

Desplegar modelos OCR de última generación como PaddleOCR-VL-1.5 puede ser abrumador — los desarrolladores se enfrentan a requisitos de hardware poco claros, una configuración de entorno compleja e incertidumbre sobre los costos de GPU. PaddleOCR-VL-1.5, el modelo de lenguaje-visión de última generación de Baidu que alcanza un 94.5% de precisión en OmniDocBench v1.5, exige configuraciones de despliegue precisas para un rendimiento óptimo.
Esta guía te guía a través del despliegue de PaddleOCR-VL-1.5 en instancias de GPU de Novita AI, desde la selección de la GPU adecuada hasta la ejecución de inferencia en producción. Cubrimos la configuración de imágenes Docker, configuración del entorno, selección de GPU y análisis de costos reales.
¿Qué es PaddleOCR-VL-1.5?
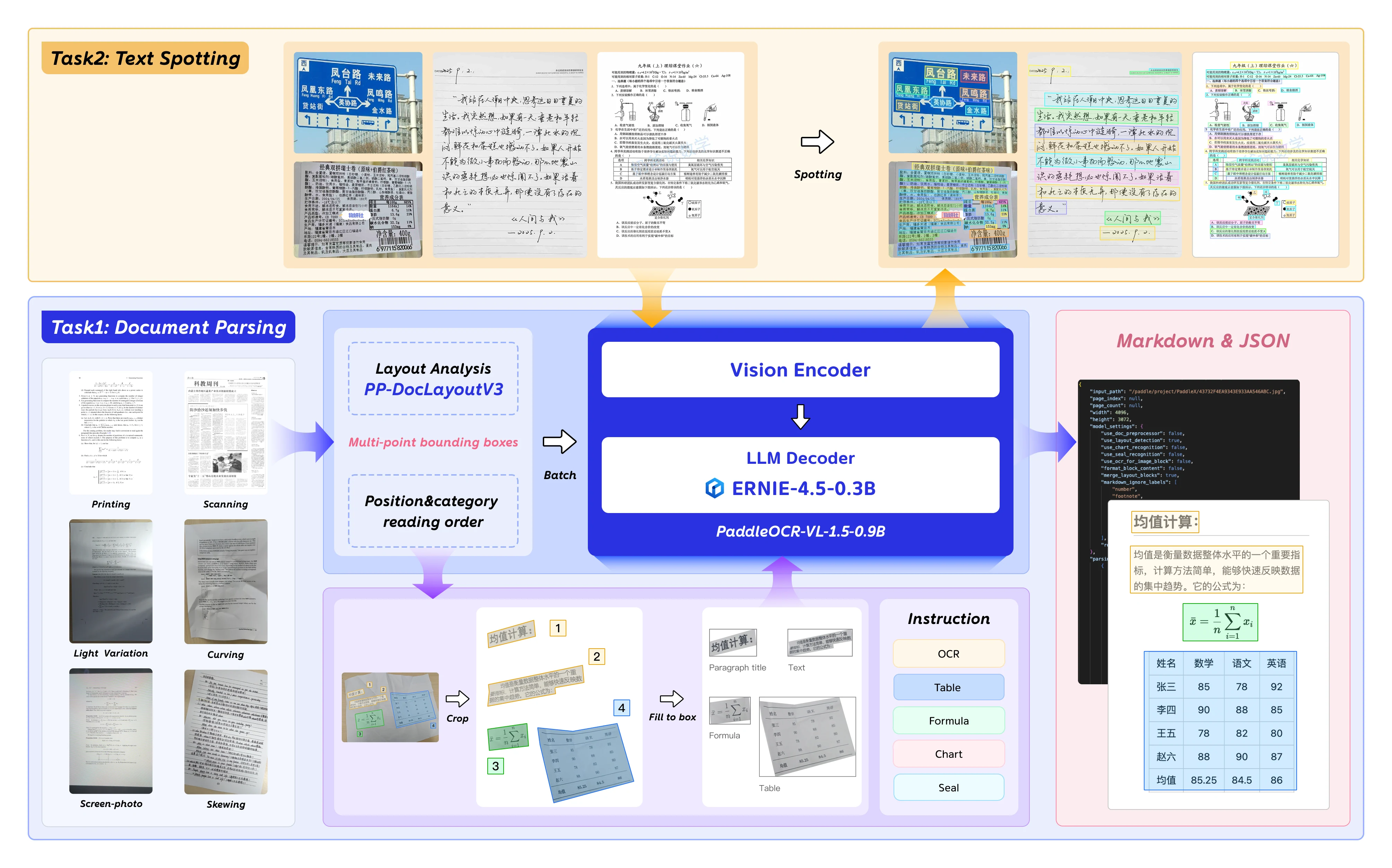
PaddleOCR-VL-1.5 es el modelo de lenguaje-visión de próxima generación de Baidu optimizado para análisis de documentos, OCR y comprensión de diseño. Con 0.9 mil millones de parámetros, ofrece precisión de nivel empresarial mientras sigue siendo desplegable en GPUs de consumo.
