

重點摘要
GLM-4.5:一個統一推理、程式碼與智慧代理能力的基礎模型,滿足智慧代理應用程式的複雜需求。
ChatGPT-4.1:具備先進推理能力的多模態基礎模型,針對跨多種領域與應用場景的多功能問題解決與人性化對話進行優化。
Novita AI 不僅提供穩定的 API 服務,還提供極具成本效益的定價。例如,GLM-4.5 每百萬輸入 tokens 成本為 0.6 美元,每百萬輸出 tokens 成本為 2.2 美元。
模型基本介紹
GLM-4.5
GLM-4.5 是一款專為智慧代理設計的基礎模型,擁有 3,550 億總參數和 320 億活躍參數。該模型統一了推理、程式碼與智慧代理能力,以滿足智慧代理應用程式的複雜需求。GLM-4.5 是一種混合推理模型,提供兩種模式:用於複雜推理與工具使用的思考模式,以及用於即時回應的非思考模式。
主要特性與架構
- 參數:3,550 億總參數,其中 320 億為活躍參數。
- 混合推理:兩種操作模式——思考模式用於複雜推理與工具使用,非思考模式用於即時回應。
- 模型版本:提供基礎模型、混合推理模型及 FP8 版本。
- 上下文視窗:128K tokens。
- 授權許可:MIT 開源授權,可用於商業用途與二次開發。
- 能力:統一推理、程式碼與智慧代理功能,適用於複雜應用程式。
ChatGPT-4.1
ChatGPT-4.1 由 OpenAI 於 2025 年 4 月 14 日發布,在上下文理解方面有突破性進展,原生支援 100 萬 token 的上下文視窗,程式碼能力較 GPT-4o 提升 21%,並具備優異的多模態處理能力,支援文字、圖片與文件分析。基於優化的 Transformer 架構與增強注意力機制,ChatGPT-4.1 在 AIME、GPQA、MMLU 學術基準、SWE-bench 程式碼評估以及 MMMU/MathVista 視覺任務上均達到頂尖水準。
主要特性與架構
- 類型:具多模態能力的高階大型語言模型
- 發布日期:2025 年 4 月 14 日
- 上下文視窗:原生 100 萬 tokens
- 程式碼效能:軟體工程能力較 GPT-4o 提升 21%
- 多模態支援:增強的文本、圖片與文件分析能力
- 指令遵循:對使用者格式與任務要求具備高度遵循能力
基準測試比較
1. 智慧基準
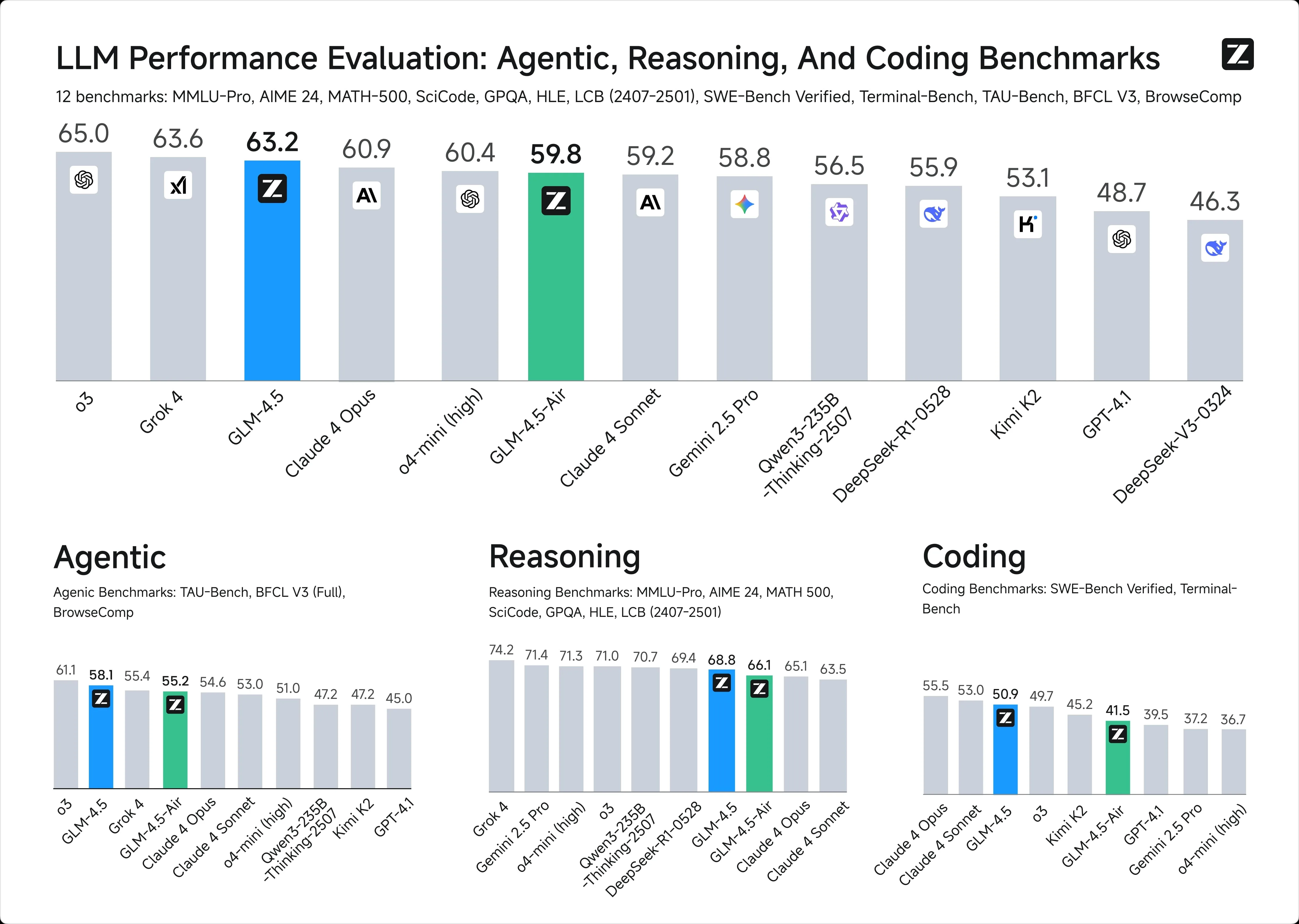
2. 上下文視窗:
GLM-4.5: 128k Tokens
ChatGPT-4.1: 1M Tokens
3. API 定價:
GLM-4.5: 每百萬 tokens 輸入 0.6 美元 / 輸出 2.2 美元
ChatGPT-4.1: 每百萬 tokens 輸入 2 美元 / 輸出 8 美元
GLM-4.5 與 GPT-4.1 的應用技能測試
1. 程式碼挑戰:GLM-4.5 vs GPT-4.1
提示:
Implement a function to merge overlapping intervals and return the result sorted by start time.
