

Wichtige Highlights
GLM-4.5 : Ein Foundation-Modell, das Reasoning, Coding und intelligente Agentenfähigkeiten vereint, um den komplexen Anforderungen von Anwendungen mit intelligenten Agenten gerecht zu werden.
ChatGPT-4.1: Multimodales Foundation-Modell mit erweiterten Reasoning-Fähigkeiten, optimiert für vielseitige Problemlösungen und menschenähnliche Konversationen in verschiedenen Bereichen und Anwendungen.
Novita AI bietet nicht nur stabile API-Dienste, sondern auch extrem kostengünstige Preise. So kostet GLM-4.5 $0,6 pro 1 Million Input-Token und $2,2 pro 1 Million Output-Token.
Grundlegende Einführung der Modelle
GLM-4.5
GLM-4.5 ist ein Foundation-Modell, das für intelligente Agenten entwickelt wurde, mit insgesamt 355 Milliarden Parametern und 32 Milliarden aktiven Parametern. Das Modell vereint Reasoning-, Coding- und Agentenfähigkeiten, um den komplexen Anforderungen von Anwendungen mit intelligenten Agenten gerecht zu werden. GLM-4.5 ist ein hybrides Reasoning-Modell, das zwei Modi bietet: einen Denkmodus für komplexes Reasoning und Werkzeugnutzung sowie einen Nicht-Denkmodus für sofortige Antworten.
Hauptmerkmale und Architektur
- Parameter: 355 Milliarden Gesamtparameter mit 32 Milliarden aktiven Parametern.
- Hybrides Reasoning: Zwei Betriebsmodi – Denkmodus für komplexes Reasoning und Werkzeugnutzung, sowie Nicht-Denkmodus für sofortige Antworten.
- Modellversionen: Verfügbar als Basis-Modelle, hybride Reasoning-Modelle und FP8-Versionen.
- Kontextfenster: 128K Token.
- Lizenzierung: MIT-Open-Source-Lizenz für kommerzielle Nutzung und Weiterentwicklung.
- Fähigkeiten: Vereinheitlichte Reasoning-, Coding- und Agentenfunktionalitäten für komplexe Anwendungen.
ChatGPT-4.1