| Especificación | Valor |
|---|---|
| Tipo de modelo | Lenguaje-Visión (VLM) |
| Parámetros | 0.9B |
| Ventana de contexto | 131 072 tokens |
| Precisión | bfloat16 |
| OmniDocBench v1.5 | 94.5% de precisión |
| Modelo base | ERNIE-4.5-0.3B-Paddle |
Capacidades clave
PaddleOCR-VL-1.5 introduce características notables para la IA de documentos:
- Detección de formas irregulares: Localización poligonal para documentos sesgados y deformados — maneja artefactos de escaneo, fotografía de pantalla y variaciones de iluminación probadas en el benchmark Real5-OmniDocBench.
- Reconocimiento mejorado de elementos: Mejoras significativas en el reconocimiento de tablas, fórmulas y texto en comparación con modelos predecesores.
- Detección de sellos y texto: Soporte nativo para reconocimiento de sellos y tareas de detección de texto — fundamental para el procesamiento de documentos legales y gubernamentales.
- Soporte multilingüe: Entrenado en conjuntos de datos en inglés, chino y multilingües.
De Hugging Face
¿Por qué desplegar en instancias de GPU de Novita AI?
Las instancias de GPU de Novita AI proporcionan un entorno óptimo para desplegar PaddleOCR-VL-1.5 con varias ventajas críticas:
- Entorno CUDA preconfigurado: Las plantillas de Novita soportan CUDA 11.x y 12.x requerido por PaddlePaddle 3.1.0/3.1.1.
