

- GPT OSS 120B vs Qwen3 235B Thinking 2507: Architektur
- GPT OSS 120B vs Qwen3 235B Thinking 2507: Ressourcenanforderungen
- GPT-OSS-120B vs Qwen-3 235B Thinking 2507: Hauptunterschiede
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: Code-Generierung
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: Hochgenauer, latenzarmer Chatbot
- Wie greife ich kosteneffizient und schnell per API auf GPT OSS 120B und Qwen3 235B Thinking 2507 zu?
Die Wahl des richtigen Large Language Models (LLM) bedeutet, eine gute Balance zwischen Argumentationstiefe, Geschwindigkeit, Hardwarekosten und Integrationsanforderungen zu finden.
Dieser Artikel vergleicht GPT‑OSS‑120B und Qwen‑3 235B (Thinking 2507) – zwei der leistungsfähigsten Open‑Source‑Modelle der heutigen Zeit.
Sie erfahren, wie sie sich in Architektur, Leistung, Ressourcenanforderungen, Code-Fähigkeiten und realen Anwendungsfällen unterscheiden, sodass Sie entscheiden können, welches Modell am besten zu Ihrer Anwendung passt – von Chatbots mit niedriger Latenz bis hin zu hochgenauen Code-Systemen.
GPT OSS 120B vs Qwen3 235B Thinking 2507: Architektur
Architekturdetails
| Feature | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| Gesamtparameter | 117B | 235B |
| Aktivierte Parameter pro Token | 5,1B | 22B |
| Aktivierungsverhältnis | 4,36 % | 9,36 % |
| Transformer-Layer | 36 | 94 |
| MoE-Experten | 128 | 128 |
| Aktivierte Experten pro Token | 4 | 8 |
| Aufmerksamkeitsmechanismus | Alternierende dichte + lokal gebänderte sparse Aufmerksamkeit, GQA | Nicht explizit angegeben (wahrscheinlich Standard + Optimierungen) |
| Quantisierung | MXFP4 (4-Bit) | Nicht angegeben |
| Native Kontextlänge | 128K | 32K |
| Erweiterte Kontextlänge | Nicht angegeben (nativ bereits 128K) | 262K+ (via YaRN, etc.) |
Leistungsbenchmark
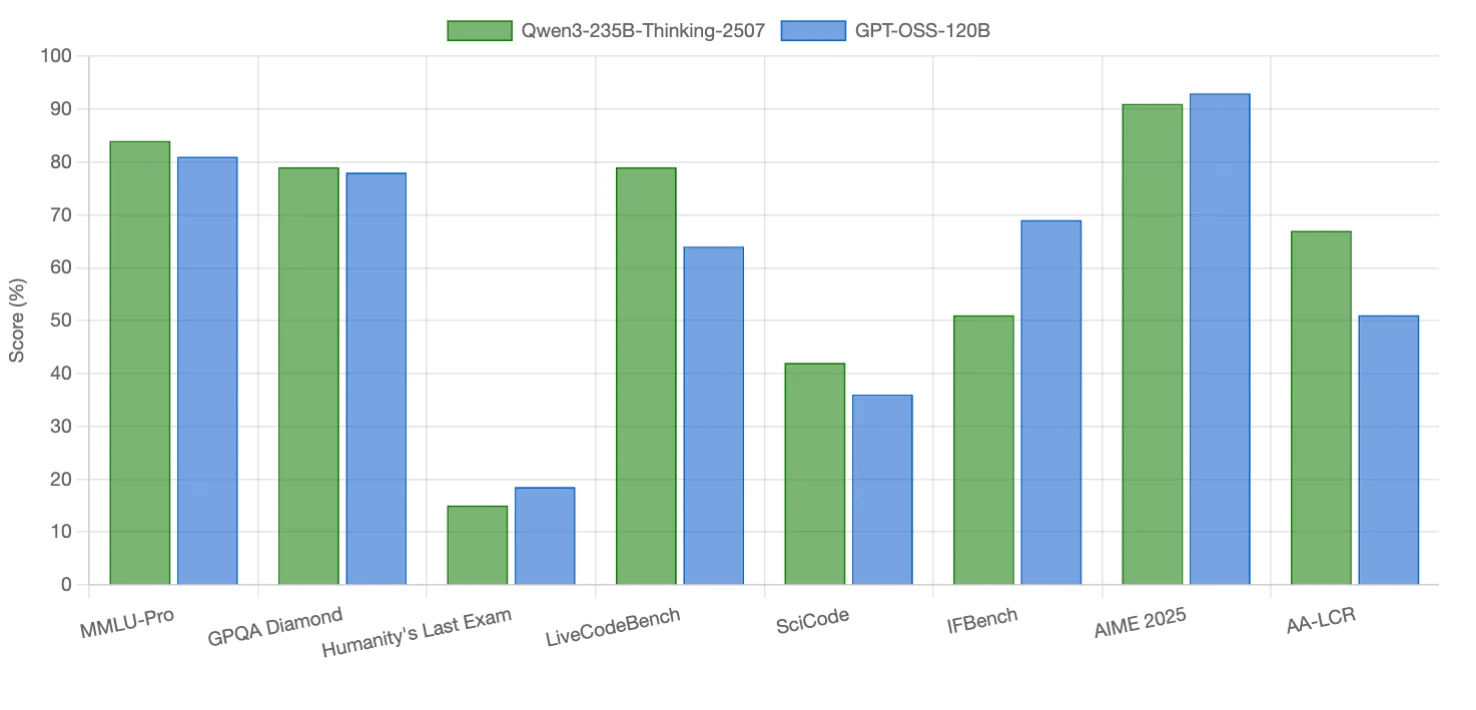
Qwen3-235B-Thinking-2507 zeichnet sich bei Code-Aufgaben und Langkontext-Argumentation aus, mit kleinen Vorteilen bei einigen Argumentations-Benchmarks. GPT-OSS-120B übertrifft in Instruktionsbefolgung, Wettbewerbsmathematik und einem argumentationsintensiven Benchmark. Beide Modelle sind in wissenschaftlicher Argumentation konkurrenzfähig (nahezu gleichauf).
GPT OSS 120B vs Qwen3 235B Thinking 2507: Ressourcenanforderungen
GPU-Anforderungen
| Modell | Quantisierung | Erforderlicher VRAM | GPU-Anforderung* |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611,09 GB | 8 × 80 GB H100/A100 |
