

- Por que a Escolha do Provedor de Inferência Realmente Importa
- Conheça os Cinco Provedores desta Comparação
- Qual a Amplitude do Catálogo de Modelos de Cada Provedor?
- Comparação de Preços: Onde a Novita AI Tem uma Vantagem Clara de Custo
- Pontuações de Qualidade de Saída: Nem Todos os Provedores Servem Modelos Igualmente Bem
- Escolhendo o Provedor Certo para o Seu Caso de Uso
- Como Começar a Usar Novita AI no Seu Projeto
- Conclusão
Escolher um provedor de API de inferência para modelos open-source não é só sobre quem oferece o modelo — é sobre qual provedor entrega a melhor qualidade de saída pelo menor custo com a maior seleção de modelos. O mesmo modelo pode retornar resultados significativamente diferentes e custar 5x mais dependendo de onde você o chama. Este artigo compara cinco provedores líderes — Novita AI, Together AI, Fireworks AI, DeepInfra e Groq — em três dimensões que realmente importam: cobertura do catálogo de modelos, preços e qualidade real da saída em benchmarks.
Por que a Escolha do Provedor de Inferência Realmente Importa
Quando você chama um modelo open-source através de uma API de terceiros, os pesos subjacentes são idênticos — mas a infraestrutura de serviço, as escolhas de quantização e a pilha de otimização diferem significativamente entre os provedores. Isso importa mais do que a maioria dos desenvolvedores imagina.
Considere o gpt-oss-120B (high), o modelo flagship de pesos abertos da OpenAI: os preços de entrada variam de $0,05 a $0,60 por 1M de tokens entre os provedores — uma diferença de 12x. As pontuações de qualidade de saída no mesmo modelo divergem por margens mensuráveis em benchmarks independentes. E enquanto um provedor suporta mais de 66 modelos no OpenRouter, outro se limita a uma dúzia. Essas diferenças se acumulam no uso em escala de produção, afetando tanto sua conta mensal de infraestrutura quanto a qualidade das saídas que seus usuários recebem.
Conheça os Cinco Provedores desta Comparação
Antes de mergulhar nos números, aqui está uma breve visão geral de cada provedor:
Novita AI é uma plataforma cloud de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações de agentes com alto desempenho, confiabilidade e eficiência de custos. Ela cobre uma ampla gama de modelos open-source — incluindo GLM, MiniMax, Kimi, Qwen, DeepSeek, a série gpt-oss de pesos abertos da OpenAI, a família Llama da Meta e muito mais — tudo sob um único endpoint compatível com OpenAI.
Together AI é um provedor de inferência bem estabelecido com fortes integrações de ecossistema, popular entre equipes que usam LangChain, LlamaIndex e frameworks similares. Oferece uma seleção sólida de modelos open-source populares com velocidades de saída competitivas.
Se Together é um finalista sério, a comparação focada Together AI vs Novita AI cobre preços, compatibilidade de API, jobs em lote, endpoints dedicados e tradeoffs de fluxo de trabalho de produção em mais detalhes.
Fireworks AI foca em inferência de baixa latência, posicionando-se para aplicações sensíveis à latência. Seu catálogo de modelos é mais seletivo, priorizando modelos prontos para produção em vez de amplitude. Para equipes que comparam esse posicionamento com as APIs de modelo da Novita AI, Agent Sandbox, inferência em lote e GPU Cloud, veja o guia dedicado Alternativa ao Fireworks AI.
DeepInfra oferece um amplo catálogo de modelos com preços consistentemente competitivos, tornando-se uma escolha comum para cargas de trabalho focadas em custo onde a variedade bruta de modelos é valorizada.
Groq é construído sob medida para velocidade, usando hardware LPU personalizado para fornecer throughput de tokens extremamente alto. Seu catálogo de modelos é intencionalmente pequeno, otimizado em torno dos modelos que mais se beneficiam da arquitetura de hardware da Groq.
![]()
Qual a Amplitude do Catálogo de Modelos de Cada Provedor?
A amplitude dos modelos disponíveis determina se você pode consolidar sua infraestrutura em um único provedor ou precisa manter várias chaves de API para diferentes casos de uso.
