

نشر نماذج التعرف الضوئي على الحروف (OCR) المتطورة مثل PaddleOCR-VL-1.5 قد يكون أمراً مرهقاً — حيث يواجه المطورون متطلبات أجهزة غير واضحة، وإعداد بيئة معقد، وعدم يقين بشأن تكاليف وحدات معالجة الرسوميات (GPU). يعد نموذج PaddleOCR-VL-1.5، وهو نموذج الرؤية واللغة المتطور من شركة Baidu الذي حقق دقة تبلغ 94.5% على معيار OmniDocBench v1.5، يتطلب تكوينات نشر دقيقة لتحقيق أداء أمثل.
يرشدك هذا الدليل خطوة بخطوة لنشر نموذج PaddleOCR-VL-1.5 على مثيلات وحدات معالجة الرسوميات (GPU) من Novita AI، بدءاً من اختيار وحدة المعالجة المناسبة وصولاً إلى تشغيل الاستدلال في بيئة الإنتاج. نحن نغطي إعداد صورة Docker، وتكوين البيئة، واختيار وحدة المعالجة، وتحليل التكاليف الفعلي.
ما هو نموذج PaddleOCR-VL-1.5؟
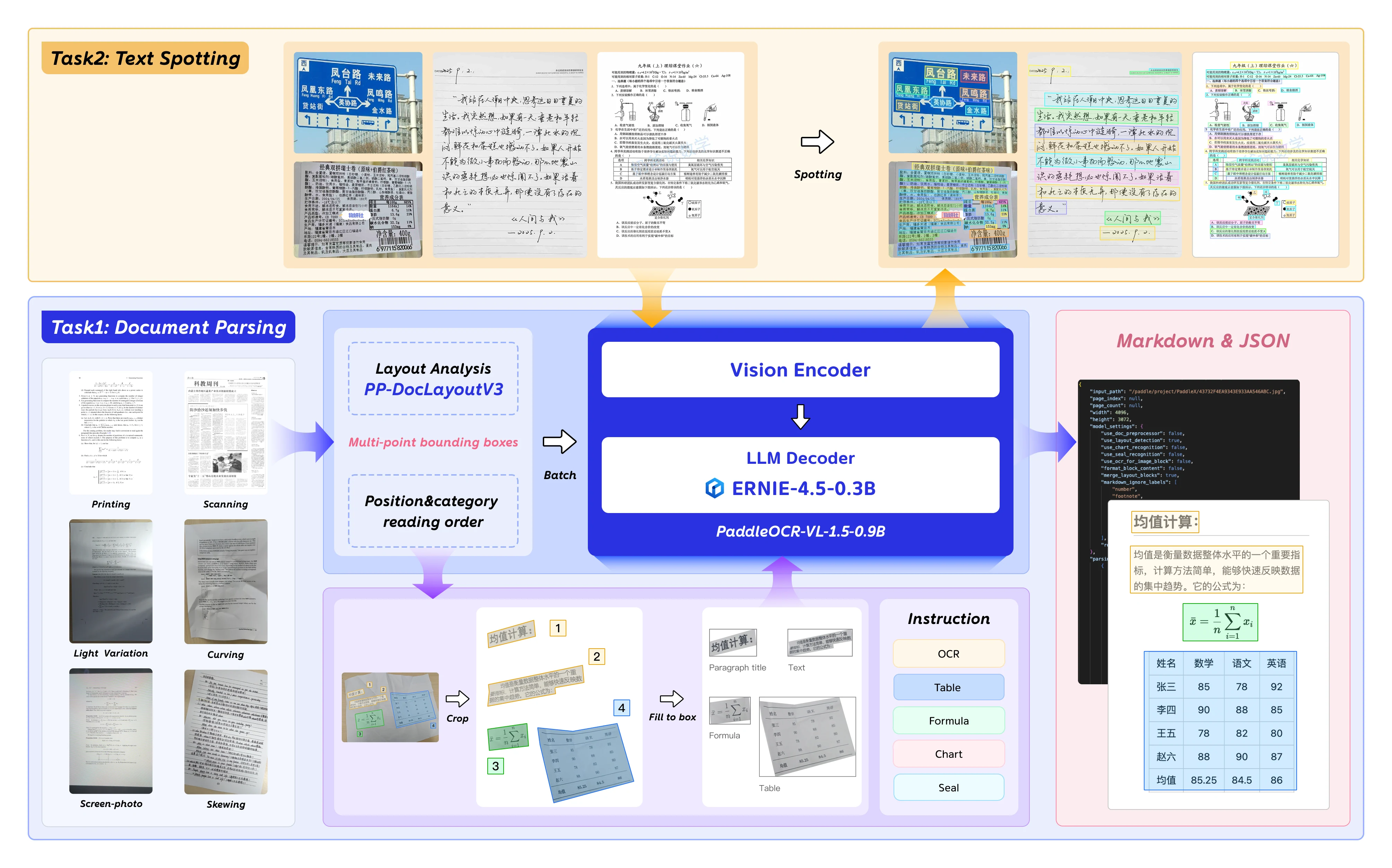
PaddleOCR-VL-1.5 هو نموذج الرؤية واللغة من الجيل التالي من شركة Baidu، محسّن لتحليل المستندات، والتعرف الضوئي على الحروف (OCR)، وفهم التخطيط. بمعاملات تبلغ 0.9 مليار، يقدم دقة على مستوى المؤسسات مع إمكانية نشره على وحدات معالجة الرسوميات (GPU) الاستهلاكية.
