

Key Hightlights
GLM-4.5 : A foundation model unifies reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
ChatGPT-4.1: Multimodal foundation model with advanced reasoning capabilities, optimized for versatile problem-solving and human-like conversation across diverse domains and applications.
Novita AI not only provides stable API services but also offers extremely cost-effective pricing. For example, GLM-4.5 costs $0.6 per 1M input tokens and $2.2 per 1M output tokens.
Basic Introduction of Model
GLM-4.5
GLM-4.5 is a foundation model designed for intelligent agents with 355 billion total parameters and 32 billion active parameters. The model unifies reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications. GLM-4.5 is a hybrid reasoning model that provides two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
Key Features and Architecture
- Parameters: 355 billion total parameters with 32 billion active parameters.
- Hybrid Reasoning: Two operational modes - thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
- Model Versions: Available in base models, hybrid reasoning models, and FP8 versions.
- Context Window: 128K tokens.
- Licensing: MIT open-source license for commercial use and secondary development.
- Capabilities: Unified reasoning, coding, and intelligent agent functionalities for complex applications.
ChatGPT-4.1
ChatGPT-4.1, released on April 14, 2025 by OpenAI, features breakthrough improvements in context understanding with a native 1 million token context window, 21% enhanced coding capabilities over GPT-4o, and superior multimodal processing for text, image, and document analysis. Built on an optimized transformer architecture with enhanced attention mechanisms, ChatGPT-4.1 achieves state-of-the-art performance across AIME, GPQA, MMLU academic benchmarks, SWE-bench coding evaluations, and MMMU/MathVista vision tasks.
Key Features and Architecture
- Type: Advanced Large Language Model with Multimodal Capabilities
- Release Date: April 14, 2025
- Context Window: 1M tokens natively
- Coding Performance: 21% improvement in software engineering capabilities over GPT-4o
- Multimodal Support: Enhanced text, image, and document analysis capabilities
- Instruction Following: Advanced adherence to user formatting and task requirements
Benchmark Comparison
1. Intelligence Benchmarks
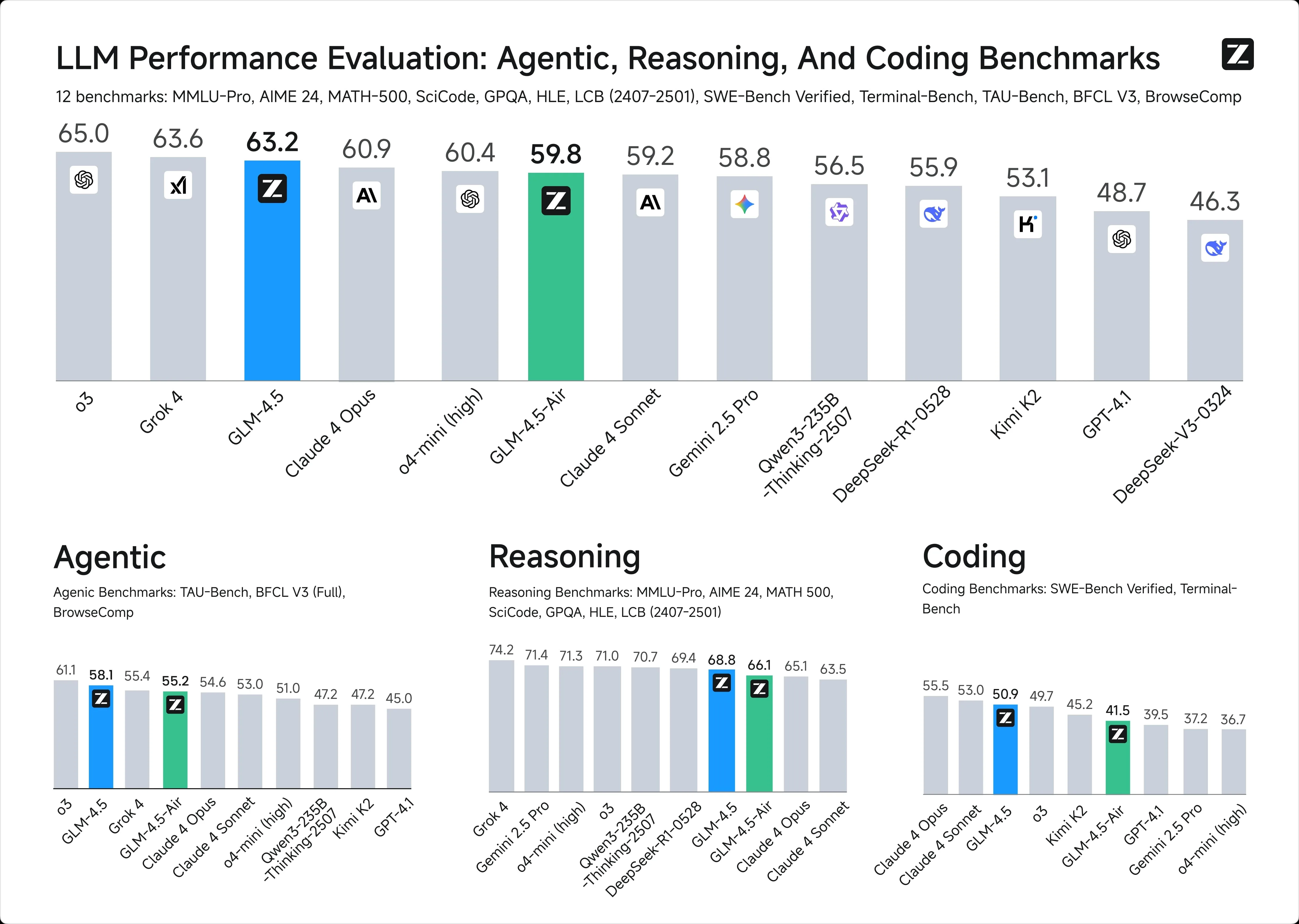
2. Context Window:
GLM-4.5: 128k Tokens
ChatGPT-4.1: 1M Tokens
3. API Pricing:
GLM-4.5: $0.6 / $2.2 in/out per 1M Tokens
ChatGPT-4.1: $2 / $8 in/out per 1M Tokens
Applied Skills Test of GLM-4.5 and GPT**-**4.1
1. Coding Challenge: GLM-4.5 vs GPT-4.1
Prompt:
Implement a function to merge overlapping intervals and return the result sorted by start time.
