

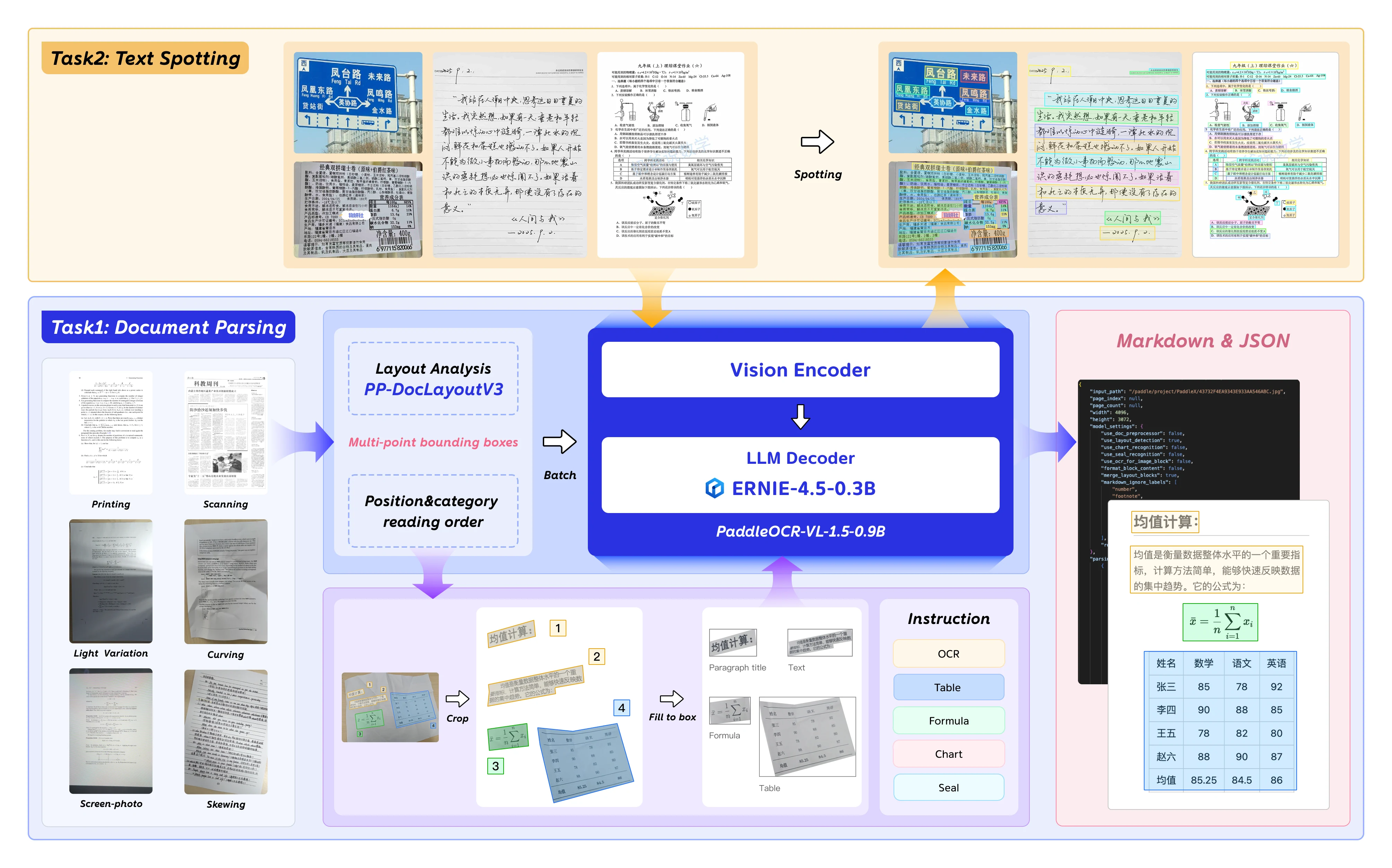
Развертывание передовых моделей OCR, таких как PaddleOCR-VL-1.5, может показаться сложным — разработчики сталкиваются с неясными требованиями к оборудованию, сложной настройкой окружения и неопределенностью в стоимости GPU. PaddleOCR-VL-1.5, передовая vision-language модель Baidu с точностью 94,5% на тесте OmniDocBench v1.5, требует точных конфигураций развертывания для достижения максимальной производительности.
