

Déployer des modèles OCR de pointe comme PaddleOCR-VL-1.5 peut être décourageant : les développeurs font face à des exigences matérielles peu claires, une configuration d’environnement complexe et une incertitude sur les coûts des GPU. PaddleOCR-VL-1.5, le modèle vision-langue de pointe de Baidu atteignant 94,5 % de précision sur OmniDocBench v1.5, nécessite des configurations de déploiement précises pour des performances optimales.
Ce guide vous accompagne pas à pas dans le déploiement de PaddleOCR-VL-1.5 sur les instances GPU de Novita AI, de la sélection du GPU adapté à l’exécution d’inférence en production. Nous couvrons la configuration de l’image Docker, la configuration de l’environnement, la sélection du GPU et une analyse des coûts réels.
Qu’est-ce que PaddleOCR-VL-1.5 ?
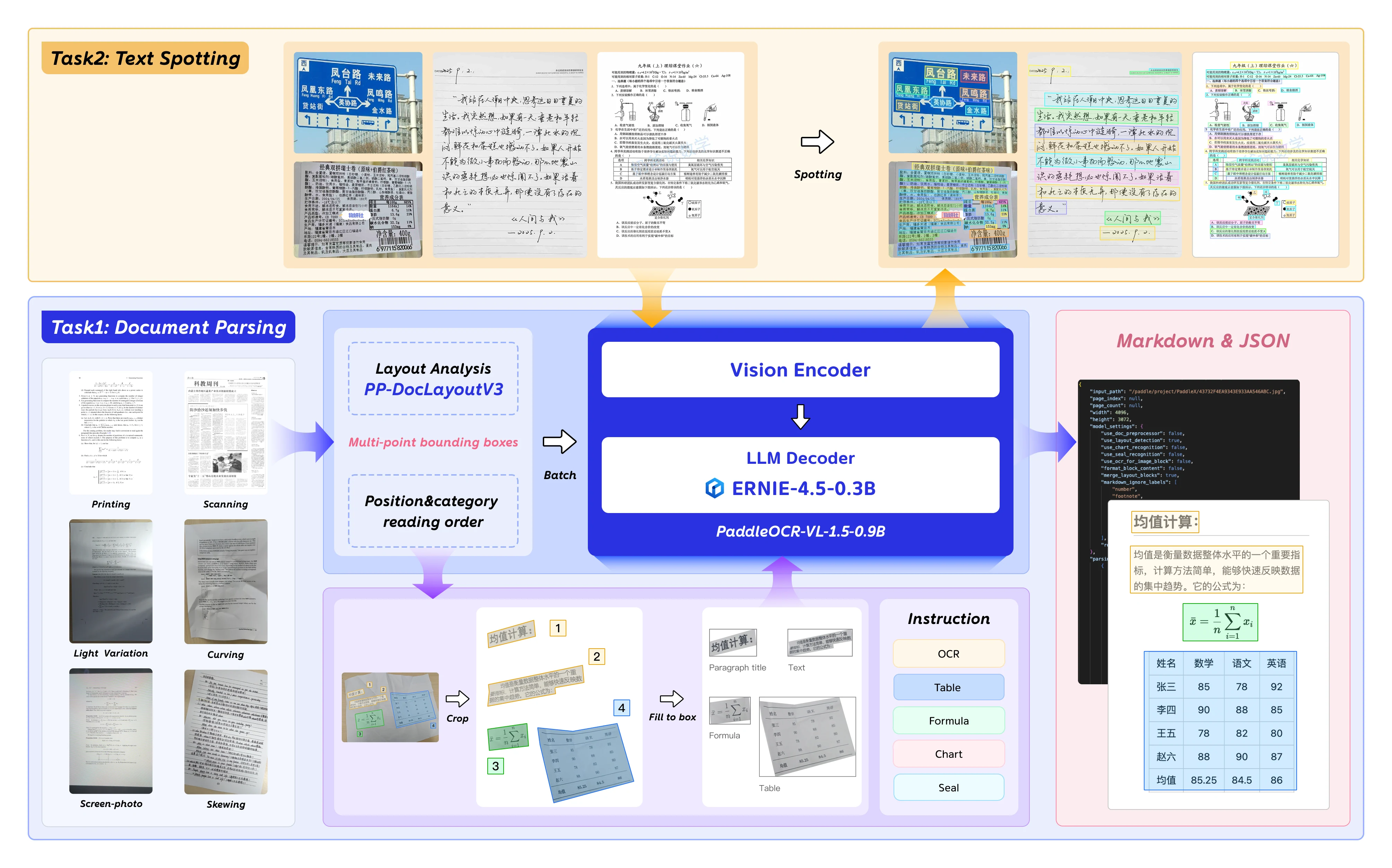
PaddleOCR-VL-1.5 est le modèle vision-langue de nouvelle génération de Baidu, optimisé pour l’analyse de documents, l’OCR et la compréhension de la mise en page. Avec 0,9 milliard de paramètres, il offre une précision adaptée aux entreprises tout en restant déployable sur des GPU grand public.
