

- Warum die Wahl des Inference-Anbieters wirklich wichtig ist
- Die fünf Anbieter im Vergleich
- Wie breit ist der Modellkatalog jedes Anbieters?
- Preisvergleich: Wo Novita AI einen klaren Kostenvorteil hat
- Ausgabequalitätswerte: Nicht alle Anbieter dienen Modelle gleich gut
- Den richtigen Anbieter für Ihren Anwendungsfall wählen
- So starten Sie mit Novita AI in Ihrem Projekt
- Fazit
Die Wahl eines Inference-API-Anbieters für Open-Source-Modelle dreht sich nicht nur darum, wer das Modell anbietet – es geht darum, welcher Anbieter die beste Ausgabequalität zu den niedrigsten Kosten bei der breitesten Modellauswahl liefert. Das gleiche Modell kann je nach Aufrufort deutlich unterschiedliche Ergebnisse liefern und bis zu 5x mehr kosten. Dieser Artikel vergleicht fünf führende Anbieter – Novita AI, Together AI, Fireworks AI, DeepInfra und Groq – in drei wirklich relevanten Dimensionen: Modellkatalogabdeckung, Preise und reale Benchmark-Ausgabequalität.
Warum die Wahl des Inference-Anbieters wirklich wichtig ist
Wenn Sie ein Open-Source-Modell über eine Drittanbieter-API aufrufen, sind die zugrunde liegenden Gewichte identisch – aber die Serving-Infrastruktur, Quantisierungsoptionen und Optimierungsstacks unterscheiden sich erheblich zwischen den Anbietern. Das ist wichtiger, als die meisten Entwickler glauben.
Betrachten Sie gpt-oss-120B (high), OpenAIs Flaggschiff-Modell mit offenen Gewichten: Die Eingabepreise reichen von 0,05 $ bis 0,60 $ pro 1M Token – eine 12-fache Spanne. Die Ausgabequalitätswerte für genau dasselbe Modell weichen in unabhängigen Benchmarks messbar voneinander ab. Und während ein Anbieter auf OpenRouter 66+ Modelle unterstützt, hat ein anderer nur ein Dutzend. Diese Unterschiede potenzieren sich im Produktionseinsatz und wirken sich sowohl auf Ihre monatliche Infrastrukturrechnung als auch auf die Qualität der Ausgaben für Ihre Nutzer aus.
Die fünf Anbieter im Vergleich
Bevor wir in die Zahlen eintauchen, ein kurzer Überblick über jeden Anbieter:
Novita AI ist eine KI- & Agent-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren. Sie deckt eine breite Palette von Open-Source-Modellen ab – darunter GLM, MiniMax, Kimi, Qwen, DeepSeek, OpenAIs gpt-oss-Serie, Metas Llama-Familie und mehr – alles unter einem OpenAI-kompatiblen Endpunkt.
Together AI ist ein etablierter Inference-Anbieter mit starken Ökosystemintegrationen, beliebt bei Teams, die LangChain, LlamaIndex und ähnliche Frameworks verwenden. Er bietet eine solide Auswahl gängiger Open-Source-Modelle mit wettbewerbsfähigen Ausgabegeschwindigkeiten.
Wenn Together ein ernsthafter Kandidat ist, finden Sie im fokussierten Vergleich Together AI vs Novita AI detailliertere Informationen zu Preisen, API-Kompatibilität, Batch-Jobs, dedizierten Endpunkten und Produktionsworkflow-Kompromissen.
Fireworks AI konzentriert sich auf latenzarme Inferenz und positioniert sich für latenzsensitive Anwendungen. Der Modellkatalog ist selektiver und priorisiert produktionsreife Modelle gegenüber der Breite. Für Teams, die diese Positionierung mit den Modell-APIs, dem Agent Sandbox, Batch-Inferenz und der GPU Cloud von Novita AI vergleichen möchten, siehe den speziellen Leitfaden Fireworks AI alternative.
DeepInfra bietet einen breiten Modellkatalog mit durchweg wettbewerbsfähigen Preisen und ist daher eine häufige Wahl für kostenorientierte Workloads, bei denen große Modellvielfalt geschätzt wird.
Groq ist speziell für Geschwindigkeit ausgelegt und nutzt kundenspezifische LPU-Hardware für extrem hohen Token-Durchsatz. Der Modellkatalog ist bewusst klein gehalten und auf die Modelle optimiert, die am meisten von Groqs Hardware-Architektur profitieren.
![]()
Wie breit ist der Modellkatalog jedes Anbieters?