O ranking de provedores do OpenRouter — ordenado por volume diário de tokens — dá um sinal direto e real de quais provedores de inferência estão lidando com mais tráfego de produção. Entre os 12 provedores listados acima da DeepInfra nesse ranking, a maioria são provedores de modelo de primeira parte (Xiaomi, Alibaba Cloud, Google Vertex, Amazon Bedrock, MiniMax, xAI, OpenAI, StepFun, Google AI Studio, Z.ai) — empresas servindo principalmente seus próprios modelos. Excluindo fornecedores de modelos de código fechado e criadores de modelos, a Novita AI ocupa o #1 entre provedores de inferência terceirizados puros por volume diário de tokens no OpenRouter, processando 135,8 bilhões de tokens por dia e 4,6 trilhões de tokens por mês em 66 modelos disponíveis.
A DeepInfra é a concorrente mais próxima com 103,6B tokens/dia e 75 modelos no OpenRouter. Together AI, Fireworks AI e Groq não aparecem nas primeiras posições deste ranking.
A contagem de modelos no OpenRouter reflete os modelos ativamente servidos através da plataforma. Para comparação, a Artificial Analysis rastreia o seguinte em cada endpoint de API do provedor:
| Provedor | Modelos no OpenRouter |
| Novita AI | 66 |
| DeepInfra | 75 |
| Together AI | 28 |
| Groq | 8 |
| Fireworks AI | 7 |
O número de 66 modelos reflete a listagem da Novita AI no OpenRouter. O catálogo completo da API da Novita AI atualmente suporta mais de 200 modelos, incluindo modelos ainda não disponíveis através do OpenRouter. Visite novita.ai/models para a lista completa.
Comparação de Preços: Onde a Novita AI Tem uma Vantagem Clara de Custo
Coletamos os preços diretamente da página de preços oficial de cada provedor para os modelos gpt-oss da OpenAI — os primeiros modelos de pesos abertos lançados pela OpenAI (agosto de 2025, licença Apache 2.0), agora amplamente suportados pelos principais provedores de inferência.
gpt-oss-120B (high) — Preços Entre os Provedores
| Provedor | Entrada (por 1M) | Saída (por 1M) |
| Novita AI | $0,05 | $0,25 |
| DeepInfra | $0,04 | $0,19 |
| Together AI | $0,15 | $0,60 |
| Fireworks AI | $0,15 | $0,60 |
| Groq | $0,15 | $0,60 |
gpt-oss-20B (low) — Preços Entre os Provedores
| Provedor | Entrada (por 1M) | Saída (por 1M) |
| Novita AI | $0,04 | $0,15 |
| Together AI | $0,05 | $0,20 |
| Fireworks AI | $0,07 | $0,30 |
| Groq | $0,08 | $0,30 |
| DeepInfra | N/D | N/D |
*Preços de março de 2026, obtidos da página de preços oficial de cada provedor.
Os preços variam até 5,9x entre os provedores para modelos idênticos. Para o gpt-oss-20B, a Novita AI é a opção mais barata disponível a $0,07 combinado por 1M de tokens. Para o gpt-oss-120B, a Novita AI fica logo acima da DeepInfra, mas muito abaixo da Together AI, Fireworks e Groq — que cobram todas a mesma taxa combinada de $0,26, quase 2,6x o preço da Novita.
O Que Isso Significa em Escala de Produção
Para uma equipe processando 100M de tokens de entrada + 33M de tokens de saída por mês no gpt-oss-120B (high):
| Provedor | Custo Mensal | vs. Novita AI |
| Novita AI | ~$10 | — |
| DeepInfra | ~$8 | −$2 |
| Together AI | ~$26 | +$16 |
| Fireworks AI | ~$26 | +$16 |
| Groq | ~$26 | +$16 |
Mudar da Together AI, Fireworks ou Groq para a Novita AI economiza aproximadamente $190/mês neste único modelo. Em uma pilha de produção com múltiplos modelos — que pode incluir DeepSeek, Llama, GLM e variantes Qwen simultaneamente — as economias escalam proporcionalmente. Na página de preços da Novita AI, você pode verificar as taxas atuais para o catálogo completo de modelos.