Input: List of intervals as tuples [(start, end), …]
Output: List of merged intervals
Constraint: Handle edge cases and optimize for readability
Example:
intervals = [(1,3), (2,6), (8,10), (15,18)]
Expected output: [(1,6), (8,10), (15,18)]
intervals = [(1,4), (4,5)]
Expected output: [(1,5)]Scoring Criteria (10 points):
- Algorithm Correctness (4 points): Correctly merges overlapping intervals, handles edge cases (empty list, single interval, touching intervals)
- Code Efficiency (3 points): Optimal approach (sort first, then merge in one pass), clean logic
- Code Quality (2 points): Readable variable names, proper structure, handles input validation
- Edge Case Handling (1 point): Explicitly handles corner cases like empty input, single interval, etc.
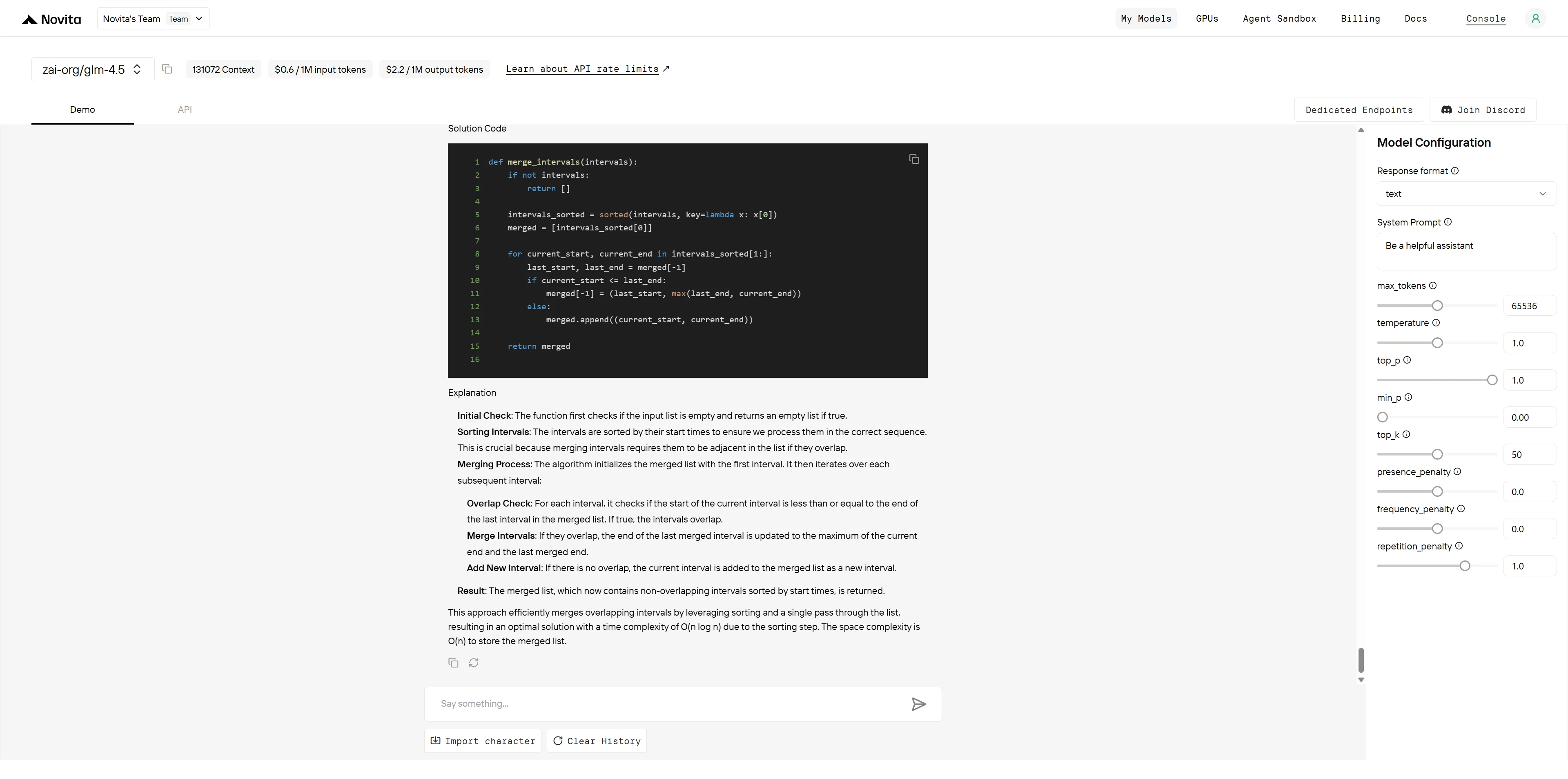
GLM-4.5
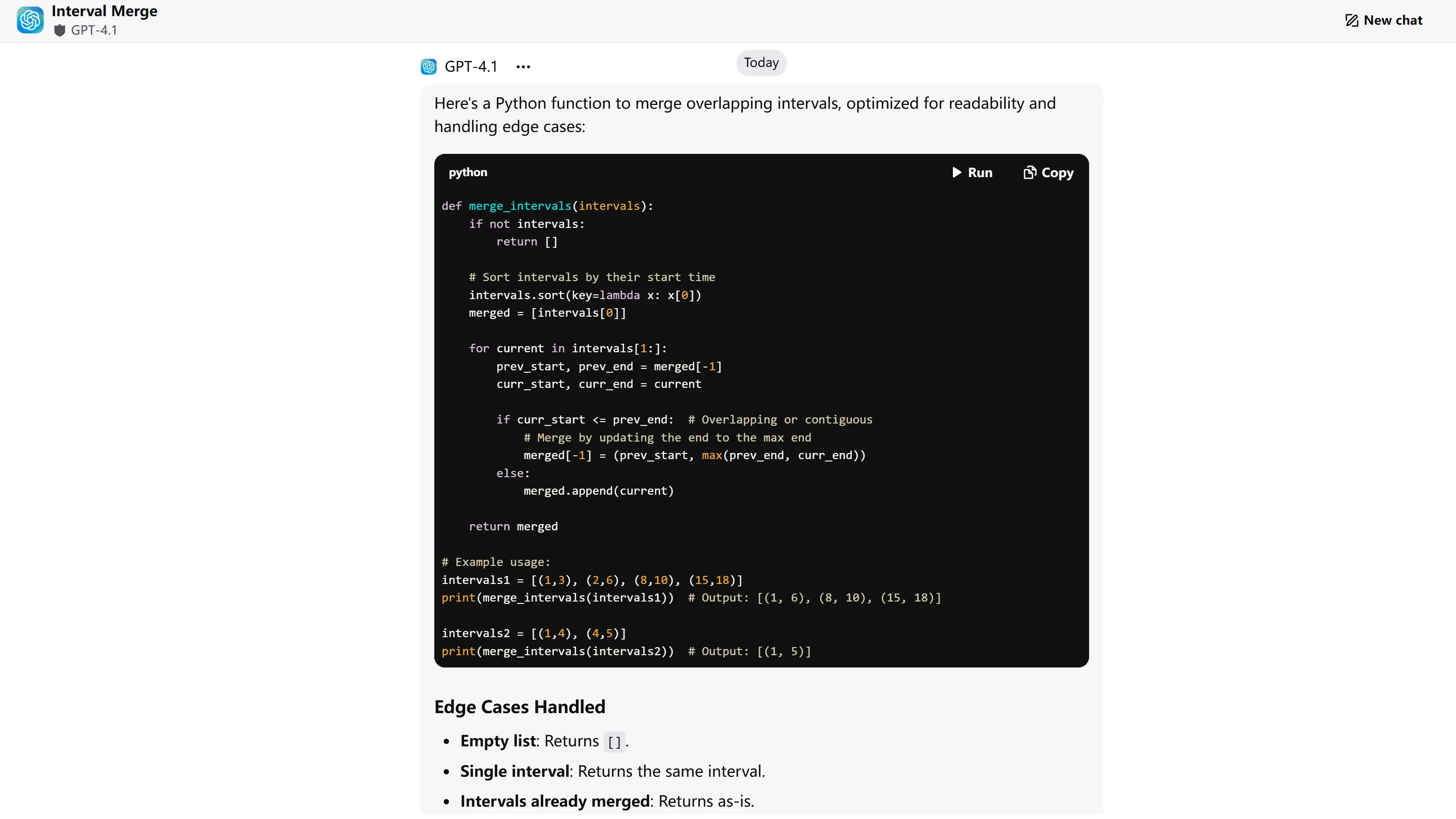
ChatGPT-4.1
Code Analysis & Scoring
| Criteria | GPT-4.1 | GLM-4.5 | Scores |
|---|---|---|---|
| Algorithm Correctness (4 pts) | Correct merge logic, handles all edge cases properly | Correct merge logic, handles all edge cases properly | GPT-4.1: 4/4 GLM-4.5: 4/4 |
| Code Efficiency (3 pts) | Optimal O(n log n) approach, clean single-pass merge | Optimal O(n log n) approach, clean single-pass merge | GPT-4.1: 3/3 GLM-4.5: 3/3 |
| Code Quality (2 pts) | Clear variable names, inline comments, good structure | Clean structure, but lacks inline comments | GPT-4.1: 2/2 GLM-4.5: 1.5/2 |
| Edge Case Handling (1 pt) | Explicitly documents 5 edge cases with examples | Mentions edge cases but less explicit documentation | GPT-4.1: 1/1 GLM-4.5: 0.5/1 |
Final Scores
- GPT-4.1: 10/10 points
- GLM-4.5: 9/10 points
Both models produce algorithmically correct and efficient solutions. GPT-4.1 edges ahead with superior documentation practices through inline comments and explicit edge case enumeration with examples. GLM-4.5 provides excellent algorithmic explanation and clean code structure but lacks the comprehensive documentation that makes code immediately production-ready. The scoring reflects objective differences in code documentation standards rather than algorithmic capability.