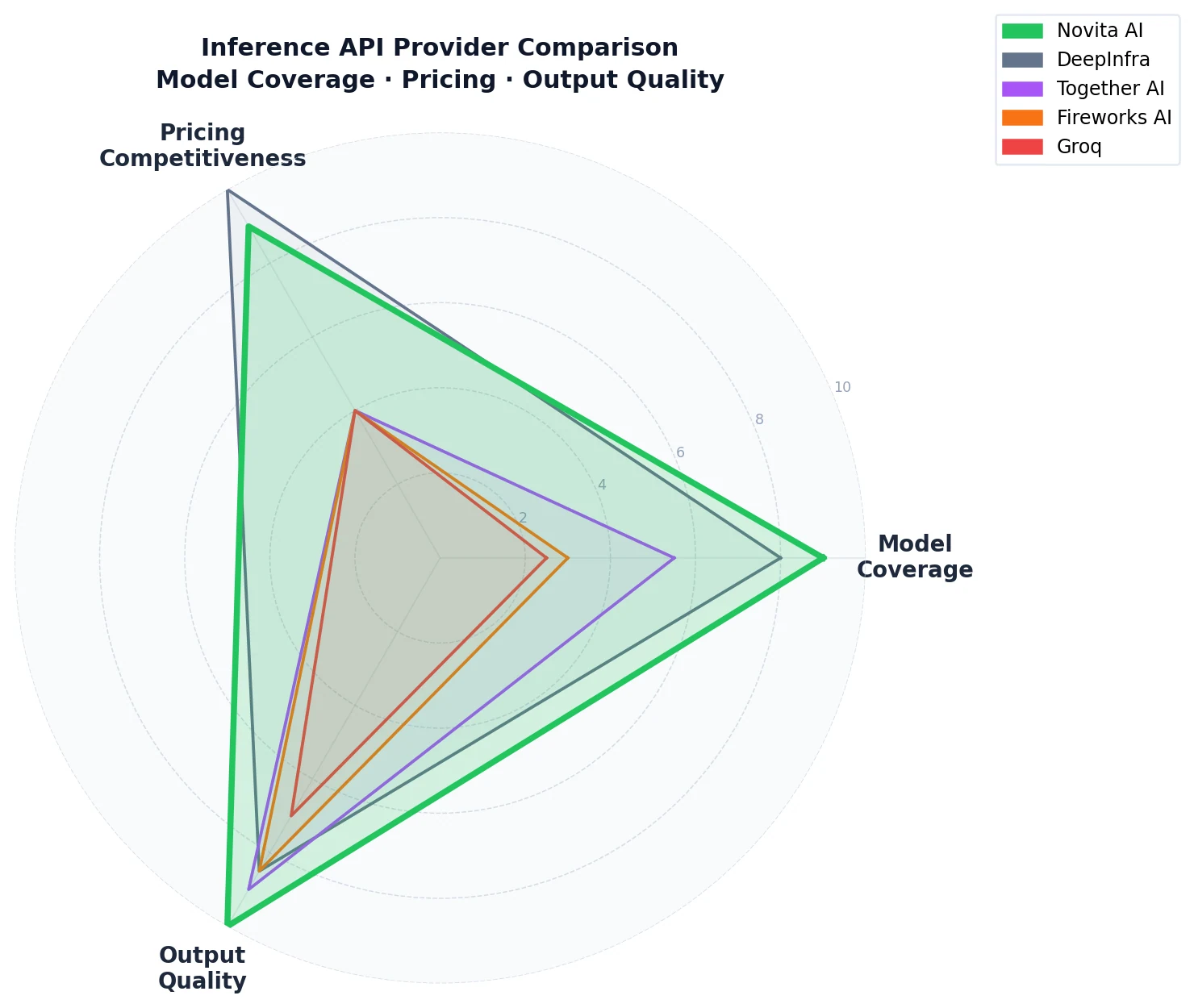
Die Breite der verfügbaren Modelle bestimmt, ob Sie Ihre Infrastruktur auf einen einzigen Anbieter konzentrieren oder mehrere API-Schlüssel für verschiedene Anwendungsfälle vorhalten müssen.
