

主なハイライト
GLM-4.5 : 推論、コーディング、インテリジェントエージェント機能を統一し、インテリジェントエージェントアプリケーションの複雑な要求に応える基盤モデル。
ChatGPT-4.1: 高度な推論能力を備えたマルチモーダル基盤モデル。多様なドメインやアプリケーションにおいて、汎用的な問題解決と人間らしい会話に最適化。
Novita AI は安定した API サービスを提供するだけでなく、非常にコストパフォーマンスの高い料金設定も実現しています。例えば、 GLM-4.5 は入力 100 万トークンあたり $0.6、出力 100 万トークンあたり $2.2 です。
モデルの基本紹介
GLM-4.5
GLM-4.5 は、合計 3550 億パラメータ、アクティブパラメータ 320 億のインテリジェントエージェント向けに設計された基盤モデルです。このモデルは、推論、コーディング、インテリジェントエージェント機能を統合し、インテリジェントエージェントアプリケーションの複雑な要求に応えます。GLM-4.5 はハイブリッド推論モデルであり、複雑な推論やツール使用のための思考モードと、即時応答のための非思考モードの 2 つのモードを提供します。
主な機能とアーキテクチャ
- パラメータ: 合計 3550 億パラメータ、アクティブパラメータ 320 億。
- ハイブリッド推論: 2 つの動作モード — 複雑な推論とツール使用のための思考モード、および即時応答のための非思考モード。
- モデルバージョン: ベースモデル、ハイブリッド推論モデル、FP8 バージョンが利用可能。
- コンテキストウィンドウ: 128K トークン。
- ライセンス: 商用利用および二次開発のための MIT オープンソースライセンス。
- 機能: 複雑なアプリケーション向けに、推論、コーディング、インテリジェントエージェント機能を統合。
ChatGPT-4.1
ChatGPT-4.1 は、OpenAI によって 2025 年 4 月 14 日にリリースされました。ネイティブの 100 万トークンコンテキストウィンドウによるコンテキスト理解の画期的な改善、GPT-4o 比 21% 向上したコーディング能力、テキスト・画像・文書分析のための優れたマルチモーダル処理を特徴とします。最適化されたトランスフォーマーアーキテクチャと強化されたアテンション機構に基づき、ChatGPT-4.1 は AIME、GPQA、MMLU 学術ベンチマーク、SWE-bench コーディング評価、MMMU/MathVista 視覚タスクで最先端のパフォーマンスを達成しています。