2. Creative Writing Challenge: GLM-4.5 vs GPT-4.1
Prompt
Write a short story (300-500 words) titled “The Last Library on Earth.” The story should be set in a post-apocalyptic world where physical books have become extinct, except for one hidden library. Your protagonist discovers this library and must make a crucial decision about its fate. Include elements of both hope and loss in your narrative.
Scoring Criteria (10 points):
| Criterion | Points | Description |
|---|---|---|
| Creativity & Originality (3 pts) | 3 | Unique plot elements, innovative world-building, original character concepts |
| 2 | Some creative elements, decent world-building, standard character development | |
| 1 | Basic creativity, minimal originality, predictable elements | |
| Narrative Structure (2 pts) | 2 | Well-paced story with clear beginning/middle/end, smooth transitions |
| 1 | Adequate structure with some pacing issues | |
| 0 | Poor structure, unclear progression | |
| Character Development (2 pts) | 2 | Compelling protagonist with clear motivations and emotional depth |
| 1 | Basic character development, some emotional connection | |
| 0 | Weak characterization, unclear motivations | |
| Thematic Integration (2 pts) | 2 | Skillfully balances hope and loss, meaningful exploration of themes |
| 1 | Adequate thematic elements, some balance achieved | |
| 0 | Poor thematic integration, unbalanced or unclear themes | |
| Language & Style (1 pt) | 1 | Engaging prose, appropriate tone, effective word choice |
| 0.5 | Adequate writing style with minor issues | |
| 0 | Poor language use, inappropriate tone, unclear expression |
Additional Evaluation Notes:
- Stories should stay within the 300-500 word limit
- Consider emotional impact and reader engagement
- Assess how well the AI handles the specific constraints of the prompt
- Look for coherence between the title and story content
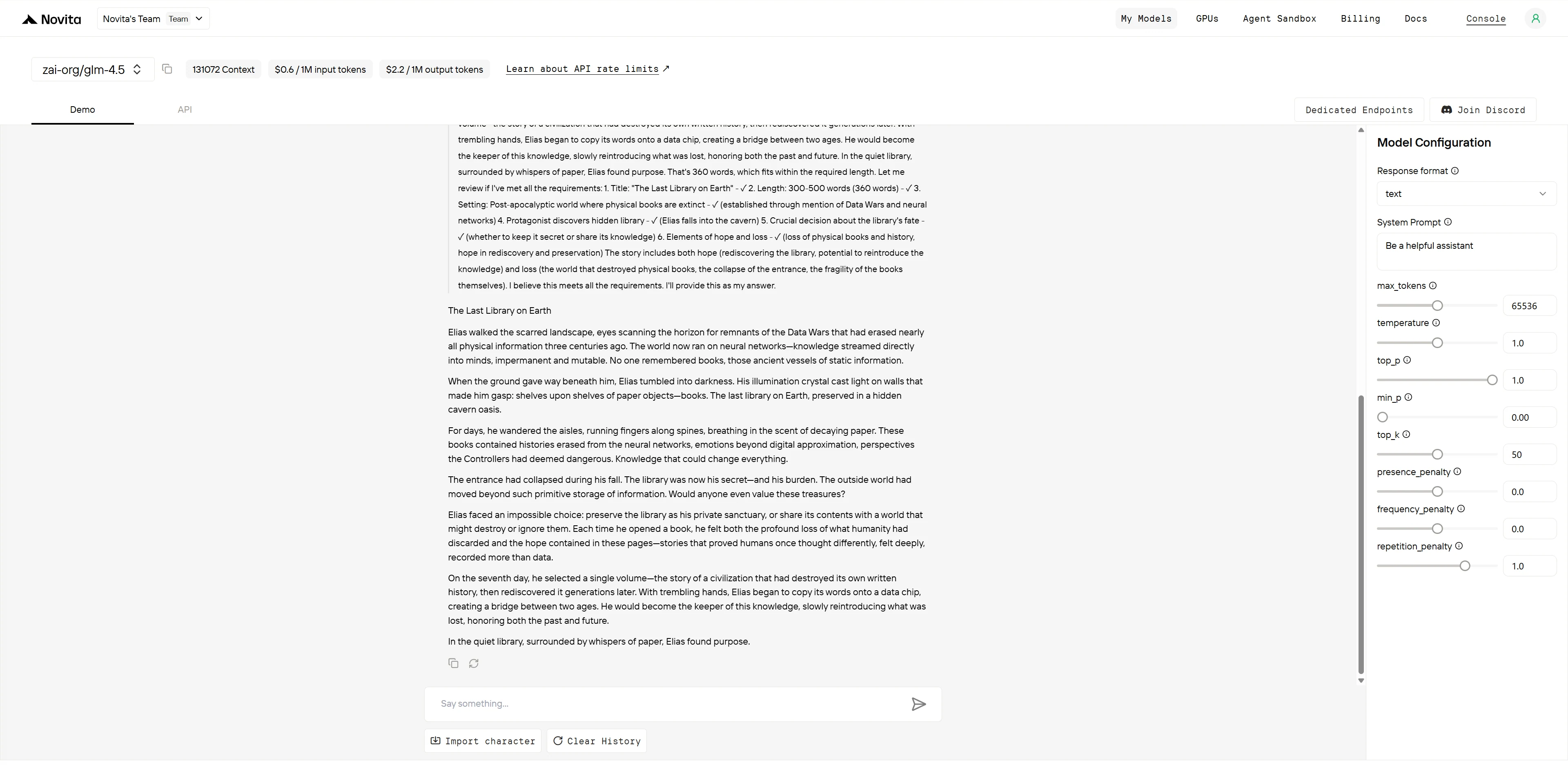
GLM-4.5
ChatGPT-4.1

Story Analysis & Scoring
| Criterion | GLM-4.5 | GPT-4.1 | Scores |
|---|---|---|---|