| المواصفات | القيمة |
|---|---|
| نوع النموذج | رؤية ولغة (VLM) |
| المعاملات | 0.9 مليار |
| نافذة السياق | 131,072 رمزاً |
| الدقة | bfloat16 |
| OmniDocBench v1.5 | دقة 94.5% |
| النموذج الأساسي | ERNIE-4.5-0.3B-Paddle |
القدرات الرئيسية
يقدم نموذج PaddleOCR-VL-1.5 ميزات ملحوظة للذكاء الاصطناعي للمستندات:
- الكشف عن الأشكال غير المنتظمة: تحديد موضع مضلع للمستندات المائلة والمشوهة — يتعامل مع عيوب المسح الضوئي، والتصوير بالشاشة، واختلافات الإضاءة التي تم اختبارها على معيار Real5-OmniDocBench.
- تحسين التعرف على العناصر: تحسينات كبيرة في التعرف على الجداول، والصيغ، والنصوص مقارنة بالنماذج السابقة.
- التعرف على الأختام وتحديد النصوص: دعم أصلي لمهام التعرف على الأختام وتحديد النصوص — أمر بالغ الأهمية لمعالجة المستندات القانونية والحكومية.
- دعم متعدد اللغات: مدرب على مجموعات بيانات باللغة الإنجليزية، والصينية، ومتعددة اللغات.
من منصة Hugging Face
لماذا تنشر على مثيلات وحدات معالجة الرسوميات (GPU) من Novita AI؟
توفر مثيلات وحدات معالجة الرسوميات (GPU) من Novita AI بيئة مثالية لنشر نموذج PaddleOCR-VL-1.5 مع العديد من المزايا الحرجة:
- بيئة CUDA مهيأة مسبقاً: تدعم قوالب Novita إصدارات CUDA 11.x و 12.x المطلوبة من قبل إصدارات PaddlePaddle 3.1.0/3.1.1.
