

- GPT OSS 120B vs Qwen3 235B thinking 2507 : Architecture
- GPT OSS 120B vs Qwen3 235B thinking 2507 : Besoins en ressources
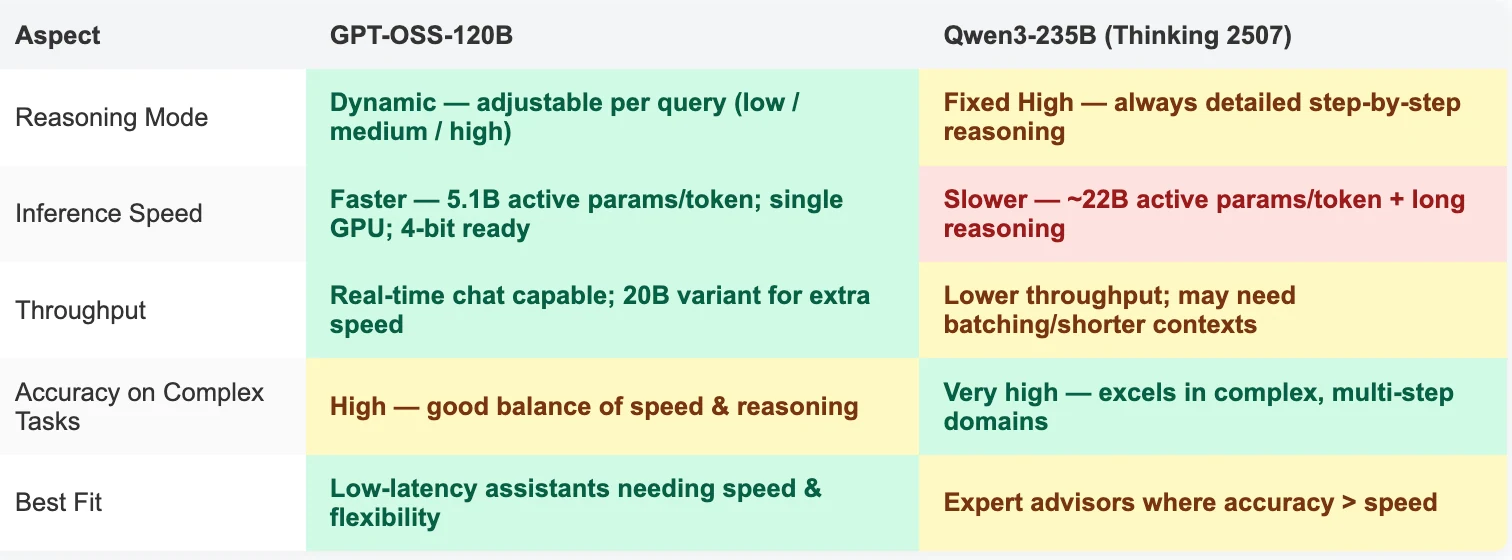
- GPT-OSS-120B vs Qwen-3 235B Thinking 2507 : Différences clés
- GPT OSS 120B vs Qwen 3 235B Thinking 2507 : Génération de code
- GPT OSS 120B vs Qwen 3 235B Thinking 2507 : Chatbot haute précision et faible latence
- Comment accéder à GPT OSS 120B et Qwen3 235B Thinking 2507 via une API rapide et économique ?
Choisir le bon grand modèle de langage (LLM) consiste à trouver un équilibre entre profondeur de raisonnement, vitesse, coût matériel et besoins d’intégration.
Cet article compare GPT‑OSS‑120B et Qwen‑3 235B (Thinking 2507) — deux des modèles open‑source les plus performants du marché.
Vous découvrirez leurs différences en matière d’architecture, de performances, de besoins en ressources, de capacités de codage et de cas d’usage concrets, afin de choisir celui qui convient le mieux à votre application — qu’il s’agisse de chatbots à faible latence ou de systèmes Code de haute précision.
