

- GPT OSS 120B против Qwen3 235B thinking 2507: Архитектура
- GPT OSS 120B против Qwen3 235B thinking 2507: Требования к ресурсам
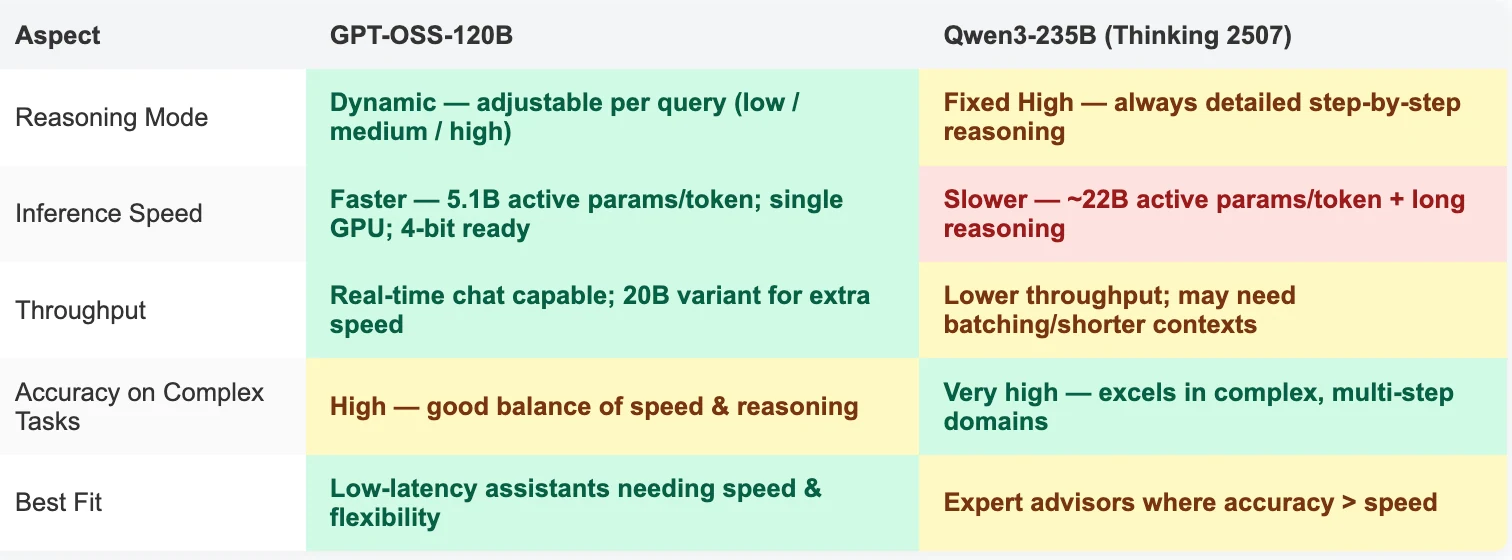
- GPT-OSS-120B против Qwen-3 235B Thinking 2507: Ключевые различия
- GPT OSS 120B против Qwen 3 235B Thinking 2507: Генерация кода
- GPT OSS 120B против Qwen 3 235B Thinking 2507: Высокоточный чат-бот с низкой задержкой
- Как получить доступ к GPT OSS 120B и Qwen3 235B Thinking 2507 через эффективный и быстрый API?
Выбор подходящей большой языковой модели (LLM) требует баланса между глубиной рассуждений, скоростью, стоимостью оборудования и потребностями в интеграции.
В этой статье сравниваются GPT‑OSS‑120B и Qwen‑3 235B (Thinking 2507) — две наиболее мощные открытые модели на сегодняшний день.
Вы узнаете, чем они отличаются по архитектуре, производительности, требованиям к ресурсам, способностям к кодированию и реальным сценариям использования, чтобы решить, какая из них лучше подходит для вашего приложения — от чат-ботов с низкой задержкой до систем с высокой точностью кода.
