

オープンソースモデル向けの推論APIプロバイダーを選ぶ際に重要なのは、単に「どのモデルが提供されているか」だけではありません。最も低コストで最高の出力品質を実現し、かつ幅広いモデルセレクションを持つプロバイダーはどこか、というのが本質です。同じモデルでも、呼び出し先のプロバイダーによって結果は大きく異なり、価格は最大5倍になることもあります。本記事では、5つの主要プロバイダー(Novita AI、Together AI、Fireworks AI、DeepInfra、Groq)を、実際に重要な3つの観点(モデルカタログの網羅性、価格、実際のベンチマークによる出力品質)で比較します。
推論プロバイダーの選択が重要な理由
サードパーティのAPIを通じてオープンソースモデルを呼び出す場合、モデルの重み自体は同一です。しかし、プロバイダーごとにサービングインフラ、量子化の選択、最適化スタックは大きく異なります。この違いは、ほとんどの開発者が認識している以上に重要です。
例えば、OpenAIの主力オープンウェイトモデル gpt-oss-120B(high) を見てみましょう。プロバイダー間で入力価格は1Mトークンあたり0.05ドルから0.60ドルまで——実に12倍の開きがあります。同一モデルでも、独立したベンチマークで出力品質スコアが測定可能な差で乖離しています。さらに、あるプロバイダーはOpenRouter上で66以上のモデルをサポートしているのに対し、別のプロバイダーは十数個に留まります。これらの違いはプロダクション規模で使用すると累積し、月々のインフラ費用とユーザーが受け取る出力の品質の両方に影響を及ぼします。
比較対象の5つのプロバイダー
数字に入る前に、各プロバイダーの簡単な概要をご紹介します。