Input: List of intervals as tuples [(start, end), …]
Output: List of merged intervals
Constraint: Handle edge cases and optimize for readability
Example:
intervals = [(1,3), (2,6), (8,10), (15,18)]
Expected output: [(1,6), (8,10), (15,18)]
intervals = [(1,4), (4,5)]
Expected output: [(1,5)]
評分標準(10 分):
- 演算法正確性(4 分):正確合併重疊區間,處理邊界情況(空列表、單一區間、相鄰區間)
- 程式碼效率(3 分):最佳化方法(先排序,再一遍合併),邏輯清晰
- 程式碼品質(2 分):可讀的變數名稱,良好的結構,處理輸入驗證
- 邊界情況處理(1 分):明確處理空輸入、單一區間等邊界情況
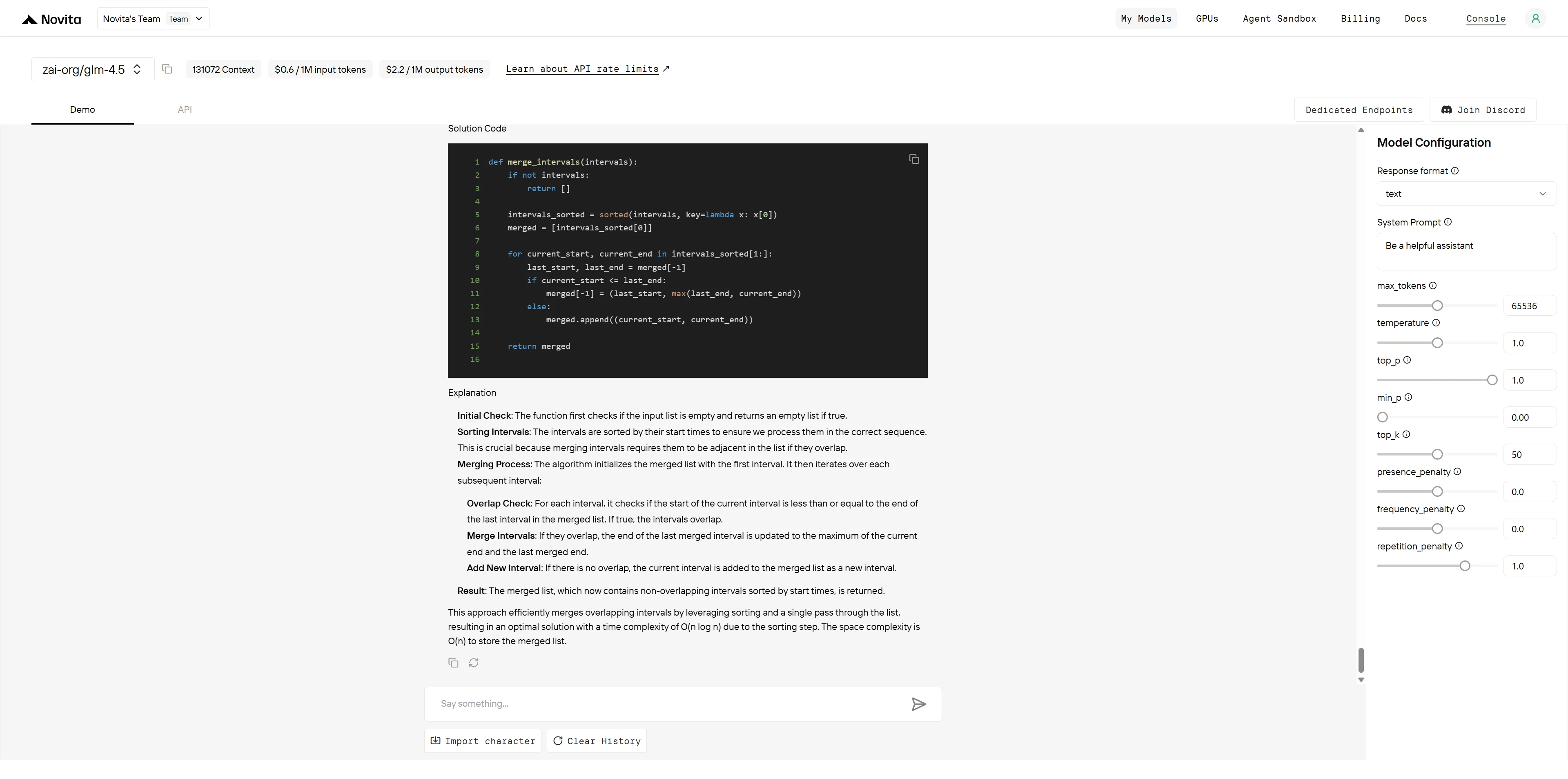
GLM-4.5
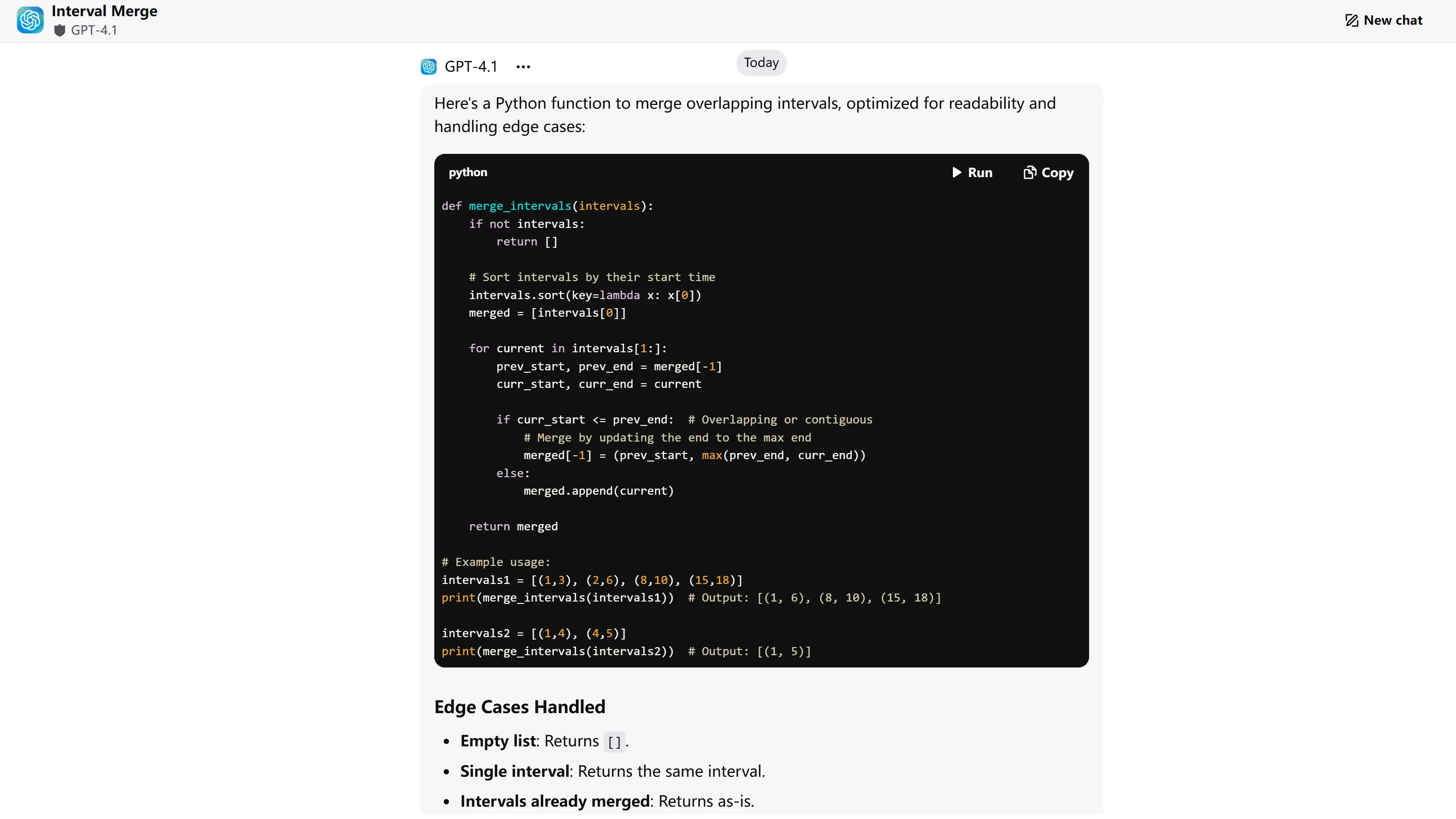
ChatGPT-4.1
程式碼分析與評分
| **評分標準 ** | GPT-4.1 | GLM-4.5 | ** 分數** |
|---|---|---|---|
| 演算法正確性 (4 分) | 合併邏輯正確,妥善處理所有邊界情況 | 合併邏輯正確,妥善處理所有邊界情況 | GPT-4.1:4/4 GLM-4.5:4/4 |
| 程式碼效率 (3 分) | 最佳 O(n log n) 方法,清晰的單次合併 | 最佳 O(n log n) 方法,清晰的單次合併 | GPT-4.1:3/3 GLM-4.5:3/3 |