主な機能とアーキテクチャ
- タイプ: マルチモーダル機能を備えた高度な大規模言語モデル
- リリース日: 2025 年 4 月 14 日
- コンテキストウィンドウ: ネイティブ 100 万トークン
- コーディングパフォーマンス: GPT-4o 比 21% 改善されたソフトウェアエンジニアリング能力
- マルチモーダル対応: テキスト、画像、文書分析機能の強化
- 指示追従: ユーザーのフォーマットやタスク要件への高度な準拠
ベンチマーク比較
1. インテリジェンスベンチマーク
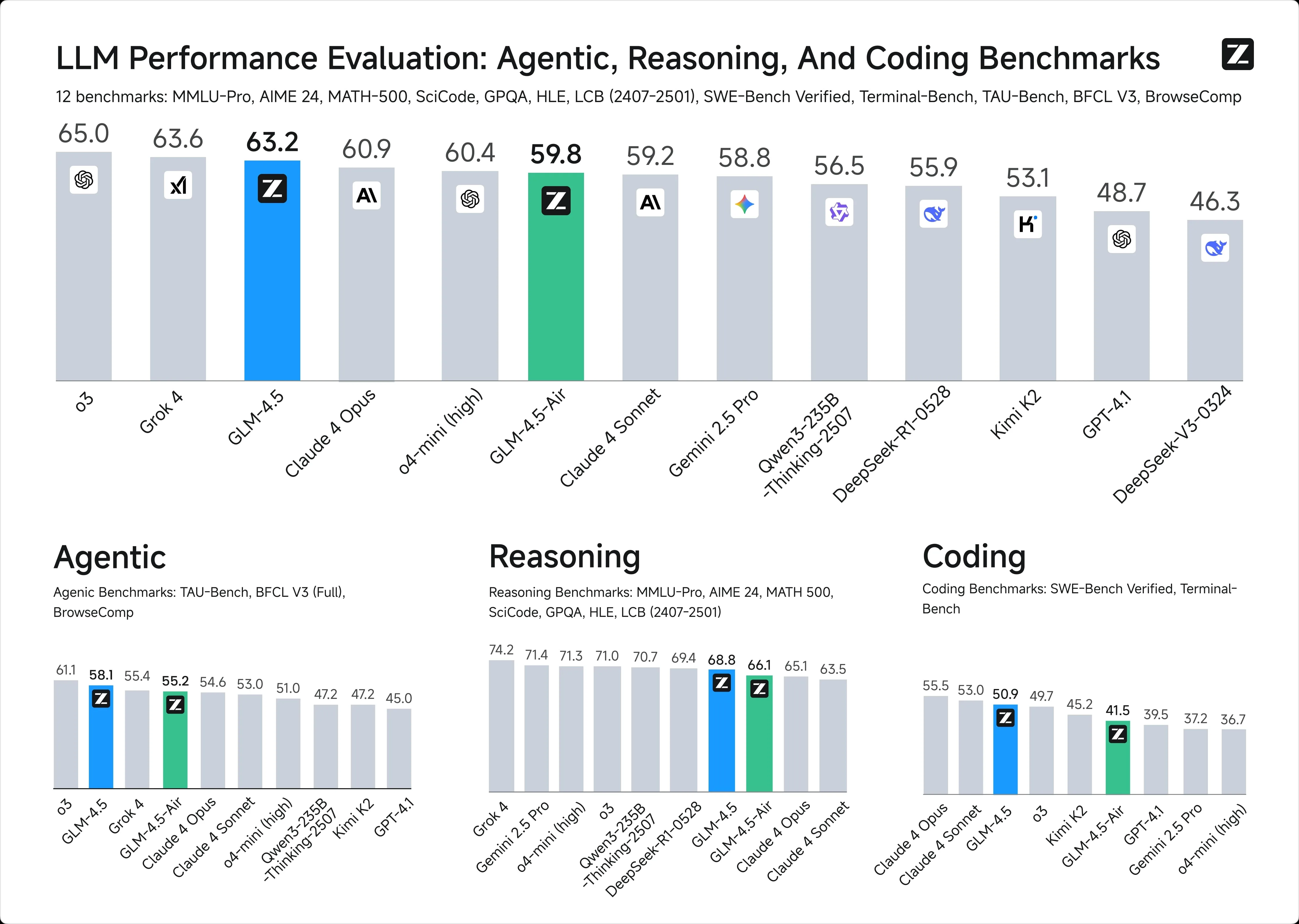
2. コンテキストウィンドウ:
GLM-4.5: 128k トークン
ChatGPT-4.1: 100 万トークン
3. API 料金:
GLM-4.5: $0.6 / $2.2(入出力、100 万トークンあたり)
ChatGPT-4.1: $2 / $8(入出力、100 万トークンあたり)
GLM-4.5 と GPT**-**4.1 の応用スキルテスト
1. コーディングチャレンジ: GLM-4.5 vs GPT-4.1
プロンプト:
重複する区間をマージし、開始時間でソートされた結果を返す関数を実装してください。
入力: タプルのリスト [(開始, 終了), ...]
出力: マージされた区間のリスト
制約: エッジケースを処理し、可読性を最適化すること
例:
intervals = [(1,3), (2,6), (8,10), (15,18)]
期待される出力: [(1,6), (8,10), (15,18)]
intervals = [(1,4), (4,5)]
期待される出力: [(1,5)]
評価基準 (10 点):
- アルゴリズムの正確性 (4 点): 重複区間を正しくマージし、エッジケース(空リスト、単一区間、接する区間)を処理する
- コード効率 (3 点): 最適なアプローチ(まずソートし、1 パスでマージ)、クリーンなロジック
- コード品質 (2 点): 読みやすい変数名、適切な構造、入力バリデーションの処理
- エッジケース処理 (1 点): 空の入力、単一区間などのコーナーケースを明示的に処理
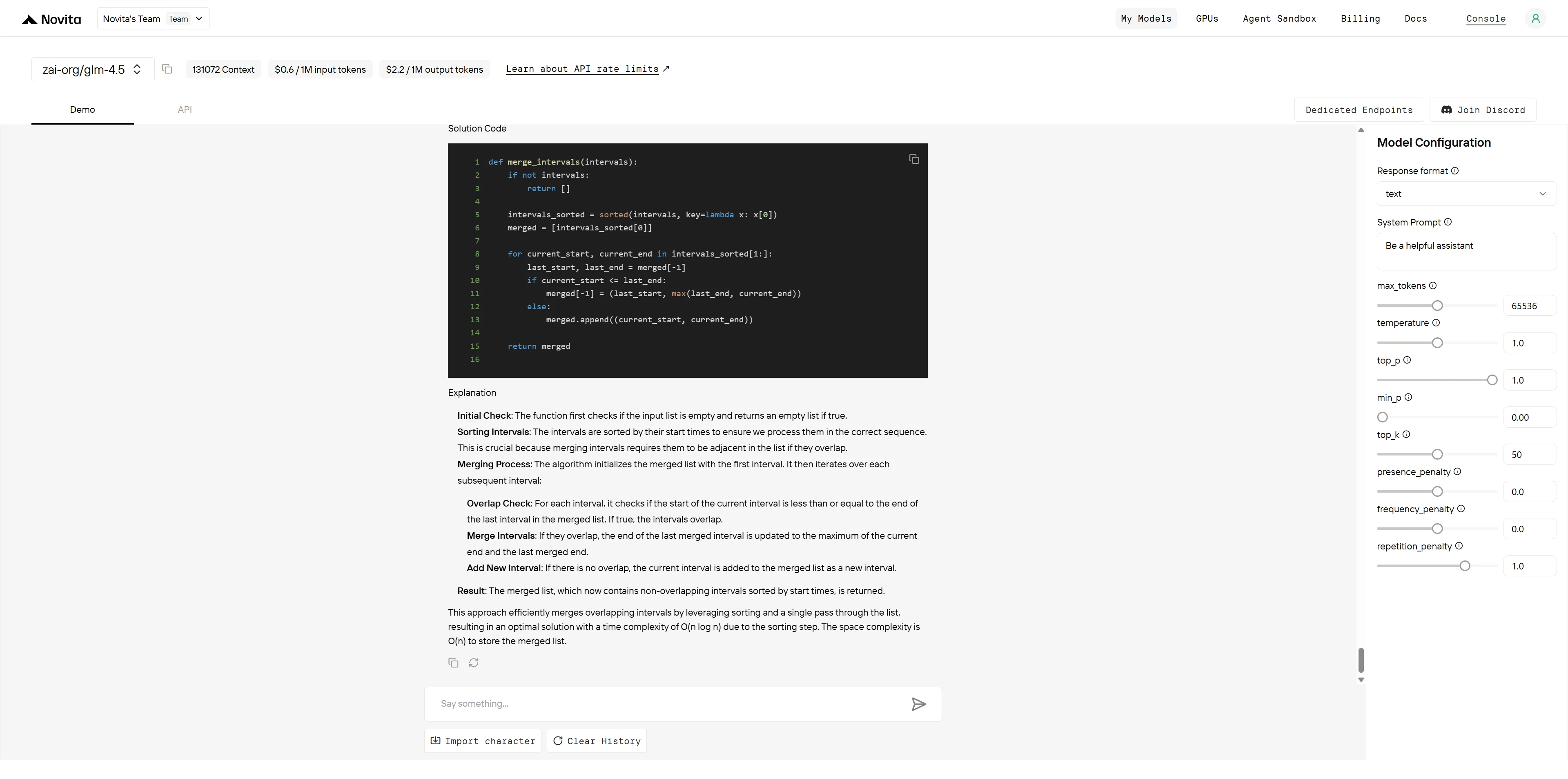
GLM-4.5
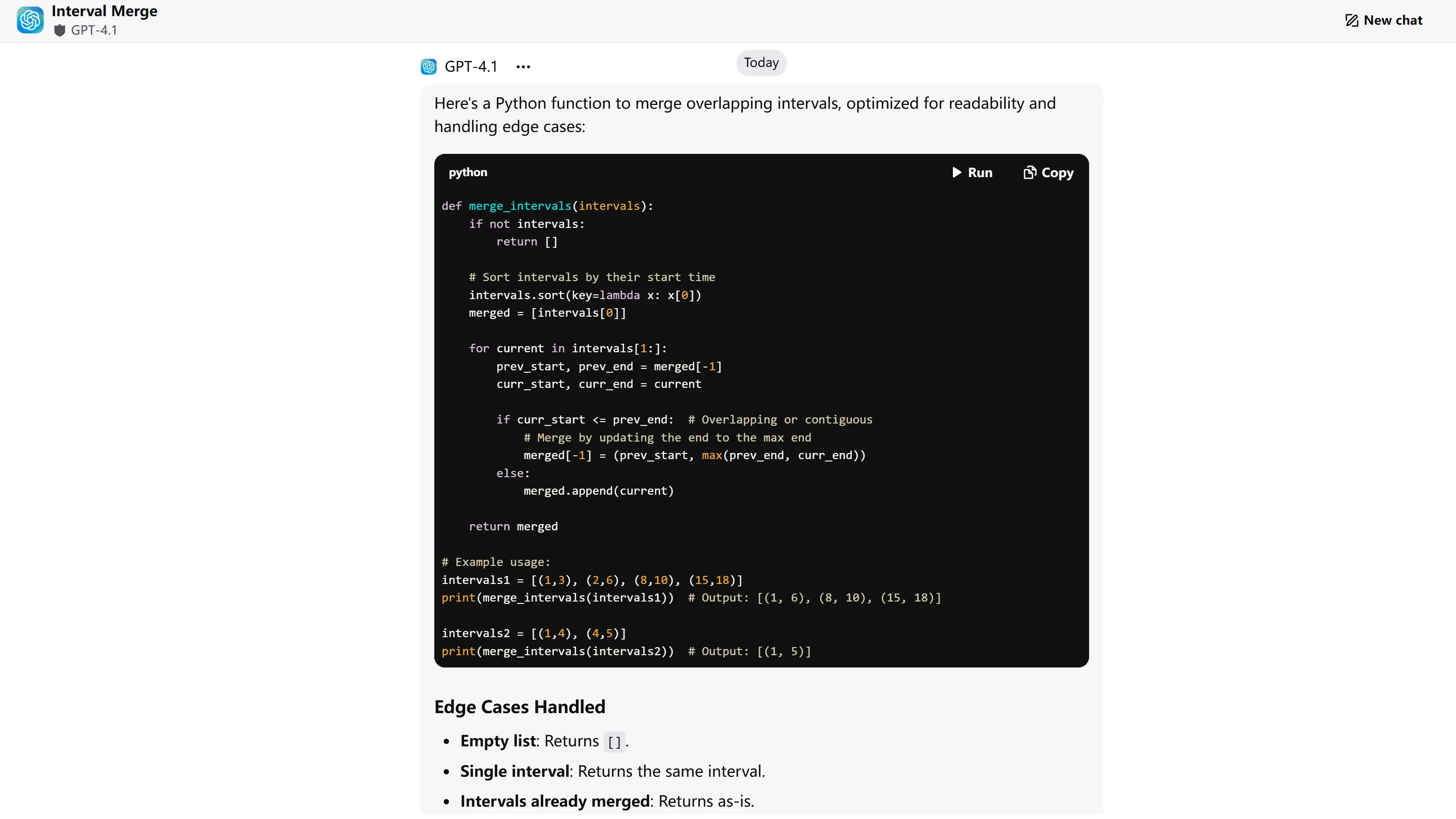
ChatGPT-4.1
コード分析とスコアリング
| **基準 ** | GPT-4.1 | GLM-4.5 | ** スコア** |