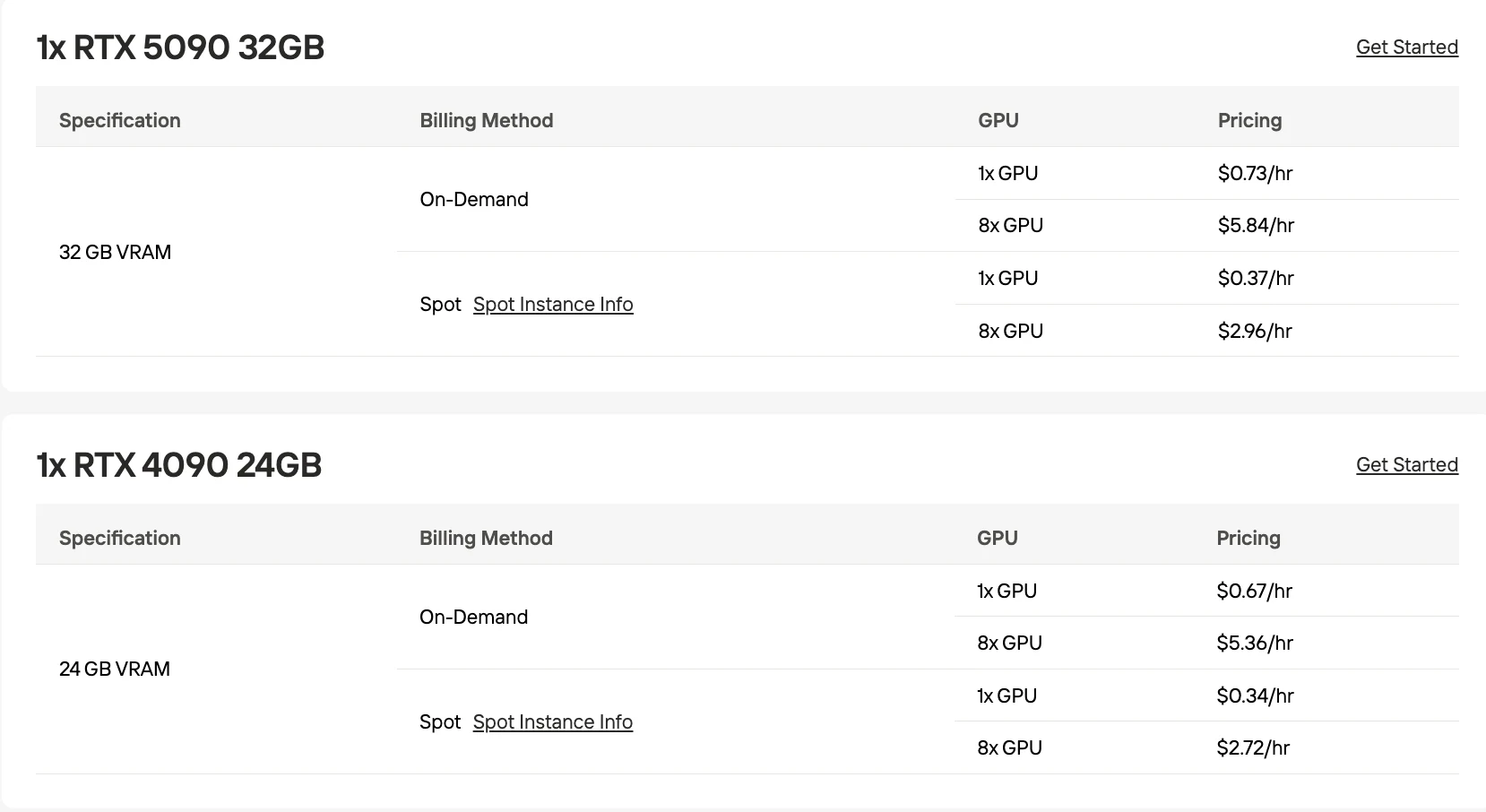
- Opciones de GPU rentables: RTX 5090 32GB a $0.73/hora bajo demanda.
- Escalado flexible: Precios de pago por uso con instancias bajo demanda y spot — escala desde una sola GPU hasta clústeres de 8 GPUs.
- Despliegue nativo con Docker: Soporte de imágenes personalizadas con registros públicos/privados que elimina la complejidad de la configuración del entorno.
- Almacenamiento en volumen de red: $0.002/GB/día para volúmenes de red que almacenan modelos de forma persistente entre instancias.
¡Prueba una GPU rentable ahora!
Desplegar PaddleOCR-VL-1.5 en la plantilla de GPU de Novita
Paso 1: Entrar a la consola
Abre la interfaz de GPU y selecciona Comenzar para acceder a la gestión de despliegues.
Paso 2: Selección del paquete
Localiza PaddleOCR-VL-1.5 en el repositorio de plantillas e inicia la secuencia de instalación.
Paso 3: Configuración de la infraestructura
Configura los parámetros de computación, incluyendo asignación de memoria, requisitos de almacenamiento y ajustes de red. Selecciona Desplegar para implementar.
Paso 4: Revisar y crear
Verifica los detalles de configuración y el resumen de costos. Cuando estés satisfecho, haz clic en Desplegar para iniciar el proceso de creación.
