

选择合适的大语言模型(LLM)需要在 推理深度 、 速度 、 硬件成本 ** 和 ** 集成需求 之间进行权衡。
本文对比了 GPT‑OSS‑120B 和 Qwen‑3 235B (Thinking 2507) —— 当前两款能力最强的开源模型。
你将了解它们在架构、性能、资源需求、编码能力和实际用例方面的差异,从而确定哪个更适合你的应用场景 —— 从 低延迟聊天机器人 ** 到 ** 高精度代码系统。
GPT OSS 120B 与 Qwen3 235B Thinking 2507:架构
架构详情
| 特性 | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| 总参数量 | 117B | 235B |
| 每 Token 激活参数量 | 5.1B | 22B |
| 激活比例 | 4.36% | 9.36% |
| Transformer 层数 | 36 | 94 |
| MoE 专家数 | 128 | 128 |
| 每 Token 激活专家数 | 4 | 8 |
| 注意力机制 | 交替密集 + 局部带状稀疏注意力,GQA | 未明确说明(可能为标准 + 优化) |
| 量化方式 | MXFP4(4 位) | 未说明 |
| 原生上下文长度 | 128K | 32K |
| 扩展上下文长度 | 未说明(原生已 128K) | 262K+(通过 YaRN 等) |
性能基准
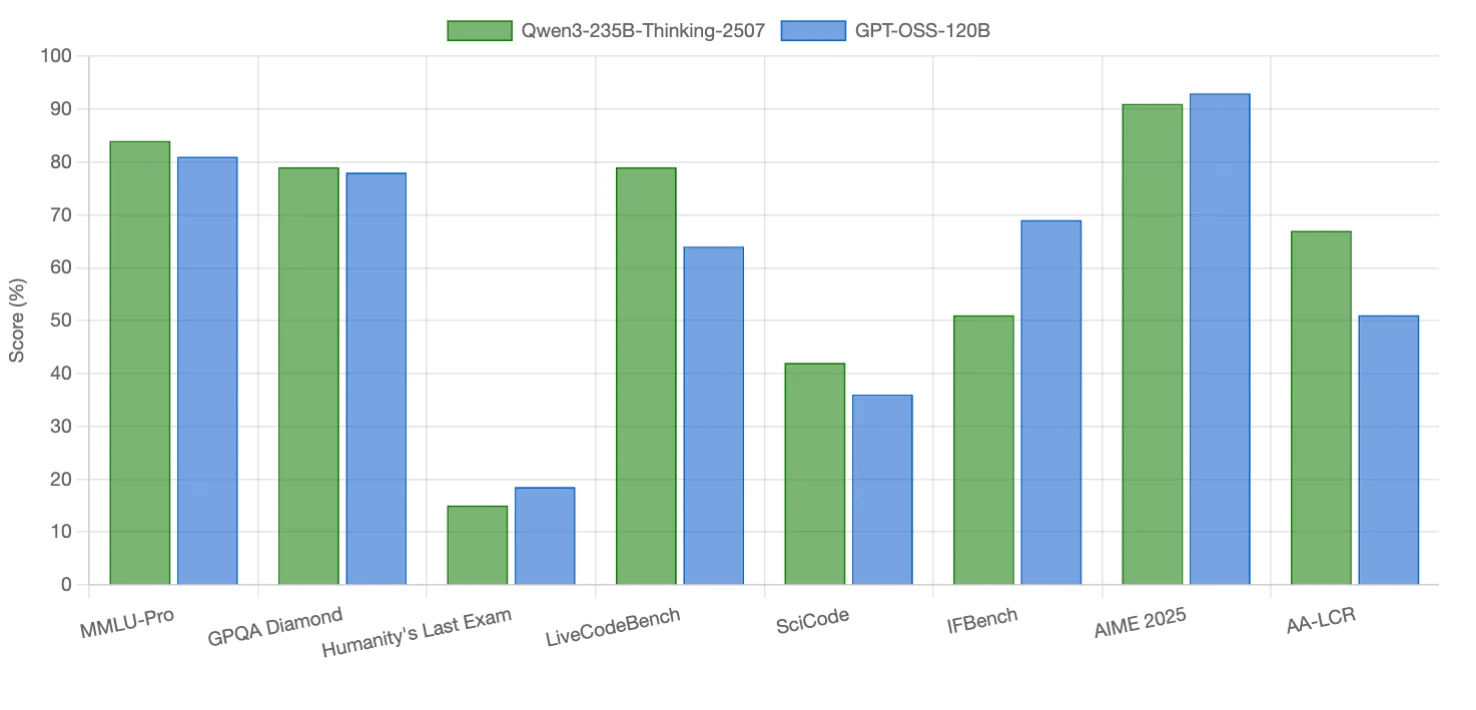
Qwen3-235B-Thinking-2507 在 ** 编码任务 ** 和 ** 长上下文推理 ** 方面表现出色,在一些推理基准上略有优势。GPT-OSS-120B 在 ** 指令遵循 、 竞赛数学 ** 和一个推理密集型基准上表现更优。两者在 ** 科学推理** 方面不相上下(几乎持平)。
GPT OSS 120B 与 Qwen3 235B Thinking 2507:资源需求
GPU 需求
| 模型 | 量化方式 | 所需显存 | GPU 需求* |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611.09 GB | 8 × 80 GB H100/A100 |
| FP8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT4 | 604.45 GB | 8 × 80 GB H100/A100 | |
| GPT-OSS-120B | FP16 | 246.34 GB | 4 × 80 GB H100/A100 |
| Q8 | 124.03 GB | 2 × 80 GB H100/A100 | |
| Q4 | 62.87 GB | 1 × 80 GB H100/A100 |
得益于 MXFP4 量化,GPT OSS 120B 只需一块 80 GB GPU(如 NVIDIA H100 或 A100)即可运行。
关于 GPU 定价,可点击下方按钮获取更多信息。
API 访问
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,并提供经济实惠且可靠的 GPU 云用于构建和扩展。
| 模型 | 上下文长度 | 输入价格 | 输出价格 |
| Qwen3-235B-Thinking-2507 | 131072 上下文 | $0.3 / 1M | $3.0 / 1M |
