

- GPT OSS 120B مقابل Qwen3 235B thinking 2507: البنية
- GPT OSS 120B مقابل Qwen3 235B thinking 2507: متطلبات الموارد
- GPT-OSS-120B مقابل Qwen-3 235B Thinking 2507: الاختلافات الرئيسية
- GPT OSS 120B مقابل Qwen 3 235B Thinking 2507: توليد الشيفرات البرمجية
- GPT OSS 120B مقابل Qwen 3 235B Thinking 2507: روبوت محادثة عالي الدقة ومنخفض زمن الاستجابة
- كيفية الوصول إلى GPT OSS 120B و Qwen3 235B Thinking 2507 بتكلفة فعالة وواجهة برمجة تطبيقات سريعة؟
اختيار نموذج اللغة الكبير (LLM) المناسب يتعلق بالموازنة بين عمق الاستدلال، السرعة، تكلفة الأجهزة، واحتياجات التكامل.
تقارن هذه المقالة GPT‑OSS‑120B و Qwen‑3 235B (Thinking 2507) — وهما من أقوى النماذج مفتوحة المصدر اليوم.
ستتعرف على كيفية اختلافهما في البنية، الأداء، متطلبات الموارد، قدرات البرمجة، وحالات الاستخدام الواقعية، لتقرر أيهما يناسب تطبيقك بشكل أفضل — بدءًا من روبوتات الدردشة منخفضة زمن الاستجابة إلى أنظمة البرمجة عالية الدقة.
GPT OSS 120B مقابل Qwen3 235B thinking 2507: البنية
تفاصيل البنية
| الميزة | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| إجمالي المعلمات | 117B | 235B |
| المعلمات المُنشَّطة / كل رمز | 5.1B | 22B |
| نسبة التنشيط | 4.36% | 9.36% |
| طبقات المحول | 36 | 94 |
| خبراء MoE | 128 | 128 |
| الخبراء المُنشَّطون / كل رمز | 4 | 8 |
| آلية الانتباه | انتباه كثيف متناوب + انتباه متفرق محلي النطاق، GQA | غير مذكورة صراحة (على الأرجح قياسية + تحسينات) |
| القياس الكمي | MXFP4 (4 بت) | غير مذكور |
| طول السياق الأصلي | 128K | 32K |
| طول السياق المُمدَّد | غير مذكور (الأصلي 128K أساسًا) | 262K+ (عبر YaRN، إلخ) |
معايير الأداء
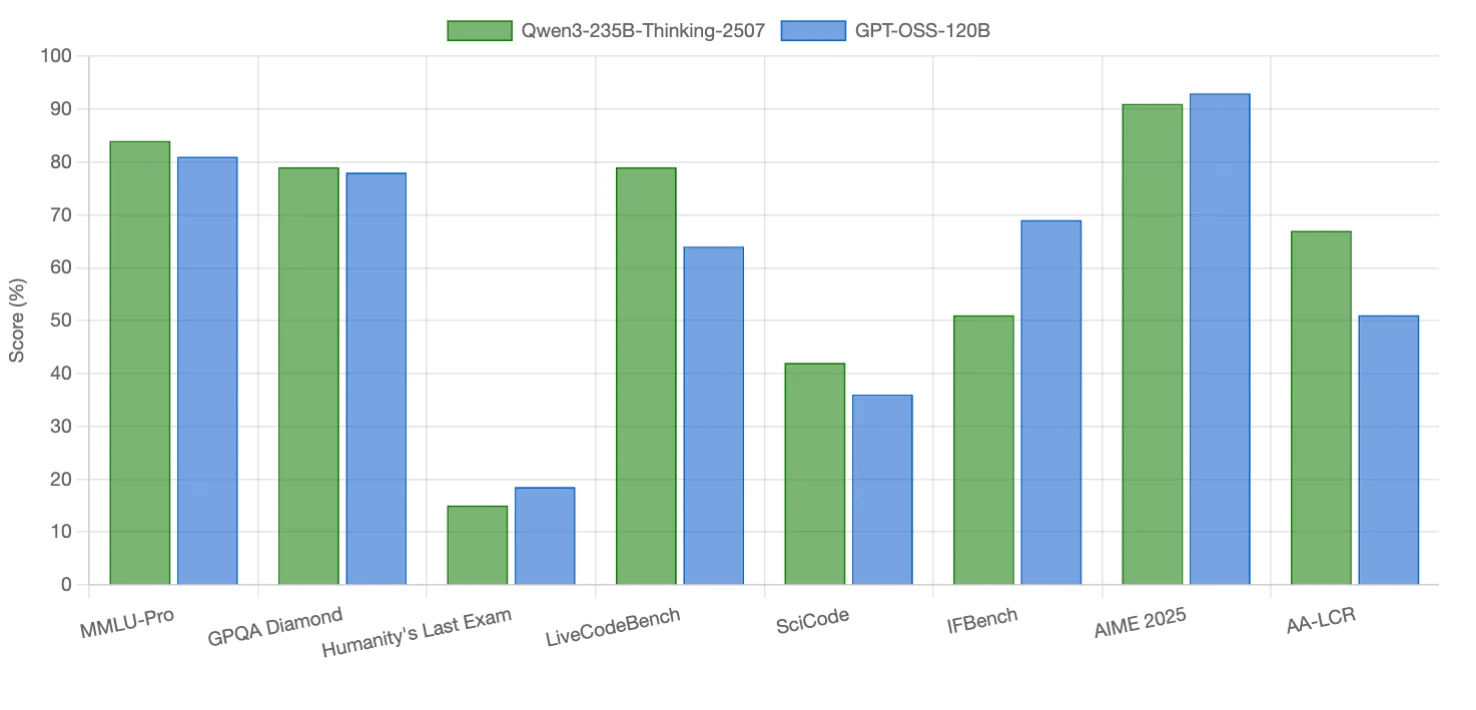
Qwen3-235B-Thinking-2507 يتفوق في مهام البرمجة والاستدلال طويل السياق، مع تفوق طفيف في بعض معايير الاستدلال. GPT-OSS-120B يتفوق في اتباع التعليمات، الرياضيات التنافسية، ومعيار واحد كثيف الاستدلال. كلا النموذجين تنافسيان في الاستدلال العلمي (متقاربان تقريبًا).
GPT OSS 120B مقابل Qwen3 235B thinking 2507: متطلبات الموارد
احتياجات وحدة معالجة الرسوميات (GPU)
| النموذج | القياس الكمي | ذاكرة VRAM المطلوبة | متطلبات وحدة معالجة الرسوميات* |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611.09 GB | 8 × 80 GB H100/A100 |
