

- GPT OSS 120B vs Qwen3 235B Thinking 2507: Arquitectura
- GPT OSS 120B vs Qwen3 235B Thinking 2507: Requisitos de Recursos
- GPT-OSS-120B vs Qwen-3 235B Thinking 2507: Diferencias Clave
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: Generación de Código
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: Chatbot de Alta Precisión y Baja Latencia
- ¿Cómo Acceder a GPT OSS 120B y Qwen3 235B Thinking 2507 de Forma Rentable y Rápida mediante API?
Elegir el modelo de lenguaje grande (LLM) adecuado implica equilibrar la profundidad de razonamiento, la velocidad, el costo de hardware y las necesidades de integración.
Este artículo compara GPT‑OSS‑120B y Qwen‑3 235B (Thinking 2507) — dos de los modelos de código abierto más capaces hoy en día.
Aprenderás en qué se diferencian en arquitectura, rendimiento, requisitos de recursos, habilidades de codificación y casos de uso reales, para que puedas decidir cuál se adapta mejor a tu aplicación — desde chatbots de baja latencia hasta sistemas de código de alta precisión.
GPT OSS 120B vs Qwen3 235B Thinking 2507: Arquitectura
Detalles de la arquitectura
| Característica | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| Parámetros totales | 117B | 235B |
| Parámetros activados / Token | 5.1B | 22B |
| Relación de activación | 4.36% | 9.36% |
| Capas del Transformer | 36 | 94 |
| Expertos MoE | 128 | 128 |
| Expertos activados / Token | 4 | 8 |
| Mecanismo de atención | Atención densa alternante + atención dispersa localmente en bandas, GQA | No se indica explícitamente (probablemente estándar + optimizaciones) |
| Cuantización | MXFP4 (4 bits) | No indicado |
| Longitud de contexto nativa | 128K | 32K |
| Longitud de contexto extendida | No indicada (nativa ya 128K) | 262K+ (mediante YaRN, etc.) |
Evaluación de rendimiento
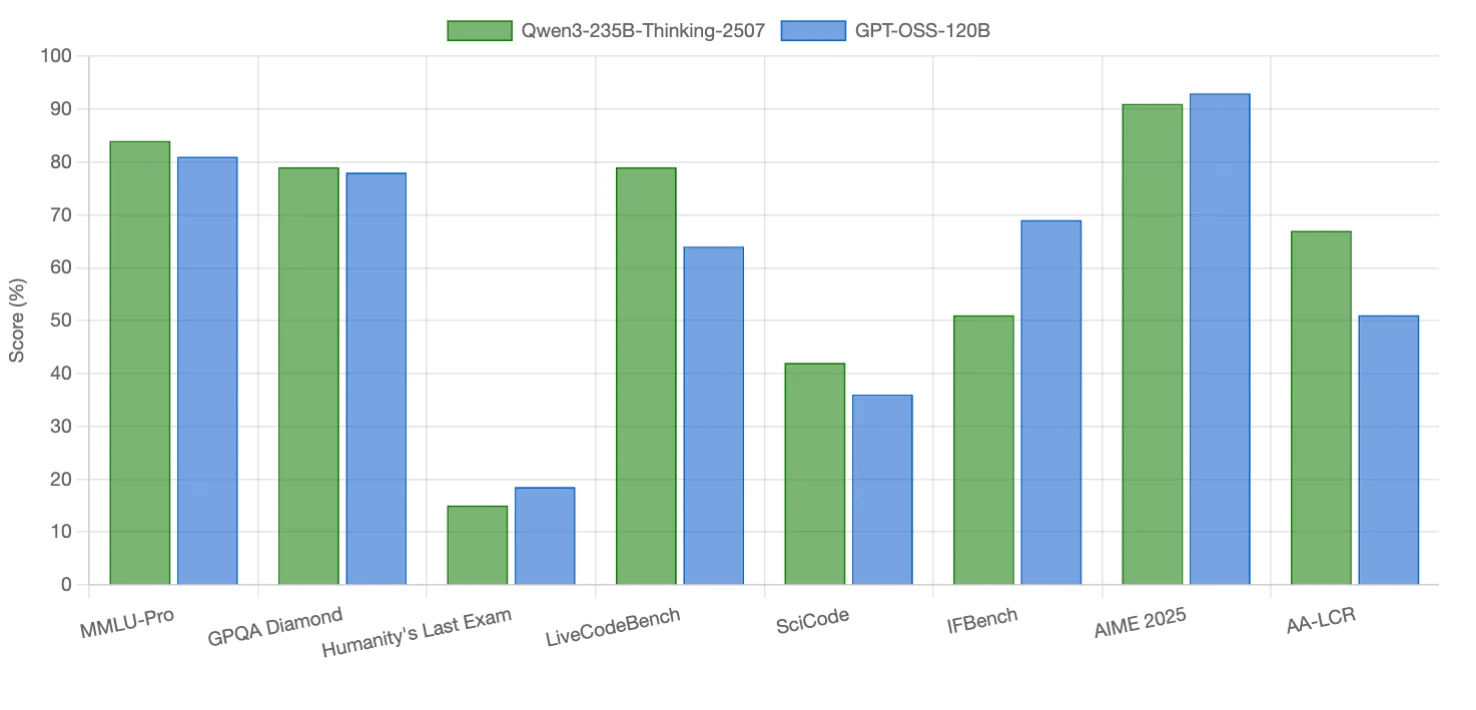
Qwen3-235B-Thinking-2507 sobresale en tareas de codificación y razonamiento de contexto largo, con pequeñas ventajas en algunos benchmarks de razonamiento. GPT-OSS-120B supera en seguimiento de instrucciones, matemáticas de competencia y un benchmark de razonamiento intensivo. Ambos modelos son competitivos en razonamiento científico (casi empatados).
GPT OSS 120B vs Qwen3 235B Thinking 2507: Requisitos de Recursos
Necesidades de GPU
| Modelo | Cuantización | VRAM Requerida | Requisito de GPU* |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611.09 GB | 8 × 80 GB H100/A100 |