Novita AI は、開発者やスタートアップが高性能、高信頼性、コスト効率でモデルやエージェントアプリケーションを構築、デプロイ、スケーリングできるAI&エージェントクラウドプラットフォームです。GLM、MiniMax、Kimi、Qwen、DeepSeek、OpenAIのオープンウェイトgpt-ossシリーズ、MetaのLlamaファミリーなど、幅広いオープンソースモデルをカバーし、すべてを単一のOpenAI互換エンドポイントで提供します。
Together AI は、確立された推論プロバイダーであり、LangChain、LlamaIndexなどのフレームワークを使用するチームに人気があります。競争力のある出力速度で、主流のオープンソースモデルの堅実なセレクションを提供します。
Together AIが有力候補である場合、詳細な比較記事「Together AI vs Novita AI」では、価格、API互換性、バッチジョブ、専用エンドポイント、プロダクションワークフローのトレードオフをより詳しく扱っています。
Fireworks AI は低レイテンシ推論に特化しており、レイテンシに敏感なアプリケーション向けに位置づけられています。モデルカタログはより選択的で、幅広さよりもプロダクション対応モデルを優先しています。このポジショニングをNovita AIのモデルAPI、エージェントサンドボックス、バッチ推論、GPUクラウドと比較するチーム向けに、専用の「Fireworks AIの代替」ガイドを用意しています。
DeepInfra は、幅広いモデルカタログと一貫して競争力のある価格を提供しており、生のモデルバラエティを重視するコスト重視のワークロードでよく選ばれています。
Groq はスピードに特化して設計されており、カスタムLPUハードウェアを使用して非常に高いトークンスループットを実現します。モデルカタログは意図的に小さく、Groqのハードウェアアーキテクチャから最も恩恵を受けるモデルに最適化されています。
![]()
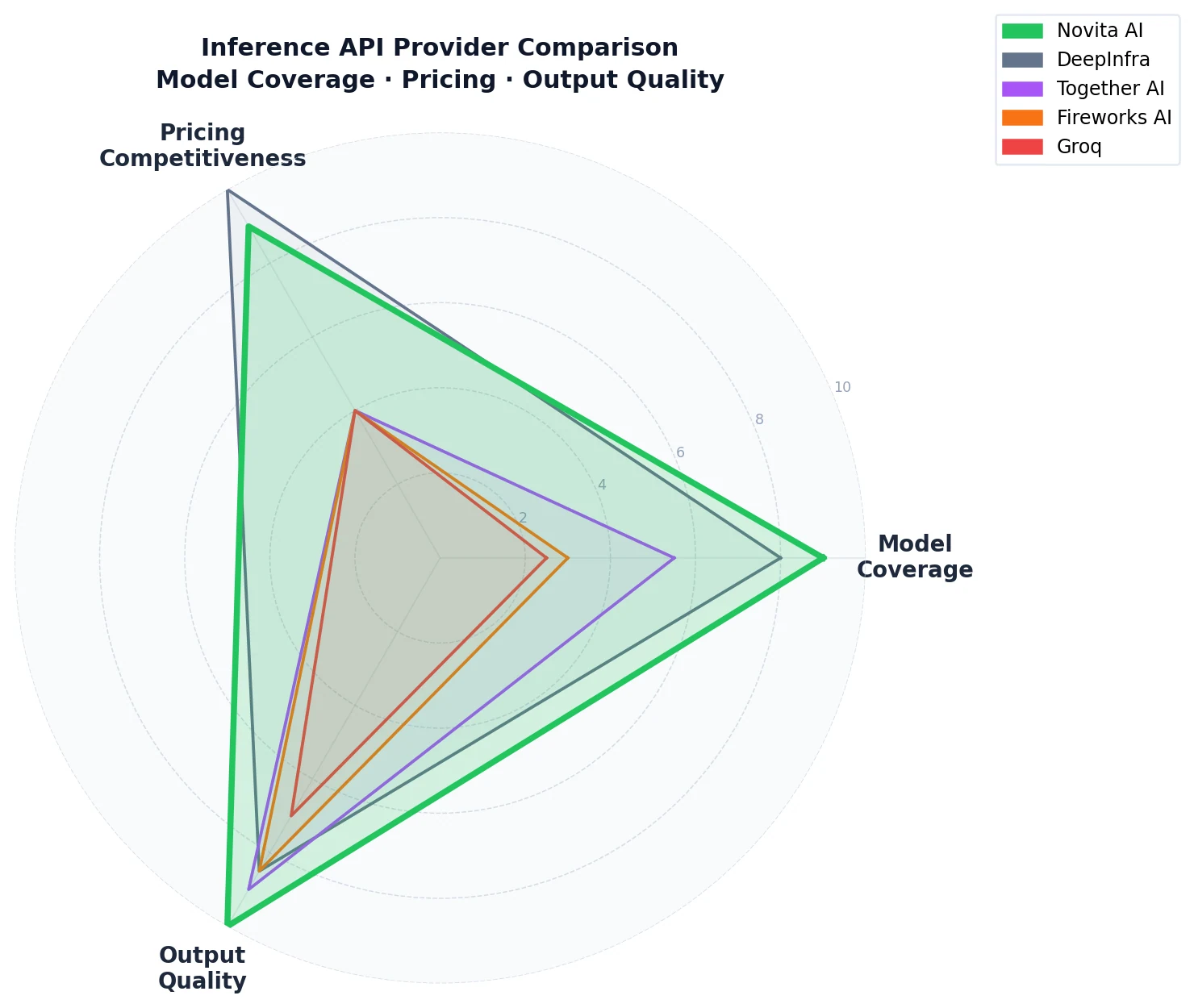
各プロバイダーのモデルカタログはどの程度の広さか?
