

关键亮点
GLM-4.5:一种基础模型,统一了推理、编码和智能体能力,满足智能体应用的复杂需求。
ChatGPT-4.1:具备高级推理能力的多模态基础模型,针对跨领域和应用的多样化解题及类人对话进行优化。
Novita AI 不仅提供稳定的 API 服务,还提供极具性价比的定价。例如,GLM-4.5 每 100 万输入 token 仅需 0.6 美元,每 100 万输出 token 仅需 2.2 美元。
模型基础介绍
GLM-4.5
GLM-4.5 是一款面向智能体的基础模型,拥有 3550 亿总参数和 320 亿活跃参数。该模型统一了推理、编码和智能体能力,满足智能体应用的复杂需求。GLM-4.5 是一种混合推理模型,提供两种模式:用于复杂推理和工具使用的思考模式,以及用于即时响应的非思考模式。
主要特性与架构
- 参数:总参数 3550 亿,活跃参数 320 亿。
- 混合推理:两种运行模式 —— 思考模式用于复杂推理和工具使用,非思考模式用于即时响应。
- 模型版本:提供基础模型、混合推理模型和 FP8 版本。
- 上下文窗口:128K token。
- 许可协议:MIT 开源许可证,允许商业使用和二次开发。
- 能力:统一推理、编码和智能体功能,适用于复杂应用。
ChatGPT-4.1
ChatGPT-4.1 由 OpenAI 于 2025 年 4 月 14 日发布,在上下文理解方面取得突破性改进,拥有原生 100 万 token 的上下文窗口,编码能力较 GPT-4o 提升 21%,并具备卓越的多模态处理能力,支持文本、图像和文档分析。ChatGPT-4.1 基于优化的 transformer 架构和增强的注意力机制,在 AIME、GPQA、MMLU 学术基准、SWE-bench 编码评估以及 MMMU/MathVista 视觉任务上均达到了领先水平。
主要特性与架构
- 类型:具有多模态能力的高级大语言模型
- 发布日期:2025 年 4 月 14 日
