

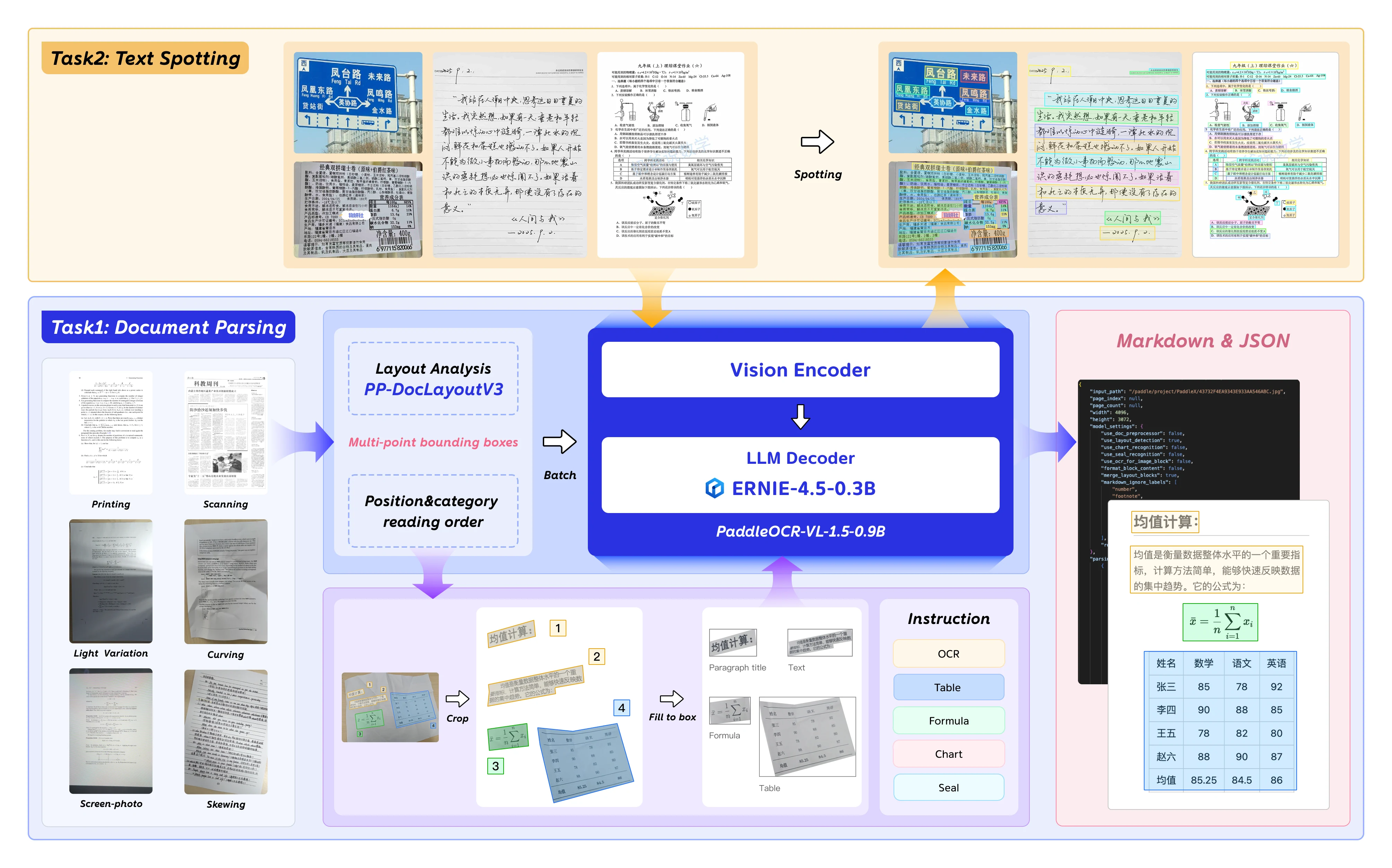
部署像 PaddleOCR-VL-1.5 這樣的前沿 OCR 模型可能會讓人不知所措 — 開發者會面臨硬體需求不明、環境設定複雜、GPU 成本不確定等問題。PaddleOCR-VL-1.5 是百度最先進的視覺語言模型,在 OmniDocBench v1.5 上達到 94.5% 的準確率,需要精確的部署配置才能發揮最佳效能。
本指南將帶領您逐步在 Novita AI 的 GPU 實例上部署 PaddleOCR-VL-1.5,從選擇合適的 GPU 到在生產環境執行推論,我們會涵蓋 Docker 映像設定、環境配置、GPU 選擇,以及實際成本分析。
什麼是 PaddleOCR-VL-1.5?
