

Points clés
GLM-4.5 : Un modèle de fondation qui unifie le raisonnement, le codage et les capacités d’agent intelligent pour répondre aux exigences complexes des applications d’agent intelligent.
ChatGPT-4.1 : Modèle de fondation multimodal doté de capacités de raisonnement avancées, optimisé pour la résolution de problèmes polyvalente et les conversations de type humain dans divers domaines et applications.
Novita AI fournit non seulement des services API stables, mais propose également des tarifs extrêmement compétitifs. Par exemple, GLM-4.5 coûte 0,6 $ pour 1 million de tokens d’entrée et 2,2 $ pour 1 million de tokens de sortie.
Présentation de base du modèle
GLM-4.5
GLM-4.5 est un modèle de fondation conçu pour les agents intelligents, avec 355 milliards de paramètres au total et 32 milliards de paramètres actifs. Le modèle unifie le raisonnement, le codage et les capacités d’agent intelligent pour répondre aux exigences complexes des applications d’agent intelligent. GLM-4.5 est un modèle de raisonnement hybride qui propose deux modes : le mode réflexion pour le raisonnement complexe et l’utilisation d’outils, et le mode non-réflexion pour les réponses immédiates.
Principales fonctionnalités et architecture
- Paramètres : 355 milliards de paramètres au total, dont 32 milliards de paramètres actifs.
- Raisonnement hybride : Deux modes de fonctionnement - le mode réflexion pour le raisonnement complexe et l’utilisation d’outils, et le mode non-réflexion pour les réponses immédiates.
- Versions du modèle : Disponible en modèles de base, modèles de raisonnement hybride et versions FP8.
- Fenêtre de contexte : 128 000 tokens.
- Licence : Licence open source MIT pour une utilisation commerciale et un développement secondaire.
- Capacités : Fonctionnalités unifiées de raisonnement, de codage et d’agent intelligent pour des applications complexes.
ChatGPT-4.1
ChatGPT-4.1, publié le 14 avril 2025 par OpenAI, présente des améliorations révolutionnaires dans la compréhension contextuelle avec une fenêtre de contexte native de 1 million de tokens, des capacités de codage améliorées de 21 % par rapport à GPT-4o, et un traitement multimodal supérieur pour l’analyse de texte, d’image et de document. Construit sur une architecture de transformateur optimisée avec des mécanismes d’attention renforcés, ChatGPT-4.1 atteint des performances de pointe dans les benchmarks académiques AIME, GPQA, MMLU, les évaluations de codage SWE-bench et les tâches de vision MMMU/MathVista.
Principales fonctionnalités et architecture
- Type : Modèle de langage avancé avec capacités multimodales
- Date de publication : 14 avril 2025
- Fenêtre de contexte : 1 million de tokens en natif
- Performances de codage : Amélioration de 21 % des capacités d’ingénierie logicielle par rapport à GPT-4o
- Support multimodal : Capacités améliorées d’analyse de texte, d’image et de document
- Suivi des instructions : Adhésion avancée aux exigences de formatage et de tâches des utilisateurs
Comparaison des benchmarks
1. Benchmarks d’intelligence
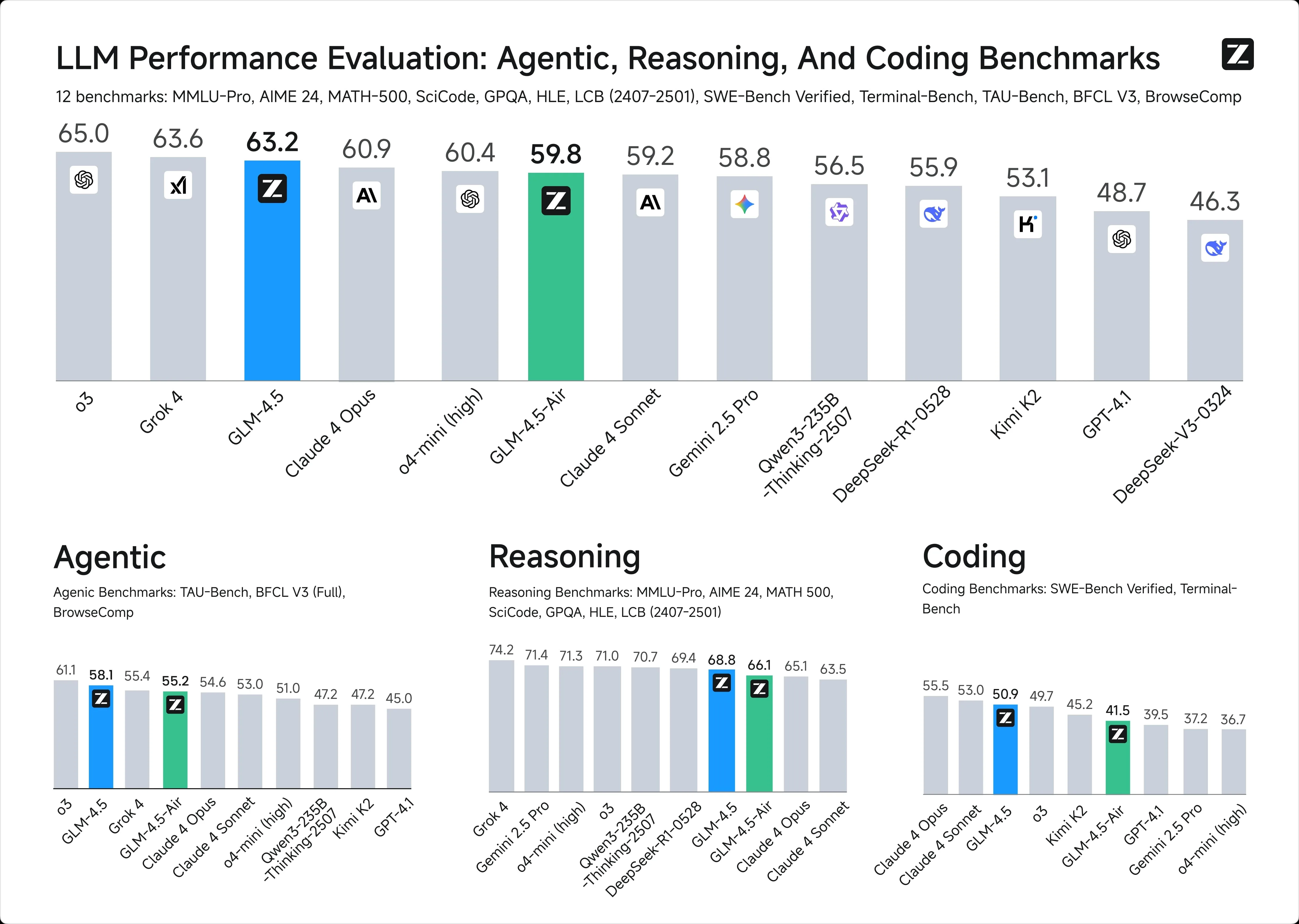
2. Fenêtre de contexte :
GLM-4.5: 128 000 tokens
ChatGPT-4.1: 1 million de tokens
3. Tarification API :
GLM-4.5: 0,6 $ / 2,2 $ entrée/sortie par million de tokens
ChatGPT-4.1: 2 $ / 8 $ entrée/sortie par million de tokens
Test des compétences appliquées de GLM-4.5 et GPT**-**4.1
1. Défi de codage : GLM-4.5 vs GPT-4.1
Invite :
Implémentez une fonction pour fusionner les intervalles qui se chevauchent et renvoyez le résultat trié par heure de début.