利用可能なモデルの幅は、インフラを単一プロバイダーに統合できるか、それともユースケースごとに複数のAPIキーを維持する必要があるかを決定します。
OpenRouterのプロバイダーリーダーボード(日間トークン量でソート)は、どの推論プロバイダーが最も多くのプロダクショントラフィックを処理しているかを示す、直接的で現実的なシグナルです。DeepInfraより上位にランクインしている12のプロバイダーのうち、ほとんどはファーストパーティのモデルプロバイダー(Xiaomi、Alibaba Cloud、Google Vertex、Amazon Bedrock、MiniMax、xAI、OpenAI、StepFun、Google AI Studio、Z.ai)であり、主に自社モデルを提供しています。クローズドソースモデルベンダーとモデル作成者を除くと、Novita AIはOpenRouter上で日間トークン量においてサードパーティ推論プロバイダーの中で第1位であり、1日あたり1,358億トークン、1ヶ月あたり4.6兆トークンを66の利用可能モデルで処理しています。
DeepInfraは、OpenRouter上で75モデル、日間1,036億トークンで最も近い競合です。Together AI、Fireworks AI、Groqはこのランキングの上位には登場しません。
OpenRouter上のモデル数は、プラットフォームを通じてアクティブに提供されているモデルを反映しています。比較のため、Artificial Analysisでは各プロバイダーのAPIエンドポイント全体で以下のように追跡しています:
| プロバイダー | OpenRouter上のモデル数 |
| Novita AI | 66 |
| DeepInfra | 75 |
| Together AI | 28 |
| Groq | 8 |
| Fireworks AI | 7 |
66モデルという数字は、OpenRouter上でのNovita AIの掲載状況を反映しています。Novita AIの完全なAPIカタログは現在200以上のモデルをサポートしており、OpenRouterではまだ利用できないモデルも含まれます。完全なリストはnovita.ai/modelsをご覧ください。
価格比較:Novita AIが明確なコスト優位性を持つ領域
各プロバイダーの公式価格ページから、OpenAIのgpt-ossモデル(2025年8月リリース、Apache 2.0ライセンス、OpenAI初のオープンウェイトモデル、現在は主要推論プロバイダーで広くサポート)の価格を直接取得しました。
gpt-oss-120B(high)— プロバイダー間の価格
| プロバイダー | ** 入力(1Mあたり)** | ** 出力(1Mあたり)** |
| Novita AI | $0.05 | $0.25 |
| DeepInfra | $0.04 | $0.19 |
| Together AI | $0.15 | $0.60 |
| Fireworks AI | $0.15 | $0.60 |
| Groq | $0.15 | $0.60 |
gpt-oss-20B(low)— プロバイダー間の価格
| プロバイダー | ** 入力(1Mあたり)** | ** 出力(1Mあたり)** |
| Novita AI | $0.04 | $0.15 |
| Together AI | $0.05 | $0.20 |
| Fireworks AI | $0.07 | $0.30 |
| Groq | $0.08 | $0.30 |
| DeepInfra | N/A | N/A |
*価格は2026年3月時点、各プロバイダーの公式価格ページから引用。