| Spécification | Valeur |
|---|---|
| Type de modèle | Vision-langue (VLM) |
| Paramètres | 0,9B |
| Fenêtre de contexte | 131 072 tokens |
| Précision | bfloat16 |
| OmniDocBench v1.5 | 94,5 % de précision |
| Modèle de base | ERNIE-4.5-0.3B-Paddle |
Fonctionnalités clés
PaddleOCR-VL-1.5 introduit des fonctionnalités notables pour l’IA documentaire :
- Détection de formes irrégulières : Localisation polygonale pour les documents inclinés et déformés — gère les artefacts de numérisation, les photos prises sur écran et les variations d’éclairage, testé sur le benchmark Real5-OmniDocBench.
- Reconnaissance améliorée des éléments : Améliorations significatives de la reconnaissance des tableaux, des formules et du texte par rapport aux modèles précédents.
- Reconnaissance de sceaux et détection de texte : Prise en charge native des tâches de reconnaissance de sceaux et de détection de texte, essentielles pour le traitement des documents juridiques et administratifs.
- Prise en charge multilingue : Entraîné sur des jeux de données en anglais, chinois et multilingues.
Source : Hugging Face
Pourquoi déployer sur les instances GPU de Novita AI ?
Les instances GPU de Novita AI offrent un environnement optimal pour le déploiement de PaddleOCR-VL-1.5 avec plusieurs avantages critiques :
- Environnement CUDA préconfiguré : Les modèles Novita prennent en charge CUDA 11.x et 12.x requis par PaddlePaddle 3.1.0/3.1.1.
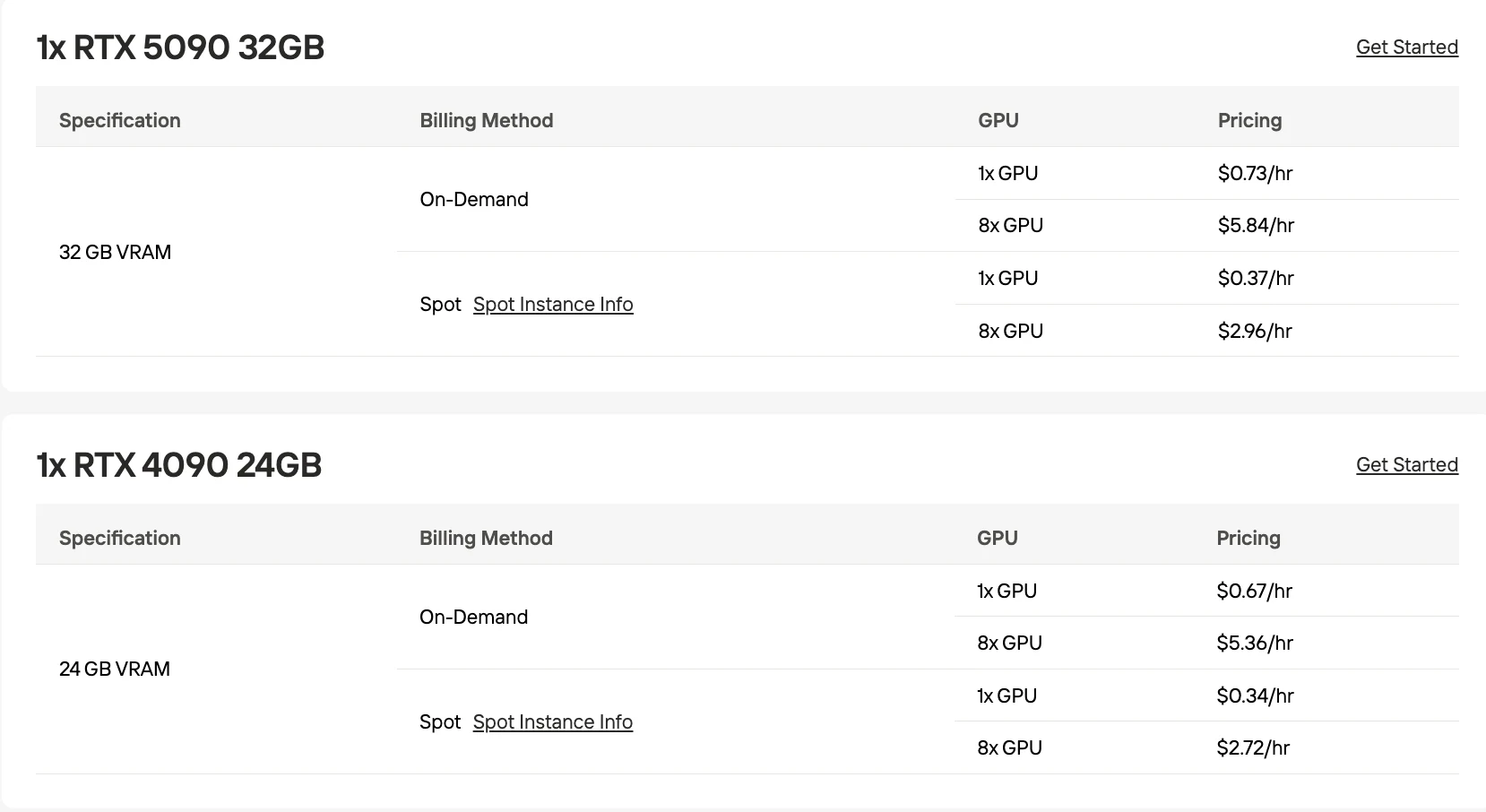
- Options GPU rentables : RTX 5090 32GB à 0,73 $/h en demande à la demande.
- Mise à l’échelle flexible : Tarification à l’usage avec instances à la demande et Spot — passez d’un seul GPU à des clusters de 8×GPU.
- Déploiement natif Docker : La prise en charge d’images personnalisées avec des registres publics/privés élimine la complexité de la configuration de l’environnement.
- Stockage sur volume réseau : 0,002 $/Go/jour pour les volumes réseau de stockage persistant des modèles entre les instances.
Essayez un GPU rentable dès maintenant !
Déployer PaddleOCR-VL-1.5 sur le modèle GPU Novita
Étape 1 : Accès à la console