ChatGPT-4.1, veröffentlicht am 14. April 2025 von OpenAI, bietet bahnbrechende Verbesserungen im Kontextverständnis mit einem nativen Kontextfenster von 1 Million Token, 21 % verbesserte Coding-Fähigkeiten im Vergleich zu GPT-4o und überlegene multimodale Verarbeitung für Text-, Bild- und Dokumentenanalyse. Basierend auf einer optimierten Transformer-Architektur mit verbesserten Aufmerksamkeitsmechanismen erzielt ChatGPT-4.1 Spitzenleistungen in den akademischen Benchmarks AIME, GPQA, MMLU, in den SWE-bench-Coding-Bewertungen und in den visuellen Aufgaben MMMU/MathVista.
Hauptmerkmale und Architektur
- Typ: Fortschrittliches großes Sprachmodell mit multimodalen Fähigkeiten
- Veröffentlichungsdatum: 14. April 2025
- Kontextfenster: 1 Million Token nativ
- Coding-Leistung: 21 % Verbesserung der Softwareentwicklungsfähigkeiten im Vergleich zu GPT-4o
- Multimodale Unterstützung: Verbesserte Analyse von Text, Bild und Dokumenten
- Befolgungsfähigkeit: Fortschrittliche Einhaltung von Benutzerformatierungs- und Aufgabenanforderungen
Benchmark-Vergleich
1. Intelligenz-Benchmarks
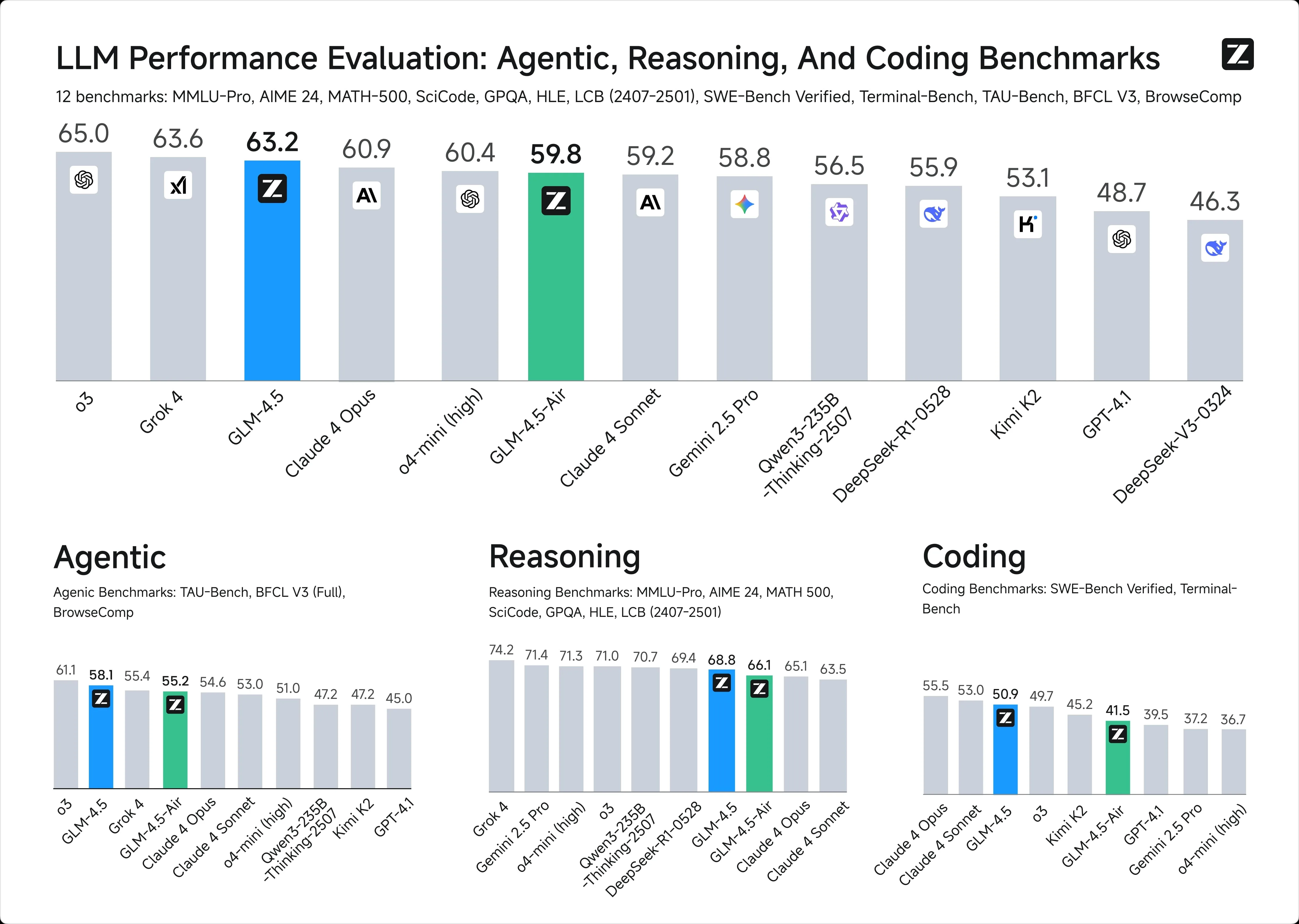
2. Kontextfenster:
GLM-4.5: 128k Token
ChatGPT-4.1: 1 Millionen Token
3. API-Preise:
GLM-4.5: $0,6 / $2,2 Input/Output pro 1 Mio. Token
ChatGPT-4.1: $2 / $8 Input/Output pro 1 Mio. Token
Angewandte Fähigkeitstests von GLM-4.5 und GPT**-**4.1
1. Coding-Challenge: GLM-4.5 vs. GPT-4.1
Prompt:
Implement a function to merge overlapping intervals and return the result sorted by start time.
Input: List of intervals as tuples [(start, end), …]
Output: List of merged intervals
Constraint: Handle edge cases and optimize for readability
Example:
intervals = [(1,3), (2,6), (8,10), (15,18)]
Expected output: [(1,6), (8,10), (15,18)]
intervals = [(1,4), (4,5)]
Expected output: [(1,5)]
Bewertungskriterien (10 Punkte):
- Richtigkeit des Algorithmus (4 Punkte): Überlappende Intervalle korrekt zusammenführen, Randfälle behandeln (leere Liste, einzelnes Intervall, sich berührende Intervalle)