¡Prueba una GPU rentable ahora!
El modo Spot de Novita AI es un sistema de alquiler de GPU optimizado en costos que aprovecha la capacidad inactiva o no utilizada de la plataforma. A diferencia de las instancias bajo demanda, que reservan hardware dedicado para un uso estable y continuo, las instancias Spot son interrumpibles — tu trabajo puede pausarse o finalizarse si la GPU es reclamada por el sistema. Debido a que el modo Spot reasigna recursos de GPU que de otro modo estarían inactivos, suele ser un 40–60% más barato que el precio bajo demanda.
Paso 5: Esperar la creación
Después de iniciar el despliegue, el sistema te redirigirá automáticamente a la página de gestión de instancias. Tu instancia se creará en segundo plano.
Paso 6: Monitorear el progreso de descarga
Sigue el progreso de descarga de la imagen en tiempo real. El estado de tu instancia cambiará de “Pulling” a “Running” una vez que el despliegue esté completo. Puedes ver el progreso detallado haciendo clic en el icono de flecha junto al nombre de tu instancia.
Paso 7: Verificar el estado de la instancia
Haz clic en el botón Registros para ver los registros de la instancia y confirmar que el servicio de PaddleOCR se ha iniciado correctamente.
Paso 8: Acceso al entorno
Inicia el espacio de desarrollo a través de la interfaz Conectar, luego inicializa Iniciar Terminal Web.
Este es un caso de prueba en Python.
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # URL del servicio
image_path = "./demo.jpg"
# Codificar imagen local a Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Contenido del archivo codificado en Base64 o URL del archivo
"fileType": 1, # Tipo de archivo, 1 significa archivo de imagen
}
# Llamar a la API
response = requests.post(API_URL, json=payload)
# Procesar los datos de respuesta de la API
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Documento Markdown guardado en {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Imagen de salida guardada en {img_path}")
Descarga la imagen de muestra y ejecuta el script de prueba:
# Descargar imagen de muestra para pruebas
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copiar la dirección de mapeo de puertos y reemplazar API_URL en test.py, luego ejecutar:
python test.py
# Salida esperada:
# Documento Markdown guardado en markdown_0/doc.md
# Imagen de salida guardada en layout_det_res_0.jpg
Optimizar el despliegue de PaddleOCR-VL-1.5 en la plantilla de GPU de Novita
Configuración de procesamiento por lotes
La guía de despliegue de AMD recomienda batch_size: 64 para optimizar el rendimiento. Ajusta según tu GPU:
| GPU | Tamaño de lote recomendado | Rendimiento (docs/min) |
|---|---|---|
| RTX 5090 32GB | 32-48 | ~120-150 |
| RTX 4090 24GB | 24-32 | ~90-120 |
| H100 80GB | 64-96 | ~250-350 |
Configuración de detección de diseño
Activa use_layout_detection: True para documentos complejos con tablas, fórmulas y gráficos. Desactívalo para documentos de texto plano y reducir la latencia en un 30-40%.
Solución de problemas comunes
Problema 1: Tiempo de espera en la descarga del modelo
Síntoma: El contenedor falla al iniciar con “Connection timeout to huggingface.co”
Solución: Descarga previamente el modelo a un volumen de red de Novita y móntalo:
# En una instancia temporal:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# En el Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
Problema 2: Errores de falta de memoria
Síntoma: CUDA out of memory durante la inferencia
Solución: Reduce batch_size en tu configuración:
batch_size: 16 # Bajar de 64
gpu_memory_utilization: 0.85 # Dejar un 15% de margen
Problema 3: Inferencia lenta en documentos complejos
Síntoma: Tiempo de procesamiento >5 segundos por documento
Solución: Desactiva funciones innecesarias según la guía de optimización de AMD:
- Establece
use_layout_detection: Falsepara documentos de texto plano (30-40% más rápido) - Establece
merge_layout_blocks: Falsesi necesitas posiciones de elementos sin procesar - