

- GPT OSS 120B vs Qwen3 235B thinking 2507: Arquitetura
- GPT OSS 120B vs Qwen3 235B thinking 2507: Requisitos de Recursos
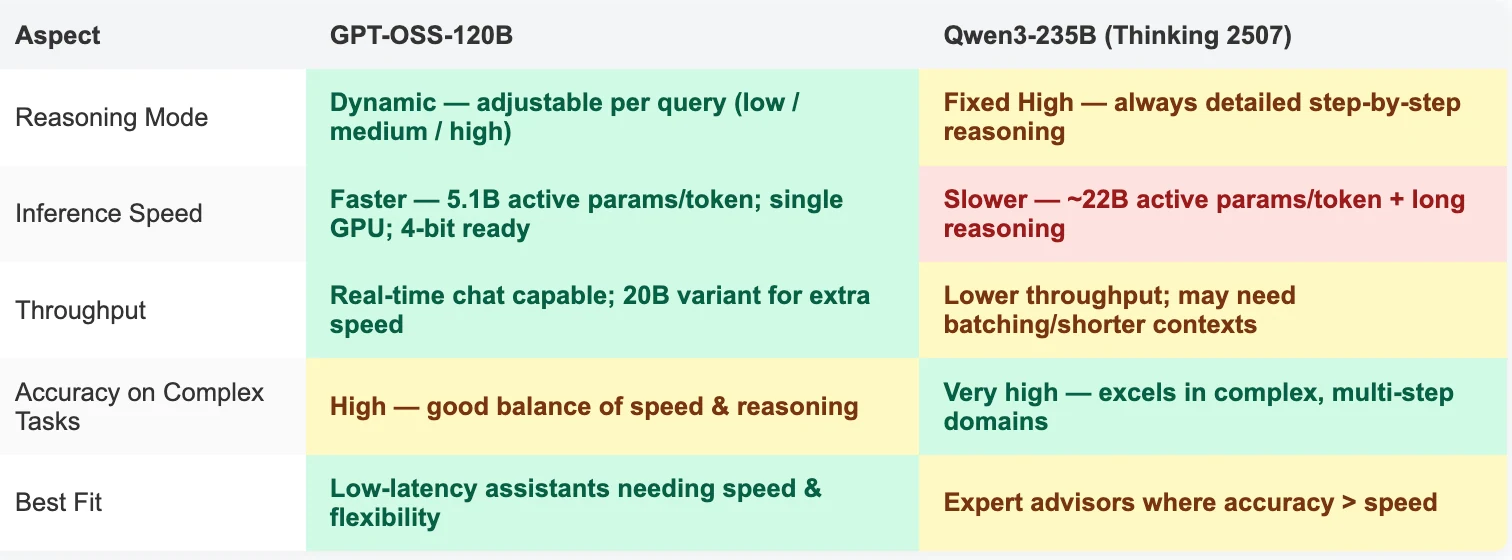
- GPT-OSS-120B vs Qwen-3 235B Thinking 2507: Principais Diferenças
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: Geração de Código
- GPT OSS 120B vs Qwen 3 235B Thinking 2507: Chatbot de Alta Precisão e Baixa Latência
- Como Acessar GPT OSS 120B e Qwen3 235B Thinking 2507 de Forme Econômica e com API Rápida?
Escolher o modelo de linguagem grande (LLM) certo envolve equilibrar profundidade de raciocínio, velocidade, custo de hardware e necessidades de integração.
Este artigo compara GPT‑OSS‑120B e Qwen‑3 235B (Thinking 2507) — dois dos modelos open‑source mais capazes atualmente.
Você aprenderá como eles diferem em arquitetura, desempenho, requisitos de recursos, habilidades de codificação e casos de uso reais, para decidir qual se adapta melhor à sua aplicação — desde chatbots de baixa latência até sistemas de código de alta precisão.