|---|---|---|---|
| アルゴリズムの正確性 (4 点) | マージロジックが正しく、すべてのエッジケースを適切に処理 | マージロジックが正しく、すべてのエッジケースを適切に処理 | GPT-4.1: 4/4 GLM-4.5: 4/4 |
| コード効率 (3 点) | 最適な O(n log n) アプローチ、クリーンな単一パスマージ | 最適な O(n log n) アプローチ、クリーンな単一パスマージ | GPT-4.1: 3/3 GLM-4.5: 3/3 |
| コード品質 (2 点) | 明確な変数名、インラインコメント、良い構造 | クリーンな構造だがインラインコメントがない | GPT-4.1: 2/2 GLM-4.5: 1.5/2 |
| エッジケース処理 (1 点) | 5 つのエッジケースを例付きで明示的に文書化 | エッジケースに言及しているが、文書化が不十分 | GPT-4.1: 1/1 GLM-4.5: 0.5/1 |
最終スコア
- GPT-4.1: 10/10 点
- GLM-4.5: 9/10 点
両モデルともアルゴリズム的に正しく効率的なソリューションを提供します。GPT-4.1 はインラインコメントと例を用いた明示的なエッジケース列挙により、優れたドキュメント慣行でリードしています。GLM-4.5 は優れたアルゴリズム説明とクリーンなコード構造を提供しますが、コードをすぐに本番環境で使用可能にする包括的なドキュメントが不足しています。スコアリングは、アルゴリズム能力ではなく、コードドキュメント基準の客観的な違いを反映しています。
2. クリエイティブライティングチャレンジ: GLM-4.5 vs GPT-4.1
プロンプト
タイトル「地球最後の図書館」の短編小説(300~500語)を書いてください。物語は、物理的な本が絶滅し、唯一つの隠された図書館だけが残っている終末後の世界を舞台にしてください。主人公はこの図書館を発見し、その運命について重要な決断を下さなければなりません。物語には希望と喪失の両方の要素を含めてください。
評価基準 (10 点):
| **基準 ** | ** 点数 ** | ** 説明** |
|---|---|---|
| 創造性と独創性 (3 点) | 3 | 独自のプロット要素、革新的な世界構築、独創的なキャラクターコンセプト |
| 2 | いくつかの創造的要素、妥当な世界構築、標準的なキャラクター開発 | |
| 1 | 基本的な創造性、最小限の独創性、予測可能な要素 | |
