

- GPT OSS 120B vs Qwen3 235B thinking 2507: アーキテクチャ
- GPT OSS 120B vs Qwen3 235B thinking 2507: リソース要件
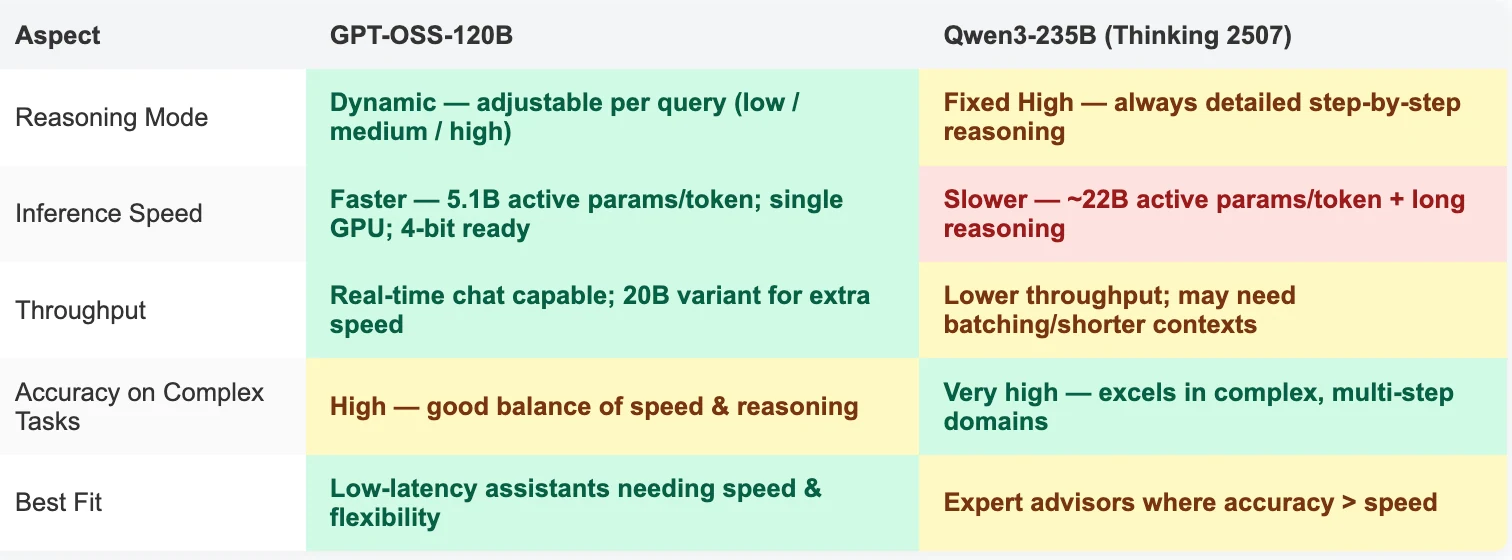
- GPT-OSS-120B vs Qwen-3 235B Thinking 2507: 主な違い
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: コード生成
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: 高精度・低レイテンシチャットボット
- GPT OSS 120B と Qwen3 235B Thinking 2507 にコスト効率よく高速APIでアクセスする方法
適切な大規模言語モデル(LLM)を選ぶには、推論の深さ 、 速度 、 ハードウェアコスト 、 統合の必要性のバランスが重要です。
この記事では、GPT‑OSS‑120B と Qwen‑3 235B (Thinking 2507) — 現在最も高性能なオープンソースモデルの2つ — を比較します。
アーキテクチャ、パフォーマンス、リソース要件、コーディング能力、実際のユースケースの違いを学べます。低レイテンシチャットボット ** から高精度コードシステム** まで、アプリケーションに最適なモデルを判断できるようになります。
GPT OSS 120B vs Qwen3 235B thinking 2507: アーキテクチャ
アーキテクチャ詳細
| 特徴 | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| 総パラメータ数 | 117B | 235B |
| 1トークンあたりの活性化パラメータ | 5.1B | 22B |
| 活性化比率 | 4.36% | 9.36% |
| Transformerレイヤー数 | 36 | 94 |
| MoEエキスパート数 | 128 | 128 |
| 1トークンあたりの活性化エキスパート数 | 4 | 8 |
| アテンション機構 | 高密度+局所バンド疎アテンションの交互、GQA | 明示されていない(おそらく標準+最適化) |
| 量子化 | MXFP4(4ビット) | 明示されていない |
| ネイティブコンテキスト長 | 128K | 32K |
| 拡張コンテキスト長 | 明示されていない(ネイティブで128K) | 262K以上(YaRNなどによる) |
パフォーマンスベンチマーク
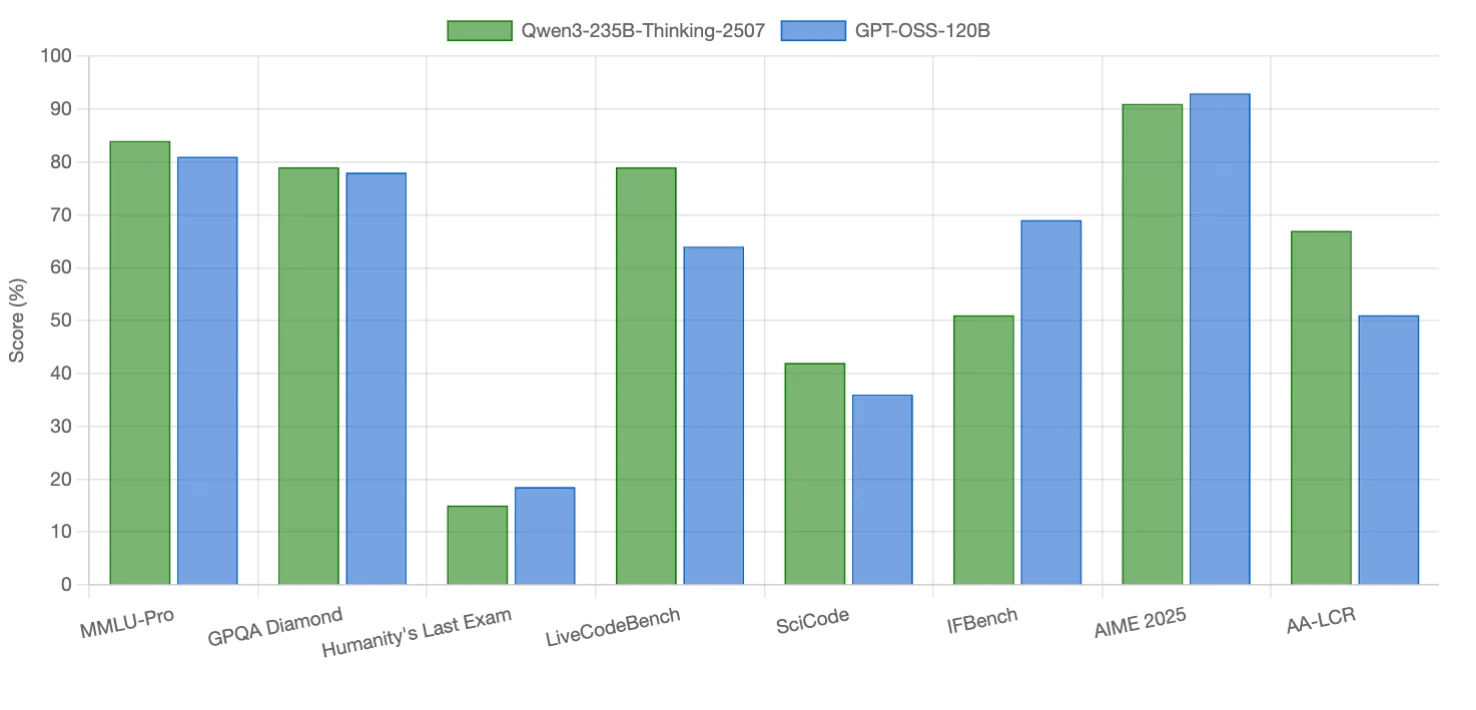
Qwen3-235B-Thinking-2507 は ** コーディングタスクと ** 長文脈推論に優れ、一部の推論ベンチマークでわずかに優位です。GPT-OSS-120B は ** 指示追従**、** 競技数学 、および1つの推論重視ベンチマークで優れています。両モデルは 科学的推論**でも互角です(ほぼ同点)。
GPT OSS 120B vs Qwen3 235B thinking 2507: リソース要件