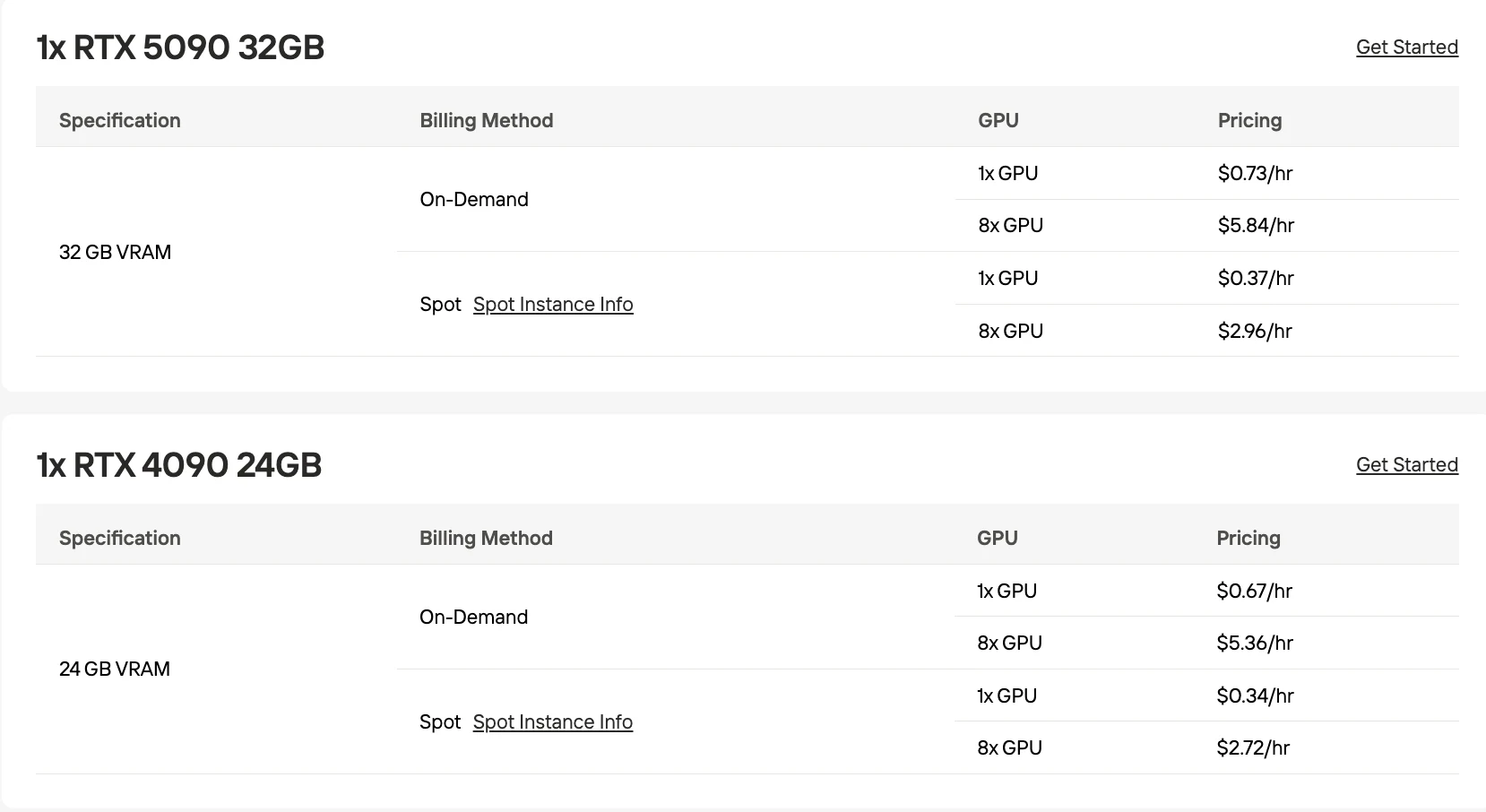
- خيارات وحدات معالجة رسوميات (GPU) فعالة من حيث التكلفة: وحدة RTX 5090 سعة 32 جيجابايت بسعر 0.73 دولار للساعة عند الطلب الفوري.
- تكيف مرن: تسعير حسب الاستخدام مع مثيلات عند الطلب الفوري ومثيلات Spot — يمكنك التوسع من وحدة معالجة رسوميات واحدة إلى مجموعات من 8 وحدات معالجة رسوميات.
- نشر أصلي لـ Docker: دعم الصور المخصصة مع سجلات عامة وخاصة يلغي تعقيد إعداد البيئة.
- تخزين حجمي شبكي: أحجام شبكية بسعر 0.002 دولار للجيجابايت في اليوم لتخزين النماذج بشكل دائم عبر المثيلات.
جرب وحدات معالجة الرسوميات (GPU) الفعالة من حيث التكلفة الآن!
نشر نموذج PaddleOCR-VL-1.5 على قالب وحدات معالجة الرسوميات (GPU) من Novita
الخطوة 1: الدخول إلى وحدة التحكم
افتح واجهة وحدات معالجة الرسوميات (GPU) واختر “ابدأ” للوصول إلى إدارة النشر.
الخطوة 2: اختيار الحزمة
ابحث عن نموذج PaddleOCR-VL-1.5 في مستودع القوالب وابدأ تسلسل التثبيت.