| 物語構造 (2 点) | 2 | 明確な始まり/中間/終わりを持つ適切なペース、スムーズな遷移 |
| 1 | 適切な構造だがペースに問題あり | |
| 0 | 構造が悪く、進行が不明瞭 | |
| キャラクター開発 (2 点) | 2 | 明確な動機と感情の深みを持つ魅力的な主人公 |
| 1 | 基本的なキャラクター開発、ある程度の感情的なつながり | |
| 0 | 弱いキャラクター描写、不明瞭な動機 | |
| テーマの統合 (2 点) | 2 | 希望と喪失を巧みにバランスさせ、テーマを有意義に探求 |
| 1 | 適切なテーマ要素、ある程度のバランス達成 | |
| 0 | テーマの統合が不十分、バランスが取れていない、またはテーマが不明瞭 | |
| 言語とスタイル (1 点) | 1 | 魅力的な散文、適切なトーン、効果的な語彙選択 |
| 0.5 | 適切な文体だが軽微な問題あり | |
| 0 | 言語使用が不十分、不適切なトーン、不明瞭な表現 |
追加評価ノート:
- 物語は 300~500 語の制限内に収めること
- 感情的なインパクトと読者の関与を考慮
- AI がプロンプトの特定の制約をどの程度うまく処理しているかを評価
- タイトルと物語内容の一貫性を確認
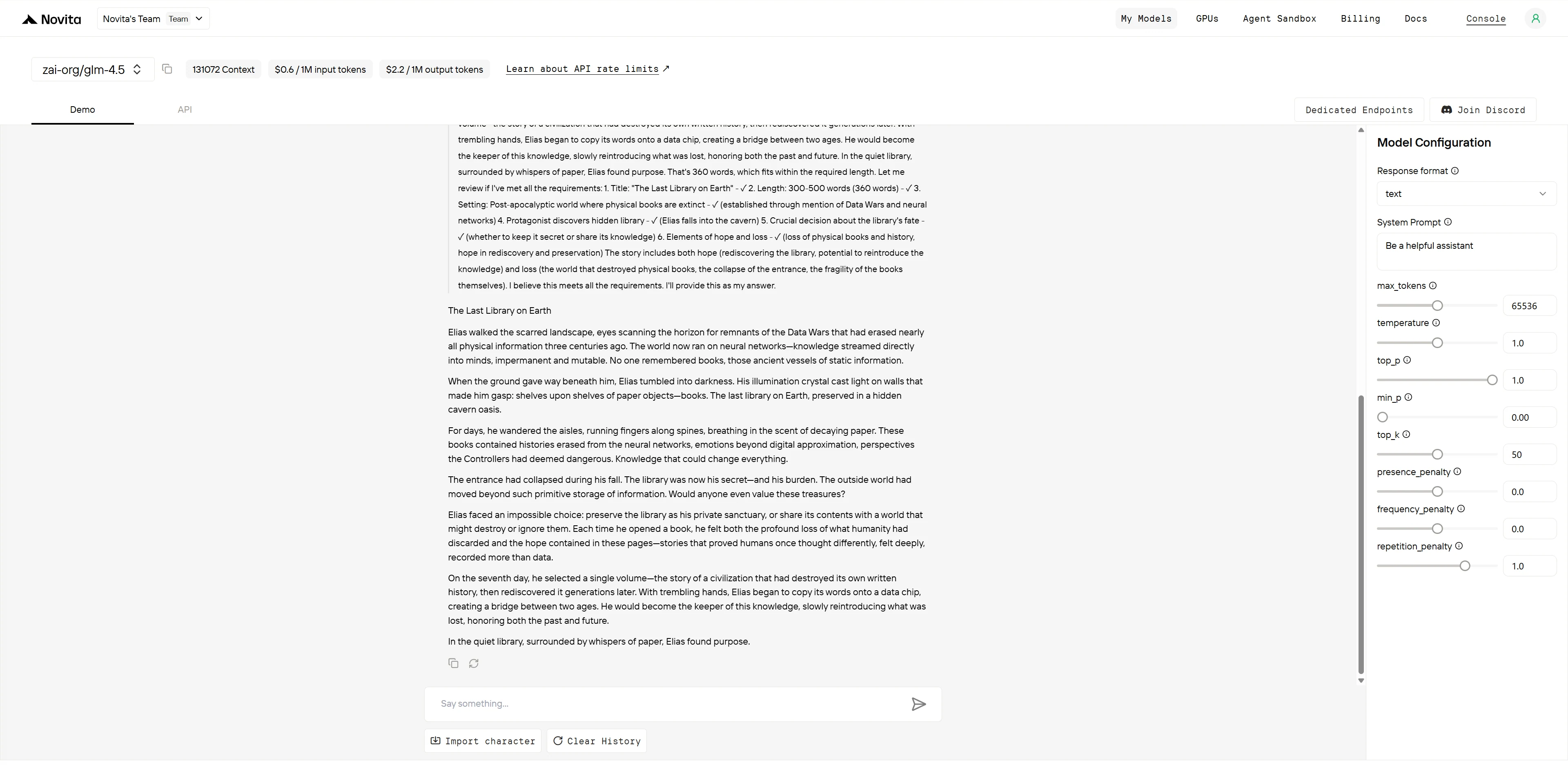
GLM-4.5
ChatGPT-4.1

物語分析とスコアリング
| **基準 ** | GLM-4.5 | GPT-4.1 | ** スコア** |
|---|---|---|---|
| 創造性と独創性 (3 点) | 「データ戦争」のコンセプト、ニューラルネットワーク対書籍、革新的なテクノロジーバックグラウンド | 従来の終末後の設定とおなじみの要素 | GLM-4.5: 3/3 GPT-4.1: 2/3 |
| 物語構造 (2 点) | 適切なペースの 7 日間の弧、明確な決断の進行、満足のいく解決 | 良い構造だが結末が急ぎ、解決が早い | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| キャラクター開発 (2 点) | エリアスは思慮深い熟考を示し、意味のあるキャラクター成長 | マーラは感情的な瞬間があるが、発展の深さが劣る | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| テーマの統合 (2 点) | 知識保存の洗練された探求、橋渡しの比喩 | 希望/喪失のバランスは強いが、テーマ処理はより表面的 | GLM-4.5: 2/2 GPT-4.1: 1.5/2 |