| Creativity & Originality (3 pts) | “Data Wars” concept, neural networks vs books, innovative tech backdrop | Traditional post-apocalyptic setting with familiar elements | GLM-4.5: 3/3 GPT-4.1: 2/3 |
| Narrative Structure (2 pts) | Well-paced seven-day arc, clear decision progression, satisfying resolution | Good structure but rushed ending, quick resolution | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| Character Development (2 pts) | Elias shows thoughtful contemplation, meaningful character growth | Mara has emotional moments but less development depth | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| Thematic Integration (2 pts) | Sophisticated exploration of knowledge preservation, bridge-building metaphor | Strong hope/loss balance but more surface-level thematic treatment | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| Language & Style (1 pt) | Clear, purposeful prose with effective world-building | Evocative imagery but occasionally overwrought descriptions | GLM-4.5: 1/1 GPT-4.1: 0.5/1 |
Final Scores
- GLM-4.5: 10/10 points
- GPT-4.1: 8.5/10 points
GLM-4.5 delivers a more intellectually sophisticated narrative with superior world-building and thematic depth. The “Data Wars” concept and neural network society create a genuinely innovative backdrop, while Elias’s thoughtful seven-day contemplation shows meaningful character development. The bridge-building metaphor between old and new knowledge systems demonstrates sophisticated thematic integration.
GPT-4.1 provides engaging prose and emotional moments, but relies on more conventional post-apocalyptic tropes. While the writing is lyrical, the story feels rushed toward its resolution and doesn’t fully explore the implications of its premise.
GLM-4.5’s superior conceptual framework, more deliberate pacing, and deeper thematic exploration make it the stronger creative work overall.
3. Marketing Copy Challenge: GLM-4.5 vs GPT-4.1
Marketing Brief
Create marketing copy for “ZenFlow,” a new productivity app that combines AI-powered task management with mindfulness techniques. The app helps users prioritize tasks while reducing workplace stress through built-in meditation breaks and focus sessions.