Entrée : Liste d'intervalles sous forme de tuples [(start, end), …]
Sortie : Liste des intervalles fusionnés
Contrainte : Gérez les cas limites et optimisez la lisibilité
Exemple :
intervals = [(1,3), (2,6), (8,10), (15,18)]
Sortie attendue : [(1,6), (8,10), (15,18)]
intervals = [(1,4), (4,5)]
Sortie attendue : [(1,5)]
Critères de notation (10 points) :
- Exactitude de l’algorithme (4 points) : Fusionne correctement les intervalles qui se chevauchent, gère les cas limites (liste vide, intervalle unique, intervalles contigus)
- Efficacité du code (3 points) : Approche optimale (tri préalable, puis fusion en un seul passage), logique propre
- Qualité du code (2 points) : Noms de variables lisibles, structure appropriée, gestion de la validation des entrées
- Gestion des cas limites (1 point) : Gère explicitement les cas particuliers comme l’entrée vide, l’intervalle unique, etc.
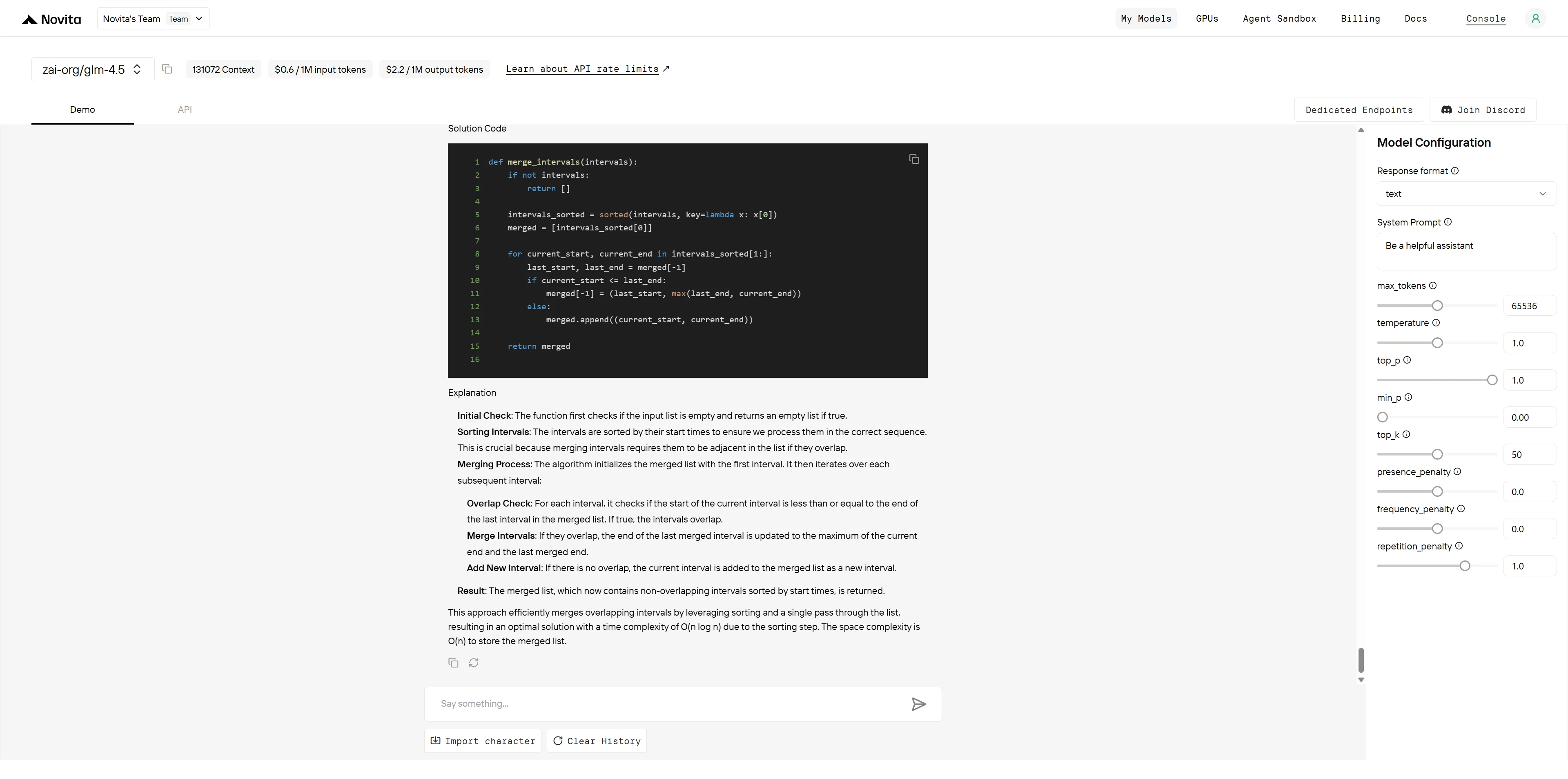
GLM-4.5
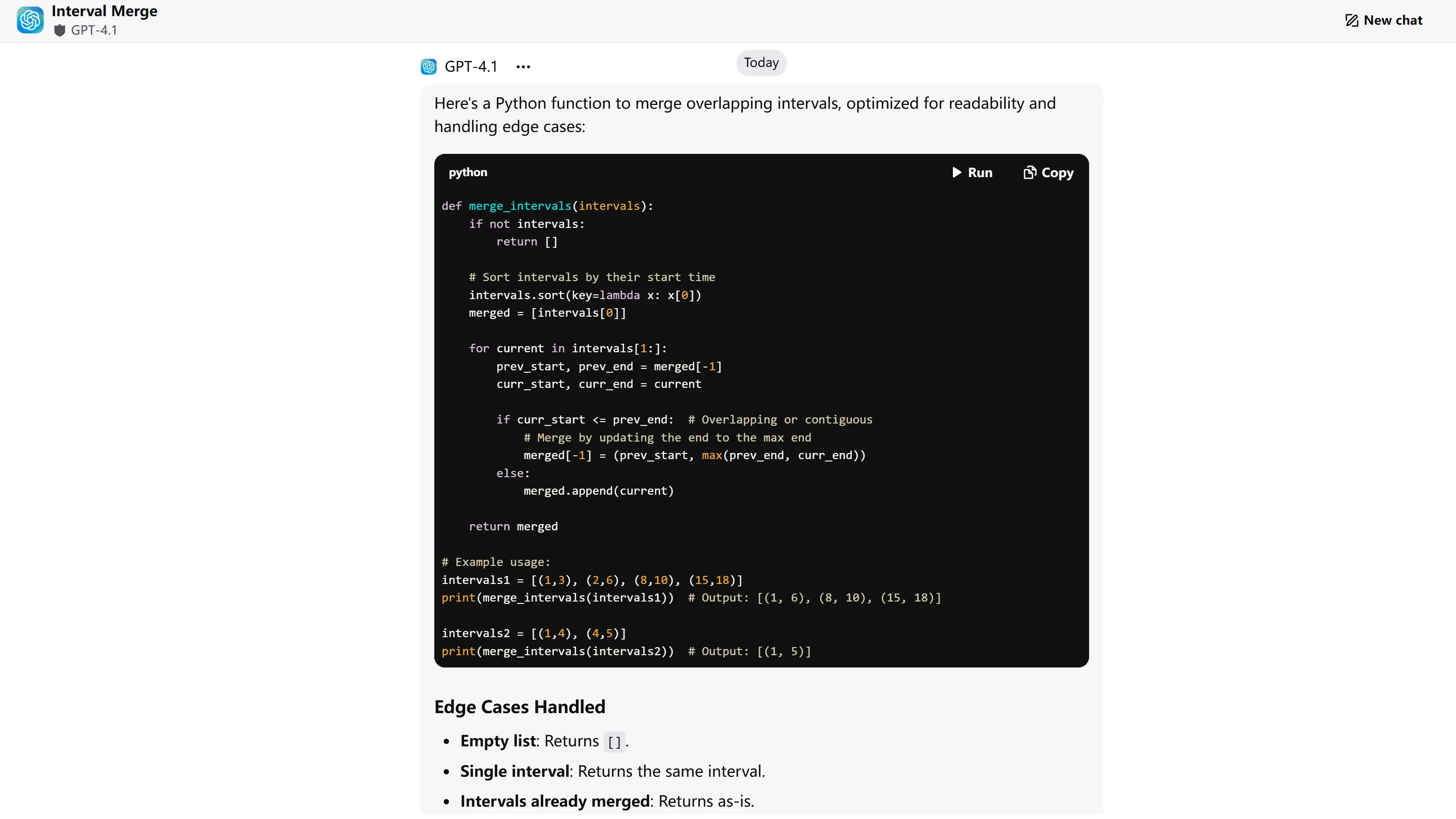
ChatGPT-4.1
Analyse et notation du code
| Critère | GPT-4.1 | GLM-4.5 | Scores |
|---|---|---|---|
| Exactitude de l’algorithme (4 pts) | Logique de fusion correcte, gère tous les cas limites | Logique de fusion correcte, gère tous les cas limites | GPT-4.1 : 4/4 GLM-4.5 : 4/4 |
| Efficacité du code (3 pts) | Approche optimale O(n log n), fusion propre en un seul passage | Approche optimale O(n log n), fusion propre en un seul passage | GPT-4.1 : 3/3 GLM-4.5 : 3/3 |