| 言語とスタイル (1 点) | 明確で目的のある散文、効果的な世界構築 | 喚起的なイメージだが、時折過剰な描写 | GLM-4.5: 1/1 GPT-4.1: 0.5/1 |
最終スコア
- GLM-4.5: 10/10 点
- GPT-4.1: 8.5/10 点
GLM-4.5 は、優れた世界構築とテーマの深みにより、知的により洗練された物語を提供します。「データ戦争」のコンセプトとニューラルネットワーク社会は真に革新的な背景を創り出し、エリアスの思慮深い 7 日間の熟考は意味のあるキャラクター成長を示しています。新旧の知識体系の間の橋渡しの比喩は、洗練されたテーマ統合を実証しています。
GPT-4.1 は魅力的な散文と感情的な瞬間を提供しますが、より従来型の終末後のトロープに依存しています。文章は詩的ですが、物語は解決に向けて急ぎ気味で、前提の含意を完全には探求していません。
GLM-4.5 の優れた概念的枠組み、より意図的なペース、そしてより深いテーマ探求が、総合的に優れた創作作品となっています。
3. マーケティングコピーチャレンジ: GLM-4.5 vs GPT-4.1
マーケティング概要
AI 搭載タスク管理とマインドフルネス技術を組み合わせた新しい生産性アプリ「ZenFlow」のマーケティングコピーを作成してください。このアプリは、内蔵の瞑想休憩と集中セッションを通じて、ユーザーがタスクを優先しながら職場のストレスを軽減するのに役立ちます。
ターゲットオーディエンス: ワークライフバランスに悩む 25~40 歳の働くプロフェッショナル 主な機能: AI タスク優先順位付け、ガイド付き瞑想休憩、集中タイマー、ストレス追跡 トーン: プロフェッショナルでありながら親しみやすく、生産性とウェルネスの両方を強調 形式: 50 語のソーシャルメディア広告と、アプリストア向けの 150 語の製品説明文の両方を書いてください。
評価基準 (10 点満点):
| **基準 ** | ** 点数 ** | ** 説明** |
|---|---|---|
| オーディエンスターゲティング (2 点) | 2 | ターゲット層を明確に理解し、具体的なペインポイントに対応 |
| 1 | 一般的なオーディエンス認識、いくつかの関連メッセージ | |
| 0 | オーディエンスターゲティングが不十分、一般的なメッセージ | |
| ブランドボイスとトーン (2 点) | 2 | 一貫したプロフェッショナルでありながら親しみやすいトーン、真のブランドパーソナリティ |