| FP8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT8 | 606.67 GB | 8 × 80 GB H100/A100 | |
| INT4 | 604.45 GB | 8 × 80 GB H100/A100 | |
| GPT-OSS-120B | FP16 | 246.34 GB | 4 × 80 GB H100/A100 |
| Q8 | 124.03 GB | 2 × 80 GB H100/A100 | |
| Q4 | 62.87 GB | 1 × 80 GB H100/A100 |
Gracias al uso de la cuantización MXFP4, GPT OSS 120B puede ejecutarse en una sola GPU de 80 GB, incluidos modelos como NVIDIA H100 o A100.
En cuanto al precio de las GPU, puedes hacer clic en el botón de abajo para obtener más información.
Acceso mediante API
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA mediante nuestra API simple, a la vez que proporciona una nube de GPU asequible y confiable para construir y escalar.
| Modelo | Longitud de contexto | Precio de entrada | Precio de salida |
| Qwen3-235B-Thinking-2507 | 131072 Context | $0.3 / 1M | $3.0/ 1M |
| GPT-OSS-120B | 131072 Context | $0.1 / 1M | $0.5 / 1M |
GPT-OSS-120B vs Qwen-3 235B Thinking 2507: Diferencias Clave
Diferencias en Capacidades
| Característica | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Profundidad de razonamiento ajustable | ✅ Sí (Opciones Baja / Media / Alta) | ❌ No (Razonamiento máximo fijo) |
| Siempre genera Cadena de Pensamiento (CoT) | ❌ No (Oculto por defecto) | ✅ Sí (etiquetas thinking) |
| Razonamiento oculto accesible para desarrolladores | ✅ Sí | ❌ No |
| Cambio entre modo pensamiento/rápido | ✅ Sí (Modo rápido disponible) | ❌ No (Solo modo pensamiento) |
| Capacidad de uso de herramientas | ✅ Compatible | ✅ Compatible |
| Resultados de evaluación de seguridad pública | ✅ Sí (Pruebas de seguridad adversaria) | ❌ Mención limitada |
| Licencia de código abierto Apache 2.0 | ✅ Sí | ✅ Sí |
Diferencias en Aplicación
| Si necesitas… | Elige GPT-OSS-120B | Elige Qwen-3 235B (Thinking 2507) |
|---|---|---|
| Ejecutar en hardware limitado | ✅ Una sola GPU de 80 GB posible (p. ej., 1× NVIDIA H100) gracias a la compresión MoE + MXFP4; también tiene una variante de 20B para dispositivos periféricos con 16 GB de VRAM | ❌ Requiere servidor multi-GPU (p. ej., 4×40 GB o 8×80 GB) para rendimiento completo |
| Menor latencia y costo de inferencia | ✅ Optimizado para velocidad y eficiencia | ❌ Mayor latencia y costo computacional |
| Máxima profundidad de razonamiento (siempre activa) | ❌ Profundidad de razonamiento ajustable (baja/media/alta) | ✅ Siempre se ejecuta con máxima profundidad de razonamiento y traza thinking visible |