GPT OSS 120B против Qwen3 235B thinking 2507: Архитектура
Детали архитектуры
| Особенность | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| Всего параметров | 117B | 235B |
| Активируемых параметров на токен | 5.1B | 22B |
| Коэффициент активации | 4.36% | 9.36% |
| Слои трансформера | 36 | 94 |
| Эксперты MoE | 128 | 128 |
| Экспертов, активируемых на токен | 4 | 8 |
| Механизм внимания | Чередование плотного и локально ленточного разреженного внимания, GQA | Не указано явно (вероятно, стандартный + оптимизации) |
| Квантование | MXFP4 (4-бит) | Не указано |
| Родная длина контекста | 128K | 32K |
| Расширенная длина контекста | Не указано (родная уже 128K) | 262K+ (через YaRN и т.д.) |
Бенчмарк производительности
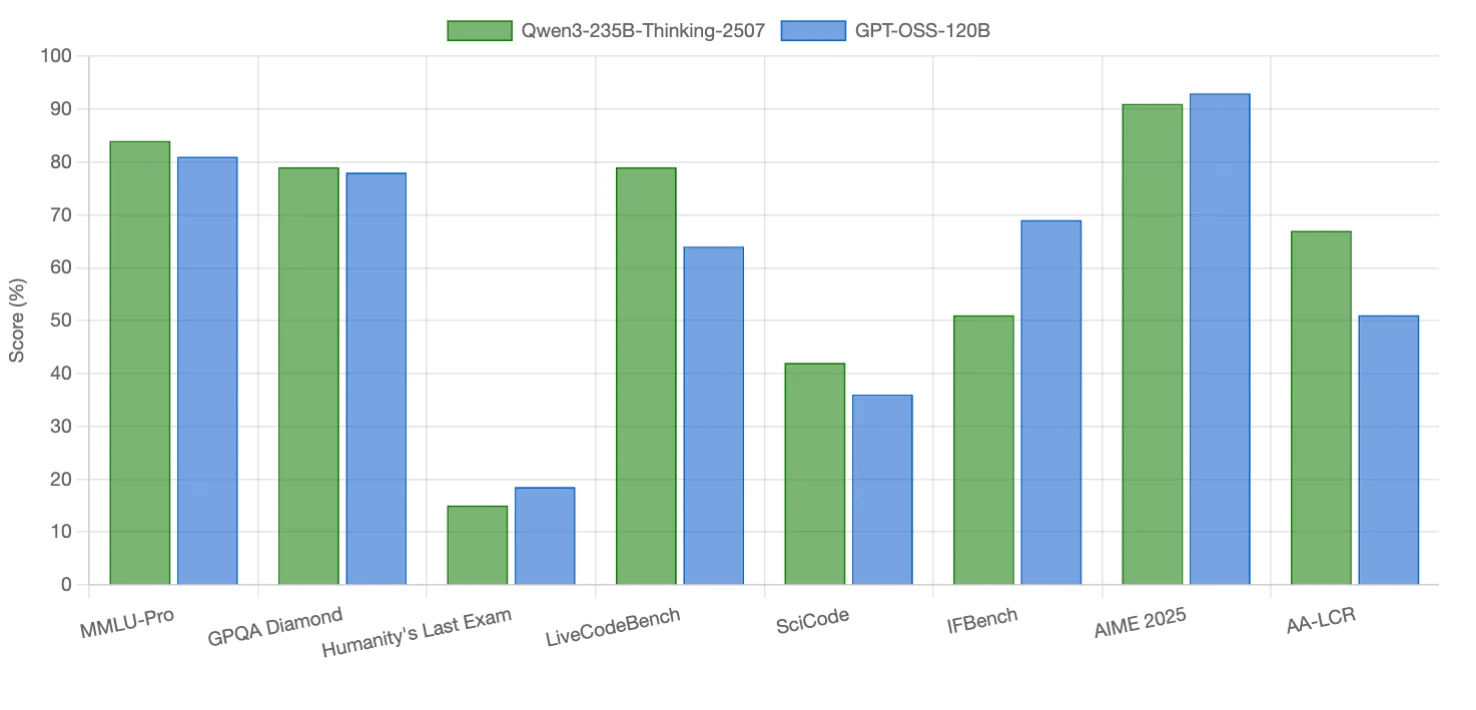
Qwen3-235B-Thinking-2507 превосходит в задачах кодирования и рассуждениях с длинным контекстом, имея небольшое преимущество в некоторых бенчмарках рассуждений. GPT-OSS-120B показывает лучшие результаты в следовании инструкциям, конкурсной математике и одном ресурсоёмком бенчмарке рассуждений. Обе модели конкурентоспособны в научных рассуждениях (почти равны).