Pontuações de Qualidade de Saída: Nem Todos os Provedores Servem Modelos Igualmente Bem
Preço é apenas metade da história. A Artificial Analysis avalia de forma independente a qualidade real da saída de cada endpoint do provedor — executando os mesmos prompts através dos provedores e medindo a qualidade real da resposta, não apenas throughput ou disponibilidade.
Para o gpt-oss-120B (high), os resultados são inequívocos. Entre cinco provedores avaliados no GPQA Diamond (conhecimento científico e raciocínio, N=16 execuções independentes), a Novita AI obtém a maior pontuação:
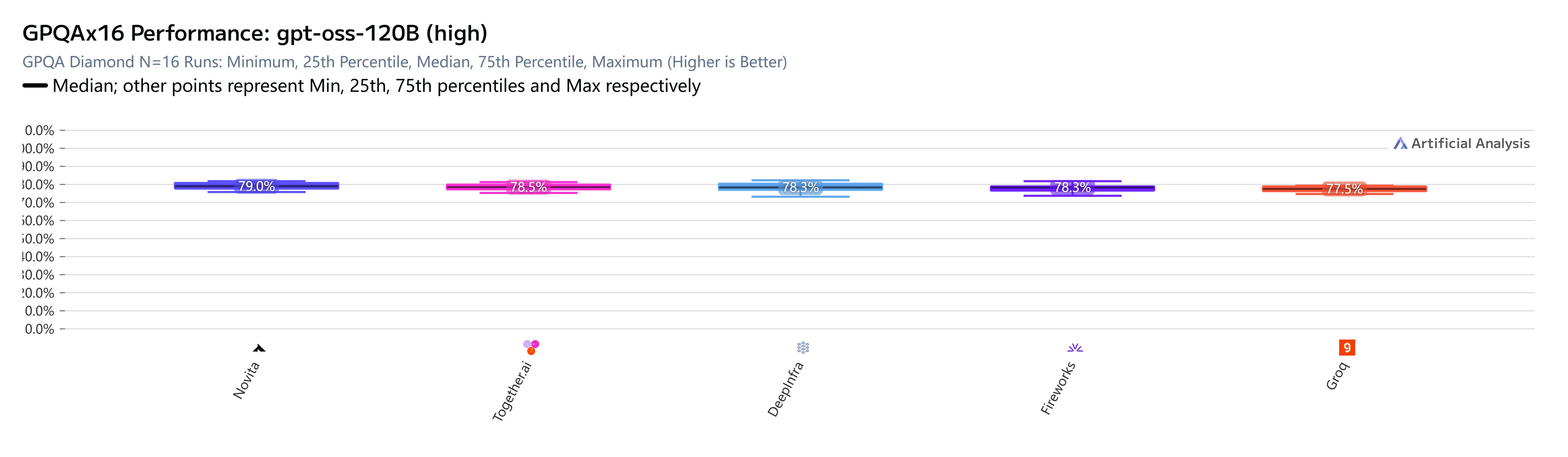
Embora a diferença no GPQA pareça estreita à primeira vista — 79,0% vs. 77,5% — são pontuações medianas em 16 execuções independentes em um benchmark projetado especificamente para ser difícil. Uma diferença de 1,5 ponto percentual nesse nível de dificuldade não é trivial. Reflete diferenças reais em como a pilha de serviço de cada provedor lida com a cadeia de raciocínio do modelo.
Para cargas de trabalho pesadas em raciocínio — pipelines de agentes, geração de código, Q&A complexo — você não está apenas pagando menos com a Novita AI, está obtendo saídas mensuravelmente melhores.