| Qualité du code (2 pts) | Noms de variables clairs, commentaires en ligne, bonne structure | Structure propre, mais manque de commentaires en ligne | GPT-4.1 : 2/2 GLM-4.5 : 1,5/2 |
| Gestion des cas limites (1 pt) | Documente explicitement 5 cas limites avec exemples | Mentionne les cas limites mais documentation moins explicite | GPT-4.1 : 1/1 GLM-4.5 : 0,5/1 |
Scores finaux
- GPT-4.1 : 10/10 points
- GLM-4.5 : 9/10 points
Les deux modèles produisent des solutions algorithmiquement correctes et efficaces. GPT-4.1 prend l’avantage grâce à des pratiques de documentation supérieures via des commentaires en ligne et une énumération explicite des cas limites avec exemples. GLM-4.5 fournit une excellente explication algorithmique et une structure de code propre, mais manque de la documentation complète qui rend le code immédiatement prêt pour la production. La notation reflète des différences objectives dans les normes de documentation du code plutôt que dans la capacité algorithmique.
2. Défi d’écriture créative : GLM-4.5 vs GPT-4.1
Invite
Écrivez une courte histoire (300-500 mots) intitulée « La dernière bibliothèque sur Terre ». L’histoire doit se dérouler dans un monde post-apocalyptique où les livres physiques ont disparu, à l’exception d’une bibliothèque cachée. Votre protagoniste découvre cette bibliothèque et doit prendre une décision cruciale concernant son destin. Incluez des éléments d’espoir et de perte dans votre récit.