GPT OSS 120B против Qwen3 235B thinking 2507: Требования к ресурсам
Потребности в GPU
| Модель | Квантование | Требуемая VRAM | Требования к GPU* |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611.09 GB | 8 × 80 GB H100/A100 |
| FP8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT4 | 604.45 GB | 8 × 80 GB H100/A100 | |
| GPT-OSS-120B | FP16 | 246.34 GB | 4 × 80 GB H100/A100 |
| Q8 | 124.03 GB | 2 × 80 GB H100/A100 | |
| Q4 | 62.87 GB | 1 × 80 GB H100/A100 |
Благодаря использованию квантования MXFP4, GPT OSS 120B может работать на одном 80 ГБ GPU, включая такие модели, как NVIDIA H100 или A100.
Что касается цен на GPU, нажмите кнопку ниже, чтобы получить дополнительную информацию.
Доступ через API
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для создания и масштабирования.
| Модель | Длина контекста | Цена входных данных | Цена выходных данных |
| Qwen3-235B-Thinking-2507 | 131072 контекст | $0.3 / 1M | $3.0/ 1M |
| GPT-OSS-120B | 131072 контекст | $0.1 / 1M | $0.5 / 1M |
GPT-OSS-120B против Qwen-3 235B Thinking 2507: Ключевые различия
Различия в возможностях
| Особенность | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Регулируемая глубина рассуждений | ✅ Да (Низкий / Средний / Высокий) | ❌ Нет (Фиксированное максимальное рассуждение) |
| Всегда выводит цепочку мыслей (CoT) | ❌ Нет (По умолчанию скрыта) | ✅ Да (теги thinking) |
| Доступные разработчику скрытые рассуждения | ✅ Да | ❌ Нет |
| Переключение между режимом размышления / быстрым режимом | ✅ Да (Доступен быстрый режим) | ❌ Нет (Только режим размышления) |
| Возможность использования инструментов | ✅ Поддерживается | ✅ Поддерживается |
| Публичные результаты оценки безопасности | ✅ Да (Тестирование на устойчивость к атакам) | ❌ Ограниченные упоминания |
| Открытая лицензия Apache 2.0 | ✅ Да | ✅ Да |
Различия в применении
| Если вам нужно… | Выберите GPT-OSS-120B | Выберите Qwen-3 235B (Thinking 2507) |
|---|---|---|
| Работа на ограниченном оборудовании | ✅ Возможна работа на одном GPU 80 ГБ (например, 1× NVIDIA H100) благодаря MoE + сжатию MXFP4; также есть вариант 20B для периферийных устройств с 16 ГБ VRAM | ❌ Требуется многопроцессорный сервер (например, 4×40 ГБ или 8×80 ГБ GPU) для полной производительности |
| Низкая задержка и стоимость вывода | ✅ Оптимизирован для скорости и эффективности | ❌ Более высокая задержка и вычислительные затраты |
| Максимальная глубина рассуждений (всегда включена) | ❌ Глубина рассуждений настраивается (низкий/средний/высокий) | ✅ Всегда работает на максимальной глубине рассуждений с видимым следом thinking |
| Лучший для исследовательских рассуждений (математические доказательства, сложный код, научные многошаговые) | ❌ Высокое качество, но настроено на баланс | ✅ Лучшая производительность среди открытых моделей в математике, конкурсах по программированию и структурированной логике |
| Чат-бот общего назначения / производственный AI-ассистент | ✅ Сильное следование инструкциям, использование инструментов, развертывание с низкой задержкой | ❌ Возможно, но тяжелее и медленнее |
| Интеграция с существующими API OpenAI/инструментами | ✅ API-совместим с инструментами OpenAI, формат общения Harmony | ❌ Использует собственный шаблон чата и инструменты Qwen (SGLang, Qwen-Agent) |
| Многоязычное взаимодействие | ⚠️ В основном оптимизирован для английского | ✅ Сильная многоязычная поддержка |
GPT OSS 120B против Qwen 3 235B Thinking 2507: Генерация кода
| Аспект | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Вызов функций (спецификация API OpenAI) | ✅ Встроенная поддержка — обучен выводить JSON function_call / tool_calls точно по схеме OpenAI; стабильная работа «из коробки». |
❌ Встроенной поддержки нет — можно имитировать через инженерию промптов, но для стабильности требуется внешний парсинг/валидация. |