الخطوة 3: إعداد البنية التحتية
قم بتكوين معلمات الحوسبة بما في ذلك تخصيص الذاكرة، ومتطلبات التخزين، وإعدادات الشبكة. اختر “نشر” لتنفيذ العملية.
الخطوة 4: المراجعة والإنشاء
تحقق مرة أخرى من تفاصيل التكوين الخاصة بك وملخص التكاليف. عندما تكون راضياً، انقر على “نشر” لبدء عملية الإنشاء.
جرب وحدات معالجة الرسوميات (GPU) الفعالة من حيث التكلفة الآن!
وضع Spot من Novita AI هو نظام استئجار لوحدات معالجة الرسوميات (GPU) محسّن من حيث التكلفة، يستفيد من سعة وحدات المعالجة الخاملة أو غير المستخدمة على المنصة. على عكس المثيلات عند الطلب الفوري، التي تحجز أجهزة مخصصة للاستخدام المستقر والمستمر، فإن مثيلات Spot قابلة للقطع — قد يتم إيقاف مهمتك أو إنهاؤها مؤقتاً إذا استعاد النظام وحدة المعالجة. وبما أن وضع Spot يعيد تخصيص موارد وحدات المعالجة التي كانت خاملة في غير ذلك، فهو عادة ما يكون أرخص بنسبة 40-60% من أسعار الطلب الفوري.
الخطوة 5: انتظر حتى اكتمال الإنشاء
بعد بدء عملية النشر، سيقوم النظام بإعادة توجيهك تلقائياً إلى صفحة إدارة المثيلات. سيتم إنشاء مثيلك في الخلفية.
الخطوة 6: مراقبة تقدم التنزيل
تتبع تقدم تنزيل الصورة في الوقت الفعلي. ستتغير حالة مثيلك من “سحب” إلى “قيد التشغيل” بمجرد اكتمال النشر. يمكنك عرض التقدم التفصيلي بالنقر على أيقونة السهم بجانب اسم مثيلك.
الخطوة 7: التحقق من حالة المثيل
انقر على زر “السجلات” لعرض سجلات المثيل والتأكد من أن خدمة PaddleOCR قد بدأت بشكل صحيح.
الخطوة 8: الوصول إلى البيئة
افتح مساحة التطوير من خلال واجهة “اتصال”، ثم قم بتهيئة “بدء طرفية الويب”.
هذا حالة اختبار بلغة بايثون.
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
قم بتنزيل الصورة النموذجية وتشغيل سكريبت الاختبار:
# Download sample image for testing
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copy port mapping address and replace API_URL in test.py, then run:
python test.py
# Expected output:
# Markdown document saved at markdown_0/doc.md
# Output image saved at layout_det_res_0.jpg
تحسين نشر نموذج PaddleOCR-VL-1.5 على قالب وحدات معالجة الرسوميات (GPU) من Novita
تكوين المعالجة الدفعية
يوصي دليل نشر AMD بضبط معامل batch_size على 64 لتحسين الإنتاجية. قم بالتعديل بناءً على وحدة المعالجة الرسومية (GPU) الخاصة بك:
| وحدة المعالجة الرسومية (GPU) | حجم الدفعة الموصى به | الإنتاجية (مستند/دقيقة) |
|---|---|---|
| RTX 5090 سعة 32 جيجابايت | 32-48 | ~120-150 |
| RTX 4090 سعة 24 جيجابايت | 24-32 | ~90-120 |
| H100 سعة 80 جيجابايت | 64-96 | ~250-350 |
إعدادات الكشف عن التخطيط
قم بتفعيل المعامل use_layout_detection: True للمستندات المعقدة التي تحتوي على جداول، وصيغ، ورسوم بيانية. قم بتعطيله للمستندات النصية البسيطة لتقليل زمن الاستجابة بنسبة 30-40%.