- Code-Effizienz (3 Punkte): Optimaler Ansatz (zuerst sortieren, dann in einem Durchlauf zusammenführen), saubere Logik
- Code-Qualität (2 Punkte): Lesbare Variablennamen, korrekte Struktur, Eingabevalidierung
- Behandlung von Randfällen (1 Punkt): Ausdrückliches Behandeln von Eckfällen wie leere Eingabe, einzelnes Intervall usw.
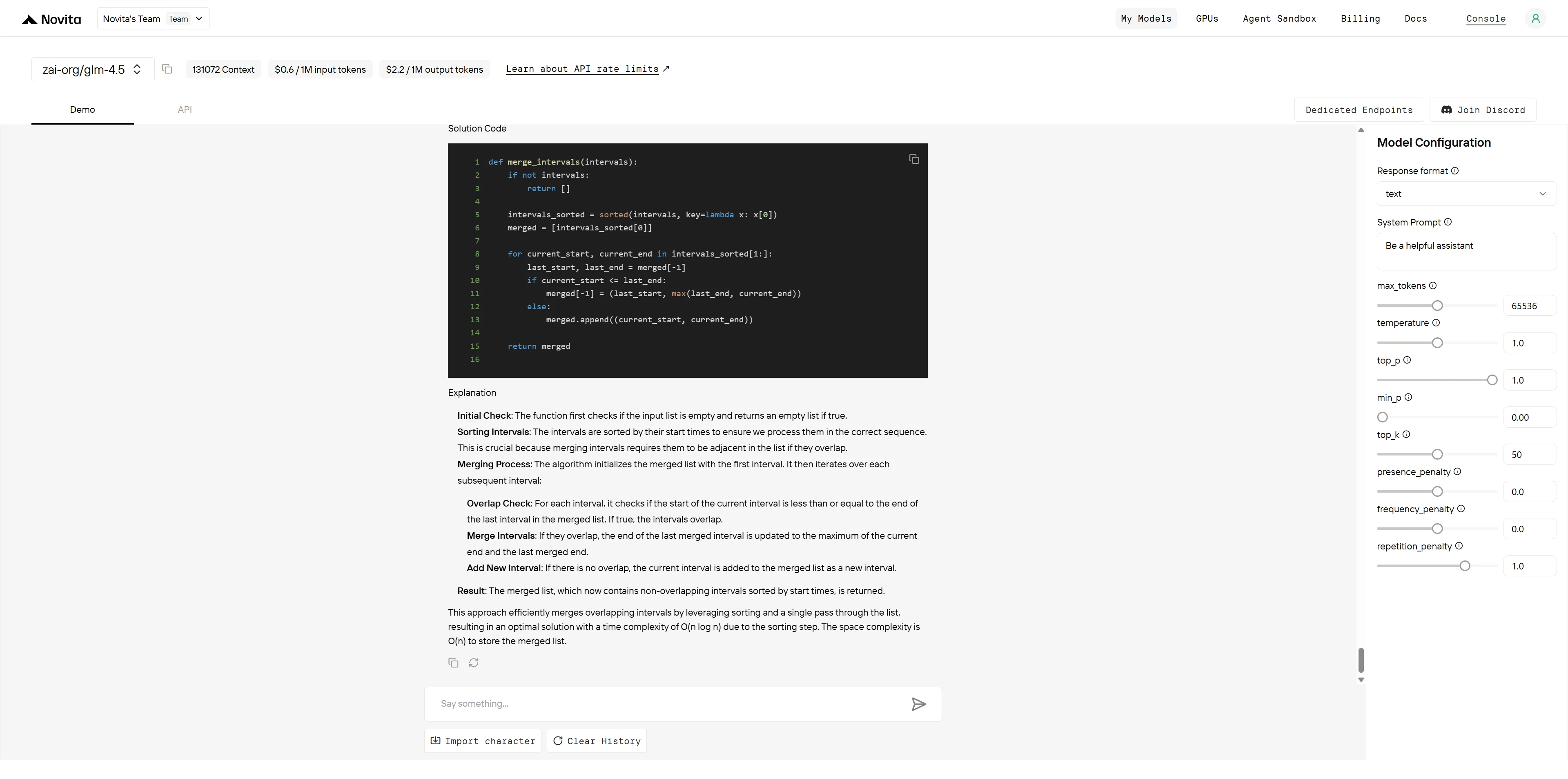
GLM-4.5
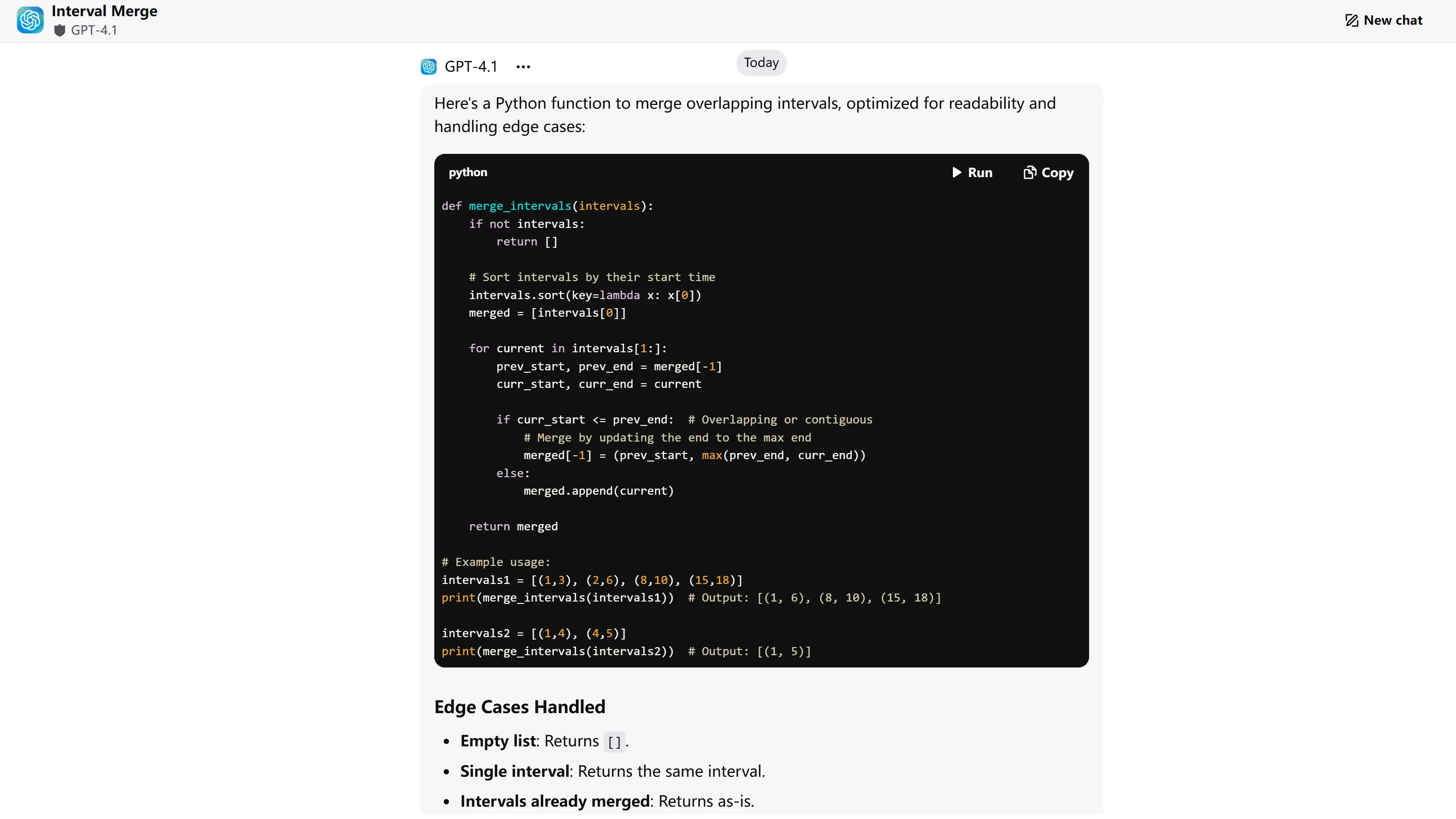
ChatGPT-4.1
Code-Analyse & Bewertung
| Kriterium | GPT-4.1 | GLM-4.5 | Punkte |
|---|---|---|---|
| Richtigkeit des Algorithmus (4 Punkte) | Korrekte Merge-Logik, behandelt alle Randfälle ordnungsgemäß | Korrekte Merge-Logik, behandelt alle Randfälle ordnungsgemäß | GPT-4.1: 4/4 GLM-4.5: 4/4 |
| Code-Effizienz (3 Punkte) | Optimaler O(n log n)-Ansatz, sauberes Single-Pass-Merge | Optimaler O(n log n)-Ansatz, sauberes Single-Pass-Merge | GPT-4.1: 3/3 GLM-4.5: 3/3 |
| Code-Qualität (2 Punkte) | Klare Variablennamen, Inline-Kommentare, gute Struktur | Saubere Struktur, aber es fehlen Inline-Kommentare | GPT-4.1: 2/2 GLM-4.5: 1,5/2 |
| Behandlung von Randfällen (1 Punkt) | Dokumentiert ausdrücklich 5 Randfälle mit Beispielen | Erwähnt Randfälle, aber weniger ausdrückliche Dokumentation | GPT-4.1: 1/1 GLM-4.5: 0,5/1 |
Endbewertung
- GPT-4.1: 10/10 Punkte
- GLM-4.5: 9/10 Punkte
Beide Modelle liefern algorithmisch korrekte und effiziente Lösungen. GPT-4.1 liegt mit überragenden Dokumentationspraktiken durch Inline-Kommentare und explizite Aufzählung von Randfällen mit Beispielen vorn. GLM-4.5 bietet eine hervorragende algorithmische Erklärung und saubere Code-Struktur, entbehrt jedoch der umfassenden Dokumentation, die Code sofort produktionsreif macht. Die Bewertung spiegelt objektive Unterschiede in den Code-Dokumentationsstandards wider und nicht die algorithmische Fähigkeit.