| Ideal para razonamiento de nivel investigativo (pruebas matemáticas, código complejo, múltiples saltos científicos) | ❌ Alta calidad pero ajustado para equilibrio | ✅ Rendimiento de primer nivel en modelos abiertos en matemáticas, competiciones de codificación y lógica estructurada |
| Chatbot de propósito general / asistente de IA en producción | ✅ Sólido seguimiento de instrucciones, uso de herramientas, implementación de baja latencia | ❌ Posible, pero más pesado y lento |
| Integración con API/herramientas OpenAI existentes | ✅ API compatible con herramientas OpenAI, formato de chat Harmony | ❌ Usa plantilla y herramientas de chat específicas de Qwen (SGLang, Qwen-Agent) |
| Interacción multilingüe | ⚠️ Optimizado principalmente para inglés | ✅ Fuerte capacidad multilingüe |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: Generación de Código
| Aspecto | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Llamada a función (especificación API de OpenAI) | ✅ Soporte nativo — entrenado para generar JSON de function_call / tool_calls exactamente según el esquema de OpenAI; estable de inmediato. |
❌ Sin soporte nativo — puede imitarse mediante ingeniería de prompts, pero requiere análisis/validación externos para ser estable. |
| Integración de herramientas | ✅ Directamente compatible con el ecosistema de OpenAI (intérprete de Python, búsqueda web, ejecución de código) mediante API. | ⚠️ Usa Qwen-Agent / SGLang para integración de herramientas; esquema diferente, requiere adaptación si se migra desde el formato de OpenAI. |
| Longitud y estilo de la salida de código | Conciso por defecto; puede producir soluciones parciales al priorizar velocidad/eficiencia (profundidad de razonamiento ajustable). | Funciones más largas, más completas y compilables por defecto, con más manejo de casos extremos y comentarios. |
| Razonamiento en la generación de código | Profundidad de razonamiento ajustable (baja/media/alta); puede omitir el razonamiento verboso para una salida de código más rápida. | Siempre genera un rastro completo de razonamiento en etiquetas thinking antes del código, con explicaciones más detalladas incrustadas. |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: Chatbot de Alta Precisión y Baja Latencia
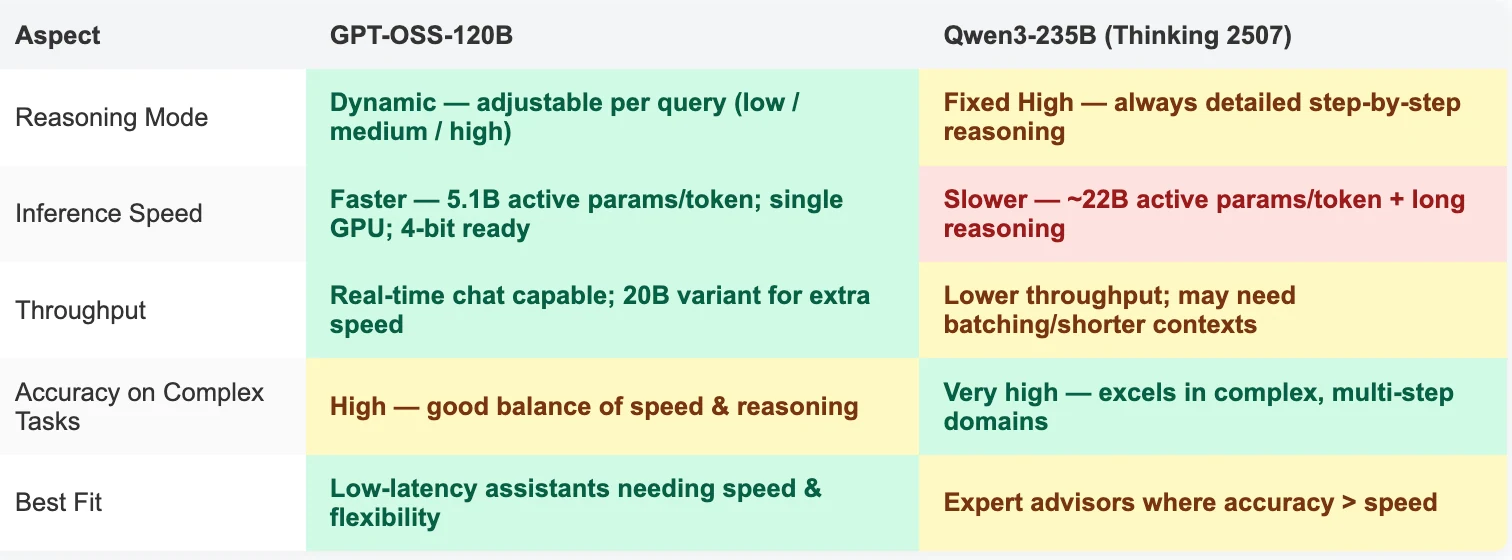
Puedes ajustar el nivel de razonamiento que se adapte a tu tarea entre tres niveles:
- Baja: Respuestas rápidas para diálogos generales.
- Media: Velocidad y detalle equilibrados.