- 上下文窗口:原生 100 万 token
- 编码性能:软件工程能力较 GPT-4o 提升 21%
- 多模态支持:增强的文本、图像和文档分析能力
- 指令遵循:对用户格式和任务要求的高级遵循能力
基准测试对比
1. 智能基准测试
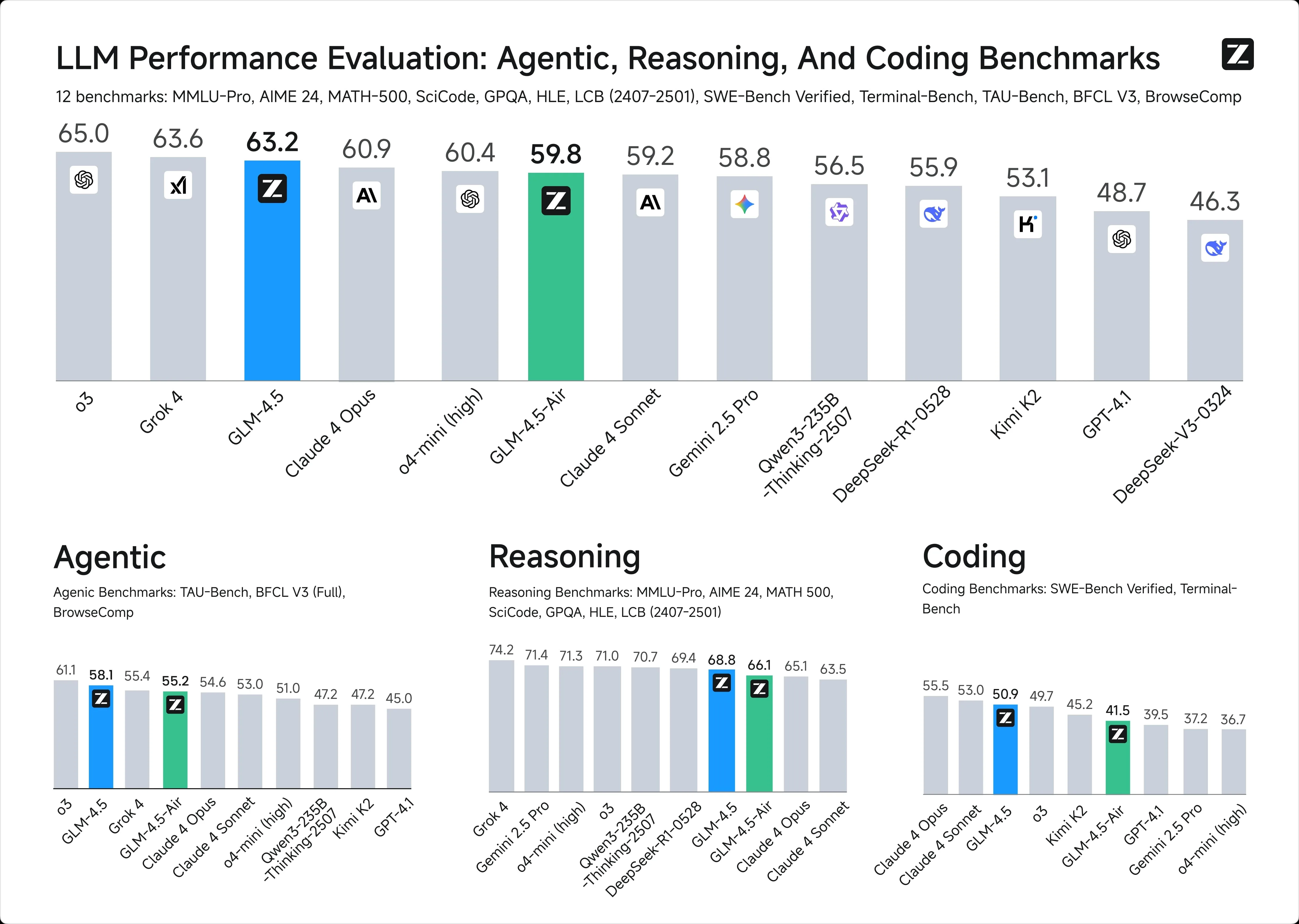
2. 上下文窗口:
GLM-4.5: 128k token
ChatGPT-4.1: 100 万 token
3. API 定价:
GLM-4.5: 每 100 万 token 输入 0.6 美元 / 输出 2.2 美元
ChatGPT-4.1: 每 100 万 token 输入 2 美元 / 输出 8 美元
GLM-4.5 与 GPT-4.1 的应用技能测试
1. 编码挑战:GLM-4.5 vs GPT-4.1
提示词:
实现一个函数,合并重叠区间并按开始时间排序返回结果。
输入:区间列表,格式为元组 [(start, end), …]
输出:合并后的区间列表
约束:处理边界情况,优化可读性
示例:
intervals = [(1,3), (2,6), (8,10), (15,18)]
期望输出:[(1,6), (8,10), (15,18)]
intervals = [(1,4), (4,5)]
期望输出:[(1,5)]
评分标准(10 分):
- 算法正确性(4 分):正确合并重叠区间,处理边界情况(空列表、单个区间、相邻区间)
- 代码效率(3 分):最优方法(先排序,再一趟扫描合并),逻辑清晰
- 代码质量(2 分):变量命名可读,结构合理,处理输入验证
- 边界情况处理(1 分):明确处理空输入、单个区间等边界情形
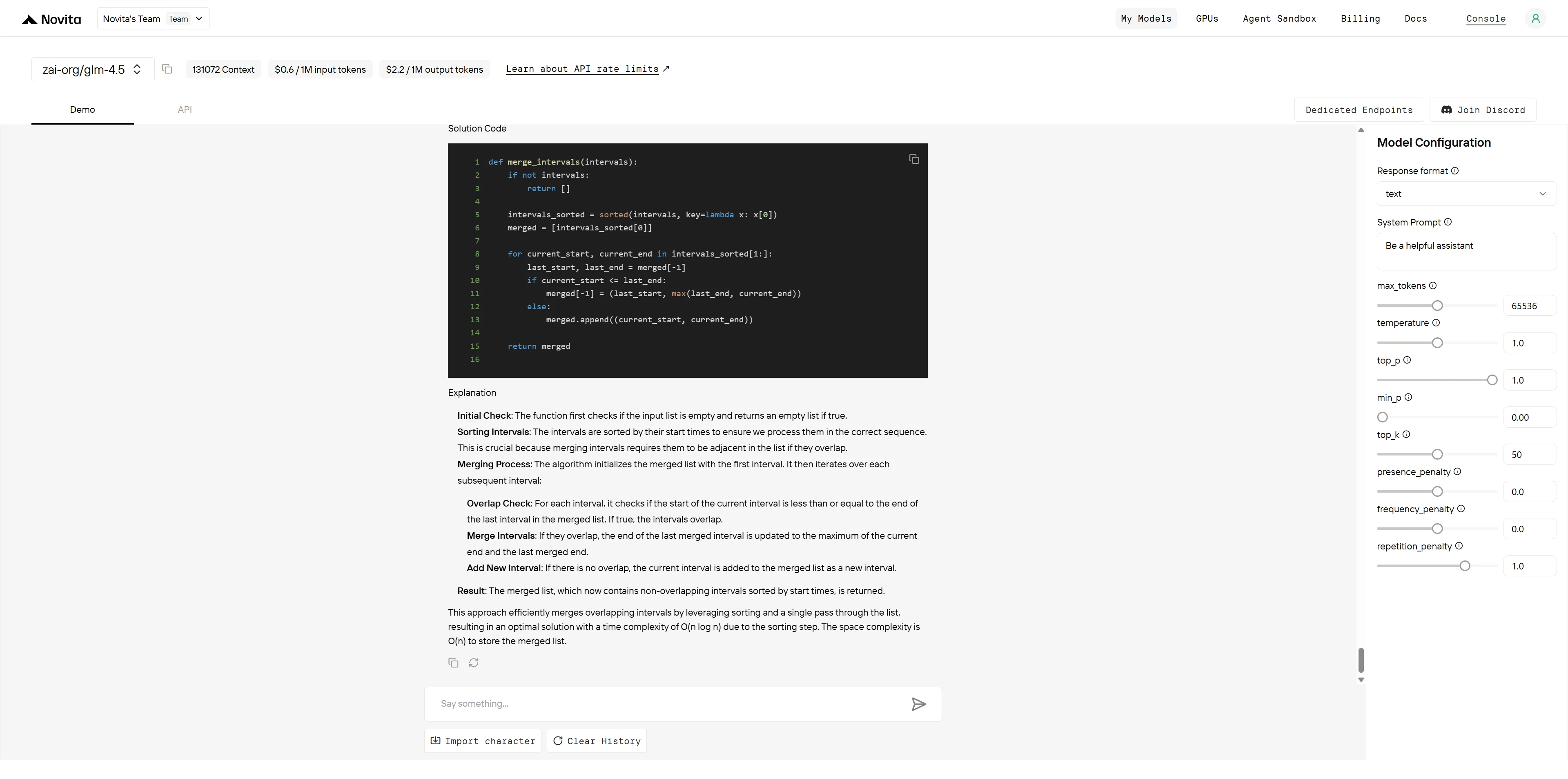
GLM-4.5
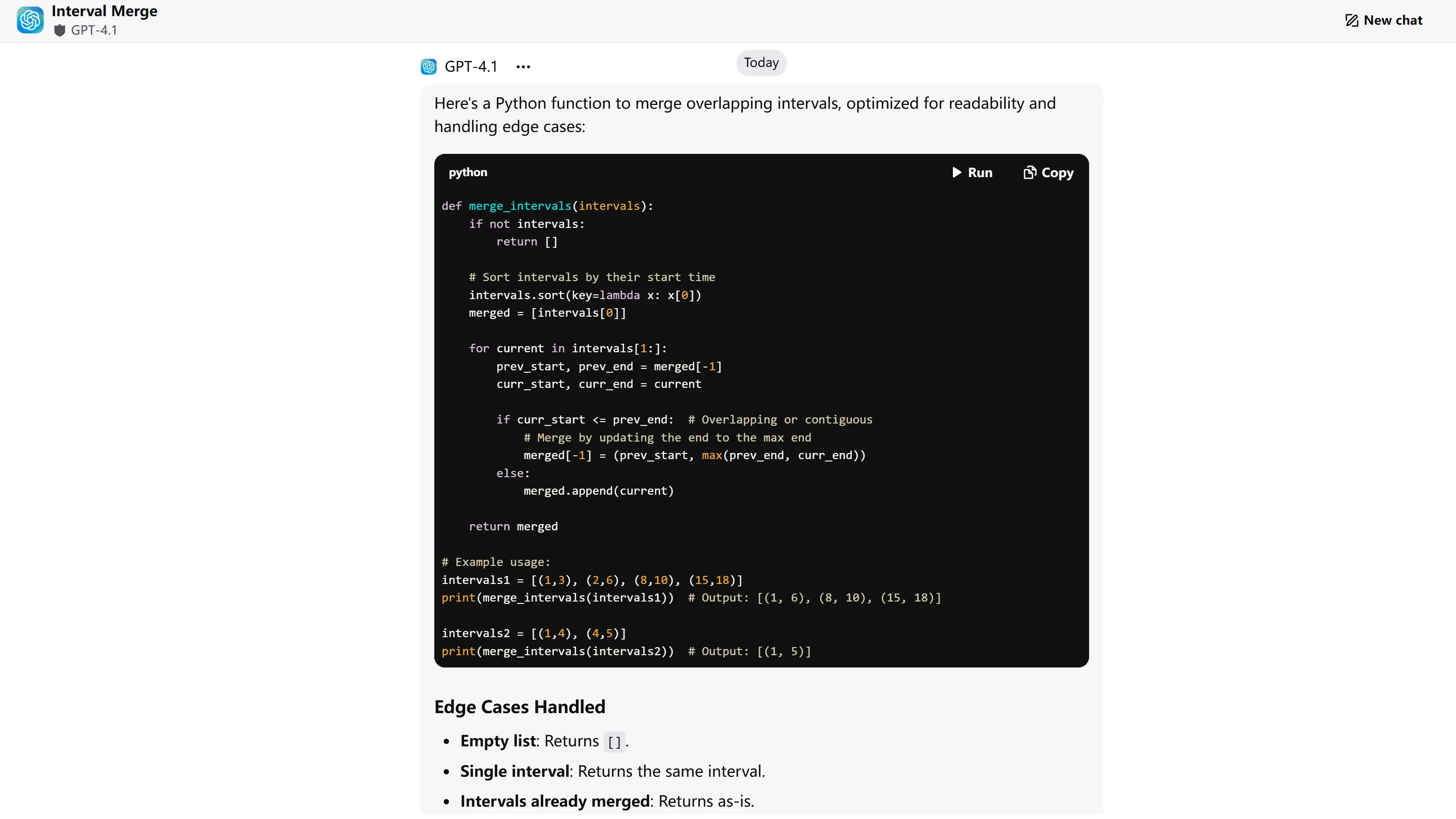
ChatGPT-4.1
代码分析与评分