同一モデルでもプロバイダー間で価格は最大5.9倍異なります。gpt-oss-20Bの場合、Novita AIは1Mトークンあたりブレンド0.07ドルで最も安い選択肢です。gpt-oss-120Bの場合、Novita AIはDeepInfraのすぐ上に位置しますが、Together AI、Fireworks、Groq(いずれもブレンド0.26ドルでNovitaの約2.6倍)よりもはるかに低価格です。
プロダクションスケールでの実際の影響
gpt-oss-120B(high)で月間1億入力トークン+3,300万出力トークンを実行するチームの場合:
| プロバイダー | ** 月額コスト ** | Novita AIとの差 |
| Novita AI | 約10ドル | — |
| DeepInfra | 約8ドル | −2ドル |
| Together AI | 約26ドル | +16ドル |
| Fireworks AI | 約26ドル | +16ドル |
| Groq | 約26ドル | +16ドル |
Together AI、Fireworks、GroqからNovita AIに切り替えると、この単一モデルで月に約190ドルの節約になります。DeepSeek、Llama、GLM、Qwenのバリアントを同時に含むマルチモデルのプロダクションスタック全体では、節約額は比例して拡大します。Novita AIの価格ページで、全モデルカタログの現在のレートを確認できます。
出力品質スコア:すべてのプロバイダーがモデルを同等にサービスしているわけではない
価格は話の半分に過ぎません。Artificial Analysisは、各プロバイダーエンドポイントの実際の出力品質を独立してベンチマークしています。つまり、プロバイダー間で同じプロンプトを実行し、スループットやアップタイムだけでなく実際の応答品質を測定します。
gpt-oss-120B(high)の場合、結果は明白です。GPQA Diamond(科学的知識と推論、N=16独立実行)で評価された5つのプロバイダーのうち、Novita AIが最高スコアを記録しました:
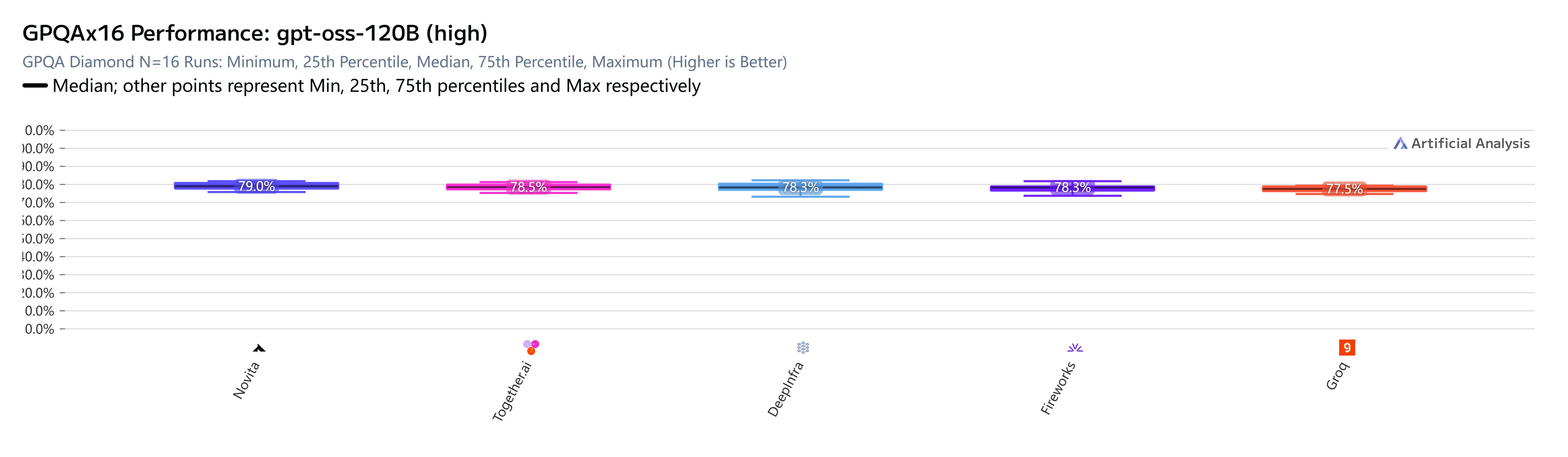
GPQAのスプレッドは一見小さいように見えますが(79.0% vs 77.5%)、これらは特に難しいベンチマークでの16回の独立実行の中央値です。この難易度での1.5パーセンテージポイントの差は無視できません。これは各プロバイダーのサービングスタックがモデルの推論チェーンをどのように処理するかにおける実際の違いを反映しています。
推論負荷の高いワークロード(エージェントパイプライン、コード生成、複雑なQ&A)では、Novita AIで単に支払いが少なくなるだけでなく、測定可能なほど優れた出力が得られることになります。
ユースケースに適したプロバイダーの選び方
Novita AIを選ぶべき場合:
- フロンティアモデル、OpenAIオープンウェイト、Meta Llamaなど、幅広いオープンソースモデルをカバーする単一のAPIが必要な場合
- スケール時のコスト効率が優先事項である場合(特に120B+層)
- 推論、エージェント、数学など、出力品質の違いが累積するワークロードに取り組んでいる場合
- サードパーティ推論プロバイダーの中で最も高い日間トークン量に裏打ちされたプロダクショングレードの信頼性を求める場合
Groqを選ぶべき場合:
- 生のトークン/秒のスループットが第一要件である場合
- レイテンシに敏感なインタラクティブアプリケーションを、小さく固定されたモデルセットで構築している場合
Together AIを選ぶべき場合:
- スタックがすでにLangChain、LlamaIndex、または類似のフレームワークと統合されている場合
- 速度と適度なモデルカタログのバランスを求めている場合
DeepInfraを選ぶべき場合:
- 絶対的に最も低いブレンド価格が唯一の基準である場合