| FP8 | 606,67 GB | 8 × 80 GB H100/A100 | |
| INT8 | 606,67 GB | 8 × 80 GB H100/A100 | |
| INT4 | 604,45 GB | 8 × 80 GB H100/A100 | |
| GPT-OSS-120B | FP16 | 246,34 GB | 4 × 80 GB H100/A100 |
| Q8 | 124,03 GB | 2 × 80 GB H100/A100 | |
| Q4 | 62,87 GB | 1 × 80 GB H100/A100 |
Dank der Verwendung von MXFP4-Quantisierung kann GPT OSS 120B auf einer einzelnen 80-GB-GPU ausgeführt werden, einschließlich Modellen wie NVIDIA H100 oder A100.
Informationen zu GPU-Preisen erhalten Sie, indem Sie auf die Schaltfläche unten klicken.
API-Zugriff
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
| Modell | Kontextlänge | Eingabepreis | Ausgabepreis |
| Qwen3-235B-Thinking-2507 | 131072 Kontext | $0,3 / 1M | $3,0 / 1M |
| GPT-OSS-120B | 131072 Kontext | $0,1 / 1M | $0,5 / 1M |
GPT-OSS-120B vs Qwen-3 235B Thinking 2507: Hauptunterschiede
Unterschiede in den Fähigkeiten
| Feature | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Anpassbare Argumentationstiefe | ✅ Ja (Optionen Niedrig / Mittel / Hoch) | ❌ Nein (Feste maximale Argumentation) |
| Gibt immer Chain-of-Thought (CoT) aus | ❌ Nein (standardmäßig verborgen) | ✅ Ja ( thinking Tags) |
| Für Entwickler zugängliche verborgene Argumentation | ✅ Ja | ❌ Nein |
| Wechsel zwischen Denk- / Schnellmodus | ✅ Ja (Schnellmodus verfügbar) | ❌ Nein (Nur Denkmodus) |
| Toolnutzungsfähigkeit | ✅ Unterstützt | ✅ Unterstützt |
| Öffentliche Sicherheitsbewertungsergebnisse | ✅ Ja (Adversarial Safety Testing) | ❌ Eingeschränkte Erwähnung |
| Apache 2.0 Open-Source-Lizenz | ✅ Ja | ✅ Ja |
Unterschiede in der Anwendung
| Wenn Sie brauchen… | Wählen Sie GPT-OSS-120B | Wählen Sie Qwen-3 235B (Thinking 2507) |
|---|---|---|
| Ausführung auf begrenzter Hardware | ✅ Einzelne 80-GB-GPU möglich (z.B. 1× NVIDIA H100) dank MoE + MXFP4-Kompression; es gibt auch eine 20B-Variante für Edge-Geräte mit 16 GB VRAM | ❌ Erfordert Multi-GPU-Server (z.B. 4×40 GB oder 8×80 GB GPUs) für volle Leistung |
| Niedrigere Latenz & Inferenzkosten | ✅ Optimiert für Geschwindigkeit und Effizienz | ❌ Höhere Latenz und Rechenkosten |
| Maximale Argumentationstiefe (immer an) | ❌ Argumentationstiefe einstellbar (niedrig/mittel/hoch) | ✅ Läuft immer mit maximaler Argumentationstiefe mit sichtbarer thinking-Spur |
