

部署像 PaddleOCR-VL-1.5 这样的前沿 OCR 模型可能让人不知所措——开发者面临着模糊的硬件需求、复杂的环境搭建以及 GPU 成本的不确定性。PaddleOCR-VL-1.5 是百度最新推出的视觉语言模型,在 OmniDocBench v1.5 上达到了 94.5% 的准确率,该模型需要精确的部署配置才能发挥最佳性能。
本指南将带你逐步完成在 Novita AI GPU 实例上部署 PaddleOCR-VL-1.5 的全过程,从选择合适 GPU 到在生产环境中运行推理。内容涵盖 Docker 镜像设置、环境配置、GPU 选择以及实际成本分析。
PaddleOCR-VL-1.5 是什么?
PaddleOCR-VL-1.5 是百度下一代视觉语言模型,针对文档解析、OCR 和版面理解进行了优化。该模型拥有 0.9B 参数,在提供企业级精度的同时,仍可在消费级 GPU 上部署。
| 规格 | 值 |
|---|---|
| 模型类型 | 视觉-语言模型 (VLM) |
| 参数量 | 0.9B |
| 上下文窗口 | 131,072 tokens |
| 精度 | bfloat16 |
| OmniDocBench v1.5 准确率 | 94.5% |
| 基础模型 | ERNIE-4.5-0.3B-Paddle |
关键能力
PaddleOCR-VL-1.5 引入了文档 AI 领域的重要功能:
- 不规则形状检测: 针对倾斜和扭曲文档的多边形定位——可处理扫描伪影、屏幕拍摄和光照变化,已在 Real5-OmniDocBench 基准上验证。
- 增强的元素识别: 与上一代模型相比,在表格、公式和文本识别方面有显著提升。
- 印章与文字检测: 原生支持印章识别和文字检测任务——对法律和政府文档处理至关重要。
- 多语言支持: 在英语、中文及多语言数据集上训练。
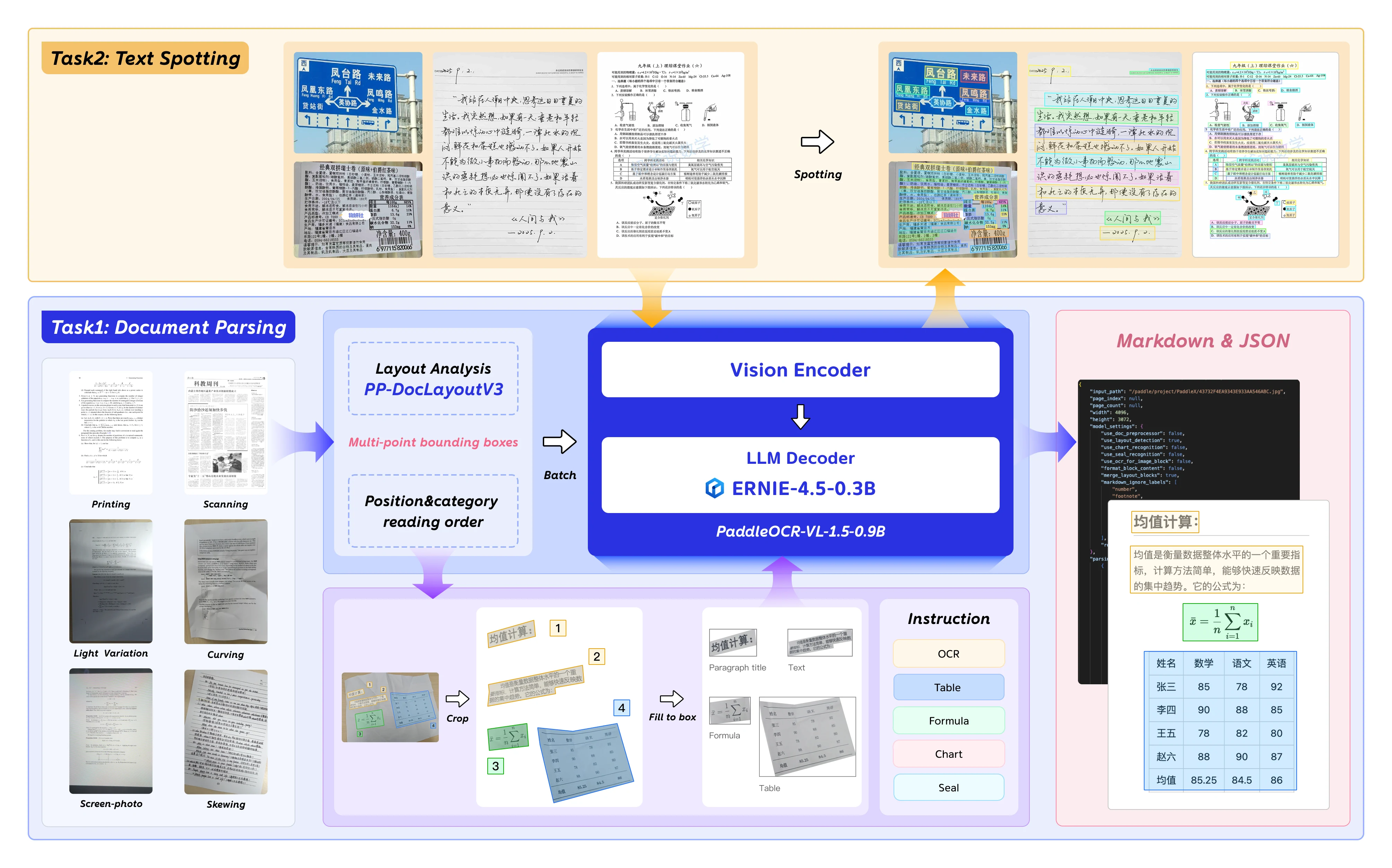
来自 Hugging Face
为什么在 Novita AI GPU 实例上部署?
Novita AI GPU 实例为部署 PaddleOCR-VL-1.5 提供了理想环境,具有以下几个关键优势:
