

최첨단 OCR 모델인 PaddleOCR-VL-1.5를 배포하는 것은 부담스러울 수 있습니다. 개발자들은 불분명한 하드웨어 요구 사항, 복잡한 환경 설정, GPU 비용에 대한 불확실성에 직면합니다. PaddleOCR-VL-1.5는 바이두의 최신 비전-언어 모델로, OmniDocBench v1.5에서 94.5%의 정확도를 달성하며 최적의 성능을 위해 정확한 배포 구성이 필요합니다.
이 가이드는 적합한 GPU 선택부터 프로덕션 환경에서 추론 실행까지 Novita AI의 GPU 인스턴스에서 PaddleOCR-VL-1.5를 배포하는 전체 과정을 설명합니다. Docker 이미지 설정, 환경 구성, GPU 선택, 실제 비용 분석을 다룹니다.
PaddleOCR-VL-1.5란 무엇인가?
PaddleOCR-VL-1.5는 문서 파싱, OCR, 레이아웃 이해에 최적화된 바이두의 차세대 비전-언어 모델입니다. 0.9B 파라미터로 엔터프라이즈급 정확도를 제공하면서도 일반 소비자용 GPU에 배포할 수 있습니다.
| 사양 | 값 |
|---|---|
| 모델 유형 | 비전-언어 (VLM) |
| 파라미터 | 0.9B |
| 컨텍스트 윈도우 | 131,072 토큰 |
| 정밀도 | bfloat16 |
| OmniDocBench v1.5 | 94.5% 정확도 |
| 기본 모델 | ERNIE-4.5-0.3B-Paddle |
주요 기능
PaddleOCR-VL-1.5는 문서 AI를 위한 주목할 만한 기능을 도입했습니다:
- 불규칙한 형태 탐지: 기울어지고 뒤틀린 문서의 다각형 지역화 — 스캔 아티팩트, 스크린 사진, 조명 변화를 Real5-OmniDocBench 벤치마크에서 테스트하여 처리합니다.