GPU要件
| モデル | 量子化 | 必要VRAM | GPU要件* |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611.09 GB | 8 × 80 GB H100/A100 |
| FP8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT4 | 604.45 GB | 8 × 80 GB H100/A100 | |
| GPT-OSS-120B | FP16 | 246.34 GB | 4 × 80 GB H100/A100 |
| Q8 | 124.03 GB | 2 × 80 GB H100/A100 | |
| Q4 | 62.87 GB | 1 × 80 GB H100/A100 |
MXFP4量子化のおかげで、GPT OSS 120B は1枚の80 GB GPU(NVIDIA H100やA100など)で動作可能です。
GPUの価格については、以下のボタンをクリックして詳細をご確認ください。
APIアクセス
Novita AI は、開発者がシンプルなAPIを使ってAIモデルを簡単にデプロイでき、さらに手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。
| モデル | コンテキスト長 | 入力価格 | 出力価格 |
| Qwen3-235B-Thinking-2507 | 131072 Context | $0.3 / 1M | $3.0/ 1M |
| GPT-OSS-120B | 131072 Context | $0.1 / 1M | $0.5 / 1M |
GPT-OSS-120B vs Qwen-3 235B Thinking 2507: 主な違い
機能の違い
| 特徴 | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| 推論深度の調整 | ✅ 可能(低/中/高のオプション) | ❌ 不可(最大推論固定) |
| Chain-of-Thought (CoT) の常時出力 | ❌ 不可(デフォルトでは非表示) | ✅ 可能( thinking タグで表示) |
| 開発者が隠れた推論にアクセス | ✅ 可能 | ❌ 不可 |
| 思考モードと高速モードの切り替え | ✅ 可能(高速モードあり) | ❌ 不可(思考モードのみ) |
| ツール使用機能 | ✅ 対応 | ✅ 対応 |
| 公開安全性評価結果 | ✅ あり(敵対的安全性テスト) | ❌ 言及が限定的 |
| Apache 2.0 オープンソースライセンス | ✅ あり | ✅ あり |
アプリケーションにおける違い
| 必要なケース | GPT-OSS-120B を選択 | Qwen-3 235B (Thinking 2507) を選択 |
|---|---|---|
| 限られたハードウェアで実行 | ✅ MoE + MXFP4圧縮により1枚の80 GB GPU(例:1× NVIDIA H100)で可能。また、エッジデバイス向け16 GB VRAMの20B版もあり | ❌ フル性能を得るにはマルチGPUサーバー(例:4×40 GB または 8×80 GB GPU)が必要 |