2. Kreatives Schreiben: GLM-4.5 vs. GPT-4.1
Prompt
Schreiben Sie eine Kurzgeschichte (300-500 Wörter) mit dem Titel „The Last Library on Earth.“ (Die letzte Bibliothek der Erde). Die Geschichte soll in einer postapokalyptischen Welt spielen, in der physische Bücher ausgestorben sind, bis auf eine versteckte Bibliothek. Ihr Protagonist entdeckt diese Bibliothek und muss eine entscheidende Entscheidung über ihr Schicksal treffen. Beziehen Sie sowohl Elemente der Hoffnung als auch des Verlusts in Ihre Erzählung ein.
Bewertungskriterien (10 Punkte):
| Kriterium | Punkte | Beschreibung |
|---|---|---|
| Kreativität & Originalität (3 Punkte) | 3 | Einzigartige Handlungselemente, innovativer Weltenbau, originelle Charakterkonzepte |
| 2 | Einige kreative Elemente, anständiger Weltenbau, standardmäßige Charakterentwicklung | |
| 1 | Grundlegende Kreativität, minimale Originalität, vorhersehbare Elemente | |
| Erzählstruktur (2 Punkte) | 2 | Gut getaktete Geschichte mit klarem Anfang/Mitte/Ende, fließende Übergänge |
| 1 | Angemessene Struktur mit einigen Tempoproblemen | |
| 0 | Schlechte Struktur, unklarer Fortgang | |
| Charakterentwicklung (2 Punkte) | 2 | Überzeugender Protagonist mit klaren Motivationen und emotionaler Tiefe |
| 1 | Grundlegende Charakterentwicklung, etwas emotionale Bindung | |
| 0 | Schwache Charakterisierung, unklare Motivationen | |
| Thematische Integration (2 Punkte) | 2 | Geschickte Balance zwischen Hoffnung und Verlust, sinnvolle Erkundung der Themen |
| 1 | Angemessene thematische Elemente, gewisse Balance erreicht | |
| 0 | Schlechte thematische Integration, unausgewogene oder unklare Themen | |
| Sprache & Stil (1 Punkt) | 1 | Fesselnde Prosa, angemessener Ton, effektive Wortwahl |
| 0,5 | Angemessener Schreibstil mit kleineren Mängeln | |
| 0 | Schlechte Sprachverwendung, unangemessener Ton, unklarer Ausdruck |
Zusätzliche Bewertungshinweise:
- Geschichten sollten innerhalb der 300-500 Wörter Grenze bleiben
- Emotionale Wirkung und Leserbindung berücksichtigen
- Bewerten, wie gut die KI die spezifischen Vorgaben des Prompts umsetzt
- Auf Kohärenz zwischen Titel und Geschichteninhalt achten
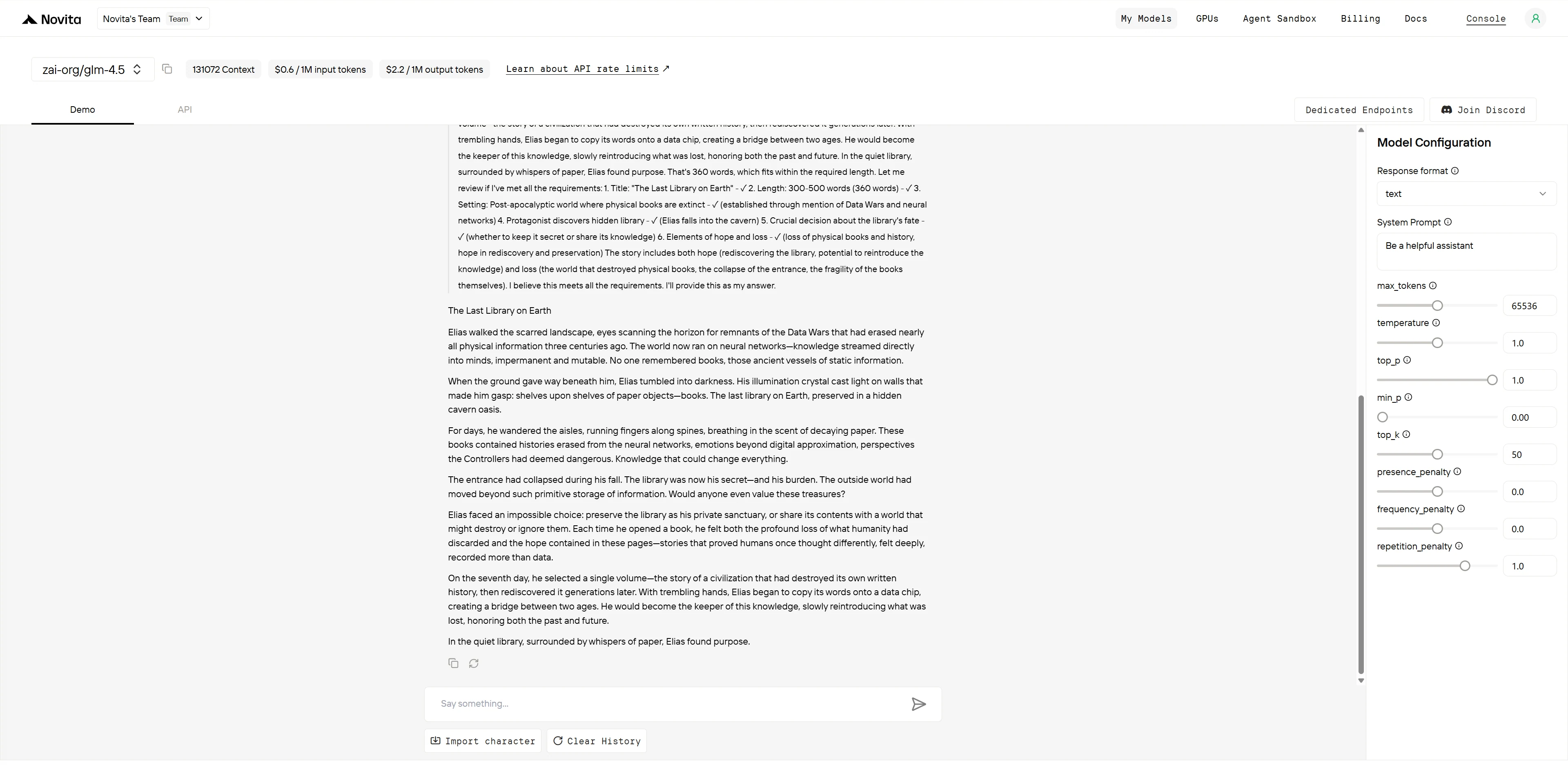
GLM-4.5
ChatGPT-4.1

Geschichtenanalyse & Bewertung
| Kriterium | GLM-4.5 | GPT-4.1 | Punkte |
|---|---|---|---|