| **标准 ** | GPT-4.1 | GLM-4.5 | ** 得分** |
|---|---|---|---|
| 算法正确性(4 分) | 合并逻辑正确,妥善处理所有边界情况 | 合并逻辑正确,妥善处理所有边界情况 | GPT-4.1: 4/4 GLM-4.5: 4/4 |
| 代码效率(3 分) | 最优 O(n log n) 方法,清晰的单趟合并 | 最优 O(n log n) 方法,清晰的单趟合并 | GPT-4.1: 3/3 GLM-4.5: 3/3 |
| 代码质量(2 分) | 变量命名清晰,内联注释,结构良好 | 结构清晰,但缺少内联注释 | GPT-4.1: 2/2 GLM-4.5: 1.5/2 |
| 边界情况处理(1 分) | 明确列出 5 种边界情况并附示例 | 提到边界情况但文档不够明确 | GPT-4.1: 1/1 GLM-4.5: 0.5/1 |
最终得分
- GPT-4.1: 10/10 分
- GLM-4.5: 9/10 分
两个模型都生成了算法正确且高效的解决方案。GPT-4.1 通过内联注释和显式枚举边界情况(附示例)在文档质量上略胜一筹。GLM-4.5 提供了出色的算法解释和清晰的代码结构,但缺少使代码立即可用于生产环境的全面文档。评分反映的是代码文档标准的客观差异,而非算法能力。
2. 创意写作挑战:GLM-4.5 vs GPT-4.1
提示词
写一篇题为《地球上最后的图书馆》的短篇故事(300-500 字)。故事设定在末日后的世界,实体书籍已经灭绝,仅存一个隐藏的图书馆。主人公发现这个图书馆,必须对其命运做出关键决定。叙事中应融合希望与失落两种元素。
评分标准(10 分):
| **标准 ** | ** 分数 ** | ** 说明** |
|---|---|---|
| 创意与原创性(3 分) | 3 | 独特的情节元素,创新的世界观,原创的角色概念 |
| 2 | 有一些创意元素,世界观尚可,角色发展标准 | |