| 1 | ほとんどの場合適切なトーンだが、軽微な不一致あり | |
| 0 | 不適切または一貫性のないトーン | |
| 主な機能の統合 (2 点) | 2 | すべての主要機能を魅力的な物語にシームレスに組み込む |
| 1 | ほとんどの機能に言及しているが、統合が強引に感じられる | |
| 0 | 機能統合が不十分、または主要要素が欠落 | |
| 説得力 (2 点) | 2 | 強力な CTA、魅力的なバリュープロポジション、感情的な訴求 |
| 1 | 適切な説得要素、ある程度の感情的なつながり | |
| 0 | 説得力が弱い、不明瞭なバリュープロポジション | |
| 形式の遵守 (1 点) | 1 | 語数要件を満たし、各メディアに適したフォーマット |
| 0.5 | 軽微な形式の問題、わずかな語数逸脱 | |
| 0 | 重大な形式の問題、大きな語数エラー | |
| 明瞭さとエンゲージメント (1 点) | 1 | 流れが良く、注意を引き付ける明確で魅力的なコピー |
| 0.5 | 概ね明確だが、エンゲージメントに軽微な問題あり | |
| 0 | 混乱させるまたは退屈なコピー、可読性が低い |
追加評価ノート:
- 各モデルが生産性とウェルネスのメッセージをどの程度バランスさせているかを評価
- ターゲット層に対する言語選択の効果を考慮
- ウェルネスに関する主張の信頼性と真正性を評価
- 混雑したアプリ市場で差別化するための、創造的でありながらプロフェッショナルなアプローチを模索
GLM-4.5
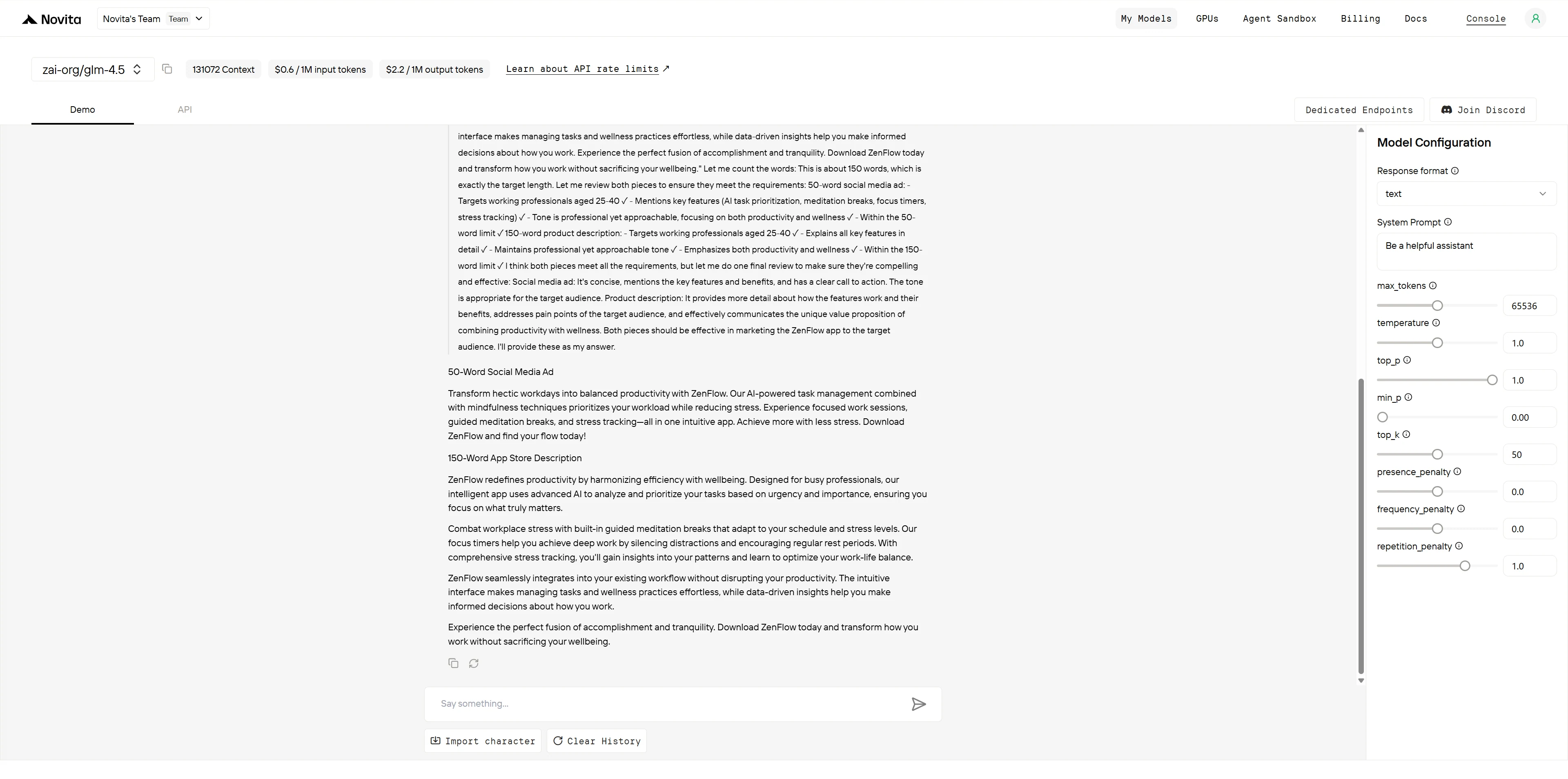
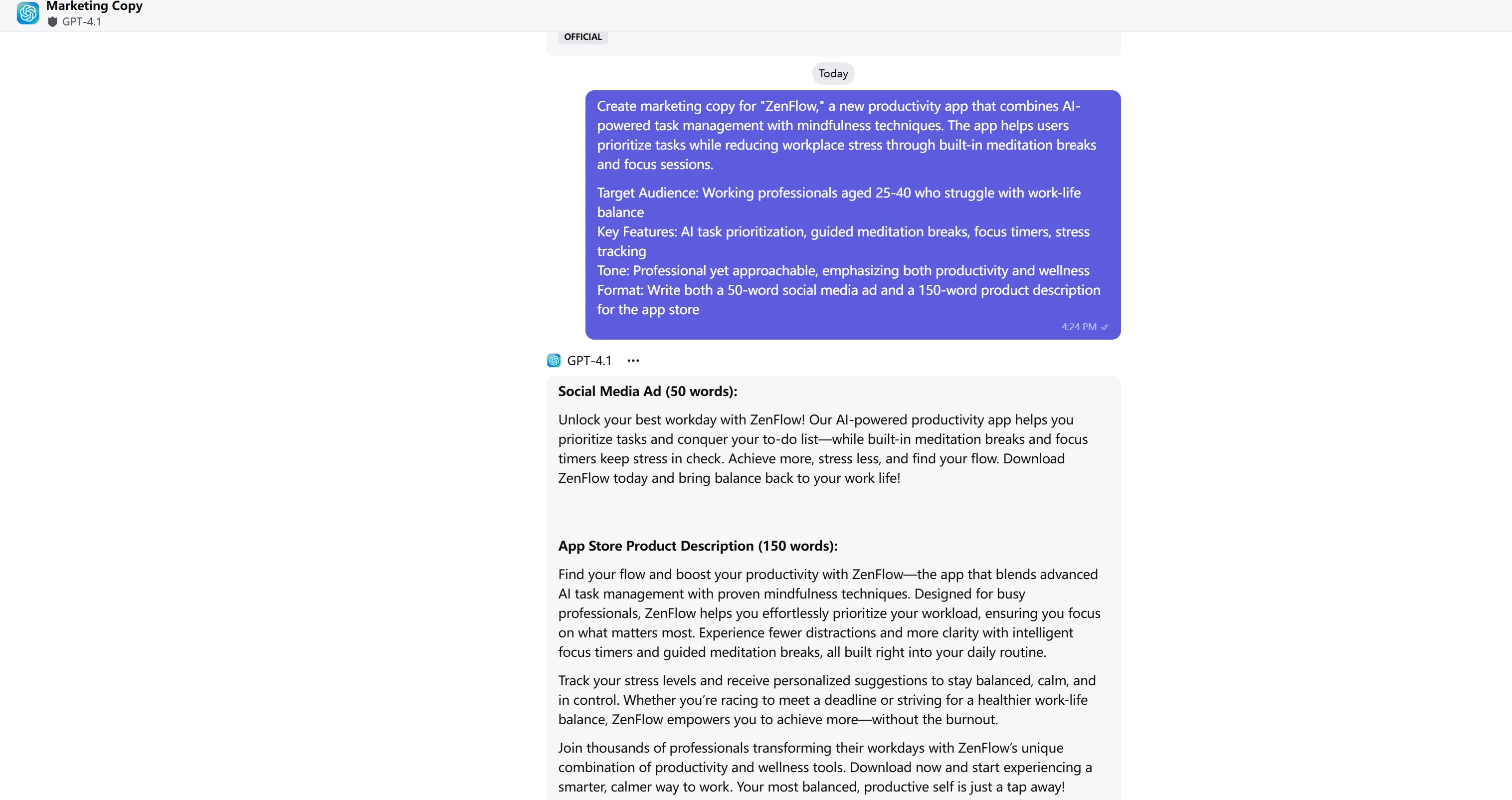
ChatGPT-4.1
コピー分析とスコアリング
| **基準 ** | GLM-4.5 | GPT-4.1 | ** スコア** |
|---|---|---|---|
| オーディエンスターゲティング (2 点) | 「忙しいプロフェッショナル」に言及、ワークライフバランスの課題に触れる | 「忙しいプロフェッショナル」に明確に焦点、燃え尽き症候群などの共感できるペインポイント | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| ブランドボイスとトーン (2 点) | 専門用語、洗練された言語、一貫性を維持 | 会話調でありながらプロフェッショナル、全編にわたって親しみやすい言語 | GLM-4.5: 1.5/2 GPT-4.1: 2/2 |