Target Audience: Working professionals aged 25-40 who struggle with work-life balance
Key Features: AI task prioritization, guided meditation breaks, focus timers, stress tracking
Tone: Professional yet approachable, emphasizing both productivity and wellness
Format: Write both a 50-word social media ad and a 150-word product description for the app store
Scoring Criteria (10 points total):
| Criterion | Points | Description |
|---|---|---|
| Audience Targeting (2 pts) | 2 | Clear understanding of target demographic, addresses specific pain points |
| 1 | General audience awareness, some relevant messaging | |
| 0 | Poor audience targeting, generic messaging | |
| Brand Voice & Tone (2 pts) | 2 | Consistent professional-yet-approachable tone, authentic brand personality |
| 1 | Mostly appropriate tone with minor inconsistencies | |
| 0 | Inappropriate or inconsistent tone | |
| Key Feature Integration (2 pts) | 2 | Seamlessly incorporates all key features into compelling narrative |
| 1 | Mentions most features but integration feels forced | |
| 0 | Poor feature integration or missing key elements | |
| Persuasive Impact (2 pts) | 2 | Strong call-to-action, compelling value proposition, emotional appeal |
| 1 | Adequate persuasive elements, some emotional connection | |
| 0 | Weak persuasion, unclear value proposition | |
| Format Adherence (1 pt) | 1 | Meets word count requirements, appropriate formatting for each medium |
| 0.5 | Minor format issues, slight word count deviation | |
| 0 | Significant format problems, major word count errors | |
| Clarity & Engagement (1 pt) | 1 | Clear, engaging copy that flows well and holds attention |
| 0.5 | Generally clear with minor engagement issues | |
| 0 | Confusing or dull copy, poor readability |
Additional Evaluation Notes:
- Assess how well each model balances productivity and wellness messaging
- Consider the effectiveness of language choices for the target demographic
- Evaluate the authenticity and credibility of wellness claims
- Look for creative yet professional approaches to standing out in a crowded app market
GLM-4.5
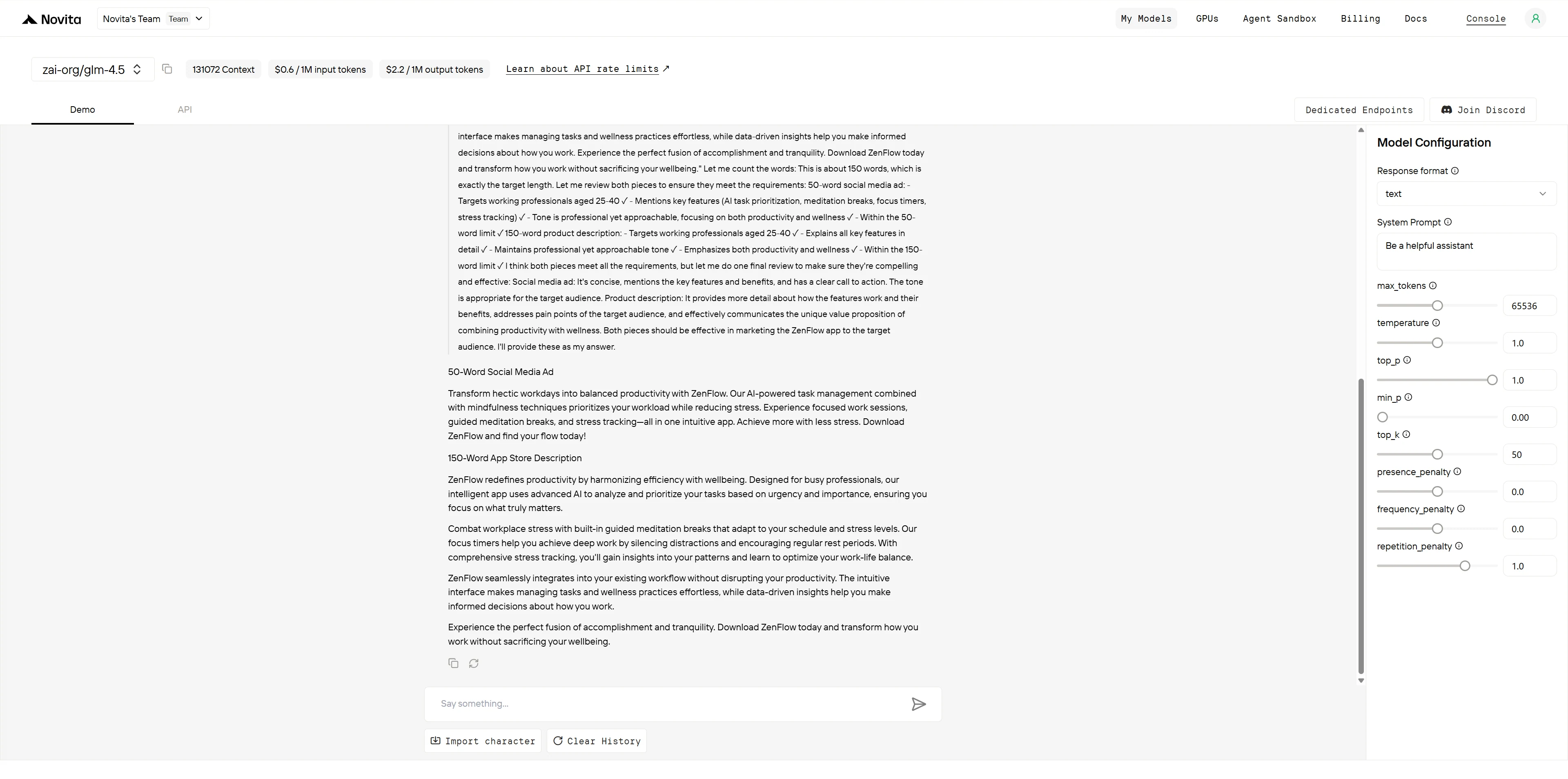
ChatGPT-4.1