- モデルカタログの幅や出力品質スコアが二次的な関心事である場合
Fireworks AIを選ぶべき場合:
- 最初のトークンまでの時間を最小化することが重要で、より小さなモデルセレクションで作業できる場合
プロジェクトでNovita AIを使い始める方法
ステップ1:APIキーを取得する
- novita.aiにサインアップします
- 設定 → API Keys に移動します
- 「Create New Key」をクリックし、安全に保管してください——パスワードと同様に扱ってください
ステップ2:最初のAPI呼び出しを行う
Novita AIはOpenAIとAnthropicの両方のクライアントライブラリをサポートしています。ベースURLとAPIキーを更新するだけで切り替えられます。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
別のモデルを試すには、modelパラメータを変更するだけです——他の設定変更は不要です。完全なカタログはnovita.ai/modelsでご覧ください。
結論
データを並べて比較すると、状況は明らかです。Novita AIは、モデルカタログの幅広さ、競争力のある価格、検証済みの出力品質の組み合わせにおいて、サードパーティ推論プロバイダーの中でリードしています。特に推論モデルやマルチモデルパイプラインを含むほとんどのプロダクションワークロードにおいて、強力な総合価値を提供します。
Novita AIは今すぐ利用可能です——GPUのセットアップも予約容量も不要で、使った分だけ支払います。上記のコード例から始めるか、Novita AI Playground で完全なモデルカタログを探索してください。
Novita AIは、開発者やスタートアップが高性能、高信頼性、コスト効率でモデルやエージェントアプリケーションを構築、デプロイ、スケーリングできるAI&エージェントクラウドプラットフォームです。
よくある質問
コードを書き直さずに、別の推論プロバイダーからNovita AIに切り替えられますか?
ほとんどの場合、はい。Novita AIのAPIはOpenAIとAnthropicの両方のクライアントライブラリと互換性があります。すでにいずれかのSDKを使用している場合、ベースURLとAPIキーを変更するだけで切り替えられ、プロンプトロジック、モデル呼び出し構造、レスポンス解析の変更は必要ありません。モデルのドキュメントページで、どのクライアントライブラリをサポートしているかを確認してください。プラットフォームを評価するための完全なチェックリストについては、LLM APIプロバイダーの切り替えとロックイン回避のためのプラットフォームチェックリストをご覧ください。
同じモデルを実行しているのに、プロバイダーによって出力品質が異なるのはなぜですか?
モデルの重みが同じでも、各プロバイダーが量子化、バッチ処理、サービングインフラをどのように構成するかによって推論品質は異なります。Artificial Analysisは、ライブエンドポイントでのベンチマーク実行を繰り返し実施することでこれを直接測定しており、その違いは理論的なものではなく実際のものです。
Novita AIの価格は、gpt-oss-120Bのセルフホスティングと比較してどうですか?
gpt-oss-120Bは1枚の80GB GPU(NVIDIA H100またはAMD MI300X)に収まります。クラウドH100インスタンスの料金は約2〜3ドル/時間です。Novita AIの0.05ドル/1M入力トークンのレートでは、インフラコストで損益分岐点に達するには1時間あたり約4,000万〜6,000万入力トークンを処理する必要があります。そのため、APIは一定のスループットで実行していないほとんどのチームにとって、大幅に費用対効果が高くなります。