PaddleOCR-VL-1.5 是百度次世代視覺語言模型,專為文件解析、OCR 和版面理解最佳化。擁有 0.9B 參數,在保持可部署於消費級 GPU 的同時,能提供企業級準確率。
| 規格 | 數值 |
|---|---|
| 模型類型 | 視覺語言(VLM) |
| 參數 | 0.9B |
| 上下文視窗 | 131,072 tokens |
| 精度 | bfloat16 |
| OmniDocBench v1.5 | 94.5% 準確率 |
| 基座模型 | ERNIE-4.5-0.3B-Paddle |
核心能力
PaddleOCR-VL-1.5 為文件 AI 帶來了多項重要功能:
- 不規則形狀偵測:針對歪斜、變形文件的多邊形定位功能 — 可處理掃描 artifacts、螢幕拍攝、光照變化,已通過 Real5-OmniDocBench 基準測試驗證。
- 強化元素辨識:與前代模型相比,表格、公式和文字辨識效能有顯著提升。
- 印章與文字定位:原生支援印章辨識與文字定位任務 — 對法律與政府文件處理至關重要。
- 多語言支援:使用英文、中文及多語言資料集訓練。
資料來源:Hugging Face
為什麼要部署在 Novita AI GPU 實例上?
Novita AI GPU 實例是部署 PaddleOCR-VL-1.5 的理想環境,具備多項關鍵優勢:
- 預先配置的 CUDA 環境:Novita 模板支援 PaddlePaddle 3.1.0/3.1.1 所需的 CUDA 11.x 與 12.x。
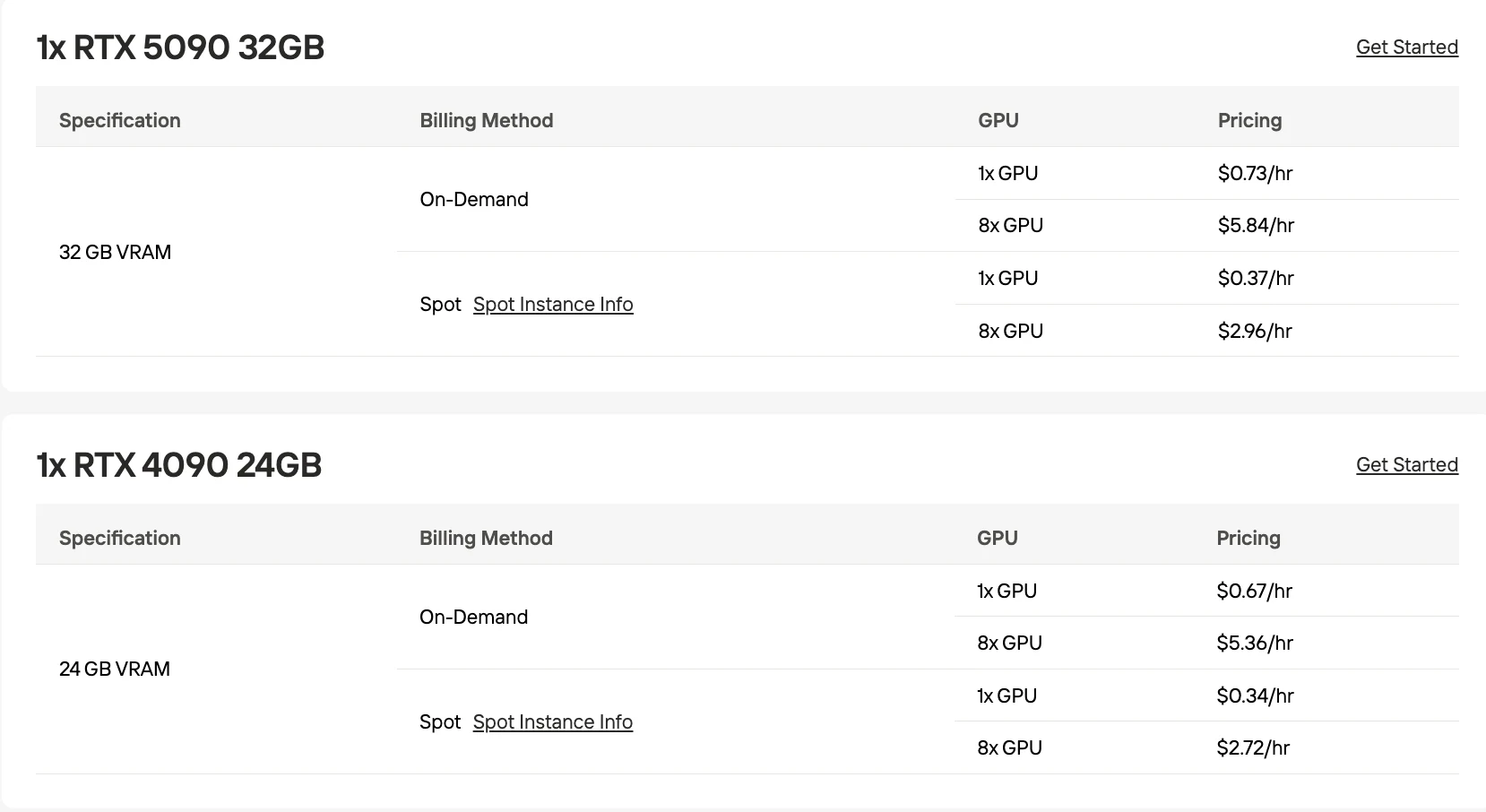
- 高性價比 GPU 選項:隨選 RTX 5090 32GB 每小時僅需 0.73 美元。
- 彈性擴展:隨用隨付計費,支援隨選與搶占實例 — 可從單 GPU 擴展至 8 張 GPU 的叢集。
- 原生 Docker 部署:支援搭配公開/私有映像庫的自訂映像,消除環境設定的複雜度。
- 網路儲存卷:網路儲存卷每 GB 每天僅需 0.002 美元,可在不同實例間持久儲存模型。
在 Novita GPU 模板上部署 PaddleOCR-VL-1.5
步驟 1:進入控制台
啟動 GPU 介面,選擇「開始使用」進入部署管理頁面。
步驟 2:選擇套件
在模板儲存庫中找到 PaddleOCR-VL-1.5,開始安裝流程。
步驟 3:基礎設施設定
配置運算參數,包括記憶體分配、儲存需求與網路設定,選擇「部署」即可執行。
步驟 4:審核與建立
再次確認您的配置細節與費用摘要,確認無誤後點擊「部署」開始建立流程。