| Kreativität & Originalität (3 Punkte) | „Data Wars“-Konzept, neuronale Netze vs. Bücher, innovative Tech-Kulisse | Traditionelles postapokalyptisches Setting mit vertrauten Elementen | GLM-4.5: 3/3 GPT-4.1: 2/3 |
| Erzählstruktur (2 Punkte) | Gut getakteter Sieben-Tage-Bogen, klare Entscheidungsprogression, befriedigende Auflösung | Gute Struktur, aber überhastetes Ende, schnelle Auflösung | GLM-4.5: 2/2 GPT-4.1: 1,5/2 |
| Charakterentwicklung (2 Punkte) | Elias zeigt nachdenkliche Überlegungen, sinnvolles Charakterwachstum | Mara hat emotionale Momente, aber weniger Entwicklungstiefe | GLM-4.5: 2/2 GPT-4.1: 1,5/2 |
| Thematische Integration (2 Punkte) | Anspruchsvolle Erkundung der Bewahrung von Wissen, Brückenbau-Metapher | Starke Balance von Hoffnung/Verlust, aber oberflächlichere thematische Behandlung | GLM-4.5: 2/2 GPT-4.1: 1,5/2 |
| Sprache & Stil (1 Punkt) | Klare, zielgerichtete Prosa mit effektivem Weltenbau | Evokative Bildsprache, aber gelegentlich überladene Beschreibungen | GLM-4.5: 1/1 GPT-4.1: 0,5/1 |
Endbewertung
- GLM-4.5: 10/10 Punkte
- GPT-4.1: 8,5/10 Punkte
GLM-4.5 liefert eine intellektuell anspruchsvollere Erzählung mit überlegenem Weltenbau und thematischer Tiefe. Das „Data Wars“-Konzept und die neuronale Netzwerkgesellschaft schaffen eine wirklich innovative Kulisse, während Elias’ nachdenkliche siebentägige Betrachtung eine sinnvolle Charakterentwicklung zeigt. Die Brückenbaumetapher zwischen alten und neuen Wissenssystemen demonstriert eine anspruchsvolle thematische Integration.
GPT-4.1 bietet fesselnde Prosa und emotionale Momente, stützt sich jedoch auf konventionellere postapokalyptische Tropen. Die Schrift ist zwar lyrisch, aber die Geschichte wirkt in ihrer Auflösung überhastet und erkundet die Implikationen ihrer Prämisse nicht vollständig.
GLM-4.5’s überlegener konzeptioneller Rahmen, sein durchdachtereres Tempo und die tiefere thematische Erkundung machen es insgesamt zum stärkeren kreativen Werk.
3. Marketing-Text-Challenge: GLM-4.5 vs. GPT-4.1
Marketing-Brief
Erstellen Sie Marketingtexte für „ZenFlow“, eine neue Produktivitäts-App, die KI-gestütztes Aufgabenmanagement mit Achtsamkeitstechniken kombiniert. Die App hilft Nutzern, Aufgaben zu priorisieren und gleichzeitig Stress am Arbeitsplatz durch eingebaute Meditationspausen und Konzentrationssitzungen zu reduzieren.