GPT OSS 120B vs Qwen3 235B thinking 2507 : Architecture
Détails architecturaux
| Fonctionnalité | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| Paramètres totaux | 117B | 235B |
| Paramètres activés par jeton | 5.1B | 22B |
| Taux d’activation | 4.36% | 9.36% |
| Couches Transformer | 36 | 94 |
| Experts MoE | 128 | 128 |
| Experts activés par jeton | 4 | 8 |
| Mécanisme d’attention | Alternance d’attention dense et d’attention localement en bande clairsemée, GQA | Non précisé (probablement standard + optimisations) |
| Quantification | MXFP4 (4 bits) | Non précisé |
| Longueur de contexte native | 128K | 32K |
| Longueur de contexte étendue | Non précisé (native déjà 128K) | 262K+ (via YaRN, etc.) |
Benchmarks de performances
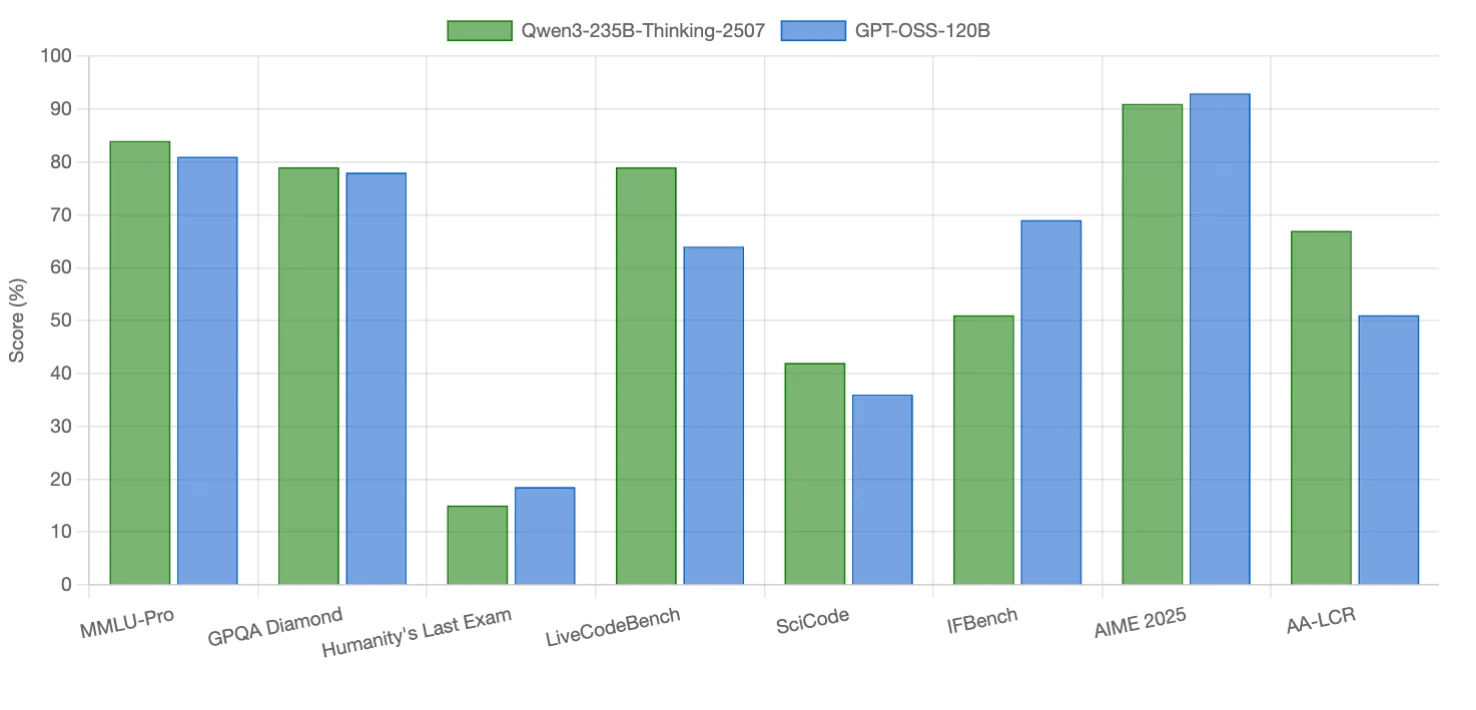
Qwen3-235B-Thinking-2507 excelle dans les tâches de codage et le raisonnement à long contexte, avec de légers avantages sur certains benchmarks de raisonnement. GPT-OSS-120B surpasse dans le suivi d’instructions, les mathématiques de compétition et un benchmark très exigeant en raisonnement. Les deux modèles sont compétitifs en raisonnement scientifique (quasiment à égalité).