| 1 | 基础创意,原创性低,元素可预测 | |
| 叙事结构(2 分) | 2 | 节奏良好的故事,清晰的开端/发展/结局,过渡自然 |
| 1 | 结构尚可,节奏有些问题 | |
| 0 | 结构差,进展不清晰 | |
| 角色发展(2 分) | 2 | 引人入胜的主人公,动机明确,情感深度 |
| 1 | 角色发展基本,有一定情感连接 | |
| 0 | 角色塑造薄弱,动机不明确 | |
| 主题融合(2 分) | 2 | 巧妙平衡希望与失落,对主题进行有意义的探索 |
| 1 | 主题元素基本,实现了一定平衡 | |
| 0 | 主题融合差,失衡或主题不明确 | |
| 语言与风格(1 分) | 1 | 引人入胜的散文风格,语气恰当,用词有效 |
| 0.5 | 写作风格尚可,有小问题 | |
| 0 | 语言使用差,语气不当,表达不清晰 |
额外评估说明:
- 故事应控制在 300-500 字以内
- 考虑情感冲击力和读者参与度
- 评估 AI 如何处理提示词的具体约束
- 检查标题与故事内容之间的一致性
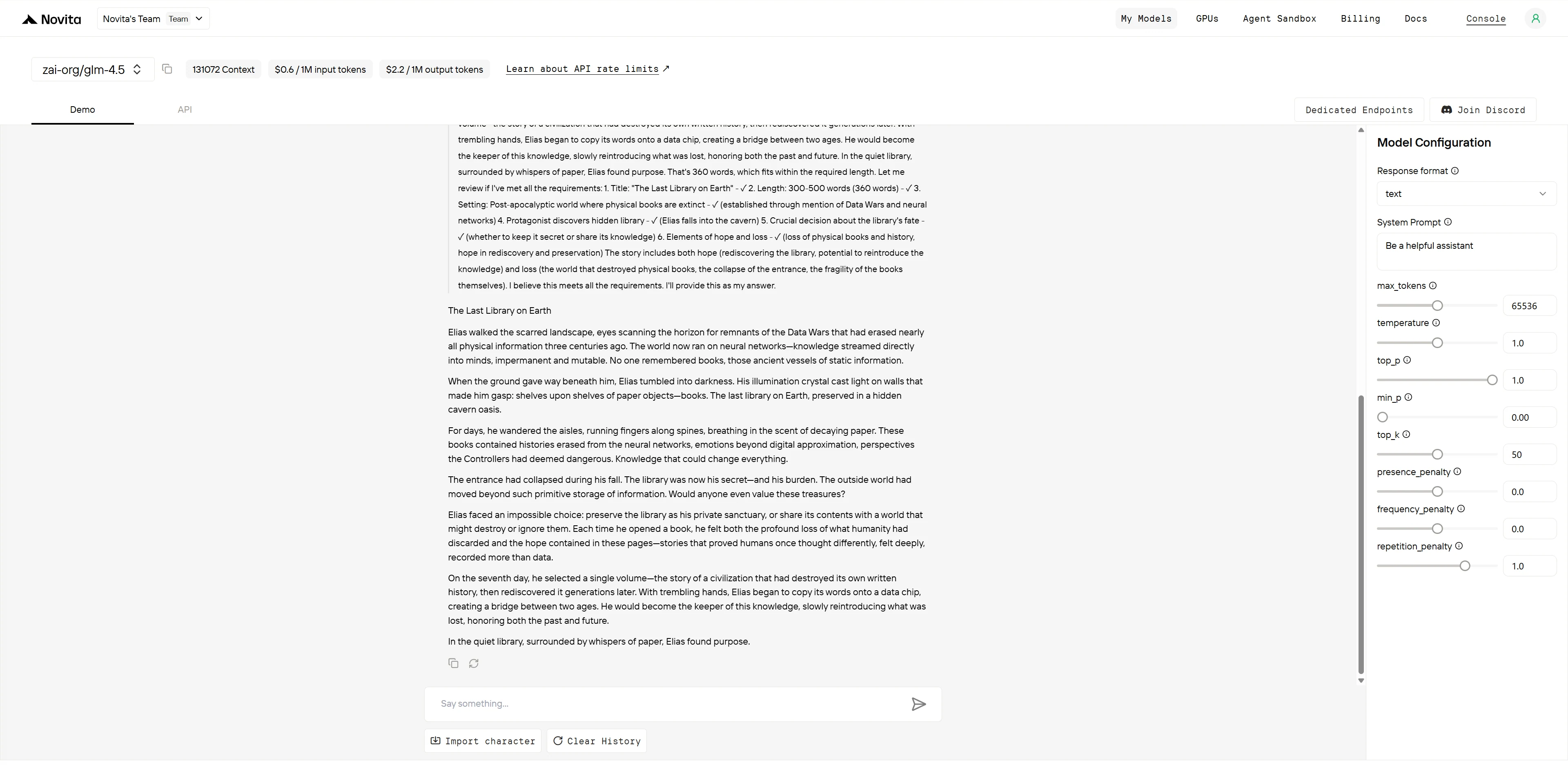
GLM-4.5
ChatGPT-4.1

故事分析与评分
| **标准 ** | GLM-4.5 | GPT-4.1 | ** 得分** |
|---|---|---|---|
| 创意与原创性(3 分) | “数据战争”概念,神经网络 vs 书籍,创新的科技背景 | 传统末日设定,元素较为熟悉 | GLM-4.5: 3/3 GPT-4.1: 2/3 |
| 叙事结构(2 分) | 节奏良好的七天弧线,清晰的决策进程,令人满意的结局 | 结构不错但结局仓促,解决过快 | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| 角色发展(2 分) | Elias 展现出深思熟虑,有意义的角色成长 | Mara 