Critères de notation (10 points) :
| Critère | Points | Description |
|---|---|---|
| Créativité et originalité (3 pts) | 3 | Éléments d’intrigue uniques, construction du monde innovante, concepts de personnages originaux |
| 2 | Quelques éléments créatifs, construction du monde correcte, développement de personnage standard | |
| 1 | Créativité de base, originalité minimale, éléments prévisibles | |
| Structure narrative (2 pts) | 2 | Histoire bien rythmée avec un début/milieu/fin clair, transitions fluides |
| 1 | Structure adéquate avec quelques problèmes de rythme | |
| 0 | Structure médiocre, progression floue | |
| Développement du personnage (2 pts) | 2 | Protagoniste captivant avec des motivations claires et une profondeur émotionnelle |
| 1 | Développement de base du personnage, un certain lien émotionnel | |
| 0 | Caractérisation faible, motivations floues | |
| Intégration thématique (2 pts) | 2 | Équilibre habile entre espoir et perte, exploration significative des thèmes |
| 1 | Éléments thématiques adéquats, un certain équilibre atteint | |
| 0 | Intégration thématique médiocre, thèmes déséquilibrés ou flous | |
| Langue et style (1 pt) | 1 | Prose engageante, ton approprié, choix de mots efficaces |
| 0,5 | Style d’écriture adéquat avec des problèmes mineurs | |
| 0 | Mauvaise utilisation de la langue, ton inapproprié, expression peu claire |
Notes d’évaluation supplémentaires :
- Les histoires doivent respecter la limite de 300 à 500 mots
- Tenir compte de l’impact émotionnel et de l’engagement du lecteur
- Évaluer comment l’IA gère les contraintes spécifiques de l’invite
- Rechercher la cohérence entre le titre et le contenu de l’histoire
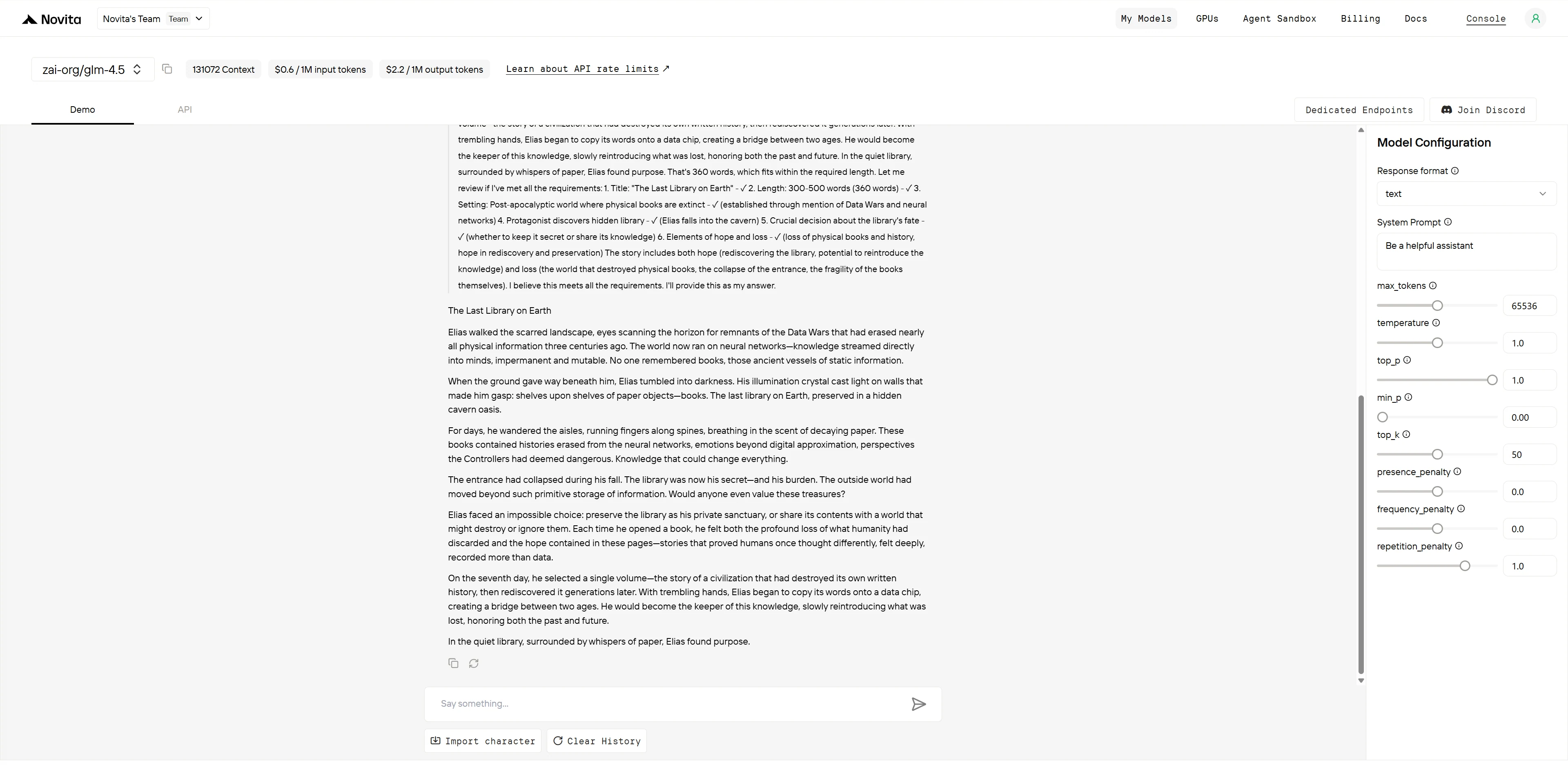
GLM-4.5
ChatGPT-4.1

Analyse et notation de l’histoire
| Critère | GLM-4.5 | GPT-4.1 | Scores |
|---|---|---|---|
| Créativité et originalité (3 pts) | Concept de « guerres des données », réseaux de neurones vs livres, toile de fond technologique innovante | Cadre post-apocalyptique traditionnel avec des éléments familiers | GLM-4.5 : 3/3 GPT-4.1 : 2/3 |
| Structure narrative (2 pts) | Arc bien rythmé de sept jours, progression claire de la décision, résolution satisfaisante | Bonne structure mais fin précipitée, résolution rapide | GLM-4.5 : 2/2 GPT-4.1 : 1,5/2 |
| Développement du personnage (2 pts) | Elias montre une contemplation réfléchie, une croissance significative du personnage | Mara a des moments émotionnels mais moins de profondeur de développement | GLM-4.5 : 2/2 GPT-4.1 : 1,5/2 |
| Intégration thématique (2 pts) | Exploration sophistiquée de la préservation des connaissances, métaphore de la construction de ponts | Bon équilibre espoir/perte mais traitement thématique plus superficiel | GLM-4.5 : 2/2 GPT-4.1 : 1,5/2 |
| Langue et style (1 pt) | Prose claire et déterminée avec une construction du monde efficace | Imagerie évocatrice mais descriptions parfois excessives | GLM-4.5 : 1/1 GPT-4.1 : 0,5/1 |
Scores finaux
- GLM-4.5 : 10/10 points
- GPT-4.1 : 8,5/10 points
GLM-4.5 offre un récit plus sophistiqué intellectuellement avec une construction du monde et une profondeur thématique supérieures. Le concept de « guerres des données » et la société des réseaux de neurones créent une toile de fond véritablement innovante, tandis que la contemplation réfléchie d’Elias sur sept jours montre un développement significatif du personnage. La métaphore de la construction de ponts entre les anciens et les nouveaux systèmes de connaissances démontre une intégration thématique sophistiquée.
GPT-4.1 offre une prose engageante et des moments émotionnels, mais repose sur des tropes post-apocalyptiques plus conventionnels. Bien que l’écriture soit lyrique, l’histoire semble précipitée vers sa résolution et n’explore pas pleinement les implications de sa prémisse.
Le cadre conceptuel supérieur de GLM-4.5, son rythme plus délibéré et son exploration thématique plus profonde en font l’œuvre créative la plus forte dans l’ensemble.
3. Défi de copie marketing : GLM-4.5 vs GPT-4.1
Brief marketing
Créez une copie marketing pour « ZenFlow », une nouvelle application de productivité qui combine la gestion des tâches alimentée par l’IA avec des techniques de pleine conscience. L’application aide les utilisateurs à prioriser les tâches tout en réduisant le stress au travail grâce à des pauses méditation intégrées et des sessions de concentration.