Das OpenRouter-Anbieter-Ranking – sortiert nach täglichem Token-Volumen – gibt ein direktes, reales Signal darüber, welche Inference-Anbieter den meisten Produktionsverkehr verarbeiten. Unter den 12 Anbietern, die in diesem Ranking über DeepInfra aufgeführt sind, handelt es sich bei den meisten um Erstanbieter-Modellanbieter (Xiaomi, Alibaba Cloud, Google Vertex, Amazon Bedrock, MiniMax, xAI, OpenAI, StepFun, Google AI Studio, Z.ai) – Unternehmen, die hauptsächlich ihre eigenen Modelle anbieten. Ohne Closed-Source-Modellanbieter und Modellentwickler belegt Novita AI auf OpenRouter den ersten Platz unter den reinen Drittanbieter-Inference-Anbietern gemessen am täglichen Token-Volumen: 135,8 Milliarden Token pro Tag und 4,6 Billionen Token pro Monat bei 66 verfügbaren Modellen.
DeepInfra ist mit 103,6B Token/Tag und 75 Modellen auf OpenRouter der nächste Mitbewerber. Together AI, Fireworks AI und Groq tauchen in den oberen Positionen dieses Rankings nicht auf.
Die Anzahl der Modelle auf OpenRouter spiegelt die Modelle wider, die aktiv über die Plattform angeboten werden. Zum Vergleich: Artificial Analysis erfasst für den API-Endpunkt jedes Anbieters:
| Anbieter | Modelle auf OpenRouter |
| Novita AI | 66 |
| DeepInfra | 75 |
| Together AI | 28 |
| Groq | 8 |
| Fireworks AI | 7 |
Die Zahl von 66 Modellen bezieht sich auf die Auflistung von Novita AI auf OpenRouter. Der vollständige API-Katalog von Novita AI umfasst derzeit mehr als 200 Modelle, darunter auch Modelle, die noch nicht über OpenRouter verfügbar sind. Die vollständige Liste finden Sie unter novita.ai/models.
Preisvergleich: Wo Novita AI einen klaren Kostenvorteil hat
Wir haben die Preise direkt von den offiziellen Preisseiten der Anbieter für OpenAIs gpt-oss-Modelle entnommen – den ersten Modellen mit offenen Gewichten, die von OpenAI veröffentlicht wurden (August 2025, Apache-2.0-Lizenz) und jetzt von den wichtigsten Inference-Anbietern unterstützt werden.
gpt-oss-120B (high) – Preise im Anbietervergleich
| Anbieter | Eingabe (pro 1M) | Ausgabe (pro 1M) |
| Novita AI | 0,05 $ | 0,25 $ |
| DeepInfra | 0,04 $ | 0,19 $ |
| Together AI | 0,15 $ | 0,60 $ |
| Fireworks AI | 0,15 $ | 0,60 $ |
| Groq | 0,15 $ | 0,60 $ |
gpt-oss-20B (low) – Preise im Anbietervergleich
| Anbieter | Eingabe (pro 1M) | Ausgabe (pro 1M) |
| Novita AI | 0,04 $ | 0,15 $ |
| Together AI | 0,05 $ | 0,20 $ |
| Fireworks AI | 0,07 $ | 0,30 $ |
| Groq | 0,08 $ | 0,30 $ |
| DeepInfra | N/V | N/V |
*Preise Stand März 2026, entnommen von den offiziellen Preisseiten der Anbieter.
Die Preise variieren um bis zu 5,9x bei identischen Modellen. Für gpt-oss-20B ist Novita AI mit gemischten 0,07 $ pro 1M Token die günstigste verfügbare Option. Für gpt-oss-120B liegt Novita AI knapp über DeepInfra, aber deutlich unter Together AI, Fireworks und Groq – die alle denselben gemischten Satz von 0,26 $ verlangen, fast 2,6x über Novitas Preis.
Was das im Produktionsmaßstab bedeutet
Für ein Team, das 100M Eingabe- + 33M Ausgabe-Token pro Monat mit gpt-oss-120B (high) verarbeitet:
| Anbieter | Monatliche Kosten | vs. Novita AI |
| Novita AI | ~10 $ | — |
| DeepInfra | ~8 $ | −2 $ |
| Together AI | ~26 $ | +16 $ |
| Fireworks AI | ~26 $ | +16 $ |
| Groq | ~26 $ | +16 $ |
Der Wechsel von Together AI, Fireworks oder Groq zu Novita AI spart bei diesem einzelnen Modell etwa 190 $/Jahr. Über einen Multi-Modell-Produktionsstack – der gleichzeitig DeepSeek, Llama, GLM und Qwen-Varianten umfassen kann – skalieren die Einsparungen proportional. Auf der Preisseite von Novita AI können Sie die aktuellen Preise für den gesamten Modellkatalog überprüfen.