- 향상된 요소 인식: 이전 모델 대비 표, 수식, 텍스트 인식에서 상당한 개선.
- 도장 및 텍스트 스포팅: 도장 인식 및 텍스트 스포팅 작업에 대한 기본 지원 — 법률 및 정부 문서 처리에 필수적.
- 다국어 지원: 영어, 중국어 및 다국어 데이터셋으로 훈련됨.
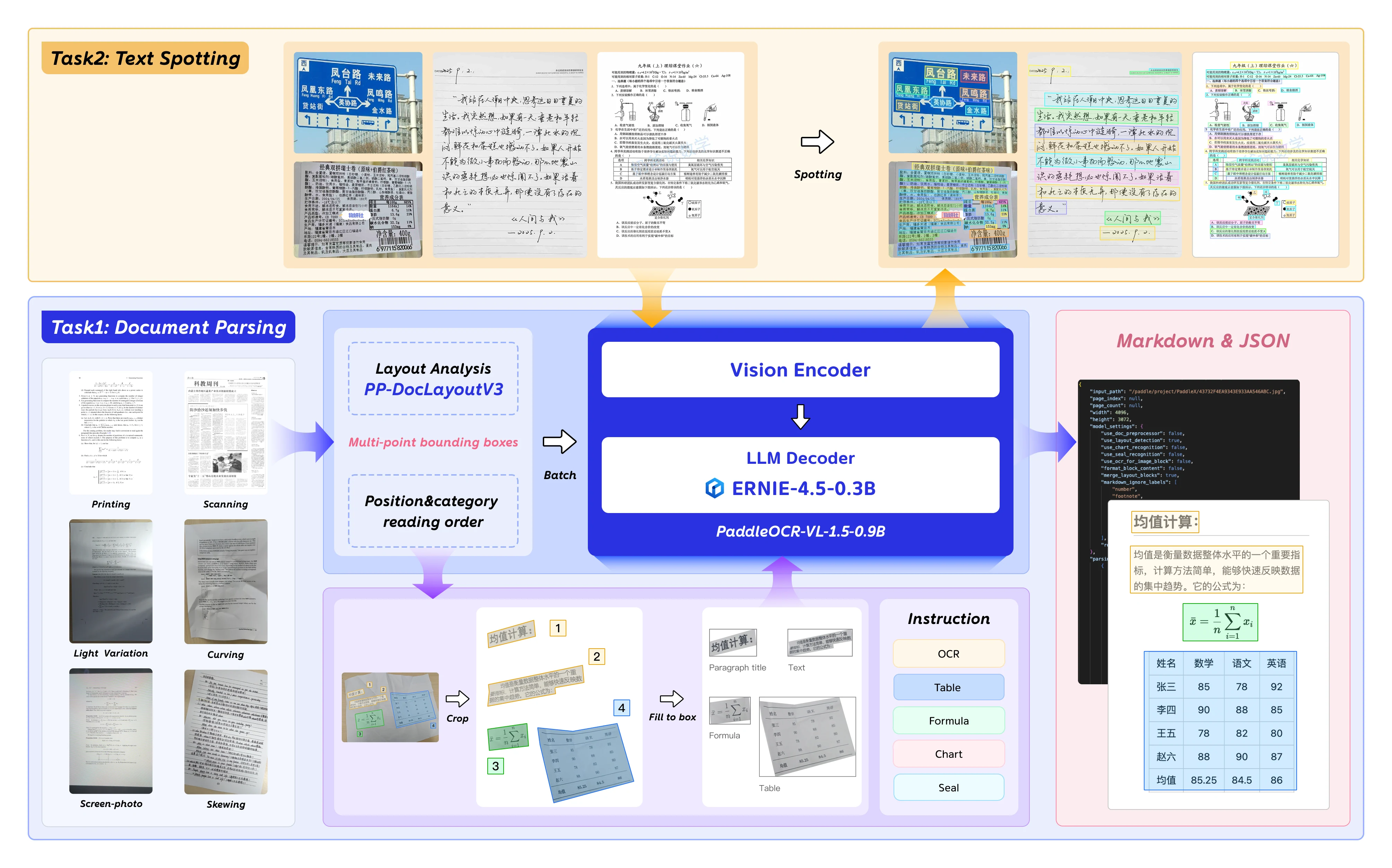
Hugging Face 출처
Novita AI GPU 인스턴스에 배포해야 하는 이유
Novita AI GPU 인스턴스는 PaddleOCR-VL-1.5 배포에 최적의 환경을 제공하며 몇 가지 중요한 장점이 있습니다:
- 사전 구성된 CUDA 환경: Novita 템플릿은 PaddlePaddle 3.1.0/3.1.1에서 필요한 CUDA 11.x 및 12.x를 지원합니다.
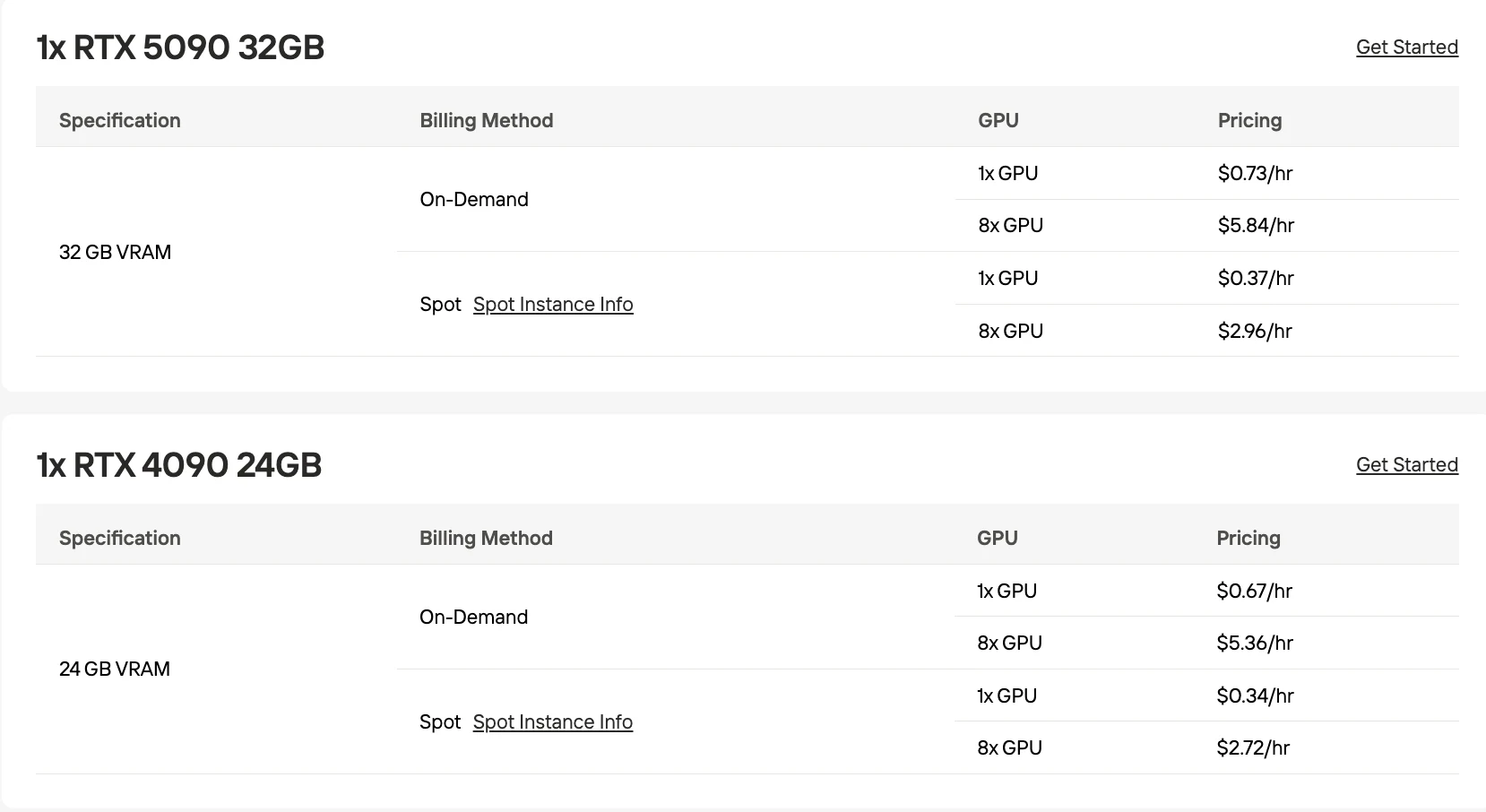
- 비용 효율적인 GPU 옵션: RTX 5090 32GB 온디맨드 시간당 $0.73.
- 유연한 확장: 종량제 가격 책정과 온디맨드 및 스팟 인스턴스 — 단일 GPU에서 8×GPU 클러스터까지 확장 가능.
- Docker 기본 배포: 공개/비공개 레지스트리를 지원하는 사용자 정의 이미지로 환경 설정 복잡성 제거.
- 네트워크 볼륨 스토리지: 인스턴스 간 지속적인 모델 저장을 위한 $0.002/GB/일 네트워크 볼륨.
Novita GPU 템플릿에서 PaddleOCR-VL-1.5 배포하기
1단계: 콘솔 진입
GPU 인터페이스를 실행하고 Get Started를 선택하여 배포 관리에 접속합니다.
2단계: 패키지 선택