GPT OSS 120B vs Qwen3 235B thinking 2507: Arquitetura
Detalhes da Arquitetura
| Característica | GPT-OSS-120B | Qwen3-235B-Thinking-2507 |
|---|---|---|
| Parâmetros Totais | 117B | 235B |
| Parâmetros Ativados / Token | 5.1B | 22B |
| Taxa de Ativação | 4,36% | 9,36% |
| Camadas Transformer | 36 | 94 |
| Especialistas MoE | 128 | 128 |
| Especialistas Ativados / Token | 4 | 8 |
| Mecanismo de Atenção | Atenção alternada densa + localmente em banda esparsa, GQA | Não declarado explicitamente (provavelmente padrão + otimizações) |
| Quantização | MXFP4 (4 bits) | Não declarado |
| Comprimento de Contexto Nativo | 128K | 32K |
| Comprimento de Contexto Estendido | Não declarado (nativo já 128K) | 262K+ (via YaRN, etc.) |
Benchmark de Desempenho
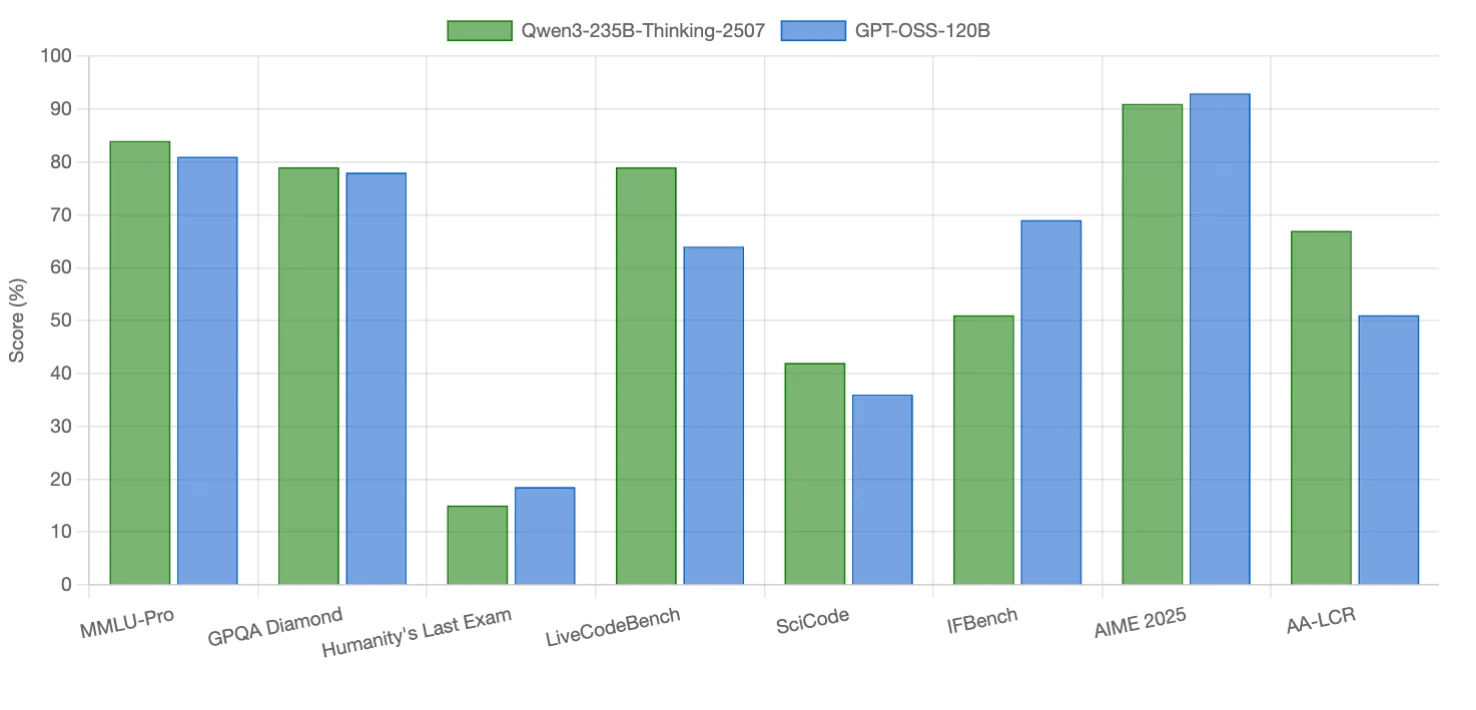
Qwen3-235B-Thinking-2507 se destaca em tarefas de codificação e raciocínio de contexto longo, com pequenas vantagens em alguns benchmarks de raciocínio. GPT-OSS-120B supera em seguimento de instruções, matemática competitiva e um benchmark pesado em raciocínio. Ambos os modelos são competitivos em raciocínio científico (quase empatados).