| FP8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT4 | 604.45 GB | 8 × 80 GB H100/A100 | |
| GPT-OSS-120B | FP16 | 246.34 GB | 4 × 80 GB H100/A100 |
| Q8 | 124.03 GB | 2 × 80 GB H100/A100 | |
| Q4 | 62.87 GB | 1 × 80 GB H100/A100 |
بفضل استخدامها لقياس MXFP4 الكمي، يمكن لـ GPT OSS 120B العمل على وحدة معالجة رسوميات واحدة بسعة 80 جيجابايت، بما في ذلك نماذج مثل NVIDIA H100 أو A100.
أما بالنسبة لتسعير وحدات معالجة الرسوميات، يمكنك النقر على الزر أدناه للحصول على مزيد من المعلومات.
الوصول عبر API
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة تطبيقات بسيطة، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
| النموذج | طول السياق | سعر الإدخال | سعر الإخراج |
| Qwen3-235B-Thinking-2507 | سياق 131072 | $0.3 / 1M | $3.0/ 1M |
| GPT-OSS-120B | سياق 131072 | $0.1 / 1M | $0.5 / 1M |
GPT-OSS-120B مقابل Qwen-3 235B Thinking 2507: الاختلافات الرئيسية
الاختلافات في القدرات
| الميزة | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| عمق استدلال قابل للتعديل | ✅ نعم (خيارات منخفض / متوسط / مرتفع) | ❌ لا (استدلال أقصى ثابت) |
| إخراج سلسلة الأفكار (CoT) دائمًا | ❌ لا (مخفي افتراضيًا) | ✅ نعم (وسوم thinking) |
| استدلال مخفي يمكن للمطور الوصول إليه | ✅ نعم | ❌ لا |
| التبديل بين وضع التفكير / الوضع السريع | ✅ نعم (الوضع السريع متاح) | ❌ لا (وضع التفكير فقط) |
| قدرة استخدام الأدوات | ✅ مدعومة | ✅ مدعومة |
| نتائج تقييم السلامة العامة | ✅ نعم (اختبار أمان خصومي) | ❌ ذكر محدود |
| ترخيص مفتوح المصدر Apache 2.0 | ✅ نعم | ✅ نعم |
الاختلافات في التطبيق
| إذا كنت بحاجة إلى… | اختر GPT-OSS-120B | اختر Qwen-3 235B (Thinking 2507) |
|---|---|---|
| العمل على أجهزة محدودة | ✅ إمكانية العمل على GPU واحد بسعة 80 جيجابايت (مثل 1× NVIDIA H100) بفضل ضغط MoE + MXFP4؛ يوجد أيضًا متغير 20B للأجهزة الطرفية ذات ذاكرة 16 جيجابايت | ❌ يتطلب خادمًا متعدد وحدات GPU (مثل 4×40 جيجابايت أو 8×80 جيجابايت GPU) للأداء الكامل |
| زمن استجابة أقل وتكلفة استدلال أقل | ✅ مُحسَّن للسرعة والكفاءة | ❌ زمن استجابة أعلى وتكلفة حسابية أعلى |
| أقصى عمق استدلال (دائم التشغيل) | ❌ عمق الاستدلال قابل للتعديل (منخفض/متوسط/مرتفع) | ✅ يعمل دائمًا بأقصى عمق استدلال مع تتبع thinking مرئي |