| 低レイテンシと低推論コスト | ✅ 速度と効率に最適化 | ❌ レイテンシと計算コストが高い |
| 最大推論深度(常時オン) | ❌ 推論深度は調整可能(低/中/高) | ✅ 常に最大推論深度で動作し、表示可能な thinking トレースあり |
| 研究グレードの推論(数学の証明、複雑なコード、科学的多段階推論)に最適 | ❌ 高品質だがバランス重視 | ✅ 数学、コーディングコンテスト、構造化ロジックでトップクラスのオープンモデル性能 |
| 汎用チャットボット / プロダクションAIアシスタント | ✅ 強力な指示追従、ツール使用、低レイテンシデプロイ | ❌ 可能だが、より重く遅い |
| 既存のOpenAI API/ツールとの統合 | ✅ OpenAIツールと互換性のあるAPI、Harmonyチャット形式 | ❌ Qwen固有のチャットテンプレートとツールを使用(SGLang、Qwen-Agent) |
| 多言語対応 | ⚠️ 主に英語向けに最適化 | ✅ 強力な多言語対応 |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: コード生成
| 側面 | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| 関数呼び出し(OpenAI API仕様) | ✅ ネイティブ対応 — OpenAIスキーマに従って function_call / tool_calls JSONを正確に出力するよう学習済み。すぐに安定動作。 |
❌ ネイティブ非対応 — プロンプトエンジニアリングで模倣可能だが、安定性には外部パース/検証が必要。 |
| ツール統合 | ✅ APIを介してOpenAIエコシステム(Pythonインタプリタ、Web検索、コード実行)と直接互換性あり。 | ⚠️ ツール統合にはQwen-Agent / SGLangを使用。スキーマが異なり、OpenAI形式からの移行には適応が必要。 |
| コード出力の長さとスタイル | デフォルトで簡潔。速度/効率を優先すると部分的な解を生成することがある(推論深度調整可能)。 | デフォルトでより長く完全なコンパイル可能な関数、エッジケース処理やコメントが多い。 |
| コード生成における推論 | 推論深度は調整可能(低/中/高)。高速コード出力のため冗長な推論を省略可能。 | コードの前に常に完全な推論トレースを thinking タグで出力し、より詳細な説明が埋め込まれる。 |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: 高精度・低レイテンシチャットボット
タスクに合わせて3段階の推論レベルを調整できます。
- 低: 一般的な対話向けの高速応答。
- 中: 速度と詳細のバランス。
- 高: 深く詳細な分析。
推論レベルはシステムプロンプトで設定できます。例:
"Reasoning: high"。