| Am besten für forschungsnahe Argumentation (mathematische Beweise, komplexer Code, wissenschaftliche Multi-Hop) | ❌ Hochwertig, aber auf Ausgewogenheit abgestimmt | ✅ Top-Leistung bei Open-Modellen in Mathematik, Programmierwettbewerben und strukturierter Logik |
| Allzweck-Chatbot / Produktions-KI-Assistent | ✅ Starke Instruktionsbefolgung, Toolnutzung, niedrige Latenz bei der Bereitstellung | ❌ Möglich, aber schwerer und langsamer |
| Integration mit vorhandenen OpenAI-APIs/Tools | ✅ API-kompatibel mit OpenAI-Tools, Harmony Chat-Format | ❌ Verwendet Qwen-spezifisches Chat-Template & Tools (SGLang, Qwen-Agent) |
| Mehrsprachige Interaktion | ⚠️ Hauptsächlich für Englisch optimiert | ✅ Starke mehrsprachige Fähigkeit |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: Code-Generierung
| Aspekt | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Funktionsaufruf (OpenAI-API-Spezifikation) | ✅ Native Unterstützung – trainiert, um function_call / tool_calls JSON exakt nach OpenAI-Schema auszugeben; stabil out-of-the-box. |
❌ Keine native Unterstützung – kann per Prompt-Engineering nachgeahmt werden, erfordert jedoch externes Parsing/Validierung für Stabilität. |
| Tool-Integration | ✅ Direkt kompatibel mit OpenAI-Ökosystem (Python-Interpreter, Websuche, Code-Ausführung) über API. | ⚠️ Verwendet Qwen-Agent / SGLang für Tool-Integration; anderes Schema, erfordert Anpassung bei Migration von OpenAI-Format. |
| Code-Ausgabelänge & -Stil | Standardmäßig prägnant; kann bei Priorisierung von Geschwindigkeit/Effizienz partielle Lösungen liefern (einstellbare Argumentationstiefe). | Standardmäßig längere, vollständigere, kompilierbare Funktionen mit mehr Edge-Case-Behandlung und Kommentaren. |
| Argumentation bei der Code-Generierung | Einstellbare Argumentationstiefe (niedrig/mittel/hoch); kann ausführliche Argumentation für schnellere Code-Ausgabe überspringen. | Gibt immer vollständige Argumentationsspur in thinking-Tags vor dem Code aus, mit detaillierteren Erklärungen eingebettet. |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: Hochgenauer, latenzarmer Chatbot
Sie können das für Ihre Aufgabe passende Argumentationsniveau in drei Stufen anpassen:
- Niedrig: Schnelle Antworten für allgemeine Dialoge.
- Mittel: Ausgewogene Geschwindigkeit und Detailtiefe.
- Hoch: Tiefgehende und detaillierte Analyse.
Das Argumentationsniveau kann in den System-Prompts eingestellt werden, z.B. „Reasoning: high".