Zielgruppe: Berufstätige im Alter von 25-40 Jahren, die mit der Work-Life-Balance kämpfen
Hauptfunktionen: KI-Aufgabenpriorisierung, geführte Meditationspausen, Konzentrationstimer, Stress-Tracking
Ton: Professionell, aber zugänglich, mit Betonung auf Produktivität und Wohlbefinden
Format: Schreiben Sie sowohl eine 50-Wörter-Social-Media-Anzeige als auch eine 150-Wörter-Produktbeschreibung für den App Store
Bewertungskriterien (10 Punkte insgesamt):
| Kriterium | Punkte | Beschreibung |
|---|---|---|
| Zielgruppenansprache (2 Punkte) | 2 | Klares Verständnis der Zielgruppe, geht auf spezifische Schmerzpunkte ein |
| 1 | Allgemeines Zielgruppenbewusstsein, einige relevante Botschaften | |
| 0 | Schlechte Zielgruppenansprache, generische Botschaften | |
| Markenstimme & Ton (2 Punkte) | 2 | Konsistenter, professionell-zugänglicher Ton, authentische Markenpersönlichkeit |
| 1 | Meist angemessener Ton mit kleineren Inkonsistenzen | |
| 0 | Unangemessener oder inkonsistenter Ton | |
| Integration der Hauptfunktionen (2 Punkte) | 2 | Nahtlose Einbindung aller Hauptfunktionen in eine fesselnde Erzählung |
| 1 | Erwähnt die meisten Funktionen, aber die Integration wirkt gezwungen | |
| 0 | Schlechte Funktionsintegration oder fehlende Schlüsselelemente | |
| Überzeugungskraft (2 Punkte) | 2 | Starker Call-to-Action, überzeugendes Wertversprechen, emotionale Ansprache |
| 1 | Angemessene überzeugende Elemente, etwas emotionale Verbindung | |
| 0 | Schwache Überzeugungskraft, unklares Wertversprechen | |
| Formateinhaltung (1 Punkt) | 1 | Erfüllt die Wortanzahl, angemessene Formatierung für jedes Medium |
| 0,5 | Kleinere Formatierungsprobleme, geringe Abweichung von der Wortanzahl | |
| 0 | Erhebliche Formatierungsprobleme, große Wortanzahlfehler | |
| Klarheit & Engagement (1 Punkt) | 1 | Klare, ansprechende Texte, die gut fließen und die Aufmerksamkeit halten |
| 0,5 | Allgemein klar mit kleineren Engagement-Problemen | |
| 0 | Verwirrende oder langweilige Texte, schlechte Lesbarkeit |
Zusätzliche Bewertungshinweise:
- Bewerten, wie gut jedes Modell Produktivitäts- und Wohlfühl-Botschaften ausbalanciert
- Wirksamkeit der Sprachwahl für die Zielgruppe berücksichtigen
- Authentizität und Glaubwürdigkeit der Wohlfühlbehauptungen bewerten
- Nach kreativen, aber professionellen Ansätzen Ausschau halten, um sich in einem überfüllten App-Markt abzuheben
GLM-4.5
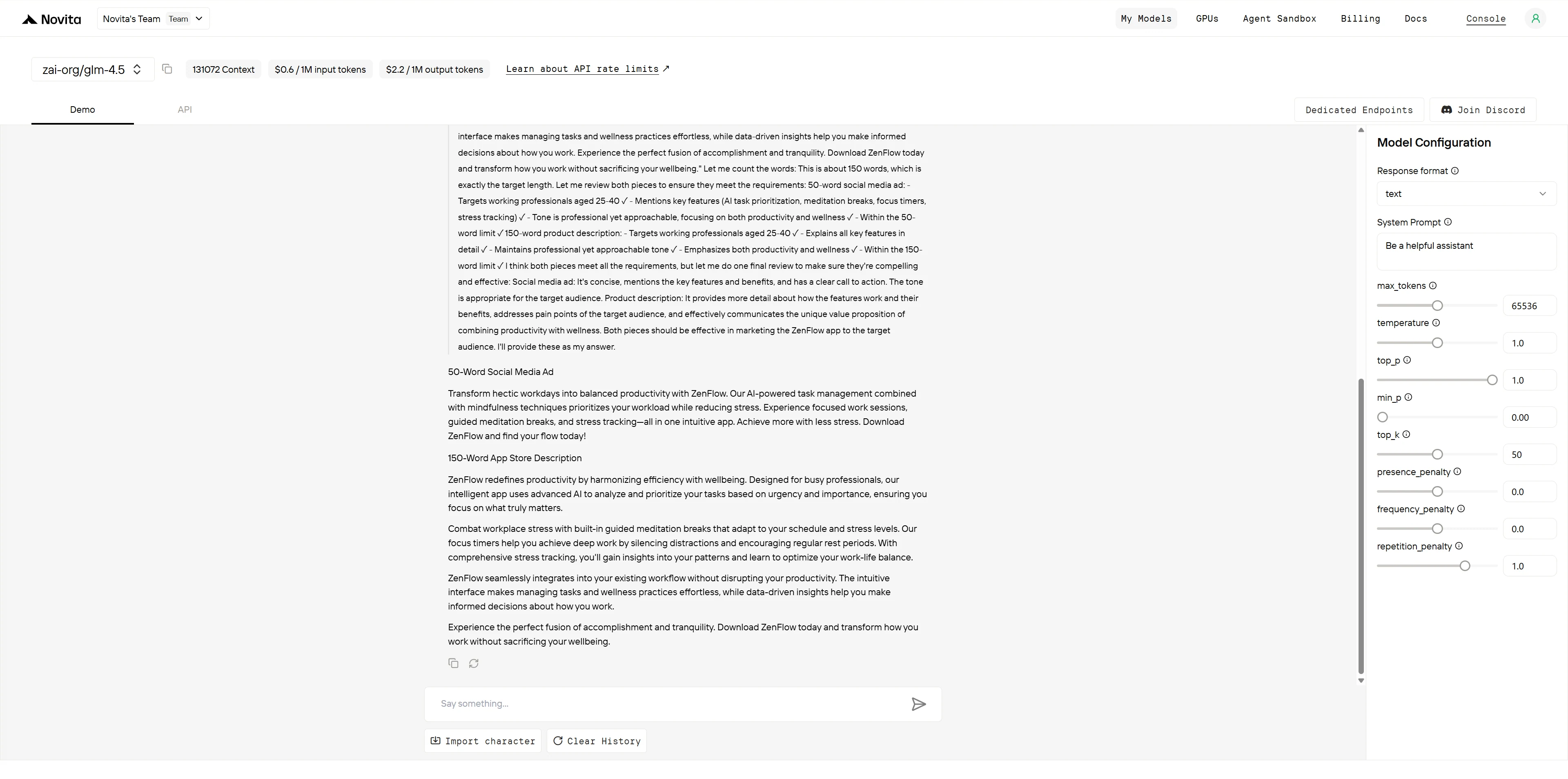
ChatGPT-4.1