Novita AI 的搶占模式是一種成本優化的 GPU 租賃系統,會重用平台閒置或未使用的 GPU 資源。與預留專用硬體、適合穩定持續使用的隨選實例不同,搶占實例是可中斷的 — 如果系統需要回收 GPU,您的任務可能會被暫停或終止。由於搶占模式重新分配原本閒置的 GPU 資源,價格通常比隨選實例便宜 40–60%。
步驟 5:等待建立完成
啟動部署後,系統會自動將您導向實例管理頁面,您的實例將在背景中建立。
步驟 6:監控下載進度
即時追蹤映像下載進度,部署完成後實例狀態會從「下載中」變為「執行中」,您可以點擊實例名稱旁的箭頭圖示查看詳細進度。
步驟 7:驗證實例狀態
點擊「日誌」按鈕查看實例日誌,確認 PaddleOCR 服務已正常啟動。
步驟 8:環境存取
透過「連接」介面啟動開發空間,接著初始化「啟動 Web 終端機」。
這是一個 Python 測試案例。
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
下載範例圖片並執行測試腳本:
# Download sample image for testing
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copy port mapping address and replace API_URL in test.py, then run:
python test.py
# Expected output:
# Markdown document saved at markdown_0/doc.md
# Output image saved at layout_det_res_0.jpg
在 Novita GPU 模板上部署 PaddleOCR-VL-1.5 的最佳化
批次處理配置
AMD 部署指南建議將 batch_size 設為 64 以最佳化吞吐量,您可以根據使用的 GPU 調整:
| GPU | 建議批次大小 | 吞吐量(文件/分鐘) |
|---|---|---|
| RTX 5090 32GB | 32-48 | ~120-150 |
| RTX 4090 24GB | 24-32 | ~90-120 |
| H100 80GB | 64-96 | ~250-350 |
版面偵測設定
對於包含表格、公式和圖表的複雜文件,請啟用 use_layout_detection: True;對於純文字文件,請關閉此功能以降低 30-40% 的延遲。
常見問題疑難排解
問題 1:模型下載逾時
症狀:容器啟動失敗,提示「連線至 huggingface.co 逾時」
解決方案:將模型預先下載到 Novita 網路儲存卷並掛載:
# On a temporary instance:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# In Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
問題 2:記憶體不足錯誤