- 预配置 CUDA 环境: Novita 模板支持 PaddlePaddle 3.1.0/3.1.1 所需的 CUDA 11.x 和 12.x。
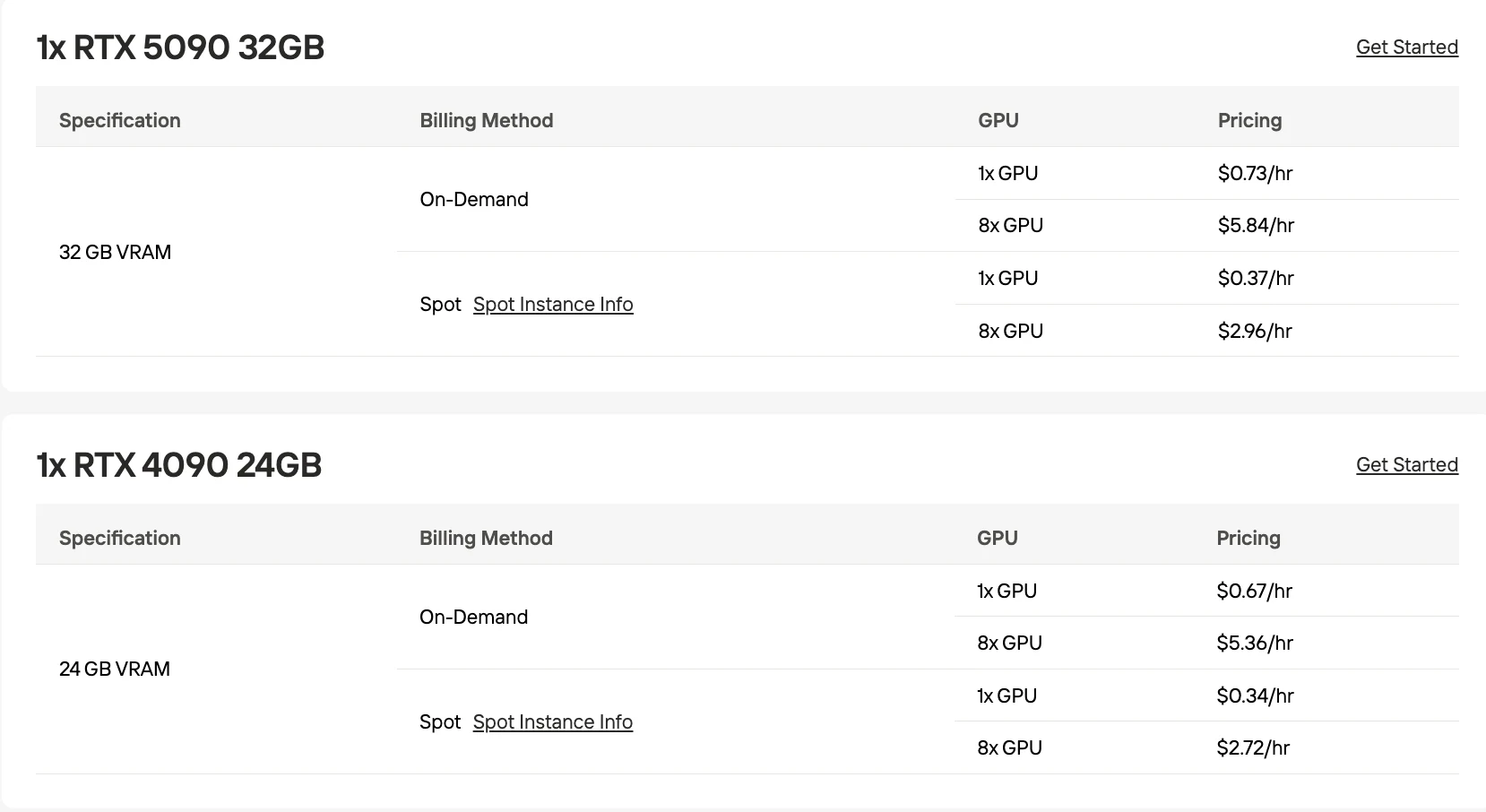
- 高性价比 GPU 选项: RTX 5090 32GB 按需价格 $0.73/小时。
- 灵活扩展: 按需和竞价实例均采用按需付费定价——可从单 GPU 扩展到 8×GPU 集群。
- 原生 Docker 部署: 支持自定义镜像及公有/私有仓库,无需复杂环境搭建。
- 网络卷存储: $0.002/GB/天的网络卷,可在实例间持久化存储模型。
在 Novita GPU 模板上部署 PaddleOCR-VL-1.5
步骤 1:控制台入口
启动 GPU 界面,选择 Get Started 进入部署管理。
步骤 2:选择模板
在模板仓库中找到 PaddleOCR-VL-1.5,并开始安装流程。
步骤 3:基础设施设置
配置计算参数,包括内存分配、存储需求和网络设置。选择 Deploy 开始部署。
步骤 4:检查并创建
再次核对配置详情和成本摘要。确认无误后,点击 Deploy 开始创建过程。
Novita AI 的竞价模式是一种成本优化的 GPU 租用系统,利用平台上的空闲或未使用 GPU 容量。与按需实例不同,竞价实例是可中断的——如果系统回收 GPU,你的任务可能会被暂停或终止。由于竞价模式重新分配了原本闲置的 GPU 资源,其价格通常比按需定价便宜 40–60%。
步骤 5:等待创建
启动部署后,系统会自动将你重定向到实例管理页面。你的实例将在后台创建。
步骤 6:监控下载进度
实时跟踪镜像下载进度。实例状态将从 Pulling 变为 Running,表示部署完成。点击实例名称旁的箭头图标可查看详细信息。
步骤 7:验证实例状态
点击日志按钮查看实例日志,确认 PaddleOCR 服务已正确启动。
步骤 8:环境访问
通过 Connect 界面启动开发空间,然后初始化 Start Web Terminal。
以下是一个 Python 测试用例。
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
下载示例图片并运行测试脚本:
