

选择开源模型的推理 API 提供商,不仅仅取决于谁能提供该模型——更关键的是,哪个提供商能以最低成本、最广泛的模型选择,提供最佳的输出质量。同一个模型在不同平台上调用,结果可能显著不同,价格甚至相差 5 倍。本文从三个实际维度——模型目录覆盖范围、定价和实际基准输出质量——对五家领先提供商(Novita AI、Together AI、Fireworks AI、DeepInfra 和 Groq)进行横向比较。
为什么推理提供商的选择如此重要
当你通过第三方 API 调用开源模型时,底层权重是相同的——但不同提供商的服务基础设施、量化选择和优化堆栈差异显著。这一点的影响远超大多数开发者的认知。
以 OpenAI 的旗舰开放权重模型 gpt-oss-120B(高精度版)为例:不同提供商的输入价格区间为每百万 token 0.05 美元至 0.60 美元——差距高达 12 倍。在独立基准测试中,同一模型的输出质量分数也存在可测量的差异。此外,一家提供商在 OpenRouter 上支持 66+ 个模型,而另一家最多只有十几个。这些差异在生产规模下会不断累积,既影响你的月度基础设施账单,也影响用户收到的输出质量。
本次比较的五家提供商概览
在深入数据之前,先简要了解各家提供商:
Novita AI 是一个 AI 与 Agent 云平台,帮助开发者和初创公司以高性能、高可靠性和高成本效益构建、部署和扩展模型与 Agent 应用。它覆盖了广泛的开源模型——包括 GLM、MiniMax、Kimi、Qwen、DeepSeek、OpenAI 开放权重的 gpt-oss 系列、Meta 的 Llama 系列等——全部通过一个兼容 OpenAI 的端点提供。
Together AI 是一家成熟的推理提供商,生态系统集成能力强,在使用 LangChain、LlamaIndex 等框架的团队中很受欢迎。它提供主流开源模型的不错选择,输出速度具有竞争力。
如果将 Together 视为重要候选,那么专门的 Together AI vs Novita AI 对比文章会更详细地涵盖定价、API 兼容性、批处理作业、专用端点和生产工作流权衡。
Fireworks AI 专注于低延迟推理,定位为延迟敏感型应用服务。其模型目录更具选择性,优先考虑生产就绪的模型而非广度。对于希望将其定位与 Novita AI 的模型 API、Agent Sandbox、批量推理和 GPU Cloud 进行比较的团队,请参阅专门的 Fireworks AI 替代方案 指南。
DeepInfra 提供广泛的模型目录且定价始终具有竞争力,是追求成本效益且看重模型多样性的常见选择。
Groq 专为速度而生,使用定制 LPU 硬件提供极高的 token 吞吐量。其模型目录有意保持较小规模,围绕最能发挥 Groq 硬件架构优势的模型进行优化。
![]()
各提供商的模型目录有多广?
可用模型的广度决定了你是可以将基础设施整合到一家提供商,还是需要为不同用例维护多个 API 密钥。
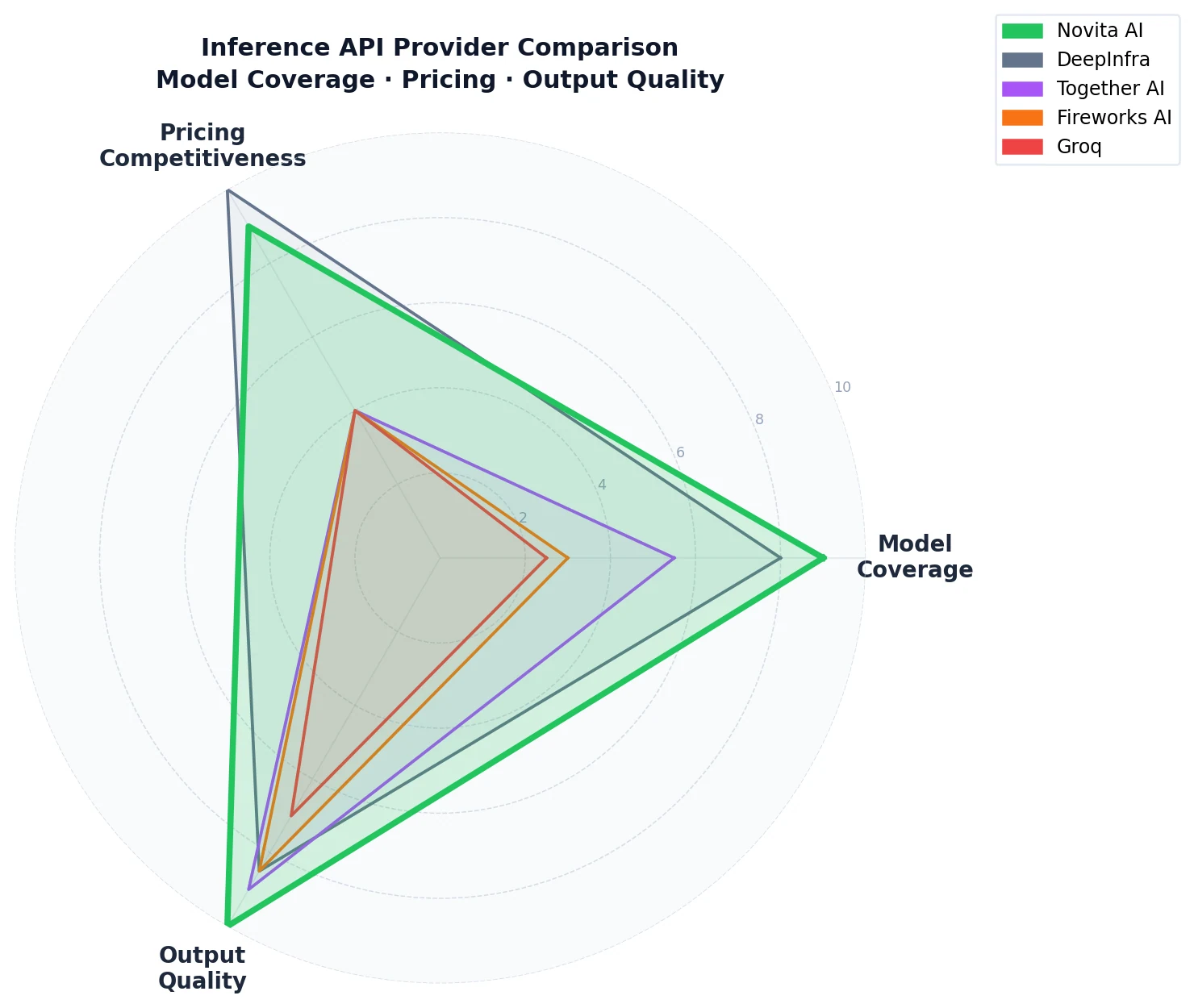