症狀:推論時出現 CUDA out of memory 錯誤
解決方案:降低配置中的 batch_size:
batch_size: 16 # Down from 64
gpu_memory_utilization: 0.85 # Leave 15% headroom
問題 3:複雜文件推論速度過慢
症狀:每份文件處理時間超過 5 秒
解決方案:根據 AMD 最佳化指南關閉不必要的功能:
- 對於純文字文件,將
use_layout_detection設為 False(速度快 30-40%) - 如果需要原始元素位置,將
merge_layout_blocks設為 False - 若需要處理複雜版面,升級至 H100 SXM 80GB 可提升 2-3 倍吞吐量
在 Novita AI GPU 實例上部署 PaddleOCR-VL-1.5 可提供生產級的文件解析能力。0.9B 參數的高效能,加上 Novita 彈性的 GPU 計價,能讓新創公司與企業每月處理數百萬份文件,且不會超出預算。
結論
在 Novita AI GPU 模板上部署 PaddleOCR-VL-1.5,只需幾分鐘即可獲得企業級的文件解析能力 — 無需複雜的環境設定,也無需負擔閒置 GPU 的成本。憑藉 0.9B 參數、OmniDocBench v1.5 上 94.5% 的準確率,以及每小時 0.73 美元起的彈性 GPU 選項,這是團隊大規模處理大量文件的高效解決方案。
關鍵要點:根據吞吐量需求選擇合適的 GPU 等級,為生產工作負載啟用批次處理,並使用搶占實例降低 40–60% 的成本。立即在 Novita AI 開始使用,今天就能部署 PaddleOCR-VL-1.5。
執行 PaddleOCR-VL-1.5 需要什麼 GPU?
PaddleOCR-VL-1.5 可在任何 8GB 以上顯存的 GPU 上執行;生產環境推薦使用每小時 0.73 美元的 RTX 5090 32GB。
PaddleOCR-VL-1.5 能否處理有扭曲的掃描文件?
可以,PaddleOCR-VL-1.5 的不規則形狀偵測功能 可處理歪斜、變形與掃描 artifacts,已通過 Real5-OmniDocBench 基準測試驗證。
PaddleOCR-VL-1.5 是否適合用於生產環境?
是的。憑藉 0.9B 參數與 94.5% 的準確率,它在效能與效率之間取得了良好的平衡,非常適合用於企業文件處理流程。
Novita AI 是 AI 與代理雲端平台,協助開發者與新創公司以高效能、高可靠性與高成本效益建置、部署和擴展模型與代理應用程式。
推薦閱讀