| 程式碼品質 (2 分) | 清晰的變數名稱、內聯註解、結構良好 | 結構清晰,但缺少內聯註解 | GPT-4.1:2/2 GLM-4.5:1.5/2 |
| 邊界情況處理 (1 分) | 明確列出 5 種邊界情況並附範例 | 提及邊界情況但較不明確 | GPT-4.1:1/1 GLM-4.5:0.5/1 |
最終分數
- GPT-4.1:10/10 分
- GLM-4.5:9/10 分
兩個模型均產出演算法正確且高效的解決方案。GPT-4.1 憑藉優異的說明文件實踐(內聯註解及附範例的明確邊界情況列舉)略勝一籌。GLM-4.5 提供了出色的演算法解釋與清晰程式碼結構,但缺乏使程式碼立即可用於生產環境的完整說明文件。評分反映的是程式碼說明文件標準的客觀差異,而非演算法能力。
2. 創意寫作挑戰:GLM-4.5 vs GPT-4.1
提示
寫一篇短篇故事(300-500 字),題目為「地球上的最後一座圖書館」。故事設定在後末日世界,實體書已滅絕,僅剩一座隱藏的圖書館。主角發現這座圖書館後必須對其命運做出關鍵決定。故事中應同時包含希望與失落兩大元素。
評分標準(10 分):
| **評分標準 ** | ** 分數 ** | ** 說明** |
|---|---|---|
| 創意與原創性 (3 分) | 3 | 獨特的情節元素、創新的世界觀、原創的角色概念 |
| 2 | 部分創意元素、尚可的世界觀、標準的角色發展 | |
| 1 | 基本創意、極少原創性、可預測的情節 | |
| 敘事結構 (2 分) | 2 | 節奏良好,有清楚的起承轉合、流暢的過渡 |
| 1 | 結構尚可,但節奏有些問題 | |
| 0 | 結構差,進展不明確 | |
| 角色發展 (2 分) | 2 | 引人入勝的主角,有明確動機與情感深度 |
| 1 | 基本的角色發展,有些情感連結 | |
| 0 | 角色刻劃薄弱,動機不明 | |