GPT OSS 120B vs Qwen3 235B thinking 2507: Requisitos de Recursos
Necessidades de GPU
| Modelo | Quantização | VRAM Necessária | Requisito de GPU* |
|---|---|---|---|
| Qwen3-235B-Thinking-2507 | FP16 | 611,09 GB | 8 × 80 GB H100/A100 |
| FP8 | 606,67 GB | 8 × 80 GB H100/A100 | |
| INT8 | 606,67 GB | 8 × 80 GB H100/A100 | |
| INT4 | 604,45 GB | 8 × 80 GB H100/A100 | |
| GPT-OSS-120B | FP16 | 246,34 GB | 4 × 80 GB H100/A100 |
| Q8 | 124,03 GB | 2 × 80 GB H100/A100 | |
| Q4 | 62,87 GB | 1 × 80 GB H100/A100 |
Devido ao uso de quantização MXFP4, o GPT OSS 120B é capaz de rodar em uma única GPU de 80 GB, incluindo modelos como NVIDIA H100 ou A100.
Quanto ao preço da GPU, clique no botão abaixo para obter mais informações.
Acesso via API
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
| Modelo | Comprimento de Contexto | Preço de Entrada | Preço de Saída |
| Qwen3-235B-Thinking-2507 | 131072 Contexto | $0,3 / 1M | $3,0/ 1M |
| GPT-OSS-120B | 131072 Contexto | $0,1 / 1M | $0,5 / 1M |
GPT-OSS-120B vs Qwen-3 235B Thinking 2507: Principais Diferenças
Diferenças nas Capacidades
| Característica | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Profundidade de raciocínio ajustável | ✅ Sim (opções Baixo / Médio / Alto) | ❌ Não (raciocínio máximo fixo) |
| Sempre gera Chain-of-Thought (CoT) | ❌ Não (oculto por padrão) | ✅ Sim (tags thinking) |
| Raciocínio oculto acessível ao desenvolvedor | ✅ Sim | ❌ Não |
| Alternar entre modo pensamento / rápido | ✅ Sim (modo rápido disponível) | ❌ Não (apenas modo pensamento) |
| Capacidade de uso de ferramentas | ✅ Suportado | ✅ Suportado |
| Resultados públicos de avaliação de segurança | ✅ Sim (testes de segurança adversarial) | ❌ Menção limitada |
| Licença open-source Apache 2.0 | ✅ Sim | ✅ Sim |
Diferenças na Aplicação
| Se você precisa de… | Escolha GPT-OSS-120B | Escolha Qwen-3 235B (Thinking 2507) |
|---|---|---|
| Rodar em hardware limitado | ✅ GPU única de 80 GB possível (ex.: 1× NVIDIA H100) graças à compressão MoE + MXFP4; também variante 20B para dispositivos de borda com 16 GB VRAM | ❌ Requer servidor multi-GPU (ex.: 4×40 GB ou 8×80 GB GPUs) para desempenho total |
| Menor latência e custo de inferência | ✅ Otimizado para velocidade e eficiência | ❌ Maior latência e custo computacional |
| Máxima profundidade de raciocínio (sempre ativo) | ❌ Profundidade de raciocínio ajustável (baixo/médio/alto) | ✅ Sempre opera na profundidade máxima de raciocínio com rastro visível thinking |
| Melhor para raciocínio de nível pesquisa (provas matemáticas, código complexo, multi-salto científico) | ❌ Alta qualidade, mas ajustado para equilíbrio | ✅ Desempenho topo de linha em modelos abertos em matemática, competições de codificação e lógica estruturada |
| Chatbot de uso geral / assistente de IA de produção | ✅ Forte seguimento de instruções, uso de ferramentas, implantação de baixa latência | ❌ Possível, mas mais pesado e lento |
| Integração com API/ferramentas OpenAI existentes | ✅ API compatível com ferramentas OpenAI, formato de chat Harmony | ❌ Usa template de chat e ferramentas específicas do Qwen (SGLang, Qwen-Agent) |
| Interação multilíngue | ⚠️ Principalmente otimizado para inglês | ✅ Capacidade multilíngue forte |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: Geração de Código
| Aspecto | GPT-OSS-120B | Qwen3-235B (Thinking 2507) |
|---|---|---|
| Chamada de Função (especificação OpenAI API) | ✅ Suporte nativo — treinado para gerar JSON function_call / tool_calls exatamente conforme esquema OpenAI; estável pronto para uso. |