| الأفضل للاستدلال على مستوى البحث (براهين رياضية، برمجة معقدة، تعدد قفزات علمية) | ❌ عالي الجودة لكنه مضبوط لتحقيق التوازن | ✅ أداء رائد في النماذج المفتوحة في الرياضيات، مسابقات البرمجة، والمنطق المنظم |
| روبوت دردشة للأغراض العامة / مساعد إنتاجي بالذكاء الاصطناعي | ✅ قدرة قوية على اتباع التعليمات، استخدام الأدوات، نشر منخفض زمن الاستجابة | ❌ ممكن، لكنه أثقل وأبطأ |
| التكامل مع أدوات/API OpenAI الحالية | ✅ متوافق مع API مع أدوات OpenAI، تنسيق محادثة Harmony | ❌ يستخدم قالب محادثة وأدوات خاصة بـ Qwen (SGLang, Qwen-Agent) |
| التفاعل متعدد اللغات | ⚠️ مُحسَّن للغة الإنجليزية بشكل أساسي | ✅ قدرة متعددة اللغات قوية |
GPT OSS 120B مقابل Qwen 3 235B Thinking 2507: توليد الشيفرات البرمجية
| الجانب | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| استدعاء الدوال (مواصفات OpenAI API) | ✅ دعم أصلي — مُدرَّب لإخراج JSON function_call / tool_calls بدقة وفقًا لمخطط OpenAI؛ مستقر فور الاستخدام. |
❌ لا يوجد دعم أصلي — يمكن تقليده عبر هندسة المطالبات، لكنه يتطلب تحليل/تحقق خارجي للاستقرار. |
| تكامل الأدوات | ✅ متوافق مباشرة مع نظام OpenAI البيئي (مفسر Python، البحث على الويب، تنفيذ الشيفرات) عبر API. | ⚠️ يستخدم Qwen-Agent / SGLang لتكامل الأدوات؛ مخطط مختلف، يتطلب تكيفًا إذا كان الانتقال من تنسيق OpenAI. |
| طول إخراج الشيفرات وأسلوبها | موجز افتراضيًا؛ قد ينتج حلولًا جزئية عند إعطاء الأولوية للسرعة/الكفاءة (عمق استدلال قابل للتعديل). | أطول، دوال كاملة قابلة للترجمة افتراضيًا، مع معالجة أفضل للحالات الطرفية والتعليقات. |
| الاستدلال في توليد الشيفرات | عمق استدلال قابل للتعديل (منخفض/متوسط/مرتفع)؛ يمكن تخطي الاستدلال المطول لإخراج شيفرات أسرع. | دائمًا يُخرج تتبع استدلال كامل في وسوم thinking قبل الشيفرة، مع تفسيرات أكثر تفصيلًا مضمنة. |
GPT OSS 120B مقابل Qwen 3 235B Thinking 2507: روبوت محادثة عالي الدقة ومنخفض زمن الاستجابة
يمكنك ضبط مستوى الاستدلال الذي يناسب مهمتك عبر ثلاثة مستويات:
- منخفض: ردود سريعة للمحادثة العامة.
- متوسط: سرعة وتفاصيل متوازنة.
- مرتفع: تحليل عميق ومفصل.
يمكن تعيين مستوى الاستدلال في المطالبات النظامية، على سبيل المثال: “Reasoning: high”.
كيفية الوصول إلى GPT OSS 120B و Qwen3 235B Thinking 2507 بتكلفة فعالة وواجهة برمجة تطبيقات سريعة؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ نسختك التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المختار.

الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة على API، سنقدم لك مفتاح API جديد. ادخل إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام واجهة chat completions API لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
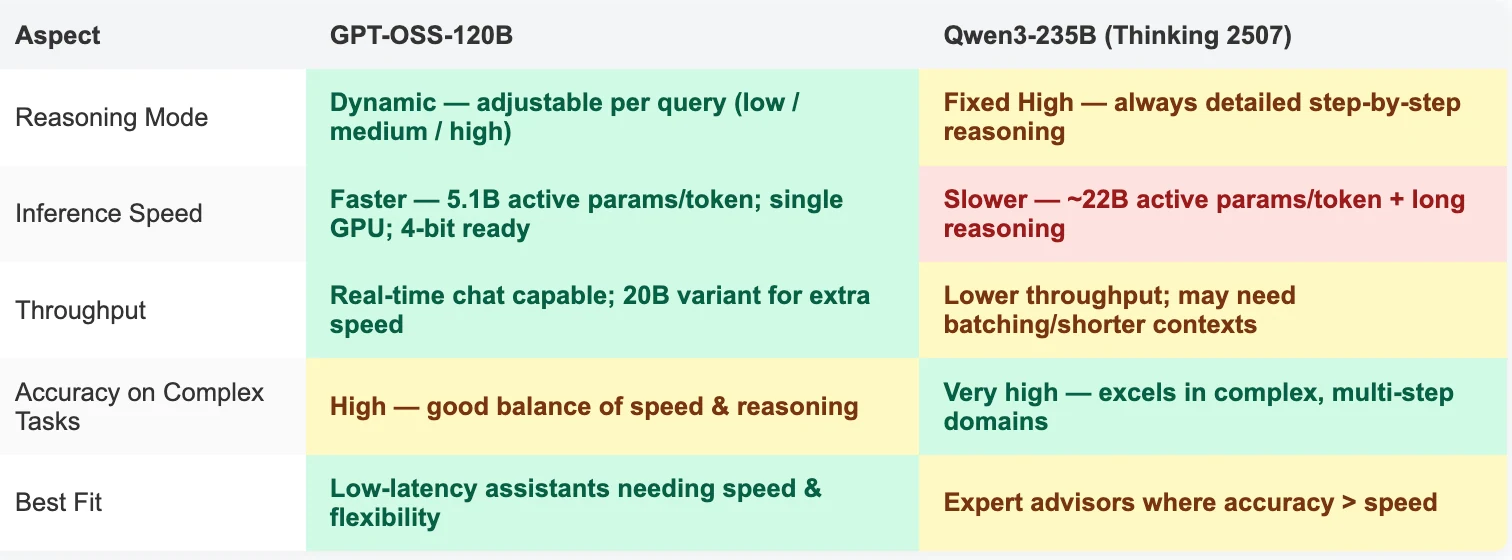
- GPT‑OSS‑120B هو الخيار الأمثل للمطورين الذين يحتاجون إلى المرونة والسرعة والنشر الأسهل.
- يعمل على وحدة GPU واحدة بسعة 80 جيجابايت (أو متغير 20B أصغر للأجهزة الطرفية).
- عمق استدلال قابل للتعديل (
منخفض/متوسط/مرتفع) للمقايضات لكل استعلام بين السرعة والدقة. - دعم أصلي لاستدعاء دوال OpenAI API وتكامل الأدوات.
- مثالي لمساعدي الإنتاج، التطبيقات التفاعلية، وعمليات النشر الحساسة للتكلفة.
- Qwen‑3 235B (Thinking 2507) مصمم لأقصى دقة استدلال في كل مرة.
- يعمل دائمًا في وضع الاستدلال العالي مع تتبعات
thinking. - يتفوق في البرمجة المعقدة، البراهين الرياضية، والاستدلال طويل السياق.
- متعدد اللغات وقوي في المهام على مستوى البحث، لكنه يتطلب إعدادات متعددة GPU ويقبل استجابات أبطأ.
- الأنسب للمستشارين الخبراء حيث تكون الدقة أهم من السرعة.
- يعمل دائمًا في وضع الاستدلال العالي مع تتبعات
الخلاصة:
إذا كانت السرعة والكفاءة هما أولويتك → اختر GPT‑OSS‑120B.
إذا كانت الدقة في الاستدلال المعقد غير قابلة للتفاوض → اختر Qwen‑3 235B (Thinking 2507).
الأسئلة الشائعة
هل يمكن لـ Qwen‑3 235B استخدام واجهة استدعاء دوال OpenAI؟
ليس بشكل أصلي. يمكن تقليد التنسيق عبر هندسة المطالبات، لكنك ستحتاج إلى تحليل خارجي وتحقق للحصول على نتائج مستقرة. GPT‑OSS‑120B يدعمها فور الاستخدام.
أي نموذج يحتاج إلى أجهزة أقل؟
GPT‑OSS‑120B — يمكنه العمل على وحدة GPU واحدة بسعة 80 جيجابايت بفضل القياس الكمي MXFP4. يتطلب Qwen‑3 235B على الأقل 4–8 وحدات GPU للأداء الكامل.
أيهما أفضل للدردشة في الوقت الحقيقي؟
GPT‑OSS‑120B — زمن استجابة أقل، استدلال قابل للتعديل، ومعلمات نشطة أصغر تجعله أكثر استجابة.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة تطبيقات بسيطة، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