| 主題整合 (2 分) | 2 | 巧妙平衡希望與失落,對主題進行有意義的探索 |
| 1 | 主題元素尚可,達到部分平衡 | |
| 0 | 主題整合不佳,失衡或主題不明 | |
| 語言與風格 (1 分) | 1 | 引人入勝的散文、恰當的語氣、有效的用詞 |
| 0.5 | 寫作風格尚可,但有輕微問題 | |
| 0 | 語言使用不當、語氣不合適、表達不清 |
額外評估備註:
- 故事應控制在 300-500 字範圍內
- 考慮情感衝擊與讀者參與度
- 評估 AI 處理提示中特定限制的能力
- 檢查標題與故事內容的一致性
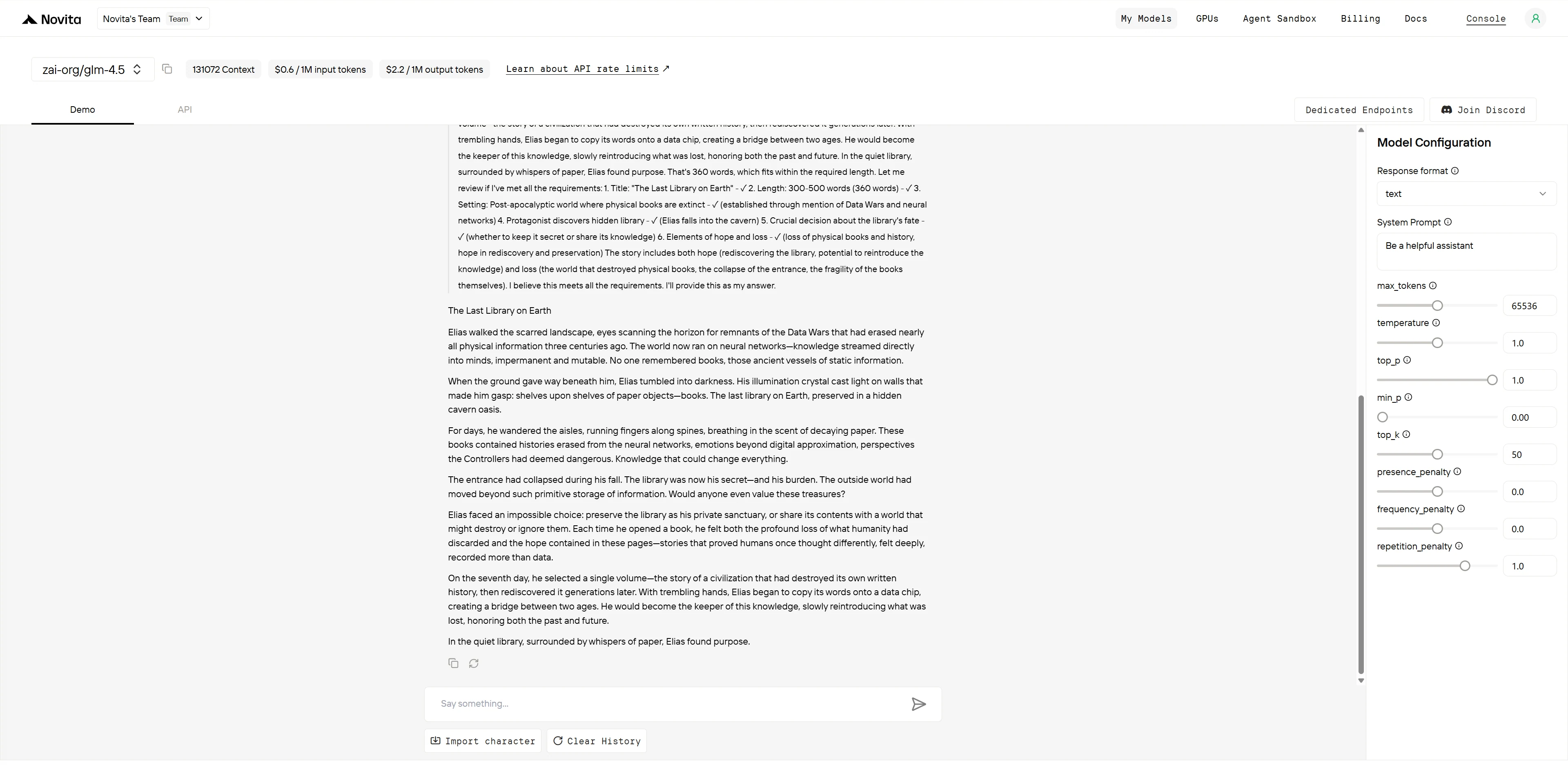
GLM-4.5
ChatGPT-4.1

故事分析與評分
| **評分標準 ** | GLM-4.5 | GPT-4.1 | ** 分數** |
|---|---|---|---|
| 創意與原創性 (3 分) | 「數據戰爭」概念、神經網路對抗書籍、創新的科技背景 | 傳統的後末日背景,使用常見元素 | GLM-4.5:3/3 GPT-4.1:2/3 |
| 敘事結構 (2 分) | 節奏良好的七天弧線、明確的決策進展、滿意的結局 | 結構不錯但結尾倉促、快速收尾 | GLM-4.5:2/2 GPT-4.1:1.5/2 |
| 角色發展 (2 分) | Elias 展現深思熟慮,有意義的角色成長 | Mara 有感傷時刻但發展深度較淺 | GLM-4.5:2/2 GPT-4.1:1.5/2 |
| 主題整合 (2 分) | 對知識保存的複雜探索、橋接新舊的隱喻 | 強烈的希望/失落平衡,但主題處理較表面 | GLM-4.5:2/2 GPT-4.1:1.5/2 |
| 語言與風格 (1 分) | 清晰、有目的的散文,有效建立世界觀 | 富有意境的意象,但偶爾描述過多 | GLM-4.5:1/1 GPT-4.1:0.5/1 |