Public cible : Professionnels actifs âgés de 25 à 40 ans qui luttent pour trouver un équilibre entre vie professionnelle et vie privée Fonctionnalités clés : Priorisation des tâches par IA, pauses méditation guidées, minuteurs de concentration, suivi du stress Ton : Professionnel mais accessible, mettant l’accent à la fois sur la productivité et le bien-être Format : Rédigez à la fois une publicité sur les réseaux sociaux de 50 mots et une description de produit de 150 mots pour l’App Store
Critères de notation (10 points au total) :
| Critère | Points | Description |
|---|---|---|
| Ciblage de l’audience (2 pts) | 2 | Compréhension claire de la démographie cible, répond aux problèmes spécifiques |
| 1 | Conscience générale de l’audience, messages pertinents | |
| 0 | Mauvais ciblage de l’audience, messages génériques | |
| Voix de la marque et ton (2 pts) | 2 | Ton cohérent professionnel mais accessible, personnalité de marque authentique |
| 1 | Ton généralement approprié avec des incohérences mineures | |
| 0 | Ton inapproprié ou incohérent | |
| Intégration des fonctionnalités clés (2 pts) | 2 | Intègre parfaitement toutes les fonctionnalités clés dans un récit convaincant |
| 1 | Mentionne la plupart des fonctionnalités mais l’intégration semble forcée | |
| 0 | Mauvaise intégration des fonctionnalités ou éléments clés manquants | |
| Impact persuasif (2 pts) | 2 | Appel à l’action fort, proposition de valeur convaincante, attrait émotionnel |
| 1 | Éléments persuasifs adéquats, un certain lien émotionnel | |
| 0 | Persuasion faible, proposition de valeur floue | |
| Respect du format (1 pt) | 1 | Respect des limites de mots, formatage approprié pour chaque support |
| 0,5 | Problèmes de format mineurs, léger écart par rapport au nombre de mots | |
| 0 | Problèmes de format majeurs, erreurs importantes de nombre de mots | |
| Clarté et engagement (1 pt) | 1 | Copie claire et engageante qui coule bien et retient l’attention |
| 0,5 | Généralement clair avec des problèmes d’engagement mineurs | |
| 0 | Copie confuse ou ennuyeuse, faible lisibilité |
Notes d’évaluation supplémentaires :
- Évaluer comment chaque modèle équilibre les messages de productivité et de bien-être
- Tenir compte de l’efficacité des choix linguistiques pour la démographie cible
- Évaluer l’authenticité et la crédibilité des affirmations de bien-être
- Rechercher des approches créatives mais professionnelles pour se démarquer sur un marché d’applications saturé
GLM-4.5
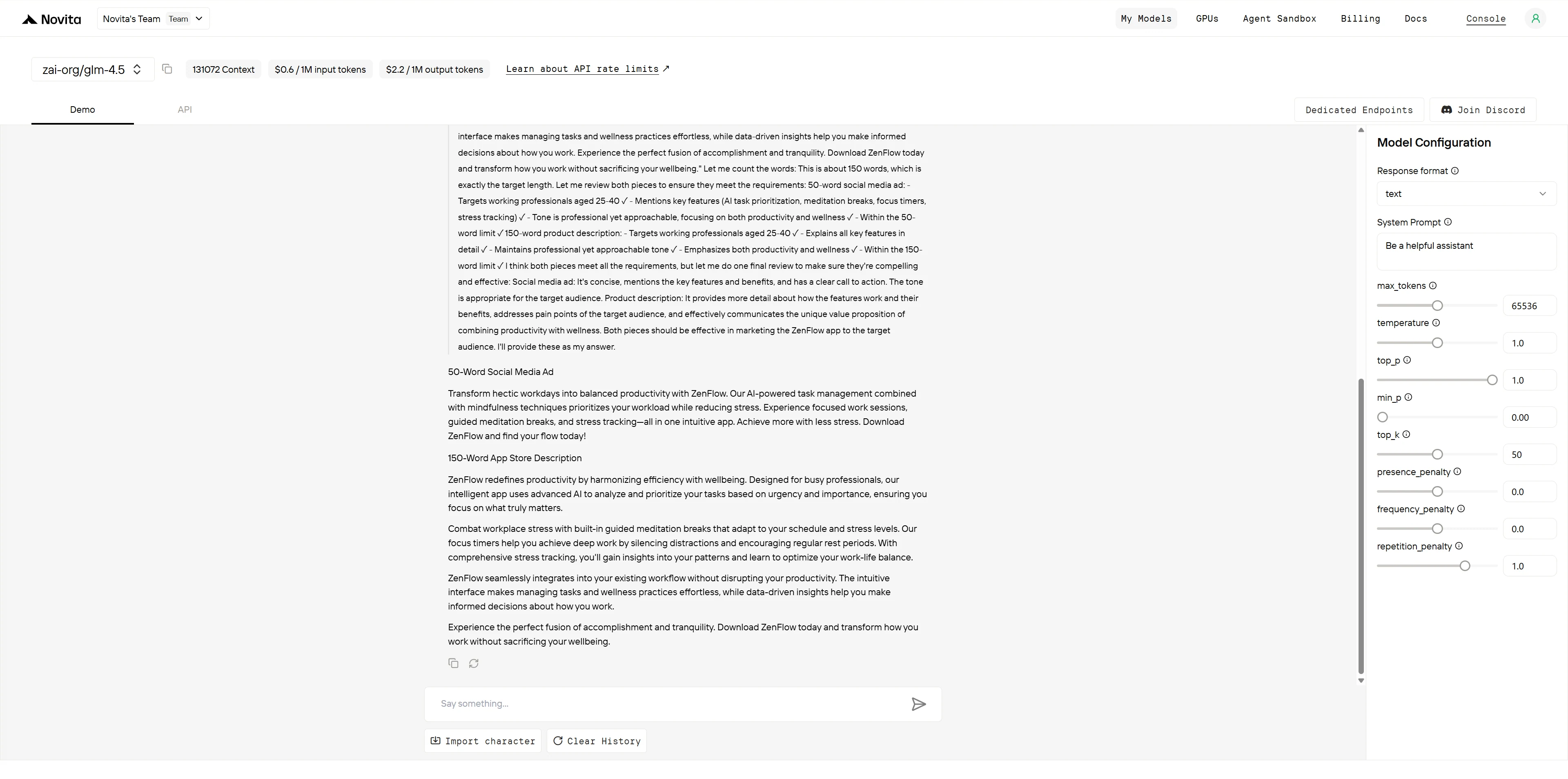
ChatGPT-4.1