# Download sample image for testing
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copy port mapping address and replace API_URL in test.py, then run:
python test.py
# Expected output:
# Markdown document saved at markdown_0/doc.md
# Output image saved at layout_det_res_0.jpg
优化在 Novita GPU 模板上部署 PaddleOCR-VL-1.5
批量处理配置
AMD 部署指南推荐 batch_size: 64 以优化吞吐量。请根据你的 GPU 进行调整:
| GPU | 推荐批次大小 | 吞吐量(文档/分钟) |
|---|---|---|
| RTX 5090 32GB | 32-48 | ~120-150 |
| RTX 4090 24GB | 24-32 | ~90-120 |
| H100 80GB | 64-96 | ~250-350 |
版面检测设置
对于包含表格、公式和图表的复杂文档,启用 use_layout_detection: True。对于纯文本文档,禁用该功能可减少 30-40% 的延迟。
常见问题排障
问题 1:模型下载超时
现象: 容器启动失败,显示 “Connection timeout to huggingface.co”
解决方案: 将模型预下载到 Novita 网络卷并挂载:
# On a temporary instance:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# In Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
问题 2:内存不足错误
现象: 推理过程中出现 CUDA out of memory
解决方案: 在配置中减小 batch_size:
batch_size: 16 # Down from 64
gpu_memory_utilization: 0.85 # Leave 15% headroom
问题 3:复杂文档推理缓慢