Escolhendo o Provedor Certo para o Seu Caso de Uso
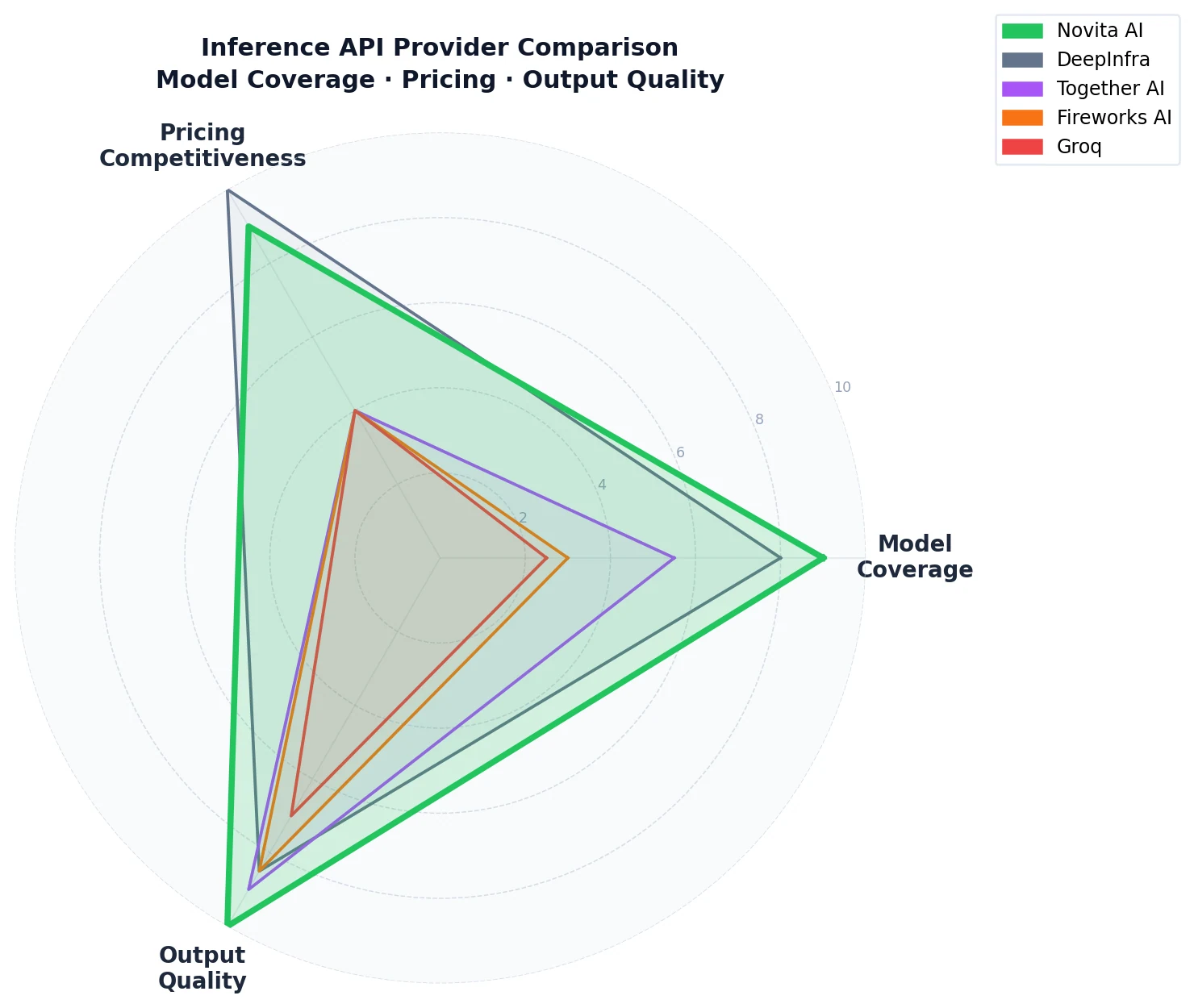
Escolha Novita AI se:
- Você precisa de uma única API que cubra um amplo catálogo de modelos open-source — incluindo modelos de fronteira, pesos abertos da OpenAI e Meta Llama — em um só lugar
- A eficiência de custos em escala é uma prioridade — especialmente no nível 120B+
- Suas cargas de trabalho envolvem raciocínio, agentes ou matemática — onde as diferenças na qualidade da saída se acumulam
- Você quer confiabilidade de nível de produção respaldada pelo maior volume diário de tokens entre provedores de inferência terceirizados
Escolha Groq se:
- O throughput bruto de tokens por segundo é o principal requisito
- Você está construindo aplicações interativas sensíveis à latência com um conjunto pequeno e fixo de modelos
Escolha Together AI se:
- Sua pilha já está integrada com LangChain, LlamaIndex ou frameworks similares
- Você quer um equilíbrio entre velocidade e um catálogo de modelos moderado
Escolha DeepInfra se:
- O menor preço combinado absoluto é o único critério
- A amplitude do catálogo de modelos e as pontuações de qualidade de saída são preocupações secundárias
Escolha Fireworks AI se:
- Minimizar o tempo até o primeiro token é crítico e você pode trabalhar com uma seleção menor de modelos
Como Começar a Usar Novita AI no Seu Projeto
Passo 1: Obtenha Sua Chave de API
- Cadastre-se em novita.ai
- Navegue até Configurações → Chaves de API
- Clique em Criar Nova Chave e armazene-a com segurança — trate-a como uma senha
Passo 2: Faça Sua Primeira Chamada de API
A Novita AI suporta tanto as bibliotecas de cliente da OpenAI quanto da Anthropic — basta substituir alterando apenas a URL base e a chave de API
from openai import OpenAI
client = OpenAI(
api_key="<Sua Chave de API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "Você é um assistente útil."},
{"role": "user", "content": "Olá, como você está?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Para experimentar um modelo diferente, basta alterar o parâmetro model — nenhuma outra alteração de configuração é necessária. Navegue pelo catálogo completo em novita.ai/models.
Conclusão
Quando os dados são dispostos lado a lado, o quadro é claro: a Novita AI lidera entre os provedores de inferência terceirizados na combinação de amplitude do catálogo de modelos, preços competitivos e qualidade de saída verificada. Para a maioria das cargas de trabalho de produção — especialmente aquelas que envolvem modelos de raciocínio ou pipelines com múltiplos modelos — ela oferece um valor geral forte.