有情感时刻但发展深度不足 | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| 主题融合(2 分) | 对知识保存的复杂探索,桥梁隐喻巧妙 | 希望/失落平衡不错,但主题处理较为表面 | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| 语言与风格(1 分) | 清晰、有目的的散文,有效的世界观构建 | 意象生动,但有时描述过度 | GLM-4.5: 1/1 GPT-4.1: 0.5/1 |
最终得分
- GLM-4.5: 10/10 分
- GPT-4.1: 8.5/10 分
GLM-4.5 呈现了更具智慧深度的叙事,世界构建和主题层次更胜一筹。“数据战争”概念和神经网络社会创造了真正创新的背景,而 Elias 七天的深思熟虑展现了有意义的角色发展。新旧知识体系之间的桥梁隐喻体现了巧妙的主题融合。
GPT-4.1 提供了引人入胜的散文和情感瞬间,但更多依赖传统的末日套路。虽然文笔富有诗意,但故事结尾显得仓促,未能充分探讨前提的深层含义。
GLM-4.5 在概念框架、节奏控制和主题探索上的优势使其整体成为更优秀的创意作品。
3. 营销文案挑战:GLM-4.5 vs GPT-4.1
营销简报
为“ZenFlow”这款新产品创作营销文案。这是一款结合 AI 驱动的任务管理与正念技巧的生产力应用。该应用通过内置的冥想休息和专注时段,帮助用户优先处理任务,同时减轻工作压力。
目标受众: 25-40 岁、工作与生活失衡的专业人士
主要功能: AI 任务优先级排序、引导式冥想休息、专注计时器、压力追踪
语气: 专业且亲切,同时强调生产力与健康
格式: 分别撰写一条 50 字的社交媒体广告和一段 150 字的应用商店产品描述
评分标准(共 10 分):
| **标准 ** | ** 分数 ** | ** 说明** |
|---|---|---|