OpenRouter 的提供商排行榜——按每日 token 量排序——直接反映了哪些推理提供商处理的生产流量最多。在该排名中,DeepInfra 之上的 12 家提供商大多是第一方模型提供商(小米、阿里云、Google Vertex、Amazon Bedrock、MiniMax、xAI、OpenAI、StepFun、Google AI Studio、Z.ai)——主要服务于自家模型的公司。排除闭源模型供应商和模型创建者后,Novita AI 在 OpenRouter 上以每日 1358 亿 token、每月 4.6 万亿 token 的流量位列纯第三方推理提供商第一,覆盖 66 个可用模型。
DeepInfra 是最近的竞争对手,每日处理 1036 亿 token,在 OpenRouter 上有 75 个模型。Together AI、Fireworks AI 和 Groq 未进入该排名前列。
OpenRouter 上的模型数量反映了通过该平台活跃服务的模型。作为对比,Artificial Analysis 跟踪了各提供商 API 端点的模型数:
| **提供商 ** | OpenRouter 上的模型数 |
| Novita AI | 66 |
| DeepInfra | 75 |
| Together AI | 28 |
| Groq | 8 |
| Fireworks AI | 7 |
66 个模型的数据反映的是 Novita AI 在 OpenRouter 上的上架情况。Novita AI 的完整 API 目录目前支持 200+ 个模型,包括尚未在 OpenRouter 上提供的模型。完整列表请访问 novita.ai/models。
定价对比:Novita AI 的明显成本优势
我们直接从各提供商官方定价页面获取了 OpenAI gpt-oss 模型的价格——这是 OpenAI 发布的首批开放权重模型(2025 年 8 月,Apache 2.0 许可),现在已广泛被各大推理提供商支持。
gpt-oss-120B(高精度版)——各提供商定价
| **提供商 ** | ** 输入(每百万Token)** | ** 输出(每百万Token)** |
| Novita AI | $0.05 | $0.25 |
| DeepInfra | $0.04 | $0.19 |
| Together AI | $0.15 | $0.60 |
| Fireworks AI | $0.15 | $0.60 |
| Groq | $0.15 | $0.60 |
gpt-oss-20B(低精度版)——各提供商定价
| **提供商 ** | ** 输入(每百万Token)** | ** 输出(每百万Token)** |
| Novita AI | $0.04 | $0.15 |
| Together AI | $0.05 | $0.20 |
| Fireworks AI | $0.07 | $0.30 |
| Groq | $0.08 | $0.30 |
| DeepInfra | N/A | N/A |
*价格为 2026 年 3 月数据,来源于各提供商官方定价页面。