Это руководство проведет вас через процесс развертывания PaddleOCR-VL-1.5 на GPU-инстансах Novita AI: от выбора подходящего GPU до запуска инференса в продакшене. Мы рассмотрим настройку Docker-образа, конфигурацию окружения, выбор GPU и анализ затрат в реальных условиях.
Что такое PaddleOCR-VL-1.5?
PaddleOCR-VL-1.5 — это следующее поколение vision-language модели Baidu, оптимизированной для парсинга документов, OCR и понимания макета. С 0,9 млрд параметров она обеспечивает точность корпоративного уровня при этом может быть развернута на потребительских GPU.
| Спецификация | Значение |
|---|---|
| Тип модели | Vision-Language (VLM) |
| Параметры | 0,9 млрд |
| Контекстное окно | 131 072 токена |
| Точность | bfloat16 |
| OmniDocBench v1.5 | 94,5% точности |
| Базовая модель | ERNIE-4.5-0.3B-Paddle |
Ключевые возможности
PaddleOCR-VL-1.5 представляет заметные возможности для анализа документов с помощью ИИ:
- Обнаружение нерегулярных форм: Полигональная локализация для перекошенных и деформированных документов — обрабатывает артефакты сканирования, фотографии с экрана и вариации освещения, протестировано на бенчмарке Real5-OmniDocBench.
- Улучшенное распознавание элементов: Значительные улучшения в распознавании таблиц, формул и текста по сравнению с предыдущими моделями.
- Распознавание печатей и текста: Встроенная поддержка задач распознавания печатей и поиска текста — критически важно для обработки юридических и государственных документов.
- Мультиязычная поддержка: Обучена на английских, китайских и многоязычных наборах данных.
Источник: Hugging Face
Почему стоит развертывать на GPU-инстансах Novita AI?
Novita AI GPU-инстансы предоставляют оптимальное окружение для развертывания PaddleOCR-VL-1.5 с рядом критических преимуществ:
- Предварительно настроенное окружение CUDA: Шаблоны Novita поддерживают CUDA 11.x и 12.x, требуемые для PaddlePaddle 3.1.0/3.1.1.
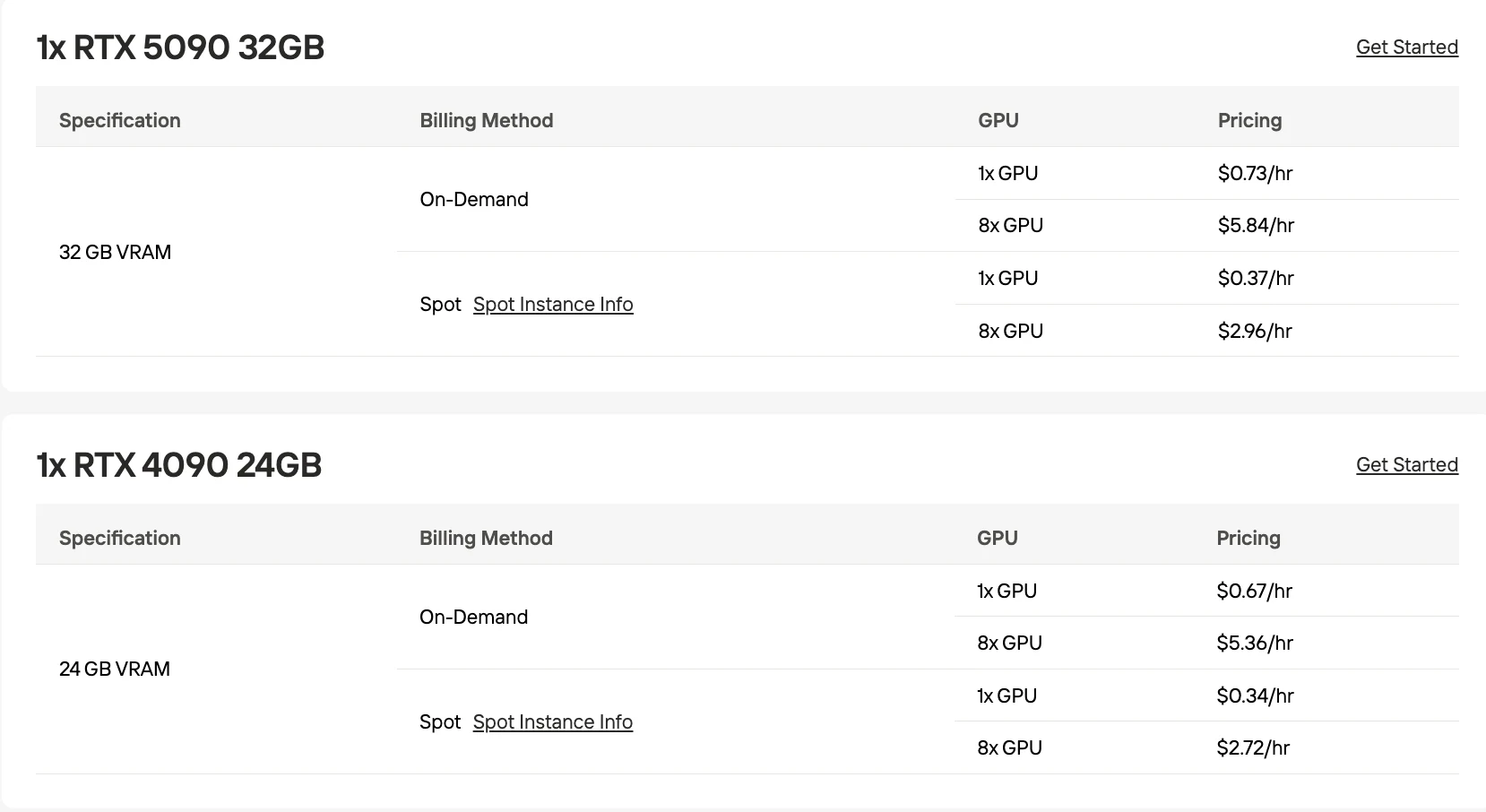
- Выгодные варианты GPU: RTX 5090 32GB по цене $0,73 в час при запросе по требованию.
- Гибкое масштабирование: Тарификация по факту использования с инстансами по требованию и спотовыми инстансами — масштабируйте от одного GPU до кластеров из 8×GPU.