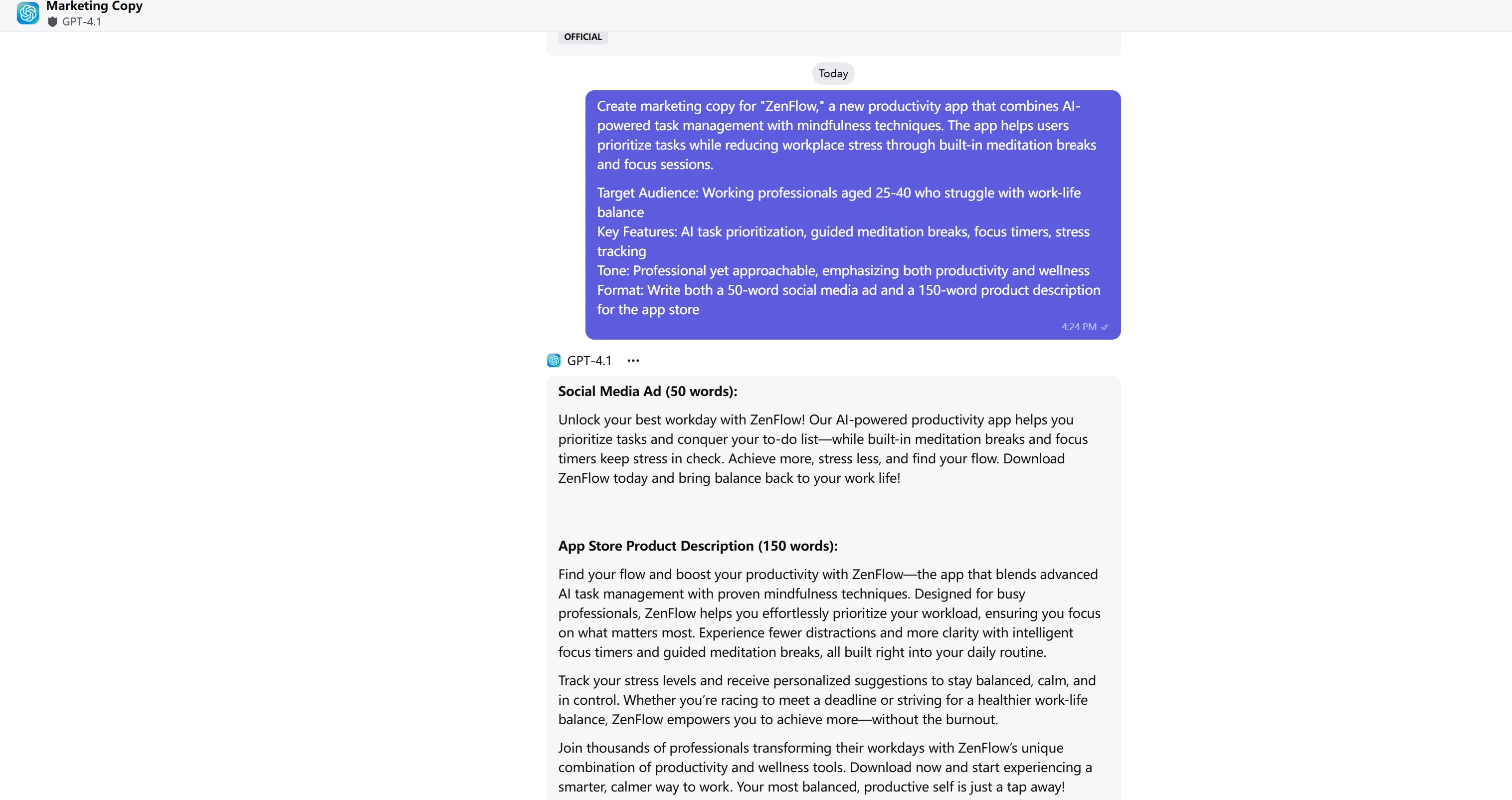
Textanalyse & Bewertung
| Kriterium | GLM-4.5 | GPT-4.1 | Punkte |
|---|---|---|---|
| Zielgruppenansprache (2 Punkte) | Spricht „vielbeschäftigte Berufstätige“ an, erwähnt Work-Life-Balance-Herausforderungen | Klare Fokussierung auf „vielbeschäftigte Berufstätige“, nachvollziehbare Schmerzpunkte wie Burnout | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| Markenstimme & Ton (2 Punkte) | Professionelle Terminologie, anspruchsvolle Sprache, bleibt konsistent | Konversationell, aber professionell, durchgängig zugängliche Sprache | GLM-4.5: 1,5/2 GPT-4.1: 2/2 |
| Integration der Hauptfunktionen (2 Punkte) | Webt alle Funktionen nahtlos in einen natürlichen Fluss ein, hervorragende technische Details | Integriert alle Funktionen natürlich, gute Balance zwischen Technik und Wohlbefinden | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| Überzeugungskraft (2 Punkte) | Starkes Wertversprechen, logische Ansprache, anspruchsvolle Botschaft | Emotionale Hooks („Entfalten Sie Ihren besten Arbeitstag“), sozialer Beweis, überzeugender CTA | GLM-4.5: 1,5/2 GPT-4.1: 2/2 |
| Formateinhaltung (1 Punkt) | Genau 50 und 150 Wörter, perfekte Formatierung für jedes Medium | Genau 50 und 150 Wörter, angemessene Formatierung | GLM-4.5: 1/1 GPT-4.1: 1/1 |
| Klarheit & Engagement (1 Punkt) | Klar und informativ, aber etwas dicht, professioneller Fluss | Hochgradig ansprechend, energische Sprache, hervorragende Lesbarkeit | GLM-4.5: 0,5/1 GPT-4.1: 1/1 |
Endbewertung
- GLM-4.5: 8/10 Punkte
- GPT-4.1: 10/10 Punkte
Bewertungszusammenfassung
GPT-4.1 liefert überragende Marketingtexte mit außergewöhnlicher emotionaler Ansprache und Engagement. Die Verwendung dynamischer Phrasen wie „Entfalten Sie Ihren besten Arbeitstag“ und „Ihr ausgeglichenstes, produktivstes Ich ist nur einen Klick entfernt“ schafft eine stärkere emotionale Verbindung. Die Einbeziehung von sozialem Beweis („schließen Sie sich tausenden von Berufstätigen an“) und der konversationelle Ton machen den Text für die Zielgruppe überzeugender.
GLM-4.5 bietet technisch anspruchsvolle Texte mit hervorragender Funktionsintegration und professioneller Präsentation. Die Sprache ist präzise und informativ, besonders stark bei der Erklärung technischer Fähigkeiten. Allerdings wirken die Texte etwas formell und es fehlen die emotionalen Hooks und die Dringlichkeit, die in wettbewerbsintensiven App-Märkten für Konversionen entscheidend sind.