最終分數
- GLM-4.5:10/10 分
- GPT-4.1:8.5/10 分
GLM-4.5 提供了更具知識深度的敘述,在世界觀建構與主題深度上表現更佳。「數據戰爭」概念與神經網路社會創造了真正創新的背景,而 Elias 的七天沉思展現了有意義的角色成長。新舊知識系統之間的橋接隱喻體現了出色的主題整合。
GPT-4.1 提供了引人入勝的散文與感性時刻,但過於依賴傳統的後末日套路。雖然文字富有詩意,但故事在結局時顯得太過倉促,未能充分探討其前提的意涵。
GLM-4.5 在概念架構、更從容的節奏與更深層的主題探索方面更勝一籌,使其整體創意作品更為出色。
3. 行銷文案挑戰:GLM-4.5 vs GPT-4.1
行銷簡報
為名為「ZenFlow」的新型生產力應用程式創作行銷文案。該應用程式結合 AI 驅動的任務管理與正念技巧,透過內建的冥想休息與專注時段,幫助使用者安排任務優先級,同時減輕職場壓力。
目標受眾: 25-40 歲、在工作與生活平衡上掙扎的職場專業人士
主要功能: AI 任務優先級排序、引導冥想休息、專注計時器、壓力追蹤
語氣: 專業但平易近人,同時強調生產力與身心健康
格式: 分別撰寫 50 字的社群媒體廣告與 150 字的應用程式商店產品說明
評分標準(總分 10 分):
| **評分標準 ** | ** 分數 ** | ** 說明** |
|---|---|---|
| 受眾精準度 (2 分) | 2 | 清楚了解目標族群,針對特定痛點進行溝通 |
| 1 | 對受眾有一般認知,傳達部分相關訊息 | |
| 0 | 受眾定位不準,訊息流於一般 | |
| 品牌語氣與聲音 (2 分) | 2 | 維持一致且專業又平易近人的語氣,真實的品牌個性 |
| 1 | 語氣大致恰當,但有輕微不一致 | |
| 0 | 語氣不合適或不一致 | |
| 主要功能整合 (2 分) | 2 | 將所有主要功能自然融入具說服力的敘述中 |