- Alta: Análisis profundo y detallado.
El nivel de razonamiento se puede configurar en los prompts del sistema, por ejemplo, “Reasoning: high”.
¿Cómo Acceder a GPT OSS 120B y Qwen3 235B Thinking 2507 de Forma Rentable y Rápida mediante API?
Paso 1: Iniciar sesión y acceder a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completado de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
- GPT‑OSS‑120B es la opción ideal para desarrolladores que necesitan flexibilidad, velocidad y una implementación más fácil.
- Se ejecuta en una sola GPU de 80 GB (o la variante más pequeña de 20B para dispositivos periféricos).
- Profundidad de razonamiento ajustable (
low/medium/high) para compensaciones por consulta entre velocidad y precisión. - Soporte nativo para llamadas a funciones de la API de OpenAI e integración de herramientas.
- Ideal para asistentes en producción, aplicaciones interactivas e implementaciones sensibles al costo.
- Qwen‑3 235B (Thinking 2507) está diseñado para la máxima precisión de razonamiento en todo momento.
- Siempre opera en modo de alto razonamiento con trazas de
thinking. - Sobresale en codificación compleja, pruebas matemáticas y razonamiento de contexto largo.
- Multilingüe y fuerte en tareas de nivel investigativo, pero requiere configuraciones multi-GPU y acepta respuestas más lentas.
- Ideal para asesores expertos donde la precisión supera a la velocidad.
- Siempre opera en modo de alto razonamiento con trazas de
Resumen:
Si la velocidad y la eficiencia son tu prioridad → elige GPT‑OSS‑120B.
Si la precisión para razonamiento complejo es innegociable → elige Qwen‑3 235B (Thinking 2507).
Preguntas Frecuentes
¿Puede Qwen‑3 235B usar la API de llamada a funciones de OpenAI?
No de forma nativa. Puede imitar el formato mediante ingeniería de prompts, pero necesitarás análisis y validación externos para obtener resultados estables. GPT‑OSS‑120B lo admite de inmediato.
¿Qué modelo necesita menos hardware?
GPT‑OSS‑120B — puede ejecutarse en una sola GPU de 80 GB gracias a la cuantización MXFP4. Qwen‑3 235B requiere al menos 4–8 GPU para rendimiento completo.
¿Cuál es mejor para chat en tiempo real?
GPT‑OSS‑120B — menor latencia, razonamiento ajustable y parámetros activos más pequeños lo hacen más receptivo.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA mediante nuestra API simple, a la vez que proporciona una nube de GPU asequible y confiable para construir y escalar.