❌ Sem suporte nativo — pode imitar via engenharia de prompt, mas requer parsing/validação externa para estabilidade. |
| Integração de Ferramentas | ✅ Diretamente compatível com o ecossistema OpenAI (interpretador Python, busca web, execução de código) via API. | ⚠️ Usa Qwen-Agent / SGLang para integração de ferramentas; esquema diferente, requer adaptação se migrando do formato OpenAI. |
| Comprimento e Estilo da Saída de Código | Conciso por padrão; pode produzir soluções parciais ao priorizar velocidade/eficiência (profundidade de raciocínio ajustável). | Mais longo, funções mais completas e compiláveis por padrão, com mais tratamento de casos extremos e comentários. |
| Raciocínio na Geração de Código | Profundidade de raciocínio ajustável (baixo/médio/alto); pode pular raciocínio detalhado para saída de código mais rápida. | Sempre gera rastro completo de raciocínio em tags thinking antes do código, com explicações mais detalhadas incorporadas. |
GPT OSS 120B vs Qwen 3 235B Thinking 2507: Chatbot de Alta Precisão e Baixa Latência
Você pode ajustar o nível de raciocínio adequado à sua tarefa em três níveis:
- Baixo: Respostas rápidas para diálogo geral.
- Médio: Velocidade e detalhes equilibrados.
- Alto: Análise profunda e detalhada.
O nível de raciocínio pode ser definido nos prompts de sistema, por exemplo, “Reasoning: high”.
Como Acessar GPT OSS 120B e Qwen3 235B Thinking 2507 de Forme Econômica e com API Rápida?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login em sua conta e clique no botão Model Library.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.

Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acesse a página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
- GPT‑OSS‑120B é a escolha certa para desenvolvedores que precisam de flexibilidade, velocidade e implantação mais fácil.
- Roda em uma única GPU de 80 GB (ou variante 20B menor para dispositivos de borda).
- Profundidade de raciocínio ajustável (
low/medium/high) para compensações por consulta entre velocidade e precisão. - Suporte nativo para chamada de função OpenAI API e integração de ferramentas.
- Ideal para assistentes de produção, aplicativos interativos e implantações sensíveis a custo.
- Qwen‑3 235B (Thinking 2507) é construído para máxima precisão de raciocínio em todas as execuções.
- Sempre opera em modo de raciocínio alto com rastros
thinking. - Excelente em codificação complexa, provas matemáticas e raciocínio de contexto longo.
- Multilíngue e forte em tarefas de nível pesquisa, mas requer configurações multi-GPU e aceita respostas mais lentas.
- Melhor para assistentes especialistas onde a correção supera a velocidade.
- Sempre opera em modo de raciocínio alto com rastros
Resumo:
Se velocidade e eficiência são sua prioridade → escolha GPT‑OSS‑120B.
Se precisão para raciocínio complexo é inegociável → escolha Qwen‑3 235B (Thinking 2507).
Perguntas Frequentes
O Qwen‑3 235B pode usar a API de chamada de função do OpenAI?
Não nativamente. Pode imitar o formato via engenharia de prompt, mas você precisará de parsing e validação externos para resultados estáveis. O GPT‑OSS‑120B suporta isso imediatamente.
Qual modelo precisa de menos hardware?
GPT‑OSS‑120B — pode rodar em uma única GPU de 80 GB graças à quantização MXFP4. Qwen‑3 235B requer pelo menos 4–8 GPUs para desempenho total.
Qual é melhor para chat em tempo real?
GPT‑OSS‑120B — menor latência, raciocínio ajustável e parâmetros ativos menores o tornam mais responsivo.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