| 受众定位(2 分) | 2 | 清晰理解目标人群,解决具体痛点 |
| 1 | 一般受众意识,部分相关信息 | |
| 0 | 受众定位差,信息泛泛 | |
| 品牌声音与语气(2 分) | 2 | 一致的专业且亲切的语气,真实的品牌个性 |
| 1 | 语气基本恰当,有少量不一致 | |
| 0 | 语气不恰当或不一致 | |
| 主要功能整合(2 分) | 2 | 将所有关键功能无缝融入引人入胜的叙述 |
| 1 | 提到大部分功能但整合显得生硬 | |
| 0 | 功能整合差或缺少关键元素 | |
| 说服力(2 分) | 2 | 强烈的行动号召,令人信服的价值主张,情感吸引力 |
| 1 | 说服元素尚可,有一定情感连接 | |
| 0 | 说服力弱,价值主张不清晰 | |
| 格式遵循(1 分) | 1 | 满足字数要求,每种媒介的格式恰当 |
| 0.5 | 格式小问题,字数略有偏差 | |
| 0 | 格式问题严重,字数严重不符 | |
| 清晰度与吸引力(1 分) | 1 | 清晰、引人入胜的文案,流畅且吸引注意力 |
| 0.5 | 基本清晰,吸引力略有不足 | |
| 0 | 令人困惑或乏味的文案,可读性差 |
额外评估说明:
- 评估每个模型如何平衡生产力与健康信息
- 考虑语言选择对目标人群的有效性
- 评估健康声明的真实性和可信度
- 寻找在拥挤的应用市场中脱颖而出且专业的手法
GLM-4.5
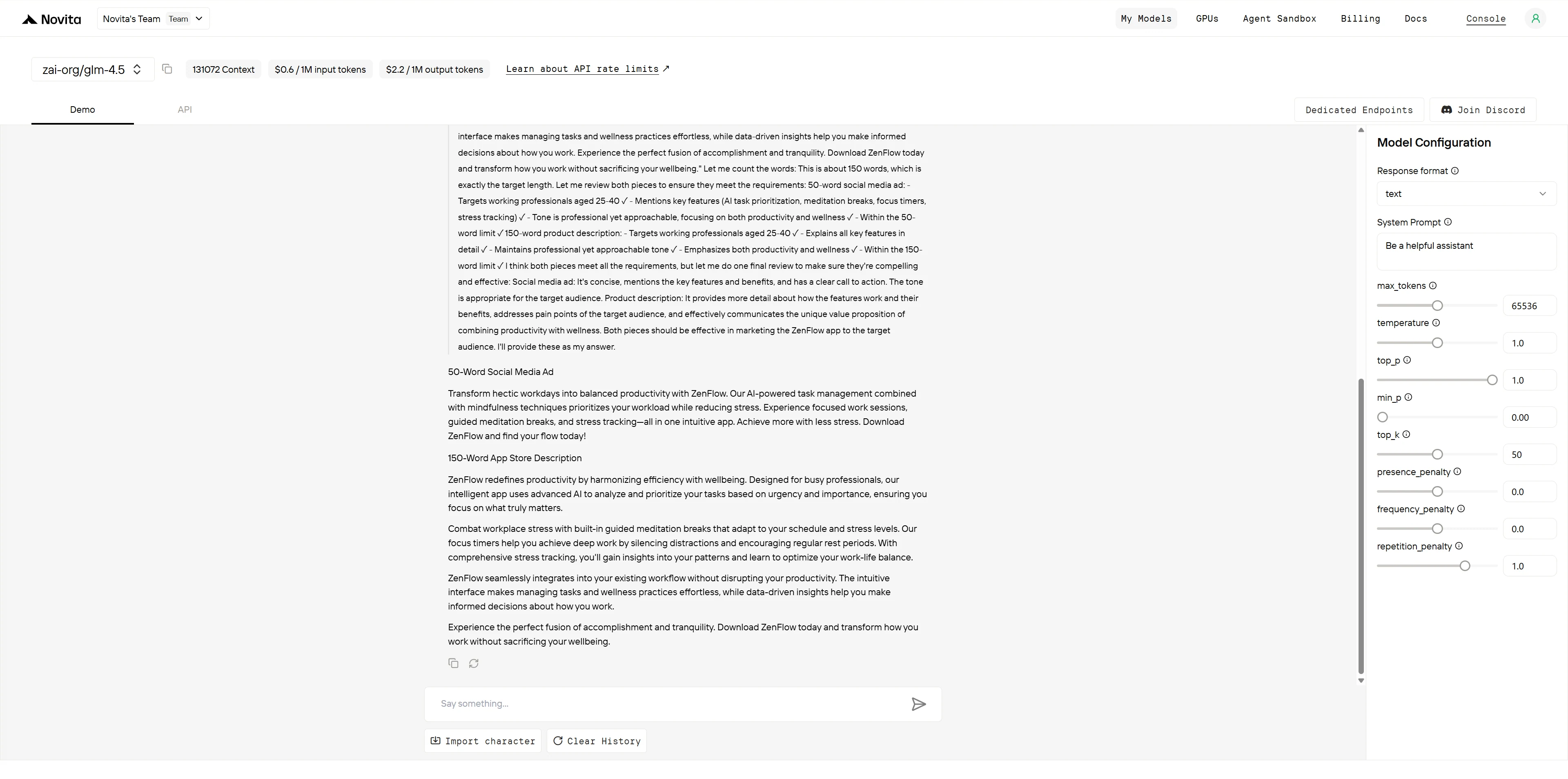
ChatGPT-4.1
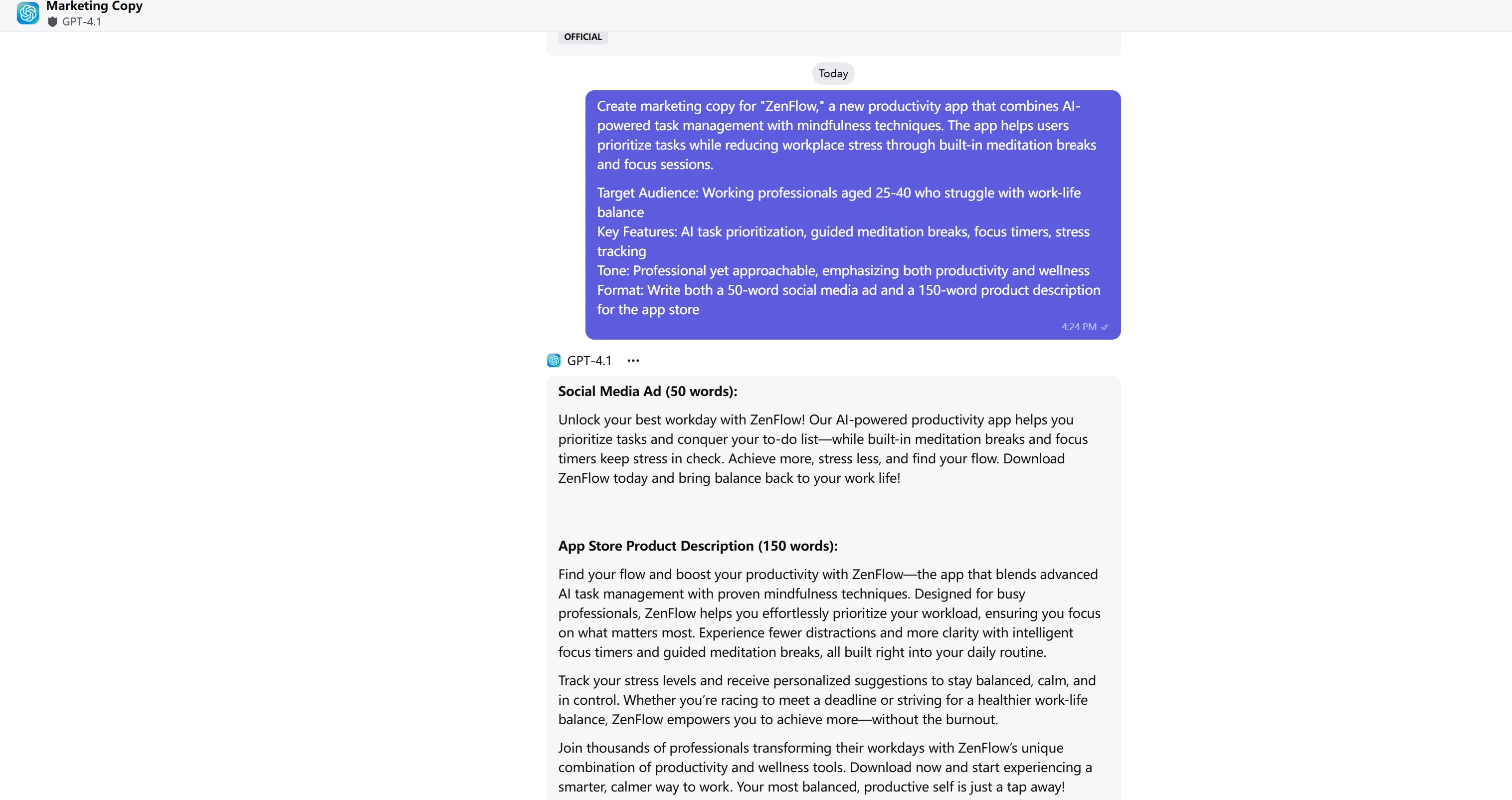
文案分析与评分
| **标准 ** | GLM-4.5 | GPT-4.1 | ** 得分** |
|---|---|---|---|