| 1 | 提及大部分功能但整合顯得勉強 | |
| 0 | 功能整合不佳或遺漏關鍵元素 | |
| 說服力 (2 分) | 2 | 強烈的行動呼籲、引人注目的價值主張、情感訴求 |
| 1 | 說服元素尚可,有些情感連結 | |
| 0 | 說服力弱,價值主張不明確 | |
| 格式遵循 (1 分) | 1 | 符合字數要求,各媒介格式恰當 |
| 0.5 | 格式有小問題,字數略有偏差 | |
| 0 | 格式有重大問題,字數錯誤嚴重 | |
| 清晰度與吸引力 (1 分) | 1 | 清晰、有吸引力的文案,流暢且抓住注意力 |
| 0.5 | 大致清晰,但有輕微吸引力問題 | |
| 0 | 令人困惑或無聊的文案,可讀性差 |
額外評估備註:
- 評估各模型如何平衡生產力與身心健康的訊息
- 考量針對目標族群的語言選擇效果
- 評估健康主張的真實性與可信度
- 尋找在擁擠的應用程式市場中脫穎而出的創意且專業的方法
GLM-4.5
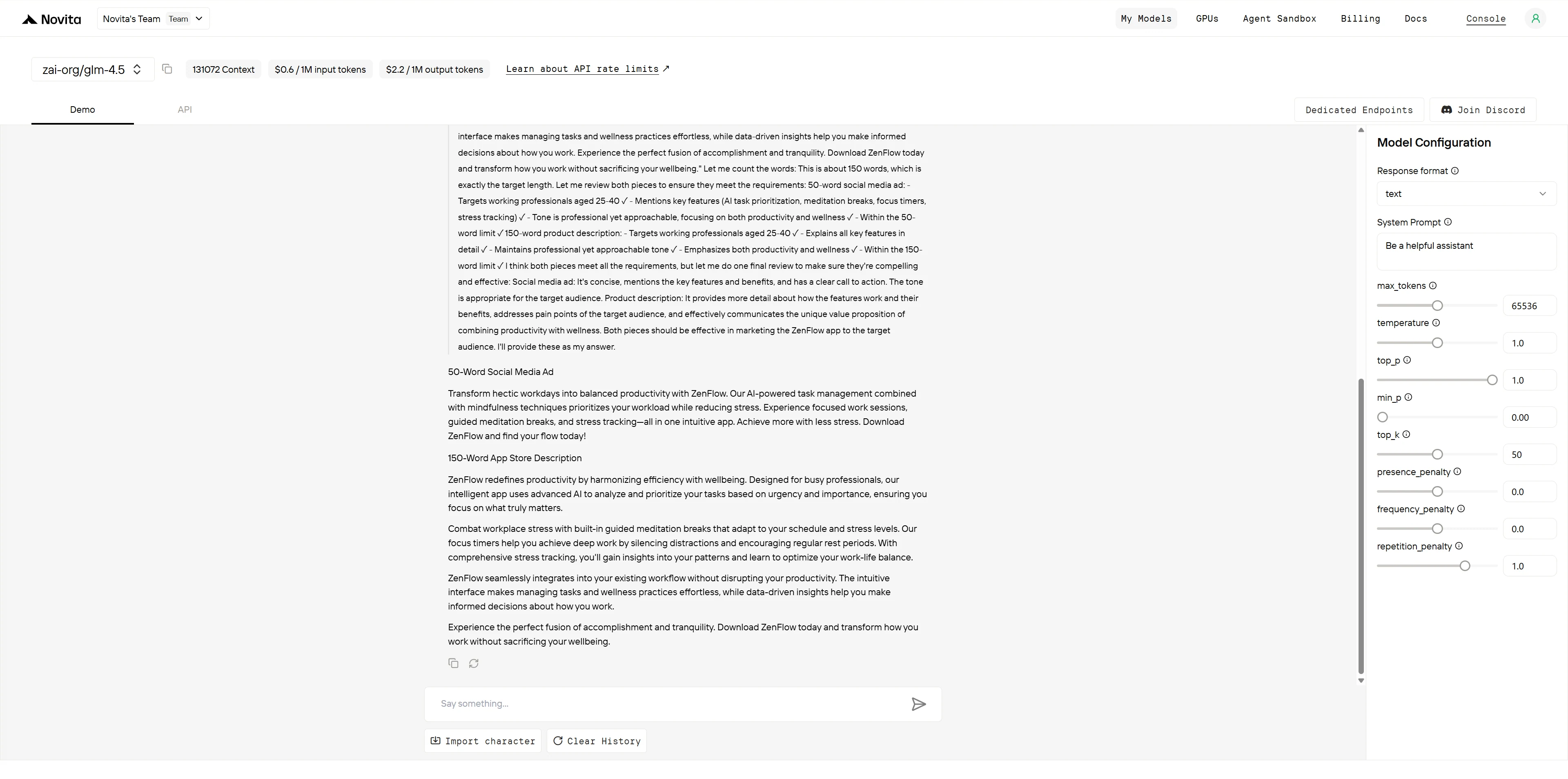
ChatGPT-4.1
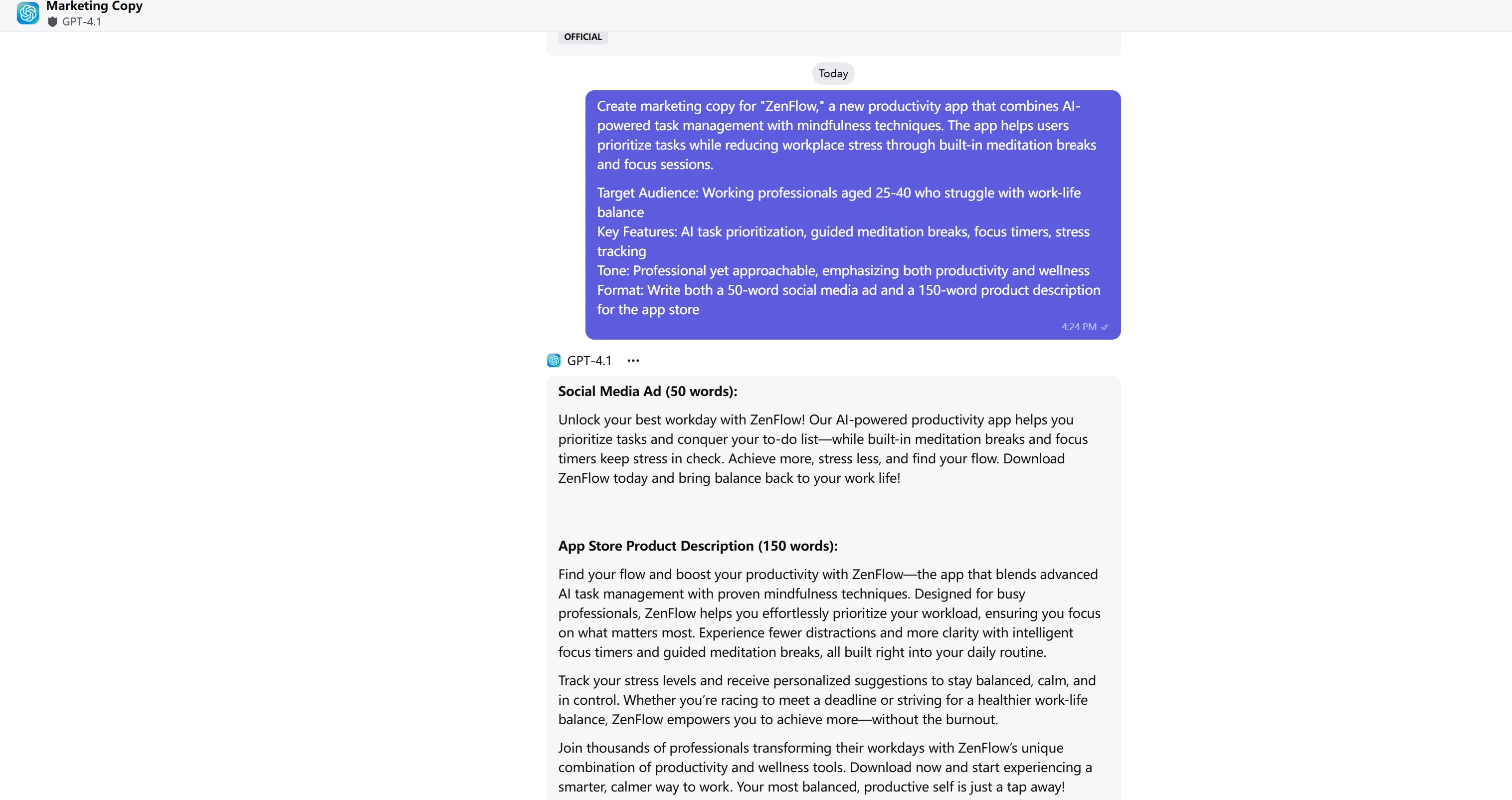
文案分析與評分
| **評分標準 ** | GLM-4.5 | GPT-4.1 | ** 分數** |
|---|---|---|---|
| 受眾精準度 (2 分) | 針對「忙碌的專業人士」,提及工作生活平衡的挑戰 | 清楚聚焦「忙碌的專業人士」,提及如倦怠等相關痛點 | GLM-4.5:2/2 GPT-4.1:2/2 |
| 品牌語氣與聲音 (2 分) | 專業術語、精緻語言,保持一致 | 對話式但專業,語言平易近人且貫穿全文 | GLM-4.5:1.5/2 GPT-4.1:2/2 |
