

- Pourquoi le choix de votre fournisseur d’inférence a vraiment de l’importance
- Présentation des cinq fournisseurs de cette comparaison
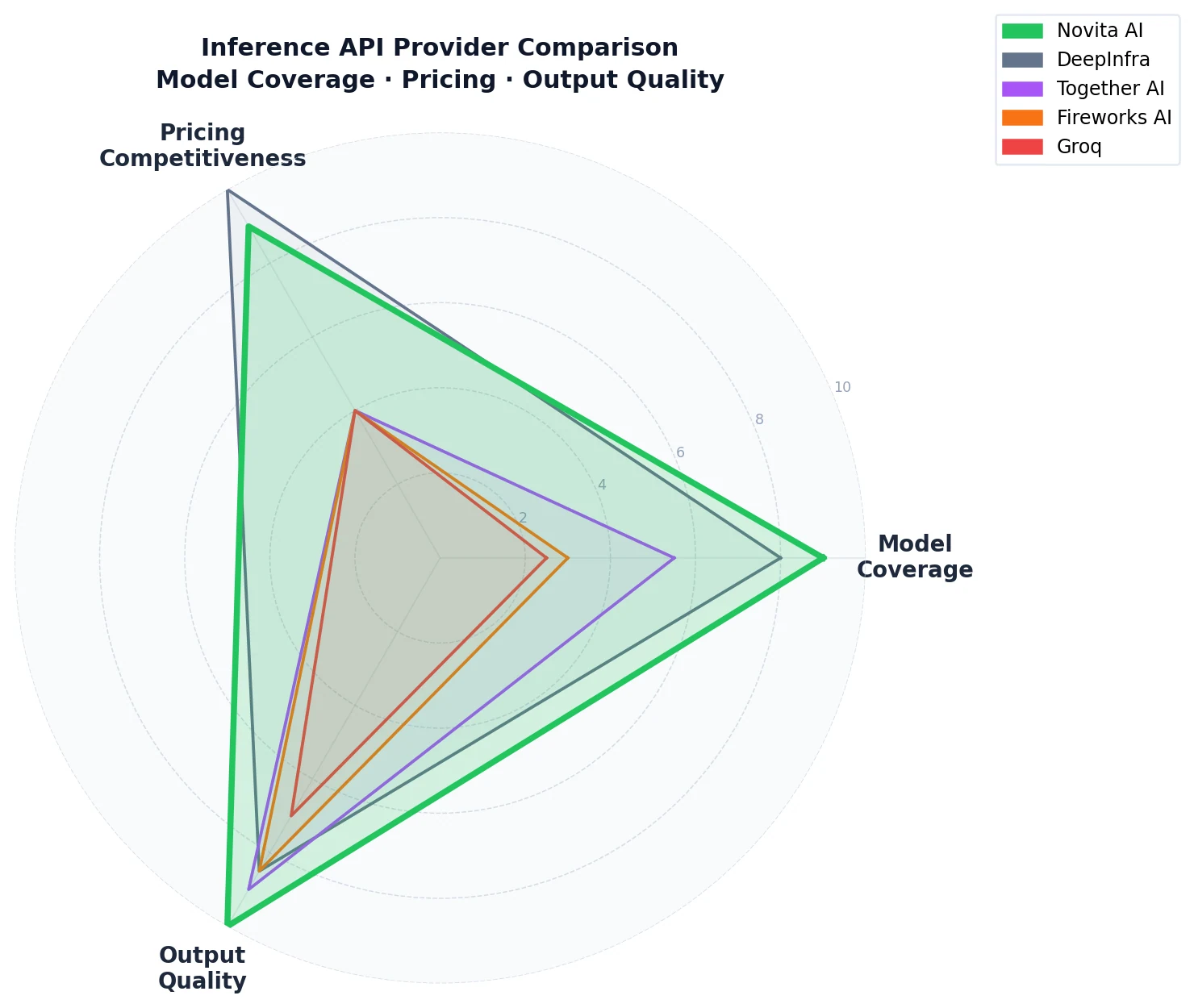
- Quelle est l’étendue du catalogue de modèles de chaque fournisseur ?