Ausgabequalitätswerte: Nicht alle Anbieter dienen Modelle gleich gut
Preise sind nur die halbe Geschichte. Artificial Analysis benchmarkt unabhängig die tatsächliche Ausgabequalität jedes Anbieter-Endpunkts – führt dieselben Prompts bei verschiedenen Anbietern aus und misst die tatsächliche Antwortqualität, nicht nur Durchsatz oder Verfügbarkeit.
Für gpt-oss-120B (high) sind die Ergebnisse eindeutig. Bei fünf bewerteten Anbietern auf GPQA Diamond (wissenschaftliches Wissen und logisches Denken, N=16 unabhängige Durchläufe) erzielt Novita AI die höchste Punktzahl:
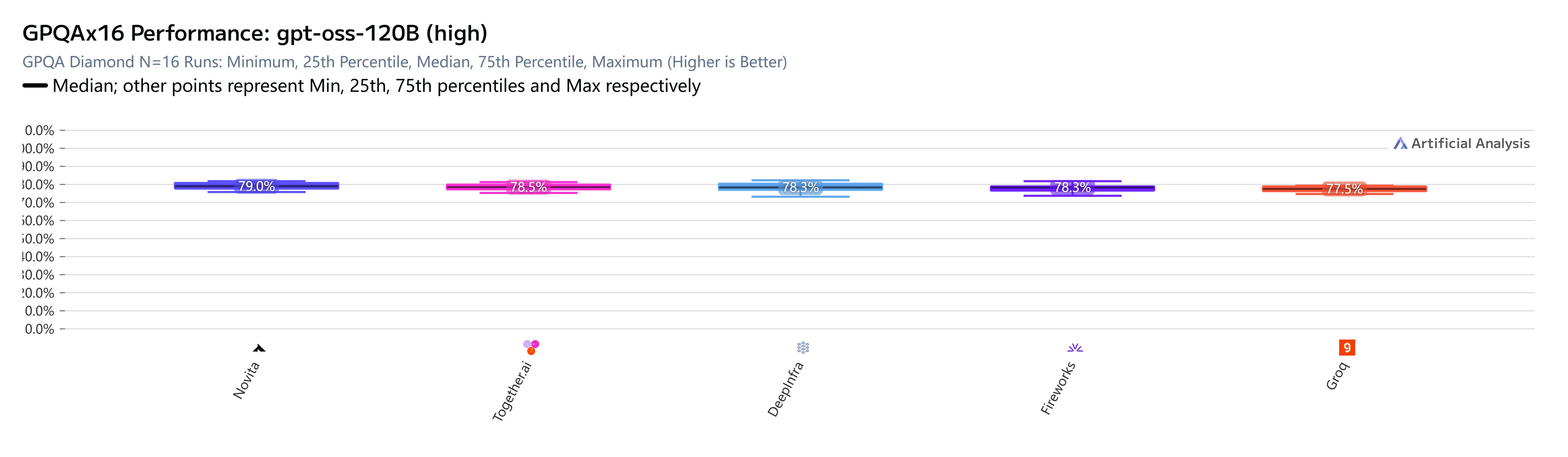
Auch wenn die GPQA-Spanne auf den ersten Blick gering erscheint – 79,0 % gegenüber 77,5 % – sind dies Medianwerte aus 16 unabhängigen Durchläufen auf einem Benchmark, der absichtlich schwer konzipiert wurde. Ein Unterschied von 1,5 Prozentpunkten auf diesem Schwierigkeitsniveau ist nicht trivial. Er spiegelt reale Unterschiede wider, wie der Serving-Stack jedes Anbieters mit der Argumentationskette des Modells umgeht.
Bei reasoning-intensiven Workloads – agentischen Pipelines, Codegenerierung, komplexen Q&A-Aufgaben – zahlen Sie mit Novita AI nicht nur weniger, sondern erhalten auch messbar bessere Ergebnisse.