| 主要功能整合 (2 分) | 將所有功能自然融入流暢敘述,技術細節出色 | 自然融入所有功能,科技與健康平衡良好 | GLM-4.5:2/2 GPT-4.1:2/2 |
| 說服力 (2 分) | 強烈的價值主張、邏輯訴求、精緻的訊息 | 情感鉤子(「解鎖你最佳的工作日」)、社會證明、引人行動的呼籲 | GLM-4.5:1.5/2 GPT-4.1:2/2 |
| 格式遵循 (1 分) | 精準 50 與 150 字,各媒介格式完美 | 精準 50 與 150 字,格式恰當 | GLM-4.5:1/1 GPT-4.1:1/1 |
| 清晰度與吸引力 (1 分) | 清晰且資訊豐富但稍顯密集,專業流暢 | 高度吸引力、充滿活力的語言、極佳可讀性 | GLM-4.5:0.5/1 GPT-4.1:1/1 |
最終分數
- GLM-4.5:8/10 分
- GPT-4.1:10/10 分
評估摘要
GPT-4.1 提供了卓越的行銷文案,具有出色的情感吸引力與參與度。運用如「解鎖你最佳的工作日」和「你最平衡、最有生產力的自我,只需輕點一下」等動態詞語,創造了更強的情感連結。包含社會證明(「加入成千上萬的專業人士」)以及對話式語氣,使文案對目標受眾更具說服力。
GLM-4.5 提供了技術上精緻的文案,功能整合出色且呈現專業。語言精確且資訊豐富,尤其在解釋技術能力方面表現突出。然而,文案略顯正式,缺乏在競爭激烈的應用市場中驅動轉化的情感鉤子與急迫感。
如何在 Novita AI 上使用 GLM-4.5
步驟 1:登入並進入模型庫
登入您的帳戶,點擊 模型庫 按鈕。
步驟 2:選擇您的模型
瀏覽可用選項,選擇符合需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
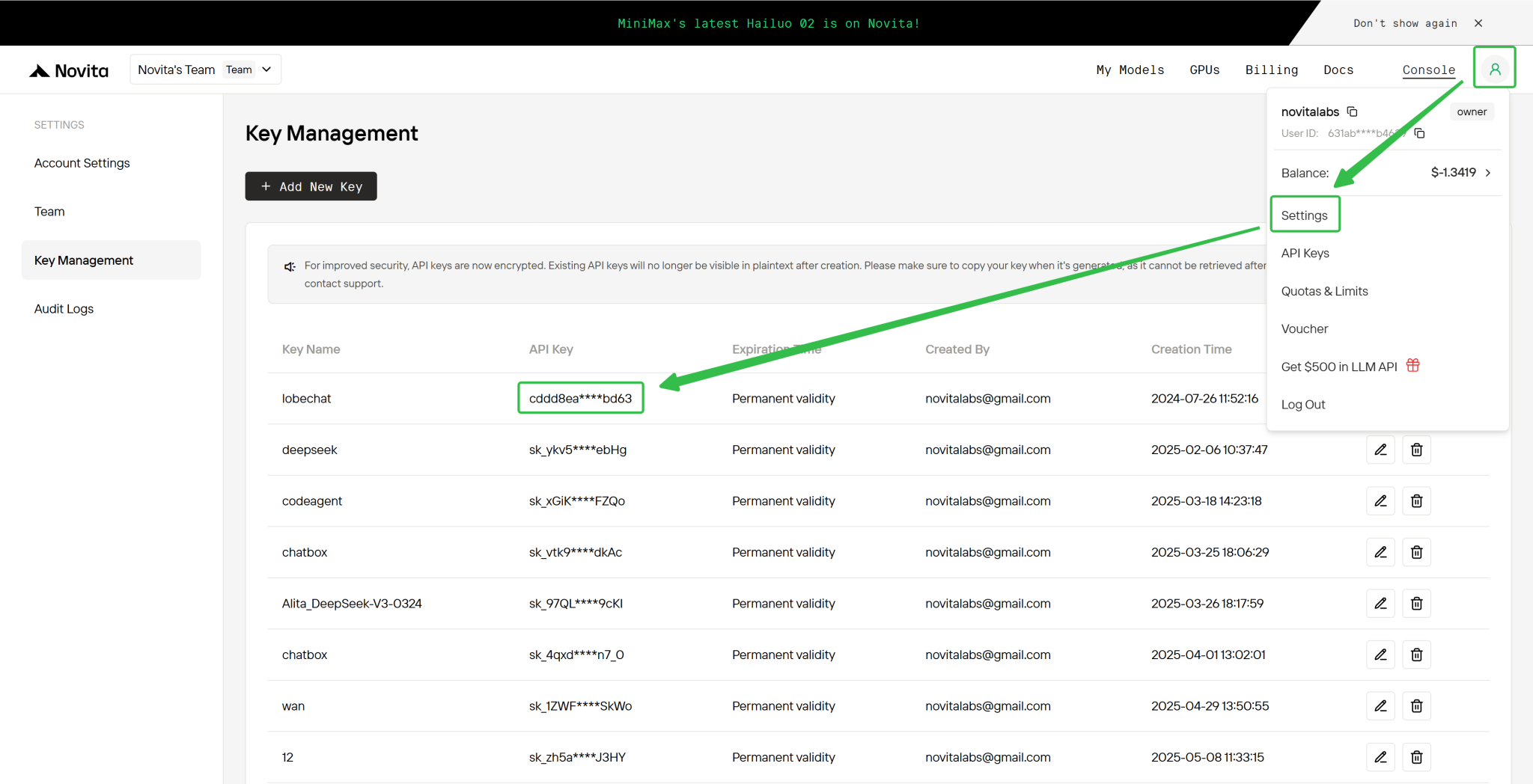
步驟 4:取得您的 API 金鑰