- Comparaison des tarifs : là où Novita AI a un net avantage de coût
- Scores de qualité des résultats : tous les fournisseurs ne servent pas les modèles aussi bien
- Choisir le bon fournisseur pour votre cas d’usage
- Comment commencer à utiliser Novita AI dans votre projet
- Conclusion
Choisir un fournisseur d’API d’inférence pour modèles open source ne se résume pas à savoir qui propose le modèle — il s’agit de déterminer quel fournisseur délivre la meilleure qualité de résultats au coût le plus bas avec la sélection de modèles la plus large. Un même modèle peut renvoyer des résultats sensiblement différents et coûter jusqu’à 5 fois plus selon l’endroit où vous l’appelez. Cet article compare cinq grands fournisseurs — Novita AI, Together AI, Fireworks AI, DeepInfra et Groq — selon trois dimensions qui comptent vraiment : le catalogue de modèles, les tarifs et la qualité réelle des résultats mesurée par des benchmarks.
Pourquoi le choix de votre fournisseur d’inférence a vraiment de l’importance
Lorsque vous appelez un modèle open source via une API tierce, les poids sous-jacents sont identiques — mais l’infrastructure de service, les choix de quantification et la pile d’optimisation diffèrent considérablement d’un fournisseur à l’autre. Cela a plus d’importance que la plupart des développeurs ne le pensent.
Prenez gpt-oss-120B (high), le modèle phare à poids ouverts d’OpenAI : les prix d’entrée varient de 0,05 $ à 0,60 $ par million de tokens selon les fournisseurs — un écart de 12x. Les scores de qualité des résultats sur le même modèle divergent de marges mesurables sur les benchmarks indépendants. Et tandis qu’un fournisseur prend en charge plus de 66 modèles sur OpenRouter, un autre plafonne à une douzaine. Ces différences se cumulent à l’échelle de la production, affectant à la fois votre facture d’infrastructure mensuelle et la qualité des résultats que vos utilisateurs reçoivent.
Présentation des cinq fournisseurs de cette comparaison
Avant de plonger dans les chiffres, voici un aperçu de chaque fournisseur :
Novita AI est une plateforme cloud IA & agents qui aide les développeurs et les startups à construire, déployer et passer à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une rentabilité optimales. Elle couvre un large éventail de modèles open source — y compris GLM, MiniMax, Kimi, Qwen, DeepSeek, la série gpt-oss à poids ouverts d’OpenAI, la famille Llama de Meta, et bien d’autres — le tout via un point d’accès compatible OpenAI.
Together AI est un fournisseur d’inférence bien établi avec de solides intégrations écosystémiques, populaire parmi les équipes utilisant LangChain, LlamaIndex et des frameworks similaires. Il propose une sélection solide de modèles open source courants avec des vitesses de sortie compétitives.
Si Together est un sérieux finaliste, la comparaison ciblée Together AI vs Novita AI couvre les tarifs, la compatibilité des API, les tâches par lots, les points d’accès dédiés et les compromis de workflow de production plus en détail.
Fireworks AI se concentre sur l’inférence à faible latence, se positionnant pour les applications sensibles à la latence. Son catalogue de modèles est plus sélectif, privilégiant les modèles prêts pour la production plutôt que l’étendue. Pour les équipes qui comparent ce positionnement avec les API de modèles, l’Agent Sandbox, l’inférence par lots et le GPU Cloud de Novita AI, consultez le guide dédié Fireworks AI alternative.
DeepInfra propose un vaste catalogue de modèles avec des tarifs constamment compétitifs, ce qui en fait un choix courant pour les charges de travail axées sur le coût où la variété brute des modèles est valorisée.
Groq est conçu pour la vitesse, utilisant du matériel LPU personnalisé pour offrir un débit de tokens extrêmement élevé. Son catalogue de modèles est intentionnellement restreint, optimisé autour des modèles qui bénéficient le plus de l’architecture matérielle de Groq.
![]()
Quelle est l’étendue du catalogue de modèles de chaque fournisseur ?
La diversité des modèles disponibles détermine si vous pouvez consolider votre infrastructure sur un seul fournisseur ou si vous devez maintenir plusieurs clés API pour différents cas d’usage.