| GPT-OSS-120B | 131072 上下文 | $0.1 / 1M | $0.5 / 1M |
GPT-OSS-120B 与 Qwen-3 235B Thinking 2507:主要差异
能力差异
| 特性 | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| 可调节的推理深度 | ✅ 支持(低/中/高选项) | ❌ 不支持(固定最大推理) |
| 始终输出思维链(CoT) | ❌ 否(默认隐藏) | ✅ 是( thinking 标记) |
| 开发者可访问隐藏推理 | ✅ 是 | ❌ 否 |
| 切换思考/快速模式 | ✅ 是(支持快速模式) | ❌ 否(仅思考模式) |
| 工具调用能力 | ✅ 支持 | ✅ 支持 |
| 公开安全评估结果 | ✅ 是(对抗性安全测试) | ❌ 提及有限 |
| Apache 2.0 开源许可 | ✅ 是 | ✅ 是 |
应用差异
| 如果你的需求是… | 选择 GPT-OSS-120B | 选择 Qwen-3 235B (Thinking 2507) |
|---|---|---|
| 在有限硬件上运行 | ✅ 单块 80 GB GPU 即可运行(例如 1× NVIDIA H100),得益于 MoE + MXFP4 压缩;还有 20B 变体适用于 16 GB 显存的边缘设备 | ❌ 需要多 GPU 服务器(例如 4×40 GB 或 8×80 GB GPU)才能发挥全部性能 |
| 更低的延迟与推理成本 | ✅ 针对速度和效率优化 | ❌ 更高的延迟和计算成本 |
| 最大推理深度(始终开启) | ❌ 推理深度可调(低/中/高) | ✅ 始终以最大推理深度运行,并附带可见的 thinking 痕迹 |
| 适合研究级推理(数学证明、复杂代码、科学多跳推理) | ❌ 质量高,但注重平衡 | ✅ 在数学、编程竞赛和结构化逻辑方面,开源模型表现顶尖 |
| 通用聊天机器人 / 生产级 AI 助手 | ✅ 指令遵循能力强、工具调用好、低延迟部署 | ❌ 可行,但更重更慢 |
| 与现有 OpenAI API/工具集成 | ✅ API 兼容 OpenAI 工具,Harmony 聊天格式 | ❌ 使用 Qwen 专属聊天模板和工具(SGLang、Qwen-Agent) |
| 多语言交互 | ⚠️ 主要针对英语优化 | ✅ 强大的多语言能力 |
GPT OSS 120B 与 Qwen 3 235B Thinking 2507:代码生成
| 方面 | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| 函数调用(OpenAI API 规范) | ✅ 原生支持 —— 经过训练可直接根据 OpenAI 模式输出 function_call / tool_calls JSON;开箱即用稳定。 |
❌ 不支持原生 —— 可通过提示工程模拟,但需要外部解析/验证来确保稳定。 |
| 工具集成 | ✅ 通过 API 直接兼容 OpenAI 生态系统(Python 解释器、网页搜索、代码执行)。 | ⚠️ 使用 Qwen-Agent / SGLang 进行工具集成;模式不同,从 OpenAI 格式迁移需要适配。 |
| 代码输出长度与风格 | 默认简洁;在优先考虑速度/效率时可能输出部分解决方案(可调节推理深度)。 | 默认输出更长、更完整、可编译的函数,包含更多边界处理和注释。 |