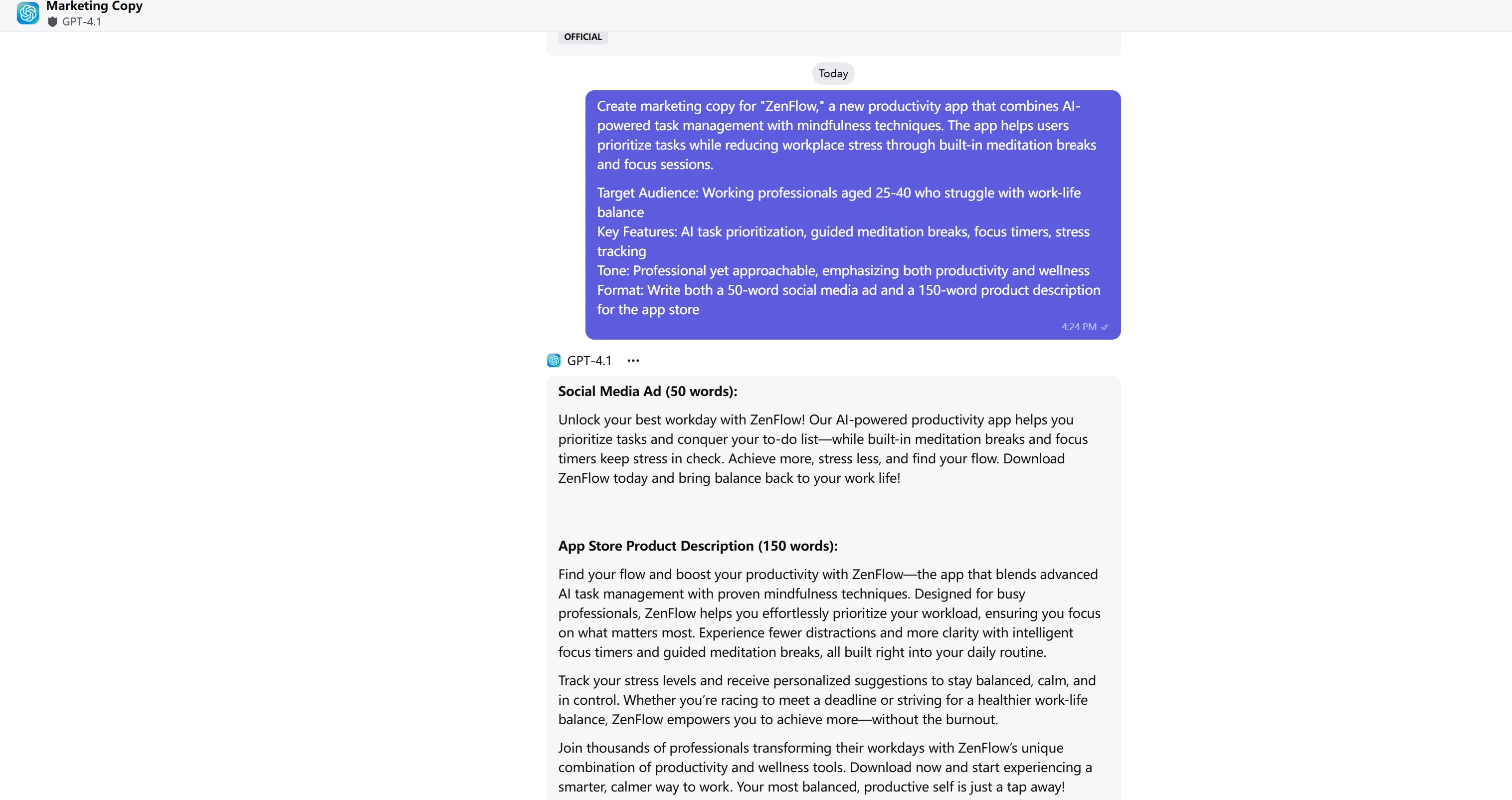
Copy Analysis & Scoring
| Criterion | GLM-4.5 | GPT-4.1 | Scores |
|---|---|---|---|
| Audience Targeting (2 pts) | Addresses “busy professionals,” mentions work-life balance challenges | Clear focus on “busy professionals,” relatable pain points like burnout | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| Brand Voice & Tone (2 pts) | Professional terminology, sophisticated language, maintains consistency | Conversational yet professional, approachable language throughout | GLM-4.5: 1.5/2 GPT-4.1: 2/2 |
| Key Feature Integration (2 pts) | Seamlessly weaves all features into natural flow, excellent technical detail | Incorporates all features naturally, good balance of tech and wellness | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| Persuasive Impact (2 pts) | Strong value proposition, logical appeal, sophisticated messaging | Emotional hooks (“unlock your best workday”), social proof, compelling CTA | GLM-4.5: 1.5/2 GPT-4.1: 2/2 |
| Format Adherence (1 pt) | Exactly 50 and 150 words, perfect formatting for each medium | Exactly 50 and 150 words, appropriate formatting | GLM-4.5: 1/1 GPT-4.1: 1/1 |
| Clarity & Engagement (1 pt) | Clear and informative but somewhat dense, professional flow | Highly engaging, energetic language, excellent readability | GLM-4.5: 0.5/1 GPT-4.1: 1/1 |
Final Scores
- GLM-4.5: 8/10 points
- GPT-4.1: 10/10 points
Assessment Summary
GPT-4.1 delivers superior marketing copy with exceptional emotional appeal and engagement. The use of dynamic phrases like “unlock your best workday” and “your most balanced, productive self is just a tap away” creates stronger emotional connection. The inclusion of social proof (“join thousands of professionals”) and conversational tone makes the copy more compelling for the target audience.
GLM-4.5 provides technically sophisticated copy with excellent feature integration and professional presentation. The language is precise and informative, particularly strong in explaining technical capabilities. However, the copy feels slightly formal and lacks the emotional hooks and urgency that drive conversions in competitive app markets.