Lancez l’interface GPU et sélectionnez Commencer pour accéder à la gestion des déploiements.
Étape 2 : Sélection du package
Localisez PaddleOCR-VL-1.5 dans le référentiel de modèles et lancez la séquence d’installation.
Étape 3 : Configuration de l’infrastructure
Configurez les paramètres de calcul, notamment l’allocation de mémoire, les exigences de stockage et les paramètres réseau. Sélectionnez Déployer pour lancer la mise en œuvre.
Étape 4 : Vérification et création
Vérifiez une dernière fois les détails de votre configuration et le récapitulatif des coûts. Lorsque vous êtes satisfait, cliquez sur Déployer pour lancer le processus de création.
Essayez un GPU rentable dès maintenant !
Le mode Spot de Novita AI est un système de location de GPU optimisé pour les coûts qui exploite la capacité GPU inactive ou inutilisée de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation continue et stable, les instances Spot sont interruptibles : votre tâche peut être mise en pause ou terminée si le GPU est récupéré par le système. Comme le mode Spot réalloue des ressources GPU qui seraient autrement inactives, il est généralement 40 à 60 % moins cher que la tarification à la demande.
Étape 5 : Attente de la création
Après avoir lancé le déploiement, le système vous redirigera automatiquement vers la page de gestion des instances. Votre instance sera créée en arrière-plan.
Étape 6 : Suivi de la progression du téléchargement
Suivez la progression du téléchargement de l’image en temps réel. L’état de votre instance passera de Pulling à Running une fois le déploiement terminé. Vous pouvez consulter la progression détaillée en cliquant sur l’icône de flèche à côté du nom de votre instance.
Étape 7 : Vérification de l’état de l’instance
Cliquez sur le bouton Logs pour consulter les journaux de l’instance et confirmer que le service PaddleOCR a démarré correctement.
Étape 8 : Accès à l’environnement
Lancez l’espace de développement via l’interface de connexion, puis initialisez le terminal web en sélectionnant Start Web Terminal.
Ceci est un cas de test Python.