- Развертывание нативно для Docker: Поддержка пользовательских образов с публичными/приватными реестрами исключает сложность настройки окружения.
- Сетевое хранилище объемов: Сетевые тома по $0,002 за ГБ в день для постоянного хранения моделей между инстансами.
Попробуйте выгодные GPU уже сейчас!
Развертывание PaddleOCR-VL-1.5 на шаблоне Novita GPU
Шаг 1: Вход в консоль
Запустите GPU-интерфейс и выберите опцию Get Started для доступа к управлению развертываниями.
Шаг 2: Выбор пакета
Найдите PaddleOCR-VL-1.5 в репозитории шаблонов и запустите последовательность установки.
Шаг 3: Настройка инфраструктуры
Настройте вычислительные параметры, включая распределение памяти, требования к хранилищу и сетевые настройки. Выберите Deploy для запуска развертывания.
Шаг 4: Проверка и создание
Дважды проверьте детали конфигурации и сводку затрат. Если все устраивает, нажмите Deploy для запуска процесса создания.
Попробуйте выгодные GPU уже сейчас!
Спотовый режим Novita AI — это оптимизированная по стоимости система аренды GPU, которая использует простаивающие или неиспользуемые мощности GPU платформы. В отличие от инстансов по требованию, которые резервируют выделенное оборудование для стабильной непрерывной работы, спотовые инстансы являются прерываемыми — ваша задача может быть приостановлена или завершена, если GPU будет возвращен в пул платформы. Поскольку спотовый режим перераспределяет в противном случае простаивающие ресурсы GPU, он обычно на 40–60% дешевле тарификации по требованию.
Шаг 5: Ожидание создания
После запуска развертывания система автоматически перенаправит вас на страницу управления инстансами. Ваш инстанс будет создан в фоновом режиме.
Шаг 6: Мониторинг прогресса загрузки
Отслеживайте прогресс загрузки образа в реальном времени. Статус вашего инстанса изменится с Pulling на Running после завершения развертывания. Вы можете просмотреть детальный прогресс, нажав на иконку стрелки рядом с именем вашего инстанса.
Шаг 7: Проверка статуса инстанса
Нажмите кнопку Logs для просмотра логов инстанса и подтверждения того, что сервис PaddleOCR запустился корректно.
Шаг 8: Доступ к окружению
Запустите пространство разработки через интерфейс Connect, затем инициализируйте Start Web Terminal.
Это пример теста на Python.
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
Скачайте тестовое изображение и запустите тестовый скрипт:
# Download sample image for testing
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copy port mapping address and replace API_URL in test.py, then run:
python test.py
# Expected output:
# Markdown document saved at markdown_0/doc.md
# Output image saved at layout_det_res_0.jpg
Оптимизация развертывания PaddleOCR-VL-1.5 на шаблоне Novita GPU
Конфигурация пакетной обработки
Руководство по развертыванию AMD рекомендует значение batch_size: 64 для оптимизации пропускной способности. Настройте значение в зависимости от вашего GPU:
| GPU | Рекомендуемый размер пакета | Пропускная способность (документов/мин) |
|---|---|---|
| RTX 5090 32GB | 32–48 | ~120–150 |
| RTX 4090 24GB | 24–32 | ~90–120 |
| H100 80GB | 64–96 | ~250–350 |
Настройки обнаружения макета
Включите use_layout_detection: True для сложных документов с таблицами, формулами и диаграммами. Отключите для документов с обычным текстом, чтобы снизить задержку на 30–40%.
Устранение распространенных проблем
Проблема 1: Таймаут загрузки модели
Симптом: Контейнер не запускается с ошибкой “Connection timeout to huggingface.co”
Решение: Предварительно загрузите модель в сетевой том Novita и смонтируйте его:
# On a temporary instance:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# In Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
Проблема 2: Ошибки нехватки памяти
Симптом: CUDA out of memory во время инференса
Решение: Уменьшите значение batch_size в вашей конфигурации:
batch_size: 16 # Down from 64
gpu_memory_utilization: 0.85 # Leave 15% headroom
Проблема 3: Медленный инференс на сложных документах
Симптом: Время обработки >5 секунд на документ
Решение: Отключите ненужные функции в соответствии с руководством по оптимизации AMD:
- Установите
use_layout_detection: Falseдля документов с обычным текстом (на 30–40% быстрее) - Установите
merge_layout_blocks: False, если вам нужны исходные позиции элементов - Перейдите на H100 SXM 80GB для увеличения пропускной способности на сложных макетах в 2–3 раза
Развертывание PaddleOCR-VL-1.5 на GPU-инстансах Novita AI обеспечивает производственный парсинг документов. Сочетание эффективности модели с 0,9 млрд параметров и гибкой тарификации GPU от Novita позволяет стартапам и предприятиям обрабатывать миллионы документов в месяц без превышения бюджета.
Заключение
Развертывание PaddleOCR-VL-1.5 на шаблонах GPU Novita AI дает вам возможность парсить документы корпоративного уровня за несколько минут — без сложной настройки окружения и без затрат на простаивающий GPU. С 0,9 млрд параметров, точностью 94,5% на OmniDocBench v1.5 и гибкими вариантами GPU от $0,73 в час это эффективное решение для команд, обрабатывающих большие объемы документов в масштабе.
Ключевой вывод: Выбирайте tier GPU в зависимости от потребностей в пропускной способности, включите пакетную обработку для производственных нагрузок и используйте спотовые инстансы, чтобы сократить затраты на 40–60%. Начните работу на Novita AI и разверните PaddleOCR-VL-1.5 уже сегодня.
Какой GPU нужен для запуска PaddleOCR-VL-1.5?
PaddleOCR-VL-1.5 работает на любом GPU с объемом VRAM от 8 ГБ; для продакшена рекомендуется RTX 5090 32GB по $0,73 в час.
Может ли PaddleOCR-VL-1.5 обрабатывать отсканированные документы с искажениями?
Да, функция обнаружения нерегулярных форм PaddleOCR-VL-1.5 обрабатывает перекосы, деформации и артефакты сканирования, проверенные на бенчмарке Real5-OmniDocBench.
Подходит ли PaddleOCR-VL-1.5 для использования в продакшене?
Да. С 0,9 млрд параметров и точностью 94,5% он обеспечивает сильный баланс между производительностью и эффективностью, что делает его подходящим для конвейеров обработки документов корпоративного уровня.
Novita AI — это облачная платформа для ИИ и агентов, которая помогает разработчикам и стартапам создавать, развертывать и масштабировать модели и агентные приложения с высокой производительностью, надежностью и экономической эффективностью.
Рекомендуемые материалы
DeepSeek против Qwen: Определите, какая экосистема подходит для продакшена
DeepSeek против Qwen: Определите, какая экосистема подходит для продакшена
Стоимость DeepSeek R1 0528: сравнение API, GPU и локальных развертываний