Le classement des fournisseurs sur OpenRouter — trié par volume quotidien de tokens — donne un signal direct et réel des fournisseurs d’inférence qui traitent le plus de trafic de production. Parmi les 12 fournisseurs listés au-dessus de DeepInfra dans ce classement, la plupart sont des fournisseurs de modoles propriétaires (Xiaomi, Alibaba Cloud, Google Vertex, Amazon Bedrock, MiniMax, xAI, OpenAI, StepFun, Google AI Studio, Z.ai) — des entreprises servant principalement leurs propres modèles. En excluant les vendeurs de modèles fermés et les créateurs de modèles, Novita AI se classe n°1 parmi les fournisseurs d’inférence tiers purs en volume quotidien de tokens sur OpenRouter, traitant 135,8 milliards de tokens par jour et 4,6 billions de tokens par mois sur 66 modèles disponibles.
DeepInfra est le concurrent le plus proche avec 103,6B tokens/jour et 75 modèles sur OpenRouter. Together AI, Fireworks AI et Groq n’apparaissent pas dans les premières positions de ce classement.
Le nombre de modèles sur OpenRouter reflète les modèles activement servis via la plateforme. À titre de comparaison, Artificial Analysis suit ce qui suit pour chaque point d’accès API :
| Fournisseur | Modèles sur OpenRouter |
| Novita AI | 66 |
| DeepInfra | 75 |
| Together AI | 28 |
| Groq | 8 |
| Fireworks AI | 7 |
Le chiffre de 66 modèles reflète la présence de Novita AI sur OpenRouter. Le catalogue complet de l’API de Novita AI prend actuellement en charge plus de 200 modèles, y compris des modèles pas encore disponibles via OpenRouter. Visitez novita.ai/models pour la liste complète.
Comparaison des tarifs : là où Novita AI a un net avantage de coût
Nous avons extrait les tarifs directement des pages de tarification officielles de chaque fournisseur pour les modèles gpt-oss d’OpenAI — les premiers modèles à poids ouverts publiés par OpenAI (août 2025, licence Apache 2.0), désormais largement pris en charge par les principaux fournisseurs d’inférence.
gpt-oss-120B (high) — Tarifs selon les fournisseurs
| Fournisseur | Entrée (par 1M) | Sortie (par 1M) |
| Novita AI | 0,05 $ | 0,25 $ |
| DeepInfra | 0,04 $ | 0,19 $ |
| Together AI | 0,15 $ | 0,60 $ |
| Fireworks AI | 0,15 $ | 0,60 $ |
| Groq | 0,15 $ | 0,60 $ |
gpt-oss-20B (low) — Tarifs selon les fournisseurs
| Fournisseur | Entrée (par 1M) | Sortie (par 1M) |
| Novita AI | 0,04 $ | 0,15 $ |
| Together AI | 0,05 $ | 0,20 $ |
| Fireworks AI | 0,07 $ | 0,30 $ |
| Groq | 0,08 $ | 0,30 $ |
| DeepInfra | N/D | N/D |
*Tarifs en date de mars 2026, issus des pages de tarification officielles de chaque fournisseur.
Les prix varient jusqu’à 5,9 fois selon les fournisseurs pour des modèles identiques. Pour gpt-oss-20B, Novita AI est l’option la moins chère disponible à 0,07 $ en moyenne par million de tokens. Pour gpt-oss-120B, Novita AI se situe juste au-dessus de DeepInfra mais bien en dessous de Together AI, Fireworks et Groq — qui facturent tous le même tarif moyen de 0,26 $, soit près de 2,6 fois le prix de Novita.
Ce que cela signifie à l’échelle de la production
Pour une équipe utilisant 100M tokens en entrée + 33M tokens en sortie par mois sur gpt-oss-120B (high) :
| Fournisseur | Coût mensuel | vs. Novita AI |
| Novita AI | ~10 $ | — |
| DeepInfra | ~8 $ | −2 $ |
| Together AI | ~26 $ | +16 $ |
| Fireworks AI | ~26 $ | +16 $ |
| Groq | ~26 $ | +16 $ |
Passer de Together AI, Fireworks ou Groq à Novita AI permet d’économiser environ 190 $/mois sur ce seul modèle. Sur une pile de production multi-modèles — qui pourrait inclure DeepSeek, Llama, GLM et Qwen simultanément — les économies s’ajustent proportionnellement. Sur la page de tarification de Novita AI, vous pouvez vérifier les tarifs actuels pour l’ensemble du catalogue.
Scores de qualité des résultats : tous les fournisseurs ne servent pas les modèles aussi bien
Les tarifs ne sont que la moitié de l’histoire. Artificial Analysis évalue indépendamment la qualité réelle des résultats de chaque point d’accès fournisseur — en exécutant les mêmes invites sur plusieurs fournisseurs et en mesurant la qualité réelle des réponses, pas seulement le débit ou la disponibilité.