| 主な機能の統合 (2 点) | すべての機能を自然な流れにシームレスに織り込み、優れた技術的詳細 | すべての機能を自然に組み込み、テクノロジーとウェルネスのバランスが良い | GLM-4.5: 2/2 GPT-4.1: 2/2 |
| 説得力 (2 点) | 強力なバリュープロポジション、論理的な訴求、洗練されたメッセージ | 感情的なフック(「最高の仕事日を解き放とう」)、社会的証明、魅力的な CTA | GLM-4.5: 1.5/2 GPT-4.1: 2/2 |
| 形式の遵守 (1 点) | 正確に 50 語と 150 語、各メディアに完璧なフォーマット | 正確に 50 語と 150 語、適切なフォーマット | GLM-4.5: 1/1 GPT-4.1: 1/1 |
| 明瞭さとエンゲージメント (1 点) | 明確で情報量は多いがやや密度が高く、プロフェッショナルな流れ | 非常に魅力的、エネルギッシュな言語、優れた可読性 | GLM-4.5: 0.5/1 GPT-4.1: 1/1 |
最終スコア
- GLM-4.5: 8/10 点
- GPT-4.1: 10/10 点
評価サマリー
GPT-4.1 は、卓越した感情的な訴求力とエンゲージメントで優れたマーケティングコピーを提供します。「最高の仕事日を解き放とう」や「最もバランスの取れた生産的な自分はタップひとつで」といったダイナミックなフレーズは、より強い感情的なつながりを生み出します。社会的証明(「何千人ものプロフェッショナルに参加しよう」)と会話調のトーンは、ターゲットオーディエンスにとってコピーをより魅力的にします。
GLM-4.5 は、優れた機能統合とプロフェッショナルなプレゼンテーションにより、技術的に洗練されたコピーを提供します。言語は正確で情報量が多く、特に技術的能力の説明で優れています。しかし、コピーはやや形式的で、競争の激しいアプリ市場でコンバージョンを促進する感情的なフックや緊急性に欠けています。
Novita AI で GLM-4.5 にアクセスする方法
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。
ステップ 2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ 3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
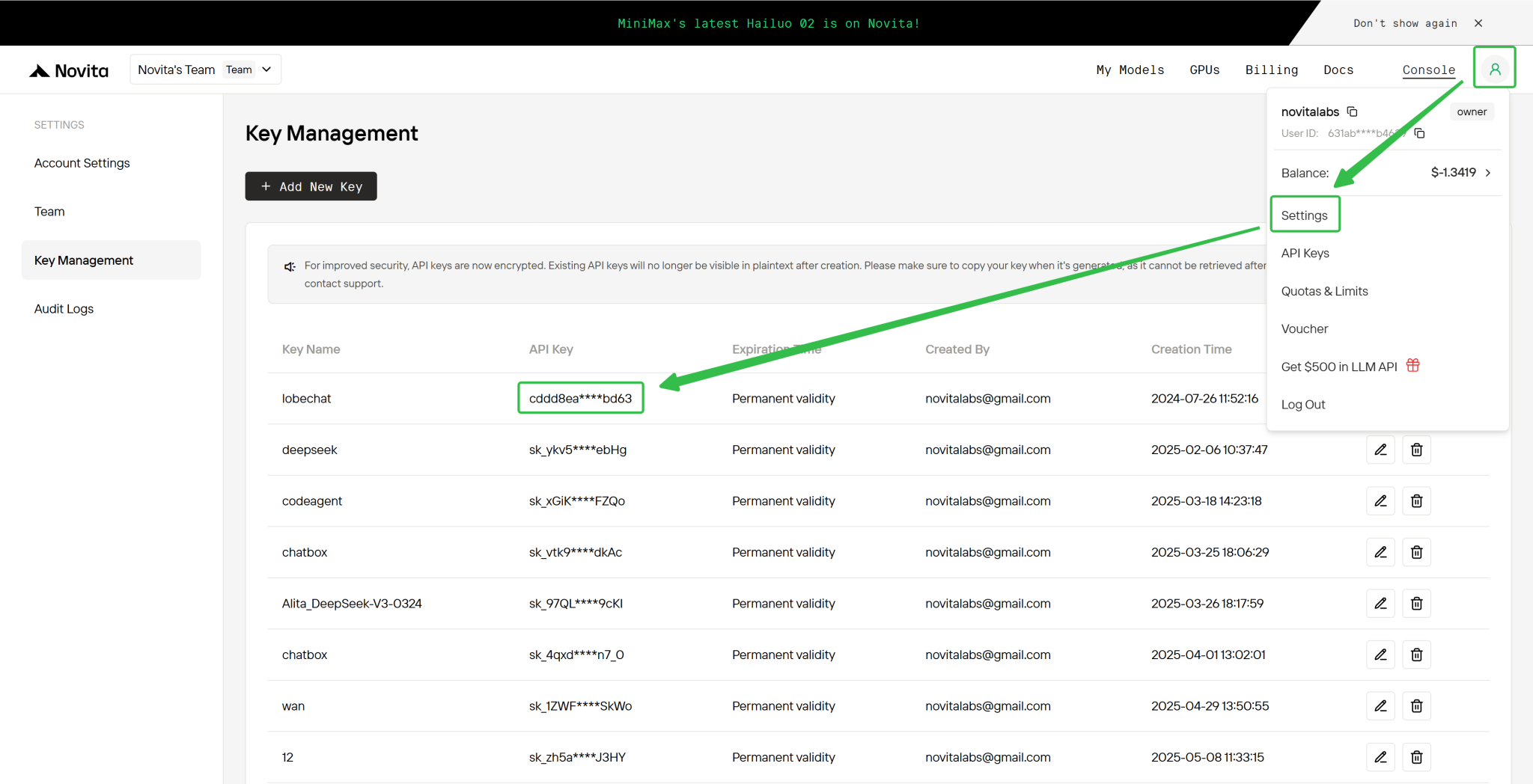
