分数。GLM 4.5V 表现良好,但在任何列出的基准测试中均未超越 Qwen。
Novita AI 是一个 AI 云平台,为开发者提供使用简单 API 部署 AI 模型的简易方式,同时还提供经济实惠且可靠的 GPU 云用于构建和扩展。