GPT OSS 120B vs Qwen3 235B thinking 2507 : Besoins en ressources
Configuration GPU nécessaire
| Modèle | Quantification | VRAM requise | Configuration GPU** |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611,09 Go | 8 × 80 Go H100/A100 |
| FP8 | 606,67 Go | 8 × 80 Go H100/A100 | |
| INT8 | 606,67 Go | 8 × 80 Go H100/A100 | |
| INT4 | 604,45 Go | 8 × 80 Go H100/A100 | |
| GPT-OSS-120B | FP16 | 246,34 Go | 4 × 80 Go H100/A100 |
| Q8 | 124,03 Go | 2 × 80 Go H100/A100 | |
| Q4 | 62,87 Go | 1 × 80 Go H100/A100 |
Grâce à sa quantification MXFP4, GPT OSS 120B peut fonctionner sur un seul GPU de 80 Go, y compris les modèles NVIDIA H100 ou A100.
Pour plus d’informations sur la tarification des GPU, cliquez sur le bouton ci-dessous.
Accès via API
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
| Modèle | Longueur de contexte | Prix d’entrée | Prix de sortie |
| Qwen3-235B-Thinking-2507 | 131072 de contexte | 0,3 $ / 1M | 3,0 $ / 1M |
| GPT-OSS-120B | 131072 de contexte | 0,1 $ / 1M | 0,5 $ / 1M |
GPT-OSS-120B vs Qwen-3 235B Thinking 2507 : Différences clés
Différences dans les capacités
| Fonctionnalité | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Profondeur de raisonnement ajustable | ✅ Oui (options Faible / Moyenne / Élevée) | ❌ Non (raisonnement maximal fixe) |
| Produit toujours une chaîne de pensée (CoT) | ❌ Non (cachée par défaut) | ✅ Oui (balises thinking) |
| Raisonnement caché accessible aux développeurs | ✅ Oui | ❌ Non |
| Bascule entre mode raisonnement / rapide | ✅ Oui (mode rapide disponible) | ❌ Non (mode raisonnement uniquement) |
| Capacité d’utilisation d’outils | ✅ Prise en charge | ✅ Prise en charge |
| Résultats publics d’évaluation de sécurité | ✅ Oui (tests de sécurité adverses) | ❌ Mention limitée |
| Licence open-source Apache 2.0 | ✅ Oui | ✅ Oui |
Différences dans les applications
| Si vous avez besoin de… | Choisissez GPT-OSS-120B | Choisissez Qwen-3 235B (Thinking 2507) |
|---|---|---|
| Fonctionner sur du matériel limité | ✅ Possible sur un seul GPU 80 Go (ex. 1× NVIDIA H100) grâce à MoE + compression MXFP4 ; également une variante 20B pour les appareils périphériques avec 16 Go de VRAM | ❌ Nécessite un serveur multi-GPU (ex. 4×40 Go ou 8×80 Go) pour des performances complètes |
| Latence et coût d’inférence réduits | ✅ Optimisé pour la vitesse et l’efficacité | ❌ Latence et coût de calcul plus élevés |
| Profondeur de raisonnement maximale (toujours active) | ❌ Profondeur de raisonnement ajustable (faible/moyen/élevé) | ✅ Fonctionne toujours à la profondeur de raisonnement maximale avec une trace thinking visible |
| Meilleur pour le raisonnement de niveau recherche (preuves mathématiques, code complexe, multi-sauts scientifiques) | ❌ Haute qualité mais équilibrée | ✅ Performance open-model de premier ordre en mathématiques, compétitions de codage et logique structurée |
| Chatbot polyvalent / assistant IA de production | ✅ Bon suivi d’instructions, utilisation d’outils, déploiement à faible latence | ❌ Possible, mais plus lourd et plus lent |
| Intégration avec les outils/API OpenAI existants | ✅ Compatible API avec les outils OpenAI, format de chat Harmony | ❌ Utilise un template de chat et des outils spécifiques à Qwen (SGLang, Qwen-Agent) |
| Interaction multilingue | ⚠️ Principalement optimisé pour l’anglais | ✅ Forte capacité multilingue |
GPT OSS 120B vs Qwen 3 235B Thinking 2507 : Génération de code
| Aspect | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Appel de fonction (spécification API OpenAI) | ✅ Prise en charge native — entraîné à produire du JSON function_call / tool_calls exactement selon le schéma OpenAI ; stable dès le départ. |