| 代码生成中的推理 | 可调节推理深度(低/中/高);可以跳过冗长推理以加快代码输出。 | 在代码之前始终在 thinking 标记中输出完整推理痕迹,并嵌入更详细的解释。 |
GPT OSS 120B 与 Qwen 3 235B Thinking 2507:高精度、低延迟聊天机器人
你可以根据任务在三个级别中调整适合的推理水平:
- 低: 通用对话的快速响应。
- 中: 平衡速度与细节。
- 高: 深入详细的分析。
推理水平可在系统提示中设置,例如 “Reasoning: high”。
如何通过低成本、快速 API 访问 GPT OSS 120B 和 Qwen3 235B Thinking 2507?
步骤 1:登录并访问模型库
登录你的账户,点击 模型库 按钮。

步骤 2:选择你的模型
浏览可用选项,选择适合你需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。

步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们会为你提供一个新的 API 密钥。进入 “设置” 页面,你可以复制 API 密钥,如图所示。

步骤 5:安装 API
使用你的编程语言对应的包管理器安装 API。
安装后,将必要的库导入到你的开发环境中。使用 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
- GPT‑OSS‑120B 是 ** 需要灵活性、速度和更易部署** 的开发者的首选。
- 可在 单块 80 GB GPU(或更小的 20B 变体用于边缘设备)上运行。
- 可调节的推理深度(
low/medium/high),在每次查询中权衡速度与准确性。 - 原生支持 OpenAI API 的函数调用和工具集成。
- 适用于 生产级助手 、 交互式应用 ** 和 ** 成本敏感型部署。
- Qwen‑3 235B (Thinking 2507) 旨在 ** 每次提供最大推理准确性**。
- 始终以高推理模式运行,并附带
thinking痕迹。 - 在 复杂编码 、 数学证明 ** 和 ** 长上下文推理 方面表现出色。
- 多语言能力强,在研究级任务中表现优异,但需要 多 GPU 配置,且响应速度较慢。
- 最适合 专家顾问 场景,其中正确性优先于速度。
- 始终以高推理模式运行,并附带
结论:
如果 **速度和效率 ** 是你的首要目标 → 选择 GPT‑OSS‑120B。
如果 **复杂推理的准确性 ** 不可妥协 → 选择 Qwen‑3 235B (Thinking 2507)。
常见问题
Qwen‑3 235B 能否使用 OpenAI 的函数调用 API?
不能原生支持。可以通过提示工程模拟格式,但需要外部解析和验证才能获得稳定结果。GPT‑OSS‑120B 开箱即用支持。
哪个模型对硬件要求更低?
GPT‑OSS‑120B —— 得益于 MXFP4 量化,它可以在单块 80 GB GPU 上运行。Qwen‑3 235B 至少需要 4–8 块 GPU 才能发挥全部性能。
哪个更适合实时聊天?
GPT‑OSS‑120B —— 更低的延迟、可调节的推理和更小的激活参数使其响应更快。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,并提供经济实惠且可靠的 GPU 云用于构建和扩展。