Pour gpt-oss-120B (high), les résultats sont sans ambiguïté. Sur cinq fournisseurs évalués sur GPQA Diamond (connaissances scientifiques et raisonnement, N=16 exécutions indépendantes), Novita AI obtient le meilleur score :
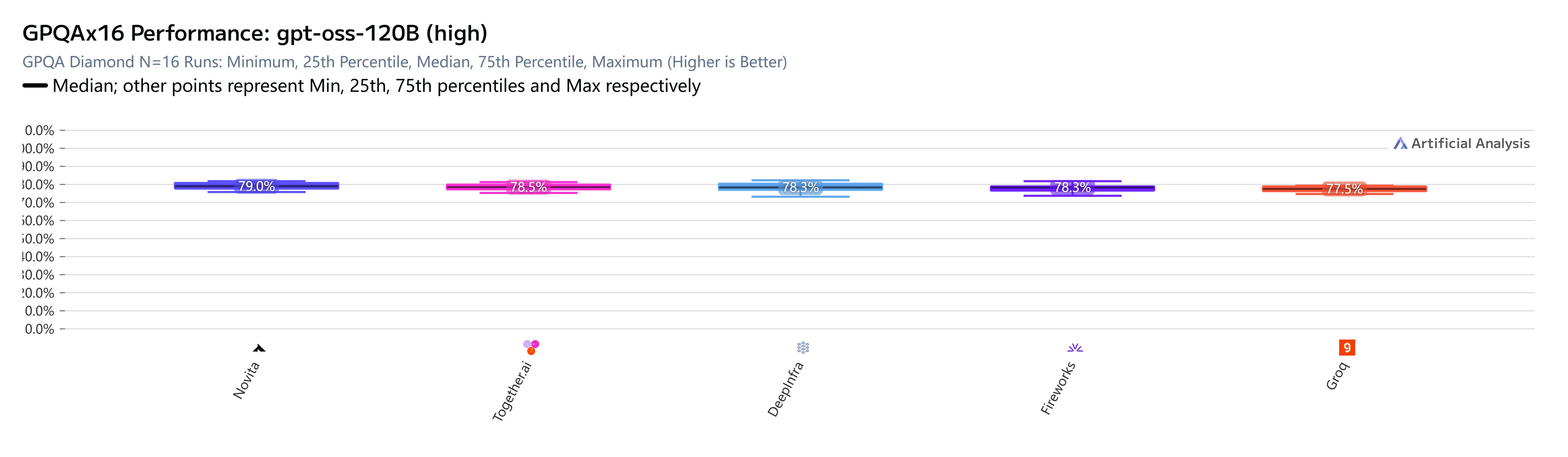
Bien que l’écart GPQA semble étroit à première vue — 79,0 % contre 77,5 % — il s’agit de scores médians sur 16 exécutions indépendantes sur un benchmark spécialement conçu pour être difficile. Une différence de 1,5 point de pourcentage à ce niveau de difficulté n’est pas négligeable. Elle reflète de réelles différences dans la manière dont la pile de service de chaque fournisseur gère la chaîne de raisonnement du modèle.
Pour les charges de travail lourdes en raisonnement — pipelines agentiques, génération de code, questions-réponses complexes — vous ne payez pas seulement moins cher avec Novita AI, vous obtenez des résultats mesurablement meilleurs.