| Интеграция инструментов | ✅ Прямая совместимость с экосистемой OpenAI (интерпретатор Python, веб-поиск, выполнение кода) через API. | ⚠️ Использует Qwen-Agent / SGLang для интеграции инструментов; другая схема, требует адаптации при миграции с формата OpenAI. |
| Длина и стиль выходного кода | По умолчанию лаконичен; может выдавать частичные решения в приоритете скорости/эффективности (настраиваемая глубина рассуждений). | По умолчанию более длинные, полные, компилируемые функции с большей обработкой крайних случаев и комментариями. |
| Рассуждения при генерации кода | Настраиваемая глубина рассуждений (низкая/средняя/высокая); можно пропустить подробные рассуждения для более быстрого вывода кода. | Всегда выводит полный след рассуждений в тегах thinking перед кодом, с более подробными объяснениями. |
GPT OSS 120B против Qwen 3 235B Thinking 2507: Высокоточный чат-бот с низкой задержкой
Вы можете настроить уровень рассуждений, подходящий для вашей задачи, на трёх уровнях:
- Низкий: Быстрые ответы для общего диалога.
- Средний: Сбалансированная скорость и детализация.
- Высокий: Глубокий и детальный анализ.
Уровень рассуждений можно задать в системных промптах, например, “Reasoning: high”.
Как получить доступ к GPT OSS 120B и Qwen3 235B Thinking 2507 через эффективный и быстрый API?
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Model Library.

Шаг 2: Выберите свою модель
Просмотрите доступные варианты и выберите модель, которая соответствует вашим потребностям.

Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.

Шаг 4: Получите свой API-ключ
Для аутентификации с помощью API мы предоставим вам новый API-ключ. Перейдя на страницу “Settings”, вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с помощью вашего API-ключа, чтобы начать взаимодействие с Novita AI LLM. Это пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
- GPT‑OSS‑120B — это выбор для разработчиков, которым нужна гибкость, скорость и простота развертывания.
- Работает на одном GPU 80 ГБ (или меньшем варианте 20B для периферийных устройств).
- Регулируемая глубина рассуждений (
low/medium/high) для компромисса между скоростью и точностью для каждого запроса. - Встроенная поддержка вызова функций API OpenAI и интеграции инструментов.
- Идеален для производственных ассистентов, интерактивных приложений и развертываний, чувствительных к стоимости.
- Qwen‑3 235B (Thinking 2507) создан для максимальной точности рассуждений каждый раз.
- Всегда работает в режиме высоких рассуждений с
thinkingтрассировкой. - Превосходит в сложном кодировании, математических доказательствах и рассуждениях с длинным контекстом.
- Многоязычен и силен в исследовательских задачах, но требует многопроцессорных конфигураций GPU и допускает более медленные ответы.
- Лучше всего подходит для экспертных советников, где точность важнее скорости.
- Всегда работает в режиме высоких рассуждений с
Итог:
Если скорость и эффективность — ваш приоритет → выбирайте GPT‑OSS‑120B.
Если точность для сложных рассуждений не подлежит обсуждению → выбирайте Qwen‑3 235B (Thinking 2507).
Часто задаваемые вопросы
Может ли Qwen‑3 235B использовать API вызова функций OpenAI?
Не нативно. Он может имитировать формат с помощью инженерии промптов, но для стабильных результатов потребуется внешний парсинг и валидация. GPT‑OSS‑120B поддерживает это «из коробки».
Какой модели требуется меньше оборудования?
GPT‑OSS‑120B — он может работать на одном GPU 80 ГБ благодаря квантованию MXFP4. Qwen‑3 235B требует как минимум 4–8 GPU для полной производительности.
Какая модель лучше для чата в реальном времени?
GPT‑OSS‑120B — более низкая задержка, настраиваемые рассуждения и меньший размер активных параметров делают его более отзывчивым.
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для создания и масштабирования.