템플릿 저장소에서 PaddleOCR-VL-1.5를 찾아 설치 시퀀스를 시작합니다.
3단계: 인프라 설정
메모리 할당, 스토리지 요구 사항, 네트워크 설정 등의 컴퓨팅 파라미터를 구성합니다. Deploy를 선택하여 구현합니다.
4단계: 검토 및 생성
구성 세부 정보와 비용 요약을 다시 확인합니다. 만족하면 Deploy를 클릭하여 생성 프로세스를 시작합니다.
Novita AI의 스팟 모드는 플랫폼의 유휴 또는 미사용 GPU 용량을 활용하는 비용 최적화된 GPU 임대 시스템입니다. 안정적인 지속 사용을 위해 전용 하드웨어를 예약하는 온디맨드 인스턴스와 달리, 스팟 인스턴스는 중단 가능합니다—GPU가 시스템에 의해 회수되면 작업이 일시 중지되거나 종료될 수 있습니다. 스팟 모드는 유휴 GPU 리소스를 재할당하기 때문에 일반적으로 온디맨드 가격보다 40~60% 저렴합니다.
5단계: 생성 대기
배포를 시작한 후 시스템이 자동으로 인스턴스 관리 페이지로 리디렉션합니다. 인스턴스는 백그라운드에서 생성됩니다.
6단계: 다운로드 진행 상황 모니터링
이미지 다운로드 진행 상황을 실시간으로 추적합니다. 배포가 완료되면 인스턴스 상태가 Pulling에서 Running으로 변경됩니다. 인스턴스 이름 옆의 화살표 아이콘을 클릭하여 자세한 진행 상황을 볼 수 있습니다.
7단계: 인스턴스 상태 확인
Logs 버튼을 클릭하여 인스턴스 로그를 확인하고 PaddleOCR 서비스가 올바르게 시작되었는지 확인합니다.
8단계: 환경 접근
Connect 인터페이스를 통해 개발 공간을 실행한 다음 Start Web Terminal을 초기화합니다.
다음은 Python 테스트 케이스입니다.