Choisir le bon fournisseur pour votre cas d’usage
Choisissez Novita AI si :
- Vous avez besoin d’une API unique couvrant un vaste catalogue de modèles open source — y compris les modèles de pointe, les poids ouverts d’OpenAI et Meta Llama — en un seul endroit
- La rentabilité à grande échelle est une priorité — en particulier au niveau 120B+
- Vos charges de travail impliquent du raisonnement, des agents ou des mathématiques — là où les différences de qualité des résultats se cumulent
- Vous voulez une fiabilité de niveau production soutenue par le volume quotidien de tokens le plus élevé parmi les fournisseurs d’inférence tiers
Choisissez Groq si :
- Le débit brut en tokens par seconde est l’exigence principale
- Vous construisez des applications interactives sensibles à la latence avec un ensemble de modèles restreint et fixe
Choisissez Together AI si :
- Votre pile est déjà intégrée avec LangChain, LlamaIndex ou des frameworks similaires
- Vous voulez un équilibre entre vitesse et un catalogue de modèles modéré
Choisissez DeepInfra si :
- Le prix moyen absolu le plus bas est le seul critère
- La diversité du catalogue de modèles et les scores de qualité sont des préoccupations secondaires
Choisissez Fireworks AI si :
- Minimiser le temps jusqu’au premier token est critique et vous pouvez travailler avec une sélection de modèles plus restreinte
Comment commencer à utiliser Novita AI dans votre projet
Étape 1 : Obtenez votre clé API
- Inscrivez-vous sur novita.ai
- Accédez à Paramètres → Clés API
- Cliquez sur Créer une nouvelle clé et stockez-la en toute sécurité — traitez-la comme un mot de passe
Étape 2 : Effectuez votre premier appel API
Novita AI prend en charge les bibliothèques client OpenAI et Anthropic — remplacez simplement l’URL de base et la clé API
from openai import OpenAI
client = OpenAI(
api_key="<Votre clé API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "Vous êtes un assistant utile."},
{"role": "user", "content": "Bonjour, comment allez-vous ?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Pour essayer un modèle différent, modifiez simplement le paramètre model — aucune autre modification de configuration n’est nécessaire. Parcourez le catalogue complet sur novita.ai/models.
Conclusion
Lorsque les données sont présentées côte à côte, le tableau est clair : Novita AI mène parmi les fournisseurs d’inférence tiers sur la combinaison de l’étendue du catalogue, des tarifs compétitifs et de la qualité de sortie vérifiée. Pour la plupart des charges de travail de production — en particulier celles impliquant des modèles de raisonnement ou des pipelines multi-modèles — elle offre un excellent rapport qualité-prix global.
Novita AI est disponible dès maintenant — pas de configuration GPU, pas de capacité réservée, payez seulement ce que vous utilisez. Commencez avec les exemples de code ci-dessus, ou explorez le catalogue complet dans le Novita AI Playground.
Novita AI est une plateforme cloud IA & agents aidant les développeurs et les startups à construire, déployer et passer à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une rentabilité optimales.
Questions fréquemment posées
Puis-je passer à Novita AI depuis un autre fournisseur d’inférence sans réécrire mon code ?
Dans la plupart des cas, oui. L’API de Novita AI est compatible avec les bibliothèques client OpenAI et Anthropic. Si vous utilisez déjà l’un de ces SDK, le passage nécessite seulement de changer l’URL de base et votre clé API — aucune modification de votre logique d’invite, de la structure d’appel du modèle ou de l’analyse des réponses n’est requise. Consultez la page de documentation du modèle sur Novita AI pour confirmer la bibliothèque client prise en charge. Pour une liste complète de vérification pour évaluer les plateformes avant de vous engager et éviter le verrouillage des API LLM, voir Comment changer de fournisseur d’API LLM sans verrouillage : liste de vérification de la plateforme.
Pourquoi la qualité des résultats diffère-t-elle entre les fournisseurs qui exécutent le même modèle ?
Même avec des poids de modèle identiques, la qualité de l’inférence varie en fonction de la manière dont chaque fournisseur configure la quantification, le traitement par lots et l’infrastructure de service. Artificial Analysis mesure cela directement via des exécutions de benchmarks répétées sur des points d’accès en direct — et les différences sont réelles, pas théoriques.
Comment les tarifs de Novita AI se comparent-ils à l’auto-hébergement de gpt-oss-120B ?
gpt-oss-120B tient sur un seul GPU 80 Go (NVIDIA H100 ou AMD MI300X). Une instance cloud H100 coûte environ 2–3 $/heure. Au tarif de Novita AI de 0,05 $/1M de tokens d’entrée, vous devriez traiter environ 40–60M de tokens d’entrée par heure pour atteindre le seuil de rentabilité des coûts d’infrastructure — ce qui rend l’API nettement plus rentable pour la plupart des équipes qui n’atteignent pas ce débit constant.
Articles recommandés
- Comment changer de fournisseur d’API LLM sans verrouillage : liste de vérification de la plateforme
- Top 10 des API LLM les moins chères en 2026
- Meilleurs modèles IA pour OpenClaw Agents en 2026
- GLM-5 vs MiniMax M2.5 : quel modèle open source 2026 gagne ?
- Meilleure plateforme cloud IA pour l’inférence de modèles sans serveur