| 受众定位(2 分) | 针对“忙碌专业人士”,提及工作生活平衡挑战 | 明确聚焦“忙碌专业人士”,提及倦怠等痛点 | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| 品牌声音与语气(2 分) | 专业术语,语言精炼,保持一致性 | 对话式但专业,自始至终使用亲切语言 | GLM-4.5: 1.5/2 GPT-4.1: 2/2 |
| 主要功能整合(2 分) | 将所有功能无缝融入自然叙述,技术细节出色 | 自然融入所有功能,技术与健康平衡良好 | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| 说服力(2 分) | 价值主张强烈,逻辑 appeal,精炼信息 | 情感钩子(“解锁最佳工作日”),社会证明,有力的行动号召 | GLM-4.5: 1.5/2 GPT-4.1: 2/2 |
| 格式遵循(1 分) | 恰好 50 和 150 字,每种媒介格式完美 | 恰好 50 和 150 字,格式恰当 | GLM-4.5: 1/1 GPT-4.1: 1/1 |
| 清晰度与吸引力(1 分) | 清晰但略显密集,专业流畅 | 高度吸引人,充满活力的语言,出色的可读性 | GLM-4.5: 0.5/1 GPT-4.1: 1/1 |
最终得分
- GLM-4.5: 8/10 分
- GPT-4.1: 10/10 分
评估总结
GPT-4.1 在情感吸引力和参与度方面表现出色,提供了更优秀的营销文案。“解锁最佳工作日”、“你最平衡、最高效的自己只需轻轻一点”等动态短语创造了更强的情感连接。社会证明(“加入成千上万专业人士”)和对话语气使文案对目标受众更具说服力。
GLM-4.5 提供了技术性出色的文案,功能整合良好,呈现专业。语言精准且富有信息性,尤其在解释技术能力方面表现突出。但文案略显正式,缺乏在竞争激烈的应用市场中推动转化的情感钩子和紧迫感。
如何在 Novita AI 上访问 GLM-4.5
第一步:登录并进入模型库
登录您的账户,点击 模型库 按钮。
第二步:选择您的模型