❌ Pas de support natif — peut imiter via ingénierie de prompt, mais nécessite une analyse/validation externe pour la stabilité. |
| Intégration d’outils | ✅ Directement compatible avec l’écosystème OpenAI (interpréteur Python, recherche web, exécution de code) via API. | ⚠️ Utilise Qwen-Agent / SGLang pour l’intégration d’outils ; schéma différent, nécessite une adaptation si vous migrez depuis le format OpenAI. |
| Longueur et style de sortie du code | Concis par défaut ; peut produire des solutions partielles en priorisant la vitesse/l’efficacité (profondeur de raisonnement ajustable). | Fonctions plus longues, plus complètes et compilables par défaut, avec davantage de gestion des cas limites et de commentaires. |
| Raisonnement dans la génération de code | Profondeur de raisonnement ajustable (faible/moyen/élevé) ; peut ignorer le raisonnement verbeux pour un code plus rapide. | Produit toujours une trace de raisonnement complète dans les balises thinking avant le code, avec des explications plus détaillées intégrées. |
GPT OSS 120B vs Qwen 3 235B Thinking 2507 : Chatbot haute précision et faible latence
Vous pouvez ajuster le niveau de raisonnement adapté à votre tâche parmi trois niveaux :
- Faible : réponses rapides pour un dialogue général.
- Moyen : équilibre entre vitesse et détail.
- Élevé : analyse approfondie et détaillée.
Le niveau de raisonnement peut être défini dans les invites système, par exemple « Reasoning: high ».
Comment accéder à GPT OSS 120B et Qwen3 235B Thinking 2507 via une API rapide et économique ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Settings », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM Novita AI. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
- GPT‑OSS‑120B est le choix idéal pour les développeurs ayant besoin de flexibilité, de vitesse et d’un déploiement plus facile.
- Fonctionne sur un seul GPU 80 Go (ou une variante 20B plus petite pour les appareils périphériques).
- Profondeur de raisonnement ajustable (
low/medium/high) pour des compromis entre vitesse et précision par requête. - Prise en charge native de l’appel de fonction et de l’intégration d’outils via l’API OpenAI.
- Idéal pour les assistants de production, les applications interactives et les déploiements sensibles aux coûts.
- Qwen‑3 235B (Thinking 2507) est conçu pour une précision de raisonnement maximale à chaque fois.
- Fonctionne toujours en mode raisonnement élevé avec des traces
thinking. - Excelle dans le codage complexe, les preuves mathématiques et le raisonnement à long contexte.
- Multilingue et performant dans les tâches de niveau recherche, mais nécessite des configurations multi-GPU et accepte des réponses plus lentes.
- Idéal pour les conseillers experts où l’exactitude prime sur la vitesse.
- Fonctionne toujours en mode raisonnement élevé avec des traces
En résumé :
Si la vitesse et l’efficacité sont votre priorité → choisissez GPT‑OSS‑120B.
Si la précision pour un raisonnement complexe est non négociable → choisissez Qwen‑3 235B (Thinking 2507).
Questions fréquentes
Qwen‑3 235B peut-il utiliser l’API d’appel de fonction d’OpenAI ?
Pas nativement. Il peut imiter le format via l’ingénierie de prompt, mais vous aurez besoin d’une analyse et d’une validation externes pour des résultats stables. GPT‑OSS‑120B le prend en charge dès le départ.
Quel modèle nécessite moins de matériel ?
GPT‑OSS‑120B — il peut fonctionner sur un seul GPU 80 Go grâce à la quantification MXFP4. Qwen‑3 235B nécessite au moins 4 à 8 GPU pour des performances complètes.
Quel est le meilleur pour le chat en temps réel ?
GPT‑OSS‑120B — latence plus faible, raisonnement ajustable et paramètres actifs plus petits le rendent plus réactif.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