Wie greife ich kosteneffizient und schnell per API auf GPT OSS 120B und Qwen3 235B Thinking 2507 zu?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Model Library.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Settings" und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die notwendigen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
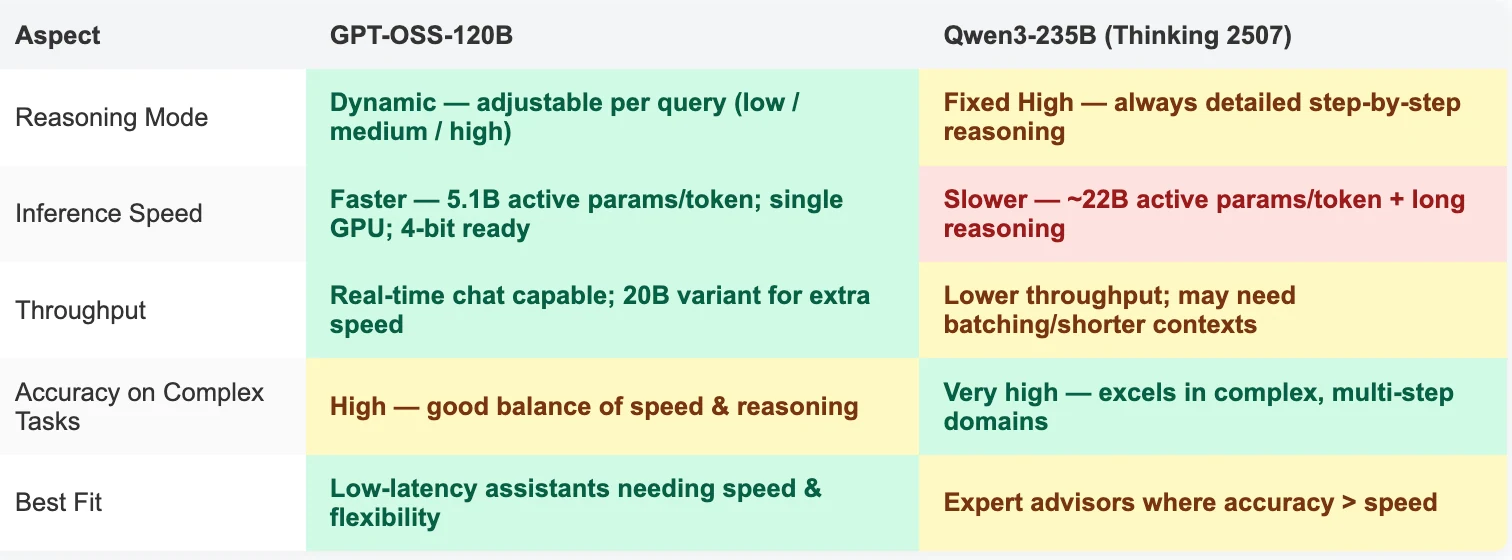
- GPT‑OSS‑120B ist die erste Wahl für Entwickler, die Flexibilität, Geschwindigkeit und einfachere Bereitstellung benötigen.
- Läuft auf einer einzelnen 80-GB-GPU (oder einer kleineren 20B-Variante für Edge-Geräte).
- Einstellbare Argumentationstiefe (
low/medium/high) für anfrageabhängige Abwägungen zwischen Geschwindigkeit und Genauigkeit. - Native Unterstützung für OpenAI-API-Funktionsaufrufe und Tool-Integration.
- Ideal für Produktionsassistenten, interaktive Apps und kostensensitive Bereitstellungen.
- Qwen‑3 235B (Thinking 2507) ist für maximale Argumentationsgenauigkeit bei jeder Anfrage ausgelegt.
- Arbeitet immer im High-Reasoning-Modus mit
thinking-Spuren. - Hervorragend geeignet für komplexes Coden, mathematische Beweise und Langkontext-Argumentation.
- Mehrsprachig und stark bei forschungsnahen Aufgaben, erfordert jedoch Multi-GPU-Setups und akzeptiert langsamere Antworten.
- Am besten geeignet für Expertenberater, bei denen Korrektheit Vorrang vor Geschwindigkeit hat.
- Arbeitet immer im High-Reasoning-Modus mit
Fazit:
Wenn Geschwindigkeit und Effizienz Ihre Priorität sind → wählen Sie GPT‑OSS‑120B.
Wenn Genauigkeit bei komplexen Argumentationen nicht verhandelbar ist → wählen Sie Qwen‑3 235B (Thinking 2507).
Häufig gestellte Fragen
Kann Qwen‑3 235B die Funktionsaufruf-API von OpenAI verwenden?
Nicht nativ. Es kann das Format per Prompt-Engineering nachahmen, aber Sie benötigen externes Parsing und Validierung für stabile Ergebnisse. GPT‑OSS‑120B unterstützt dies out-of-the-box.
Welches Modell benötigt weniger Hardware?
GPT‑OSS‑120B – es kann auf einer einzelnen 80-GB-GPU ausgeführt werden, dank MXFP4-Quantisierung. Qwen‑3 235B benötigt mindestens 4–8 GPUs für die volle Leistung.
Welches ist besser für Echtzeit-Chat?
GPT‑OSS‑120B – niedrigere Latenz, anpassbare Argumentation und kleinere aktive Parameter machen es reaktionsschneller.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