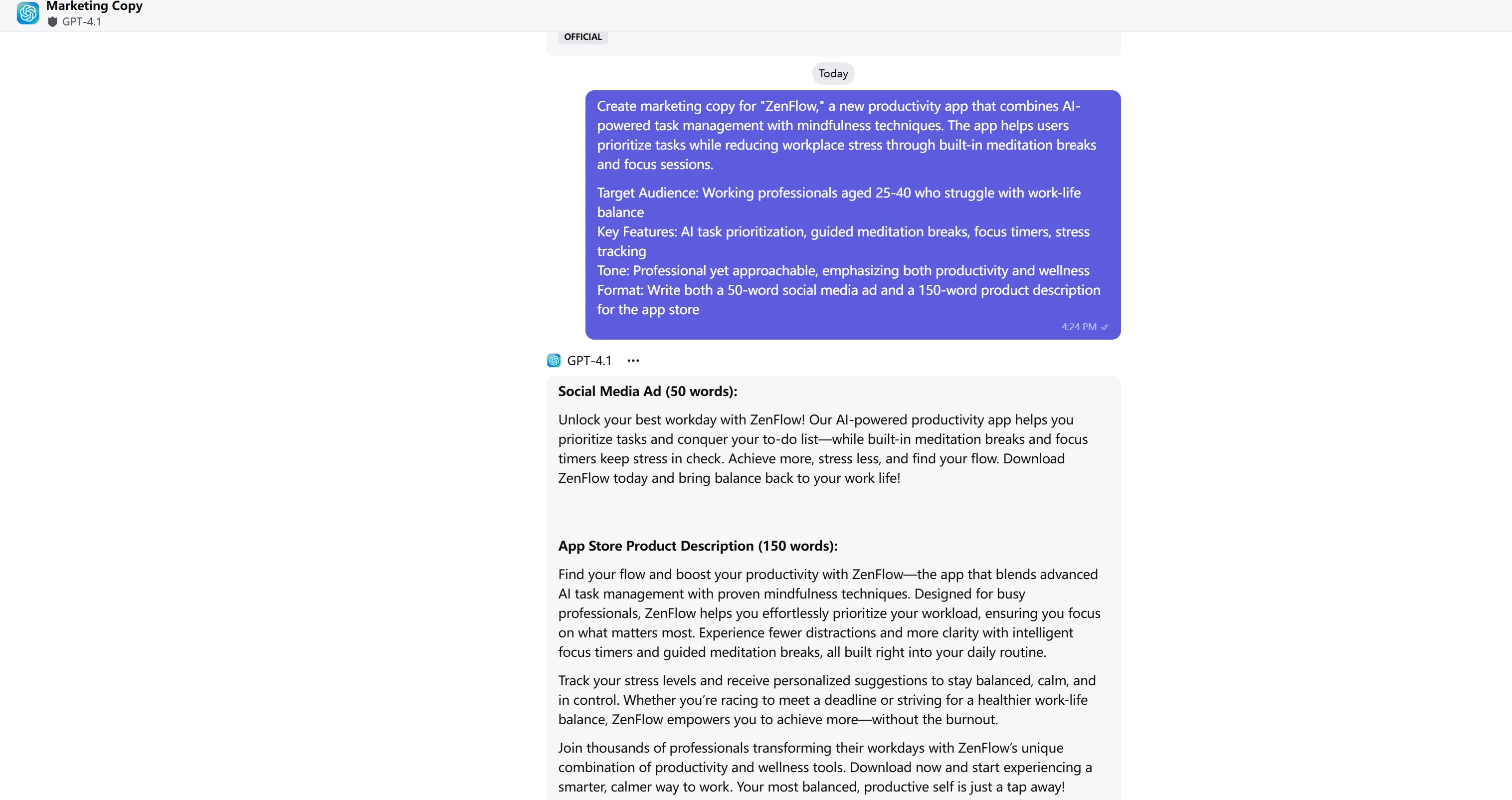
Analyse et notation de la copie
| Critère | GLM-4.5 | GPT-4.1 | Scores |
|---|---|---|---|
| Ciblage de l’audience (2 pts) | S’adresse aux « professionnels occupés », mentionne les défis d’équilibre travail-vie personnelle | Accent clair sur les « professionnels occupés », problèmes pertinents comme l’épuisement professionnel | GLM-4.5 : 2/2 GPT-4.1 : 2/2 |
| Voix de la marque et ton (2 pts) | Terminologie professionnelle, langage sophistiqué, maintient la cohérence | Conversationnel mais professionnel, langage accessible tout au long | GLM-4.5 : 1,5/2 GPT-4.1 : 2/2 |
| Intégration des fonctionnalités clés (2 pts) | Tisse parfaitement toutes les fonctionnalités dans un flux naturel, excellent détail technique | Intègre toutes les fonctionnalités naturellement, bon équilibre entre technologie et bien-être | GLM-4.5 : 2/2 GPT-4.1 : 2/2 |
| Impact persuasif (2 pts) | Proposition de valeur solide, attrait logique, message sophistiqué | Accroches émotionnelles (« libérez votre meilleure journée de travail »), preuve sociale, appel à l’action convaincant | GLM-4.5 : 1,5/2 GPT-4.1 : 2/2 |
| Respect du format (1 pt) | Exactement 50 et 150 mots, formatage parfait pour chaque support | Exactement 50 et 150 mots, formatage approprié | GLM-4.5 : 1/1 GPT-4.1 : 1/1 |
| Clarté et engagement (1 pt) | Clair et informatif mais quelque peu dense, flux professionnel | Très engageant, langage énergique, excellente lisibilité | GLM-4.5 : 0,5/1 GPT-4.1 : 1/1 |
Scores finaux
- GLM-4.5 : 8/10 points
- GPT-4.1 : 10/10 points
Résumé de l’évaluation
GPT-4.1 offre une copie marketing supérieure avec un attrait émotionnel et un engagement exceptionnels. L’utilisation de phrases dynamiques comme « libérez votre meilleure journée de travail » et « votre moi le plus équilibré et productif est à portée de main » crée un lien émotionnel plus fort. L’inclusion de preuve sociale (« rejoignez des milliers de professionnels ») et le ton conversationnel rendent la copie plus convaincante pour le public cible.
GLM-4.5 fournit une copie techniquement sophistiquée avec une excellente intégration des fonctionnalités et une présentation professionnelle. Le langage est précis et informatif, particulièrement fort dans l’explication des capacités techniques. Cependant, la copie semble légèrement formelle et manque des accroches émotionnelles et de l’urgence qui favorisent les conversions sur les marchés d’applications concurrentiels.
Comment accéder à GLM-4.5 sur Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.