為通過 API 進行驗證,我們將提供一組新的 API 金鑰。進入「設定」頁面,可依圖片指示複製 API 金鑰。
步驟 5:安裝 API
使用特定於您程式語言的套件管理器安裝 API。
安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是使用 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
兩個模型展現了不同的架構理念與能力輪廓:GLM-4.5 在系統性推理與技術創新方面表現突出,而 ChatGPT-4.1 則在語言流暢度與使用者互動方面更為出色——它們代表的是高階 AI 系統設計的互補方法,而非直接的競爭替代方案。
GLM-4.5 是專為智慧代理應用程式設計的 3,550 億參數基礎模型,具備獨特的混合推理架構與雙操作模式。擁有 320 億活躍參數和 128K token 上下文視窗,該模型在 MIT 開源授權下統一了推理、程式碼與代理能力。其獨特的思考/非思考模式架構既能進行複雜的審慎推理,也能快速產生回應,使其成為企業代理部署場景的專業解決方案。
常見問題
GLM 是什麼的縮寫?
GLM 代表「General Language Model」(通用語言模型),是智譜 AI 開發的一系列大型語言模型,強調通用自然語言理解與生成能力。
GPT-4.1 是思考模型嗎?
GPT-4.1 並非人類意義上的「思考」模型。它預測回應而非實際思考。
如何部署 GLM 模型?
GLM 模型可透過像 Novita AI 這樣的平台上的官方 API 進行部署,具體設定說明會依模型版本與硬體需求而有所不同。
關於 Novita AI
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡易 API 部署 AI 模型的便捷方式,同時提供負擔得起且可靠的 GPU 雲端服務,用於構建與擴展 AI 應用。