相同模型的价格在不同提供商之间差异高达 5.9 倍。对于 gpt-oss-20B,Novita AI 是最便宜的选择,混合价格每百万 token 仅 0.07 美元。对于 gpt-oss-120B,Novita AI 略高于 DeepInfra,但远低于 Together AI、Fireworks 和 Groq——这三家均收取 0.26 美元的混合费率,几乎是 Novita 价格的 2.6 倍。
生产规模下的实际影响
假设一个团队每月在 gpt-oss-120B(高精度版)上运行 1 亿输入 token + 3300 万输出 token:
| **提供商 ** | ** 月度成本 ** | ** 与 Novita AI 对比** |
| Novita AI | 约 $10 | — |
| DeepInfra | 约 $8 | −$2 |
| Together AI | 约 $26 | +$16 |
| Fireworks AI | 约 $26 | +$16 |
| Groq | 约 $26 | +$16 |
仅此一个模型,从 Together AI、Fireworks 或 Groq 切换到 Novita AI 每月可节省约 190 美元。在一个包含 DeepSeek、Llama、GLM 和 Qwen 变体等模型的多模型生产栈中,节省成本会按比例放大。您可以在 Novita AI 定价页面 验证完整模型目录的最新价格。
输出质量分数:并非所有提供商服务模型都同样出色
定价只是故事的一半。Artificial Analysis 独立基准测试了每个提供商端点的实际输出质量——跨提供商运行相同提示,测量真实的响应质量,而不仅仅是吞吐量或可用性。
对于 gpt-oss-120B(高精度版)而言,结果明确无误。在 GPQA Diamond(科学知识与推理,N=16 次独立运行)评估的五家提供商中,Novita AI 得分最高:
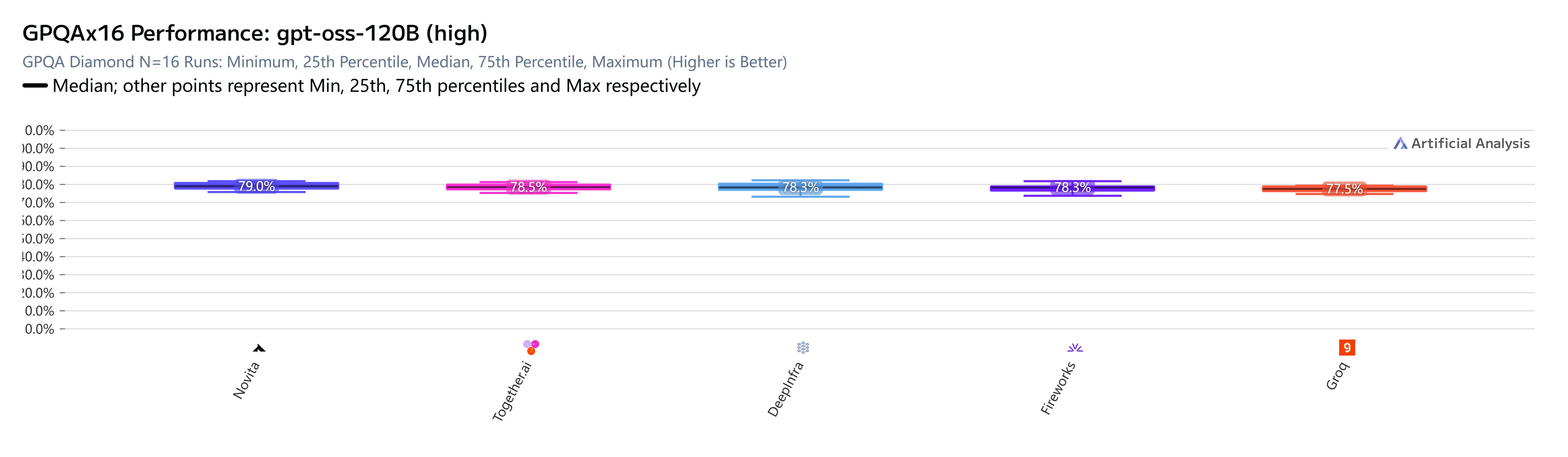
虽然乍看之下 GPQA 分数差距不大——79.0% 对比 77.5%——但这些是在一个设计为高难度的基准测试上,经过 16 次独立运行得出的中位数分数。在此难度级别上,1.5 个百分点的差异绝非微不足道。它反映了各提供商服务栈在处理模型推理链时的真实差异。
对于推理密集型工作负载——Agent 管道、代码生成、复杂问答——使用 Novita AI 不仅支付更少,而且能获得可测量更优的输出。
根据用例选择合适的提供商
选择 Novita AI,如果:
- 你需要一个 API 一站式覆盖广泛的开源模型——包括前沿模型、OpenAI 开放权重和 Meta Llama
- 规模化下的成本效益是优先考虑项——尤其是在 120B+ 参数级别
- 你的工作负载涉及推理、Agent 或数学——输出质量差异会不断累积
- 你需要生产级可靠性,且背后是第三方推理提供商中最高的每日 token 量
选择 Groq,如果:
- 原始 token/秒吞吐量是首要需求
- 你正在构建延迟敏感的交互式应用,且使用固定的小型模型集
选择 Together AI,如果:
- 你的技术栈已与 LangChain、LlamaIndex 或类似框架集成