A Novita AI está disponível agora — sem configuração de GPU, sem capacidade reservada, pague apenas pelo que usar. Comece com os exemplos de código acima ou explore o catálogo completo de modelos no Novita AI Playground.
Novita AI é uma plataforma cloud de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações de agentes com alto desempenho, confiabilidade e eficiência de custos.
Perguntas Frequentes
Posso migrar para a Novita AI a partir de outro provedor de inferência sem reescrever meu código?
Na maioria dos casos, sim. A API da Novita AI é compatível com as bibliotecas de cliente OpenAI e Anthropic. Se você já usa algum desses SDKs, a migração requer apenas alterar a URL base e sua chave de API — nenhuma alteração na lógica dos prompts, na estrutura da chamada do modelo ou no parsing das respostas é necessária. Verifique a página de documentação do modelo na Novita AI para confirmar qual biblioteca de cliente ele suporta. Para uma lista de verificação completa sobre como avaliar plataformas antes de se comprometer e evitar o lock-in de API de LLM, veja Como Trocar de Provedor de API de LLM Sem Lock-In: Lista de Verificação da Plataforma.
Por que a qualidade da saída difere entre provedores que executam o mesmo modelo?
Mesmo com pesos de modelo idênticos, a qualidade da inferência varia com base em como cada provedor configura a quantização, o batching e a infraestrutura de serviço. A Artificial Analysis mede isso diretamente através de execuções repetidas de benchmarks em endpoints ao vivo — e as diferenças são reais, não teóricas.
Como os preços da Novita AI se comparam ao self-hosting do gpt-oss-120B?
O gpt-oss-120B cabe em uma única GPU de 80 GB (NVIDIA H100 ou AMD MI300X). Uma instância H100 em nuvem custa aproximadamente $2–3/hora. Com a taxa da Novita AI de $0,05/1M tokens de entrada, você precisaria processar cerca de 40–60M tokens de entrada por hora para empatar nos custos de infraestrutura — tornando a API significativamente mais custo-efetiva para a maioria das equipes que não operam nesse throughput constante.
Artigos Recomendados
- Como Trocar de Provedor de API de LLM Sem Lock-In: Lista de Verificação da Plataforma
- Top 10 APIs de LLM Mais Baratas em 2026
- Melhores Modelos de IA para OpenClaw Agents em 2026
- GLM-5 vs MiniMax M2.5: Qual Modelo Open-Source de 2026 Vence?
- Melhor Plataforma Cloud de IA para Inferência Serverless de Modelos