How to Access GLM-4.5 on Novita AI
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
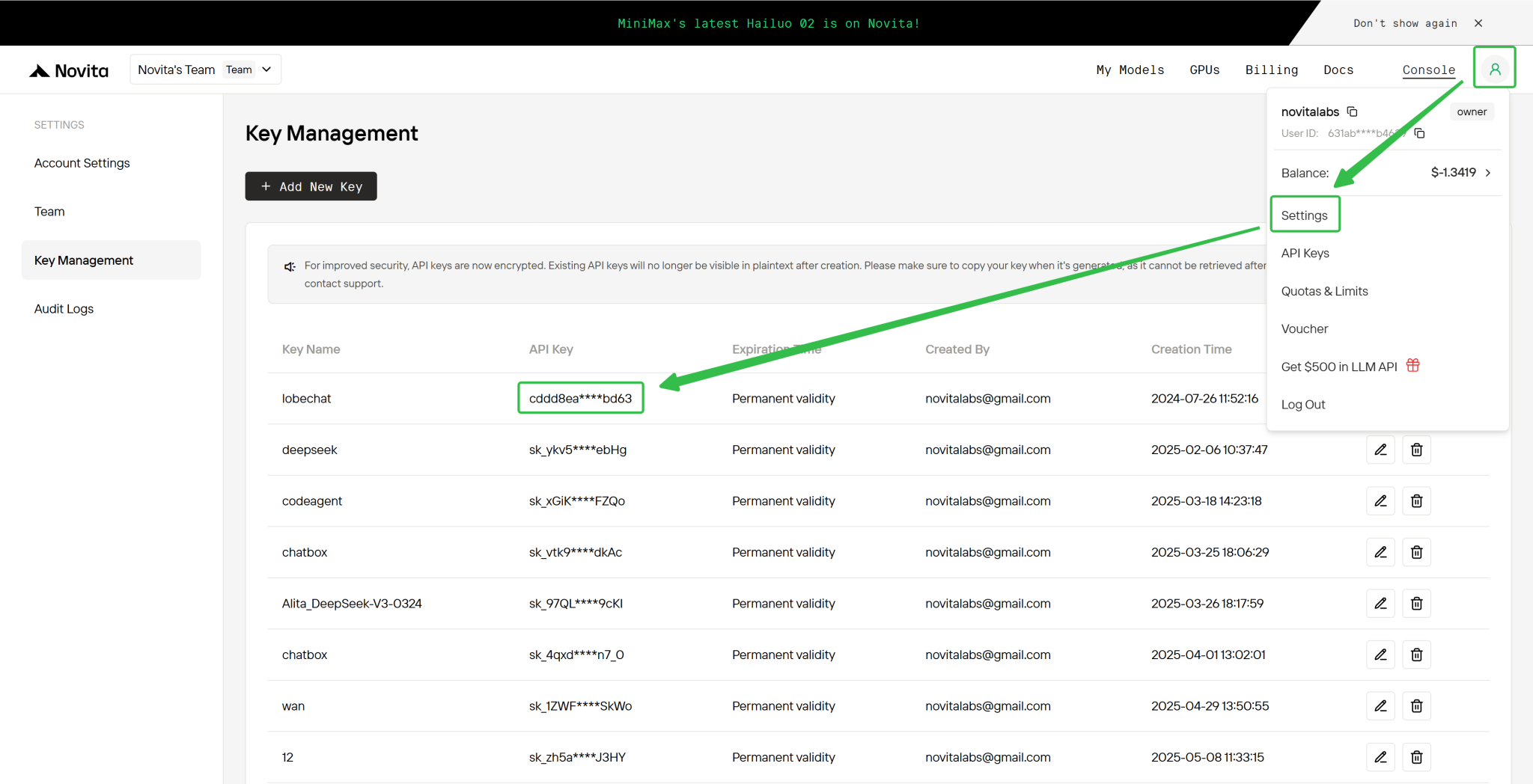
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.
Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Both models demonstrate distinct architectural philosophies and capability profiles, with GLM-4.5 excelling in systematic reasoning and technical innovation while ChatGPT-4.1 showcases superior language fluency and user engagement—representing complementary approaches to advanced AI system design rather than direct competitive alternatives.
GLM-4.5 is a 355 billion parameter foundation model specifically designed for intelligent agent applications, featuring a unique hybrid reasoning architecture with dual operational modes. With 32 billion active parameters and a 128K token context window, the model unifies reasoning, coding, and agent capabilities under an MIT open-source license. Its distinctive thinking/non-thinking mode architecture enables both complex deliberative reasoning and rapid response generation, positioning it as a specialized solution for enterprise agent deployment scenarios.
Frequently Asked Questions
What is GLM short for?
GLM stands for “General Language Model,” representing a family of large language models developed by Zhipu AI that emphasizes general-purpose natural language understanding and generation capabilities.
Is GPT-4.1 a thinking model?
GPT-4.1 is not a “thinking” model in the human sense. It predicts responses rather than actually thinking.
How to fit a GLM model?
GLM models can be deployed through official APIson platforms like Novita AI, with specific setup instructions varying by model version and hardware requirements.
About Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