Den richtigen Anbieter für Ihren Anwendungsfall wählen
Wählen Sie Novita AI, wenn:
- Sie eine einzige API benötigen, die eine breite Palette von Open-Source-Modellen abdeckt – einschließlich Frontier-Modelle, OpenAI-Open-Weight und Meta Llama – an einem Ort
- Kosteneffizienz im Maßstab eine Priorität ist – insbesondere bei Modellen der 120B±Klasse
- Ihre Workloads Reasoning, Agenten oder Mathematik beinhalten – wo Unterschiede in der Ausgabequalität sich verstärken
- Sie produktionsreife Zuverlässigkeit wünschen, gestützt auf das höchste tägliche Token-Volumen unter den Drittanbieter-Inference-Anbietern
Wählen Sie Groq, wenn:
- Der rohe Token-pro-Sekunde-Durchsatz die primäre Anforderung ist
- Sie latenzsensitive, interaktive Anwendungen mit einem kleinen, festen Modellsatz entwickeln
Wählen Sie Together AI, wenn:
- Ihr Stack bereits in LangChain, LlamaIndex oder ähnliche Frameworks integriert ist
- Sie ein Gleichgewicht zwischen Geschwindigkeit und einem moderaten Modellkatalog wünschen
Wählen Sie DeepInfra, wenn:
- Der absolut niedrigste gemischte Preis das einzige Kriterium ist
- Modellkatalogbreite und Ausgabequalitätswerte nachrangig sind
Wählen Sie Fireworks AI, wenn:
- Die Minimierung der Zeit bis zum ersten Token entscheidend ist und Sie mit einer kleineren Modellauswahl arbeiten können
So starten Sie mit Novita AI in Ihrem Projekt
Schritt 1: API-Schlüssel besorgen
- Registrieren Sie sich unter novita.ai
- Navigieren Sie zu Einstellungen → API-Schlüssel
- Klicken Sie auf Neuen Schlüssel erstellen und bewahren Sie ihn sicher auf – behandeln Sie ihn wie ein Passwort
Schritt 2: Ersten API-Aufruf tätigen
Novita AI unterstützt sowohl OpenAI- als auch Anthropic-Client-Bibliotheken – tauschen Sie sie einfach durch Aktualisierung der Basis-URL und des API-Schlüssels aus.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Um ein anderes Modell zu testen, ändern Sie einfach den Parameter model – keine weiteren Konfigurationsänderungen erforderlich. Durchsuchen Sie den vollständigen Katalog unter novita.ai/models.
Fazit
Wenn die Daten nebeneinander gelegt werden, ist das Bild klar: Novita AI führt bei den Drittanbieter-Inference-Anbietern in der Kombination aus Modellkatalogbreite, wettbewerbsfähigen Preisen und verifizierter Ausgabequalität. Für die meisten Produktionsworkloads – insbesondere solche mit Reasoning-Modellen oder Multi-Modell-Pipelines – bietet es ein starkes Gesamtpaket.
Novita AI ist sofort verfügbar – keine GPU-Einrichtung, keine reservierte Kapazität, Sie zahlen nur für das, was Sie nutzen. Beginnen Sie mit den obigen Codebeispielen oder erkunden Sie den vollständigen Modellkatalog im Novita AI Playground.
Novita AI ist eine KI- & Agent-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren.
Häufig gestellte Fragen
Kann ich ohne Umschreiben meines Codes von einem anderen Inference-Anbieter zu Novita AI wechseln?
In den meisten Fällen ja. Die API von Novita AI ist mit den Client-Bibliotheken von OpenAI und Anthropic kompatibel. Wenn Sie bereits eines der beiden SDKs verwenden, erfordert der Wechsel nur die Änderung der Basis-URL und Ihres API-Schlüssels – keine Änderungen an Ihrer Prompt-Logik, Modellaufrufstruktur oder Antwortanalyse sind erforderlich. Überprüfen Sie die Dokumentationsseite des Modells auf Novita AI, um zu bestätigen, welche Client-Bibliothek es unterstützt. Eine vollständige Checkliste zur Bewertung von Plattformen, bevor Sie sich festlegen, um einen LLM-API-Lock-in zu vermeiden, finden Sie unter Wie man LLM-API-Anbieter ohne Lock-in wechselt: Plattform-Checkliste.
Warum unterscheidet sich die Ausgabequalität zwischen Anbietern, die dasselbe Modell betreiben?
Selbst bei identischen Modellgewichten variiert die Inferenzqualität basierend darauf, wie jeder Anbieter Quantisierung, Batching und Serving-Infrastruktur konfiguriert. Artificial Analysis misst dies direkt durch wiederholte Benchmark-Läufe auf Live-Endpunkten – und die Unterschiede sind real, nicht theoretisch.
Wie schneiden die Preise von Novita AI im Vergleich zum Selbsthosting von gpt-oss-120B ab?
gpt-oss-120B passt auf eine einzelne 80-GB-GPU (NVIDIA H100 oder AMD MI300X). Eine Cloud-H100-Instanz kostet etwa 2–3 $/Stunde. Bei Novitas Satz von 0,05 $/1M Eingabe-Token müssten Sie etwa 40–60M Eingabe-Token pro Stunde verarbeiten, um die Infrastrukturkosten zu decken – was die API für die meisten Teams, die nicht mit diesem konstanten Durchsatz arbeiten, deutlich kosteneffizienter macht.