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
샘플 이미지를 다운로드하고 테스트 스크립트를 실행합니다:
# Download sample image for testing
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copy port mapping address and replace API_URL in test.py, then run:
python test.py
# Expected output:
# Markdown document saved at markdown_0/doc.md
# Output image saved at layout_det_res_0.jpg
Novita GPU 템플릿에서 PaddleOCR-VL-1.5 배포 최적화
배치 처리 구성
AMD 배포 가이드에서는 처리량 최적화를 위해 batch_size: 64를 권장합니다. GPU에 따라 조정하세요:
| GPU | 권장 배치 크기 | 처리량 (문서/분) |
|---|---|---|
| RTX 5090 32GB | 32-48 | ~120-150 |
| RTX 4090 24GB | 24-32 | ~90-120 |
| H100 80GB | 64-96 | ~250-350 |
레이아웃 탐지 설정
표, 수식, 차트가 포함된 복잡한 문서의 경우 use_layout_detection: True를 활성화하세요. 일반 텍스트 문서의 경우 비활성화하여 지연 시간을 30-40% 줄일 수 있습니다.
일반적인 문제 해결
문제 1: 모델 다운로드 시간 초과
증상: 컨테이너가 “Connection timeout to huggingface.co” 오류로 시작 실패
해결 방법: Novita 네트워크 볼륨에 모델을 미리 다운로드하고 마운트하세요:
# On a temporary instance:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# In Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
문제 2: 메모리 부족 오류
증상: 추론 중 CUDA out of memory
해결 방법: 구성에서 batch_size를 줄이세요:
batch_size: 16 # Down from 64
gpu_memory_utilization: 0.85 # Leave 15% headroom
문제 3: 복잡한 문서에서 느린 추론
증상: 문서당 처리 시간 5초 초과
해결 방법: AMD 최적화 가이드에 따라 불필요한 기능을 비활성화하세요:
- 일반 텍스트 문서의 경우
use_layout_detection: False설정 (30-40% 더 빠름) - 원시 요소 위치가 필요한 경우
merge_layout_blocks: False설정 - 복잡한 레이아웃의 경우 H100 SXM 80GB로 업그레이드하여 2-3배 높은 처리량 달성
Novita AI GPU 인스턴스에 PaddleOCR-VL-1.5를 배포하면 프로덕션 수준의 문서 파싱이 가능합니다. 0.9B 파라미터 효율성과 Novita의 유연한 GPU 가격 책정 덕분에 스타트업과 기업 모두 예산을 초과하지 않고 매달 수백만 개의 문서를 처리할 수 있습니다.
결론
Novita AI GPU 템플릿에 PaddleOCR-VL-1.5를 배포하면 몇 분 만에 엔터프라이즈급 문서 파싱이 가능합니다. 복잡한 환경 설정이나 유휴 GPU 비용이 들지 않습니다. 0.9B 파라미터, OmniDocBench v1.5에서 94.5% 정확도, 시간당 $0.73부터 시작하는 유연한 GPU 옵션을 통해 대량의 문서를 확장하여 처리하는 팀에 효율적인 솔루션입니다.
핵심 요약: 처리량 요구 사항에 따라 GPU 등급을 선택하고, 프로덕션 워크로드에는 배치 처리를 활성화하며, 스팟 인스턴스를 사용하여 비용을 40~60% 절감하세요. Novita AI에서 시작하기 지금 PaddleOCR-VL-1.5를 배포하세요.
PaddleOCR-VL-1.5를 실행하려면 어떤 GPU가 필요한가요?
PaddleOCR-VL-1.5는 8GB 이상의 VRAM이 있는 모든 GPU에서 실행됩니다. 프로덕션 환경에서는 RTX 5090 32GB ($0.73/hr)를 권장합니다.
PaddleOCR-VL-1.5가 왜곡된 스캔 문서를 처리할 수 있나요?
예, PaddleOCR-VL-1.5의 불규칙한 형태 탐지는 Real5-OmniDocBench 벤치마크에서 검증된 기울기, 뒤틀림, 스캔 아티팩트를 처리합니다.
PaddleOCR-VL-1.5는 프로덕션 사용에 적합한가요?
예. 0.9B 파라미터와 94.5% 정확도로 성능과 효율성 사이의 강력한 균형을 제공하여 엔터프라이즈 문서 처리 파이프라인에 적합합니다.
Novita AI는 개발자와 스타트업이 고성능, 신뢰성, 비용 효율성으로 모델과 에이전트 애플리케이션을 구축, 배포, 확장할 수 있도록 지원하는 AI 및 에이전트 클라우드 플랫폼입니다.
추천 읽을거리
DeepSeek vs Qwen: Identify Which Ecosystem Fits Production Needs
DeepSeek vs Qwen: Identify Which Ecosystem Fits Production Needs