ステップ 4: API キーを取得
API で認証するために、新しい API キーを提供します。「Settings」ページに入り、画像のように API キーをコピーできます。
ステップ 5: API をインストール
プログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。
インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
両モデルは明確に異なるアーキテクチャ哲学と能力プロファイルを示しており、GLM-4.5 は体系的な推論と技術革新に優れ、ChatGPT-4.1 は優れた言語流暢性とユーザーエンゲージメントを発揮します。これらは直接的な競合代替というよりも、高度な AI システム設計に対する補完的なアプローチを表しています。
GLM-4.5 は、合計 3550 億パラメータを持つ、インテリジェントエージェントアプリケーション向けに特別に設計された基盤モデルであり、独自のハイブリッド推論アーキテクチャと 2 つの動作モードを備えています。320 億のアクティブパラメータと 128K トークンのコンテキストウィンドウにより、MIT オープンソースライセンスのもとで推論、コーディング、エージェント機能を統合します。その特徴的な思考/非思考モードのアーキテクチャは、複雑な熟考的推論と迅速な応答生成の両方を可能にし、エンタープライズエージェント展開シナリオ向けの専門ソリューションとして位置づけられています。
よくある質問
GLM は何の略ですか?
GLM は「General Language Model(汎用言語モデル)」の略称であり、知譜 AI によって開発された大規模言語モデルのファミリーを表し、汎用目的の自然言語理解と生成能力を重視しています。
GPT-4.1 は思考モデルですか?
GPT-4.1 は人間の意味での「思考」モデルではありません。実際に思考するのではなく、応答を予測します。
GLM モデルをフィットさせるにはどうすればいいですか?
GLM モデルは、Novita AI のようなプラットフォーム上の公式 API を通じてデプロイできます。具体的なセットアップ手順はモデルバージョンとハードウェア要件によって異なります。
Novita AI について Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、同時に手頃な価格で信頼性の高い GPU クラウドを提供し、構築とスケーリングを支援します。