استكشاف الأخطاء الشائعة وإصلاحها
المشكلة 1: انتهاء مهلة تنزيل النموذج
العرض: يفشل تشغيل الحاوية مع ظهور رسالة “انتهاء مهلة الاتصال بـ huggingface.co”
الحل: قم بتنزيل النموذج مسبقاً إلى حجم شبكي من Novita وتثبيته (mount) كالتالي:
# On a temporary instance:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# In Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
المشكلة 2: أخطاء نفاد الذاكرة
العرض: ظهور رسالة CUDA out of memory أثناء عملية الاستدلال
الحل: تقليل قيمة المعامل batch_size في التكوين الخاص بك:
batch_size: 16 # Down from 64
gpu_memory_utilization: 0.85 # Leave 15% headroom
المشكلة 3: استدلال بطيء للمستندات المعقدة
العرض: زمن معالجة يزيد عن 5 ثوانٍ لكل مستند
الحل: قم بتعطيل الميزات غير الضرورية وفقاً لدليل تحسين AMD:
- اضبط المعامل
use_layout_detection: Falseللمستندات النصية البسيطة (أسرع بنسبة 30-40%) - اضبط المعامل
merge_layout_blocks: Falseإذا كنت بحاجة إلى مواضع عناصر خام - قم بالترقية إلى وحدة H100 SXM سعة 80 جيجابايت لتحقيق إنتاجية أعلى بنسبة 2-3 أضعاف للتخطيطات المعقدة
إن نشر نموذج PaddleOCR-VL-1.5 على مثيلات وحدات معالجة الرسوميات (GPU) من Novita AI يوفر تحليلاً للمستندات على مستوى الإنتاج. إن الجمع بين كفاءة المعاملات البالغة 0.9 مليار، وتسعير وحدات المعالجة المرن من Novita، يتيح للشركات الناشئة والمؤسسات معالجة ملايين المستندات شهرياً دون تجاوز الميزانيات.
الخلاصة
يتيح لك نشر نموذج PaddleOCR-VL-1.5 على قوالب وحدات معالجة الرسوميات (GPU) من Novita AI الحصول على تحليل مستندات على مستوى المؤسسات في دقائق — بدون إعداد بيئة معقد، بدون تكاليف لوحدات معالجة خاملة. بمعاملات تبلغ 0.9 مليار، ودقة 94.5% على معيار OmniDocBench v1.5، وخيارات وحدات معالجة مرنة تبدأ من 0.73 دولار للساعة، فإنه حل فعال للفرق التي تعالج أحجاماً كبيرة من المستندات على نطاق واسع.
النقطة الرئيسية: اختر فئة وحدة المعالجة المناسبة بناءً على احتياجات الإنتاجية، وقم بتفعيل المعالجة الدفعية لأحمال عمل الإنتاج، واستخدم مثيلات Spot لتخفيض التكاليف بنسبة 40-60%. ابدأ الآن على منصة Novita AI وانشر نموذج PaddleOCR-VL-1.5 اليوم.
ما هي وحدة معالجة الرسوميات (GPU) التي أحتاجها لتشغيل نموذج PaddleOCR-VL-1.5؟
يعمل نموذج PaddleOCR-VL-1.5 على أي وحدة معالجة رسومية (GPU) بذاكرة وصول عشوائي (VRAM) سعة 8 جيجابايت أو أكثر؛ يوصى باستخدام وحدة RTX 5090 سعة 32 جيجابايت بسعر 0.73 دولار للساعة لبيئة الإنتاج.
هل يمكن لنموذج PaddleOCR-VL-1.5 التعامل مع المستندات الممسوحة ضوئياً والتي تحتوي على تشوهات؟
نعم، يتعامل الكشف عن الأشكال غير المنتظمة في نموذج PaddleOCR-VL-1.5 مع الميل، والتشوه، وعيوب المسح الضوئي التي تم التحقق من صحتها على معيار Real5-OmniDocBench.
هل نموذج PaddleOCR-VL-1.5 مناسب للاستخدام في بيئة الإنتاج؟
نعم. بفضل معاملات تبلغ 0.9 مليار ودقة 94.5%، يقدم توازناً قوياً بين الأداء والكفاءة، مما يجعله مناسباً لـ خطوط معالجة مستندات المؤسسات.
منصة Novita AI هي منصة سحابية للذكاء الاصطناعي والعوامل المساعدة تساعد المطورين والشركات الناشئة على بناء ونشر وتوسيع نطاق النماذج والتطبيقات المعتمدة على العوامل المساعدة بأداء عالٍ، وموثوقية، وكفاءة في التكاليف.
قراءات موصى بها
ديب سيك ضد كوين: تحديد أي نظام بيئي يناسب احتياجات الإنتاج