Essayez maintenant gratuitement !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
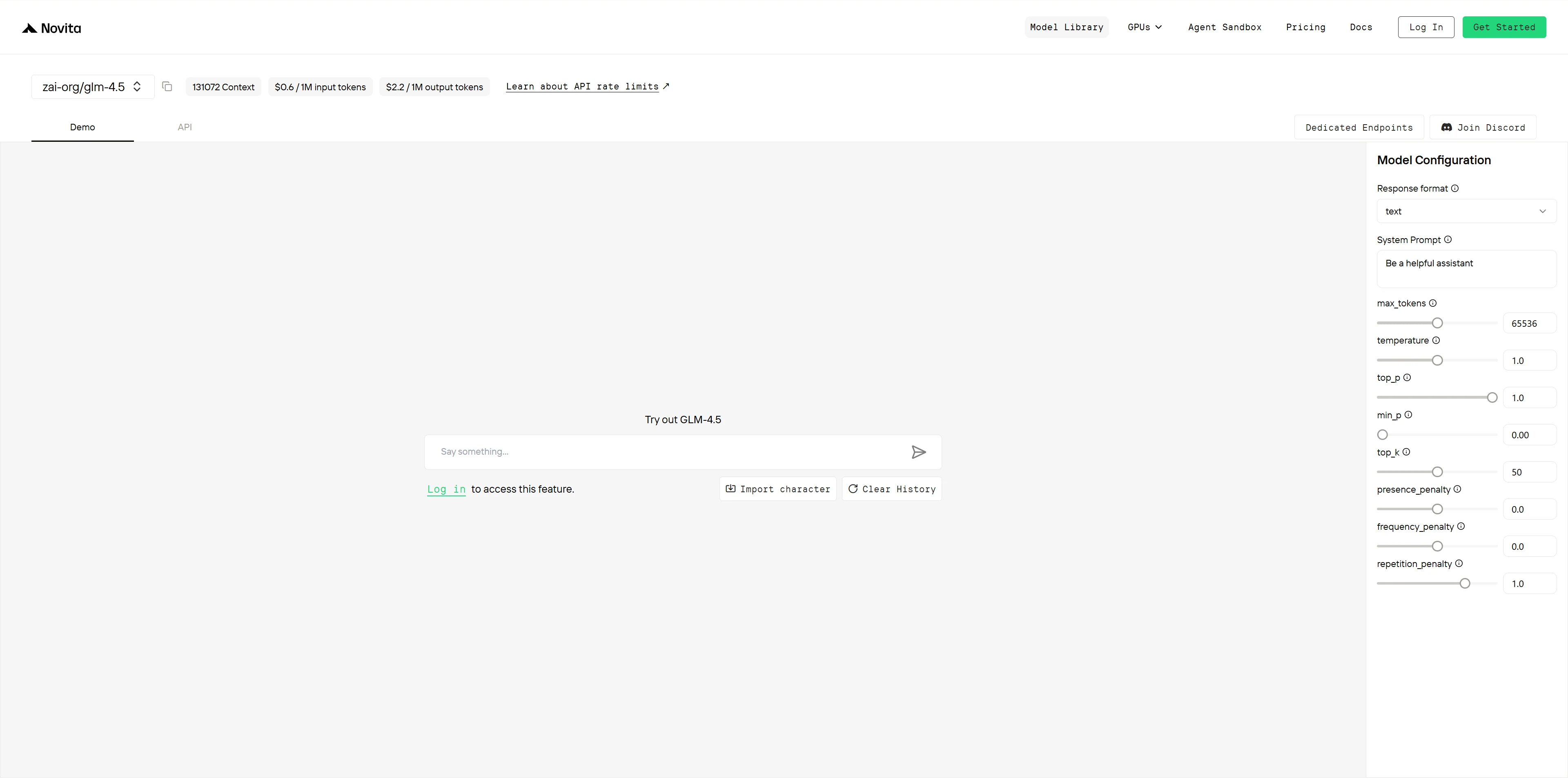
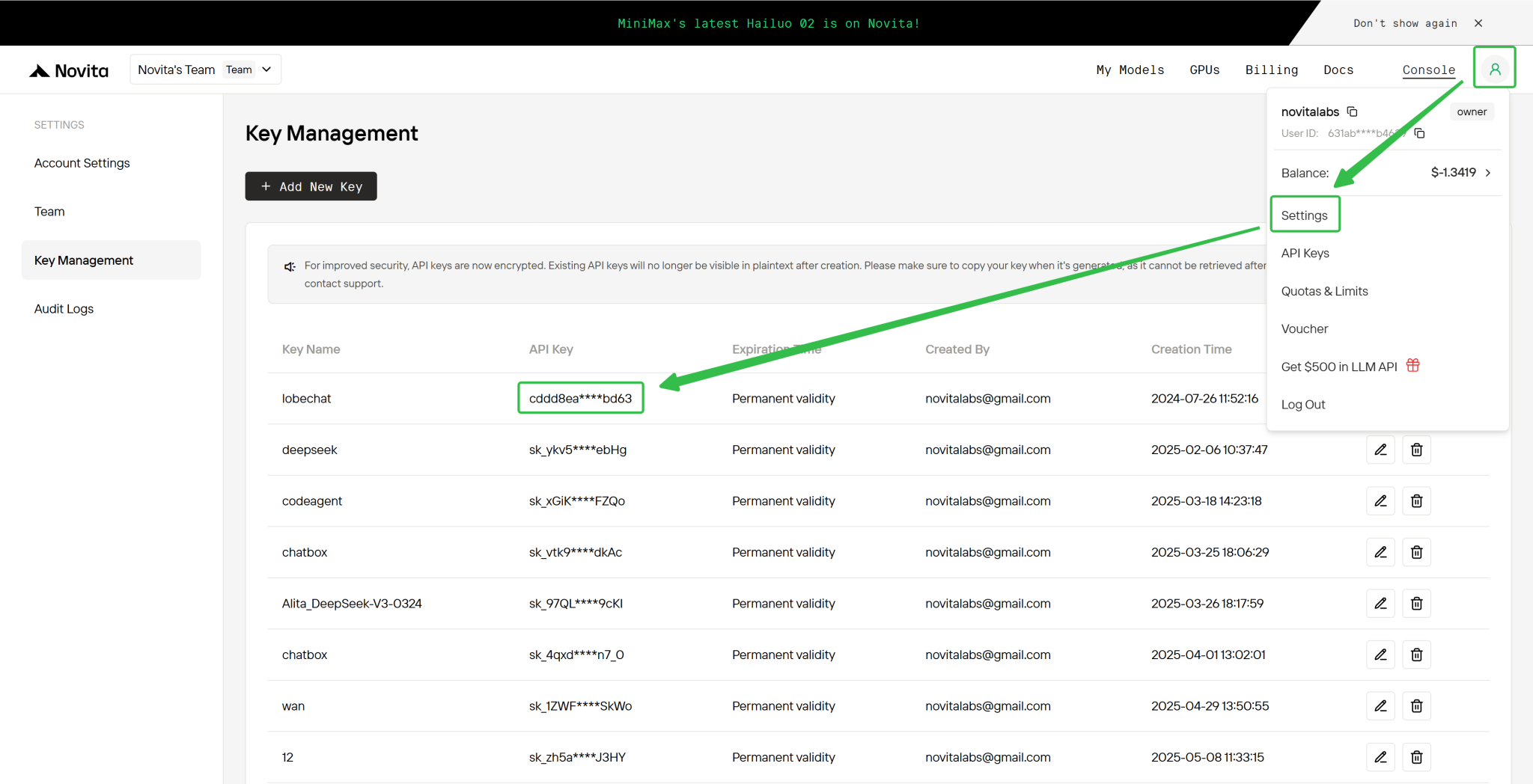
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Settings », vous pouvez copier la clé API comme indiqué dans l’image.
Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de packages spécifique à votre langage de programmation.
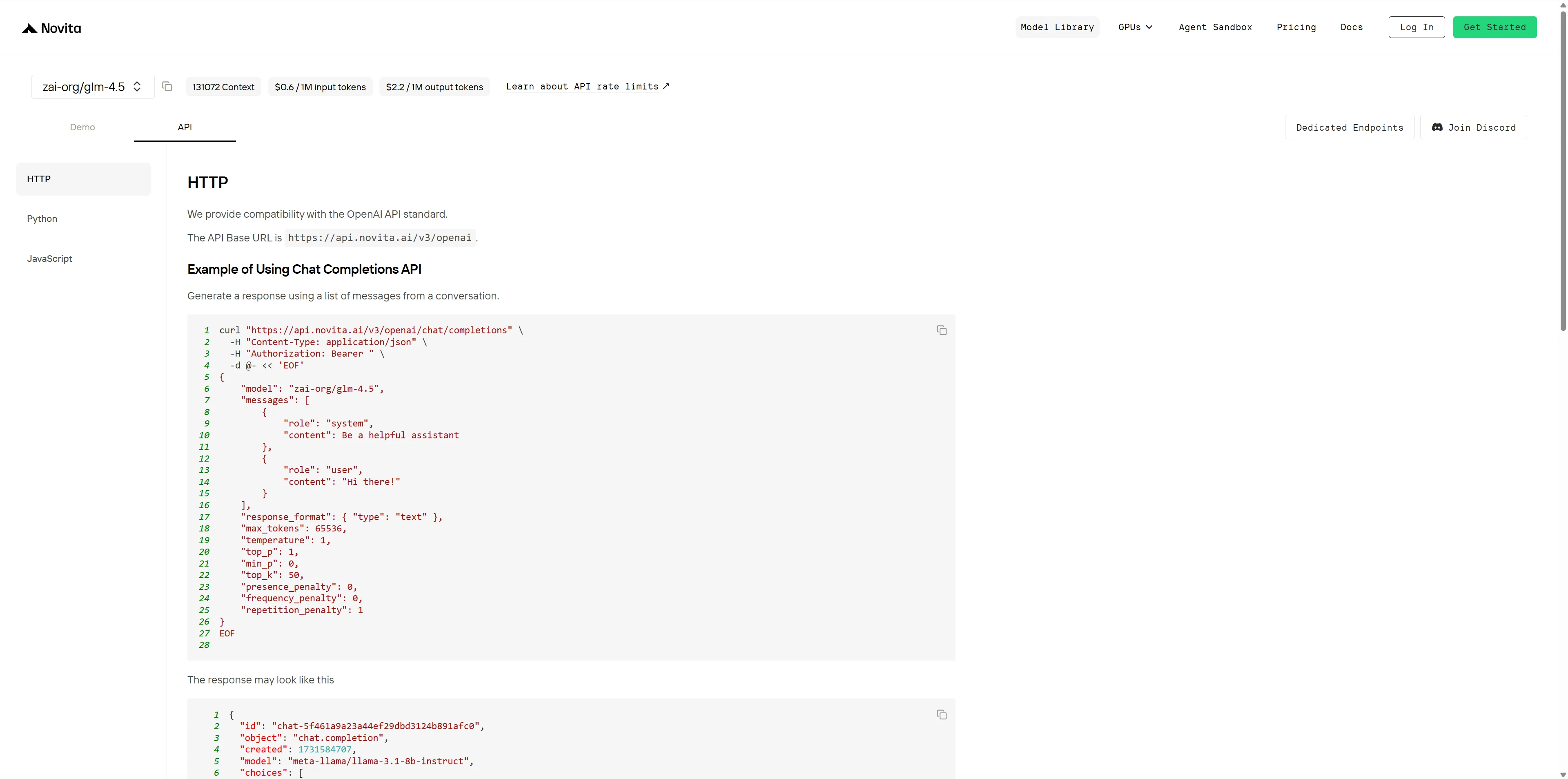
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Les deux modèles présentent des philosophies architecturales et des profils de capacités distincts, GLM-4.5 excellant dans le raisonnement systématique et l’innovation technique tandis que ChatGPT-4.1 démontre une fluidité linguistique et un engagement utilisateur supérieurs - représentant des approches complémentaires de la conception de systèmes d’IA avancés plutôt que des alternatives concurrentielles directes.
GLM-4.5 est un modèle de fondation de 355 milliards de paramètres spécialement conçu pour les applications d’agent intelligent, doté d’une architecture de raisonnement hybride unique avec deux modes de fonctionnement. Avec 32 milliards de paramètres actifs et une fenêtre de contexte de 128 000 tokens, le modèle unifie le raisonnement, le codage et les capacités d’agent sous une licence open source MIT. Son architecture distinctive de mode réflexion/non-réflexion permet à la fois un raisonnement délibératif complexe et une génération rapide de réponses, le positionnant comme une solution spécialisée pour les scénarios de déploiement d’agents en entreprise.
Essayez GLM-4.5 gratuitement !
Questions fréquemment posées
Que signifie GLM ?
GLM signifie « General Language Model », représentant une famille de grands modèles de langage développés par Zhipu AI qui met l’accent sur la compréhension et la génération de langage naturel à usage général.
GPT-4.1 est-il un modèle de réflexion ?
GPT-4.1 n’est pas un modèle de « réflexion » au sens humain. Il prédit des réponses plutôt que de réellement penser.
Comment ajuster un modèle GLM ?
Les modèles GLM peuvent être déployés via les API officielles sur des plateformes comme Novita AI, avec des instructions de configuration spécifiques variant selon la version du modèle et les exigences matérielles.
À propos de Novita AI
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