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
Téléchargez l’image exemple et exécutez le script de test :
# Download sample image for testing
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copy port mapping address and replace API_URL in test.py, then run:
python test.py
# Expected output:
# Markdown document saved at markdown_0/doc.md
# Output image saved at layout_det_res_0.jpg
Optimiser le déploiement de PaddleOCR-VL-1.5 sur le modèle GPU Novita
Configuration du traitement par lots
Le guide de déploiement AMD recommande un batch_size de 64 pour l’optimisation du débit. Ajustez ce paramètre en fonction de votre GPU :
| GPU | Taille de lot recommandée | Débit (docs/min) |
|---|---|---|
| RTX 5090 32GB | 32-48 | ~120-150 |
| RTX 4090 24GB | 24-32 | ~90-120 |
| H100 80GB | 64-96 | ~250-350 |
Paramètres de détection de mise en page
Activez use_layout_detection: True pour les documents complexes contenant des tableaux, des formules et des graphiques. Désactivez-le pour les documents en texte brut pour réduire la latence de 30 à 40 %.
Résolution des problèmes courants
Problème 1 : Délai de téléchargement du modèle dépassé
Symptôme : Le conteneur ne démarre pas avec le message « Connection timeout to huggingface.co »
Solution : Préchargez le modèle sur un volume réseau Novita et montez-le :
# On a temporary instance:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# In Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
Problème 2 : Erreurs de mémoire insuffisante
Symptôme : Erreur CUDA out of memory pendant l’inférence
Solution : Réduisez le paramètre batch_size dans votre configuration :
batch_size: 16 # Down from 64
gpu_memory_utilization: 0.85 # Leave 15% headroom
Problème 3 : Inférence lente sur des documents complexes
Symptôme : Temps de traitement supérieur à 5 secondes par document
Solution : Désactivez les fonctionnalités inutiles conformément au guide d’optimisation AMD :
- Définissez
use_layout_detection: Falsepour les documents en texte brut (30 à 40 % plus rapide) - Définissez
merge_layout_blocks: Falsesi vous avez besoin des positions brutes des éléments - Passez à un H100 SXM 80GB pour un débit 2 à 3 fois plus élevé sur des mises en page complexes
Déployer PaddleOCR-VL-1.5 sur les instances GPU de Novita AI permet d’obtenir une analyse de documents de qualité production. La combinaison de l’efficacité des 0,9 milliard de paramètres et de la tarification flexible des GPU Novita permet aux startups et aux entreprises de traiter des millions de documents par mois sans dépasser leur budget.
Conclusion
Déployer PaddleOCR-VL-1.5 sur les modèles GPU Novita AI vous permet d’obtenir une analyse de documents de qualité entreprise en quelques minutes — pas de configuration d’environnement complexe, pas de coûts de GPU inutilisés. Avec 0,9 milliard de paramètres, une précision de 94,5 % sur OmniDocBench v1.5 et des options GPU flexibles à partir de 0,73 $/h, c’est une solution efficace pour les équipes traitant des volumes élevés de documents à grande échelle.
Point clé : Sélectionnez votre catégorie de GPU en fonction de vos besoins de débit, activez le traitement par lots pour les charges de travail de production et utilisez les instances Spot pour réduire vos coûts de 40 à 60 %. Commencez sur Novita AI et déployez PaddleOCR-VL-1.5 dès aujourd’hui.
Quel GPU est nécessaire pour exécuter PaddleOCR-VL-1.5 ?
PaddleOCR-VL-1.5 fonctionne sur tout GPU avec au moins 8 Go de VRAM ; le RTX 5090 32GB à 0,73 $/h est recommandé pour la production.
PaddleOCR-VL-1.5 peut-il traiter des documents numérisés avec des distorsions ?
Oui, la détection de formes irrégulières de PaddleOCR-VL-1.5 gère l’inclinaison, la déformation et les artefacts de numérisation, validés sur le benchmark Real5-OmniDocBench.
PaddleOCR-VL-1.5 est-il adapté à un usage en production ?
Oui. Avec 0,9 milliard de paramètres et une précision de 94,5 %, il offre un excellent équilibre entre performance et efficacité, ce qui le rend adapté aux chaînes de traitement de documents d’entreprise.
Novita AI est une plateforme cloud IA et d’agents qui aide les développeurs et les startups à créer, déployer et mettre à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une efficacité des coûts.
Lectures recommandées
DeepSeek vs Qwen : Identifiez quel écosystème correspond aux besoins de production
DeepSeek vs Qwen : Identifiez quel écosystème correspond aux besoins de production