现象: 每个文档处理时间超过 5 秒
解决方案: 根据 AMD 优化指南禁用不必要的功能:
- 对于纯文本文档,设置
use_layout_detection: False(提速 30-40%) - 如果需要原始元素位置,设置
merge_layout_blocks: False - 升级到 H100 SXM 80GB,复杂版面的吞吐量可提升 2-3 倍
在 Novita AI GPU 实例上部署 PaddleOCR-VL-1.5 可实现生产级文档解析。 0.9B 参数的高效性与 Novita 灵活的 GPU 定价相结合,使初创企业和大公司能够每月处理数百万文档,而不会超出预算。
结论
在 Novita AI GPU 模板上部署 PaddleOCR-VL-1.5,你可以在几分钟内获得企业级文档解析能力——无需复杂的环境搭建,无需闲置的 GPU 成本。凭借 0.9B 参数、OmniDocBench v1.5 上 94.5% 的准确率以及低至 $0.73/小时的灵活 GPU 选项,它是需要大规模处理高负载文档的团队的高效解决方案。
核心要点: 根据吞吐量需求选择 GPU 层级,在生产工作负载中启用批处理,并使用竞价实例将成本降低 40–60%。立即在 Novita AI 上开始 部署 PaddleOCR-VL-1.5。
运行 PaddleOCR-VL-1.5 需要什么 GPU?
PaddleOCR-VL-1.5 可在任何 8GB 以上显存的 GPU 上运行;生产环境推荐使用 RTX 5090 32GB($0.73/小时)。
PaddleOCR-VL-1.5 能处理带有变形的扫描文档吗?
可以。PaddleOCR-VL-1.5 的不规则形状检测 能够处理倾斜、扭曲和扫描伪影,已在 Real5-OmniDocBench 基准上得到验证。
PaddleOCR-VL-1.5 适合生产使用吗?
是的。凭借 0.9B 参数和 94.5% 的准确率,它在性能与效率之间达到了良好平衡,非常适合企业文档处理流水线。
Novita AI 是一个 AI 与智能体云平台,帮助开发者和初创公司构建、部署和扩展模型及智能体应用,提供高性能、高可靠性和高性价比。
延伸阅读
DeepSeek vs Qwen:识别哪个生态系统适合生产需求