GPT OSS 120B と Qwen3 235B Thinking 2507 にコスト効率よく高速APIでアクセスする方法
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3: 無料トライアルを開始
選択したモデルの機能を体験するために無料トライアルを開始します。

ステップ4: APIキーを取得
API認証のため、新しいAPIキーを提供します。“Settings” ページに移動し、画像のようにAPIキーをコピーします。

ステップ5: APIをインストール
使用するプログラミング言語のパッケージマネージャーを使ってAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使ってAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
- GPT‑OSS‑120B は、** 柔軟性、速度、容易なデプロイを必要とする開発者**に最適です。
- 1枚の80 GB GPU(またはエッジデバイス向けの小型20B版)で動作。
- 調整可能な推論深度(
low/medium/high)により、クエリごとに速度と精度をトレードオフ。 - OpenAI APIの関数呼び出しとツール統合をネイティブサポート。
- プロダクションアシスタント 、 インタラクティブアプリ 、 コスト重視のデプロイに最適。
- Qwen‑3 235B (Thinking 2507) は、** 毎回最大の推論精度**を求めるために設計されています。
- 常に高推論モードで動作し、
thinkingトレースを出力。 - 複雑なコーディング 、 数学の証明 、 長文脈推論に優れる。
- 多言語対応で研究グレードのタスクに強いが、マルチGPU環境 が必要で、応答が遅くなる。
- 正確さが速度より優先される エキスパートアドバイザー に最適。
- 常に高推論モードで動作し、
まとめ:
**速度と効率 ** が優先なら → GPT‑OSS‑120B を選択。
**複雑な推論の正確さ ** が譲れないなら → Qwen‑3 235B (Thinking 2507) を選択。
よくある質問
Qwen‑3 235B は OpenAI の関数呼び出し API を使用できますか?
ネイティブではサポートしていません。プロンプトエンジニアリングで形式を模倣することは可能ですが、安定した結果を得るには外部パースと検証が必要です。GPT‑OSS‑120B はすぐに使えます。
どちらのモデルが少ないハードウェアで済みますか?
GPT‑OSS‑120B です。MXFP4量子化により1枚の80 GB GPUで動作可能です。Qwen‑3 235B はフル性能を得るために最低4〜8枚のGPUが必要です。
リアルタイムチャットにはどちらが適していますか?
GPT‑OSS‑120B です。レイテンシが低く、推論深度が調整可能で、活性化パラメータが小さいため応答性が高いです。
Novita AI は、開発者がシンプルなAPIを使ってAIモデルを簡単にデプロイでき、さらに手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。