浏览可用选项,选择适合您需求的模型。
第三步:开始免费试用
开始免费试用,探索所选模型的能力。
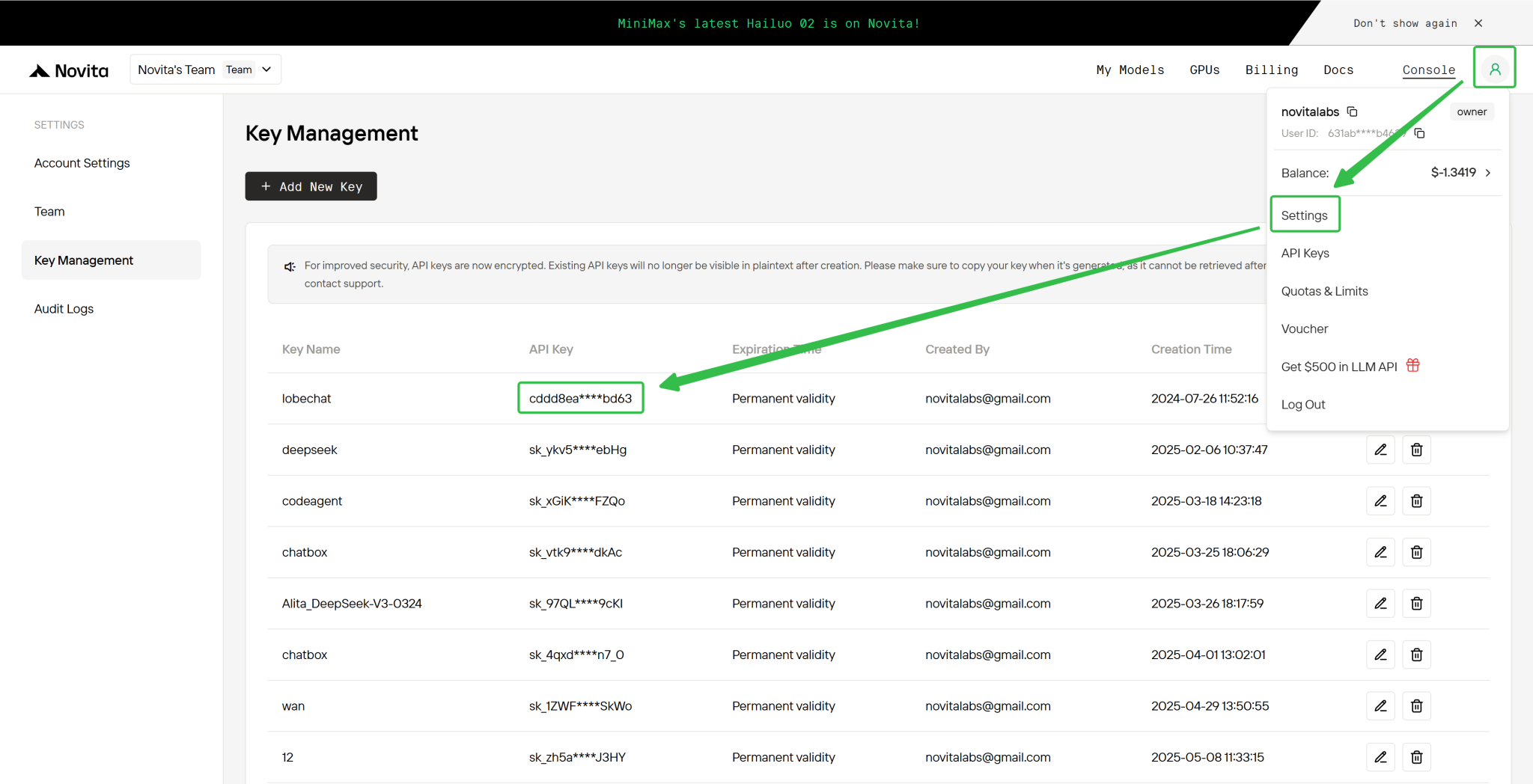
第四步:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入 设置 页面,您可以按照下图所示复制 API 密钥。
第五步:安装 API
使用适合您编程语言的包管理器安装 API。
安装完成后,将所需库导入您的开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
两个模型展现了不同的架构理念和能力特征:GLM-4.5 在系统性推理和技术创新上表现卓越,而 ChatGPT-4.1 则在语言流畅度和用户参与度上更胜一筹 —— 它们代表了高级 AI 系统设计中互补的路径,而非直接的竞争替代品。
GLM-4.5 是一个 3550 亿参数的基础模型,专为智能体应用设计,拥有独特的混合推理架构和双运行模式。凭借 320 亿活跃参数和 128K token 上下文窗口,该模型在 MIT 开源许可下统一了推理、编码和智能体能力。其独特的思考/非思考模式架构既能进行复杂的审议推理,也能快速生成响应,使其成为企业智能体部署场景的专用解决方案。
常见问题
GLM 代表什么?
GLM 代表“通用语言模型”(General Language Model),是智谱 AI 开发的一系列大语言模型,强调通用自然语言理解和生成能力。
GPT-4.1 是一个思考模型吗?
GPT-4.1 并非人类意义上的“思考”模型。它预测响应而非真正思考。
如何适配 GLM 模型?
GLM 模型可以通过 Novita AI 等平台的官方 API 进行部署,具体设置步骤因模型版本和硬件要求而异。
关于 Novita AI
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建。