- 你希望在速度和适度模型目录之间取得平衡
选择 DeepInfra,如果:
- 绝对最低的混合价格是唯一标准
- 模型目录广度和输出质量分数是次要考虑
选择 Fireworks AI,如果:
- 最小化首个 token 的延迟时间至关重要,并且你可以在较小的模型选择范围内工作
如何在你的项目中使用 Novita AI
第一步:获取 API Key
- 在 novita.ai 注册
- 进入设置 → API Keys
- 点击创建新 Key 并安全保存——像对待密码一样对待它
第二步:发送你的第一个 API 调用
Novita AI 支持 OpenAI 和 Anthropic 客户端库——只需更新 base URL 和 API Key 即可替换:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
要尝试不同模型,只需更改 model 参数——无需其他配置更改。浏览完整目录请访问 novita.ai/models。
结论
当数据并排展示时,结论清晰:Novita AI 在模型目录广度、竞争性定价和已验证的输出质量方面,在第三方推理提供商中处于领先地位。对于大多数生产工作负载——尤其是涉及推理模型或多模型管道的场景——它提供了强大的整体价值。
Novita AI 现已可用——无需 GPU 设置,无需预留容量,按使用量付费。从上面的代码示例开始,或探索 Novita AI Playground 中的完整模型目录。
Novita AI 是一个 AI 与 Agent 云平台,帮助开发者和初创公司以高性能、高可靠性和高成本效益构建、部署和扩展模型与 Agent 应用。
常见问题
我能否在不重写代码的情况下,从其他推理提供商切换到 Novita AI?
大多数情况下可以。Novita AI 的 API 兼容 OpenAI 和 Anthropic 客户端库。如果你已在使用任一 SDK,切换只需更改 base URL 和 API Key——无需更改提示逻辑、模型调用结构或响应解析。请查看 Novita AI 上对应模型的文档页面,确认其支持的客户端库。关于切换前避免 LLM API 锁定性的完整检查清单,请参阅《如何无锁定切换 LLM API 提供商:平台检查清单》。
为什么同一模型在不同提供商的输出质量会不同?
即使模型权重相同,推理质量也会因各提供商对量化、批处理和服务基础设施的配置不同而有所差异。Artificial Analysis 通过对实时端点进行重复基准测试直接衡量这一点——差异是真实存在的,而非理论上的。
Novita AI 的定价与自托管 gpt-oss-120B 相比如何?
gpt-oss-120B 可单张 80GB GPU(NVIDIA H100 或 AMD MI300X)运行。云 H100 实例成本约为 2-3 美元/小时。按 Novita AI 每百万输入 token 0.05 美元的费率计算,你需要每小时处理约 4000-6000 万输入 token 才能达到基础设施成本盈亏平衡点——因此对于大多数无法维持此恒定吞吐量的团队来说,API 的成本效益要高得多。