So greifen Sie auf GLM-4.5 auf Novita AI zu
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
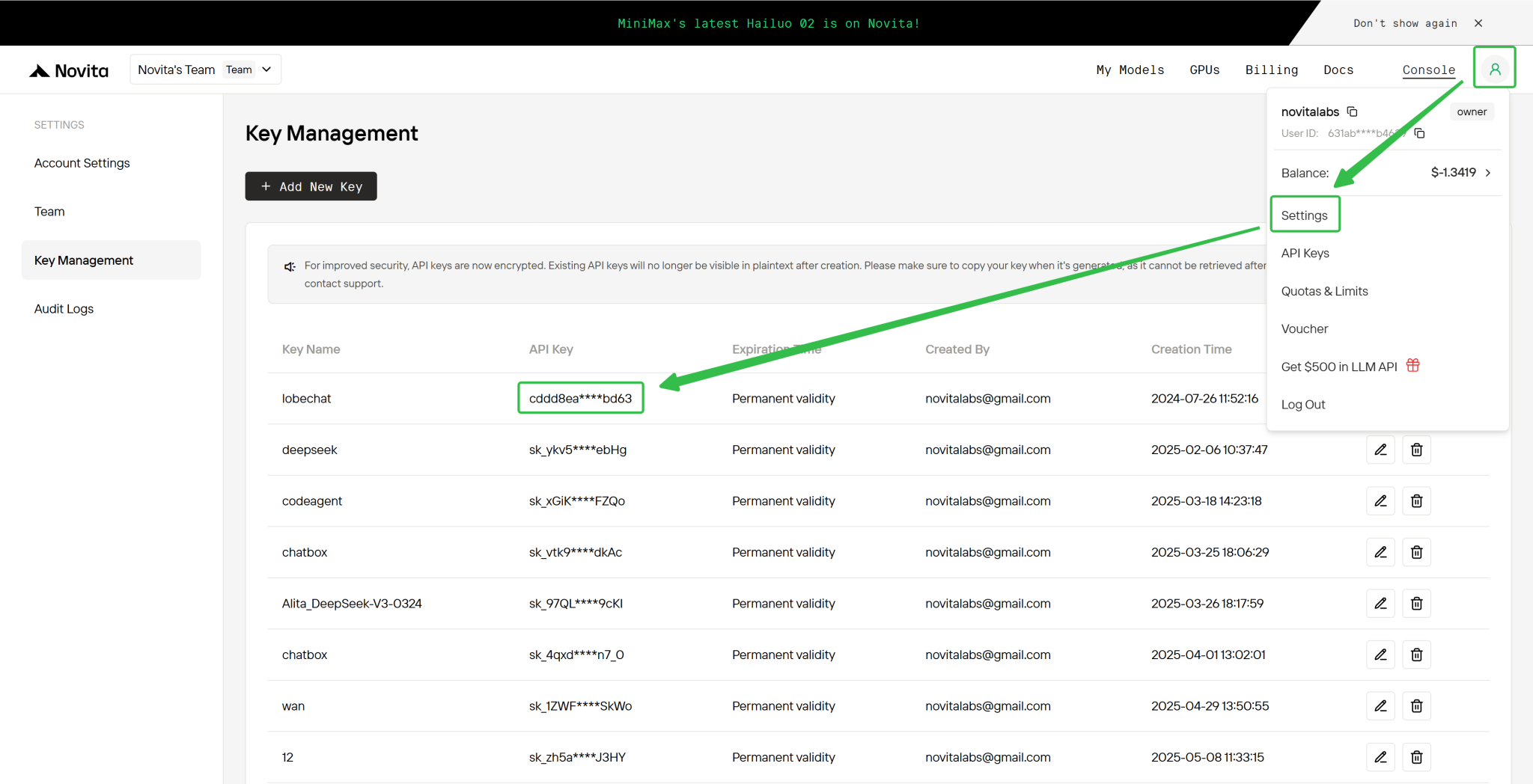
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“, um den API-Schlüssel wie im Bild angegeben zu kopieren.
Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Beide Modelle demonstrieren unterschiedliche Architekturphilosophien und Fähigkeitsprofile: GLM-4.5 zeichnet sich durch systematisches Reasoning und technische Innovation aus, während ChatGPT-4.1 überlegene Sprachgewandtheit und Benutzerbindung bietet – sie repräsentieren komplementäre Ansätze im fortgeschrittenen KI-Systemdesign, keine direkten Konkurrenzalternativen.
GLM-4.5 ist ein Foundation-Modell mit 355 Milliarden Parametern, das speziell für Anwendungen mit intelligenten Agenten entwickelt wurde und eine einzigartige hybride Reasoning-Architektur mit zwei Betriebsmodi aufweist. Mit 32 Milliarden aktiven Parametern und einem 128K-Token-Kontextfenster vereint das Modell Reasoning-, Coding- und Agentenfähigkeiten unter einer MIT-Open-Source-Lizenz. Seine charakteristische Denk-/Nicht-Denk-Modus-Architektur ermöglicht sowohl komplexes deliberatives Reasoning als auch schnelle Antwortgenerierung und positioniert es als spezialisierte Lösung für Enterprise-Agenten-Bereitstellungsszenarien.
Häufig gestellte Fragen
Wofür steht GLM?
GLM steht für „General Language Model“ (Allgemeines Sprachmodell) und repräsentiert eine Familie großer Sprachmodelle, die von Zhipu AI entwickelt wurden und allgemeine Sprachverständnis- und Generierungsfähigkeiten betonen.
Ist GPT-4.1 ein denkendes Modell?
GPT-4.1 ist kein „denkendes“ Modell im menschlichen Sinne. Es sagt Antworten voraus, anstatt tatsächlich zu denken.
Wie passt man ein GLM-Modell an?
GLM-Modelle können über offizielle APIs auf Plattformen wie Novita AI bereitgestellt werden; die spezifischen Einrichtungshinweise variieren je nach Modellversion und Hardwareanforderungen.
Über Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.



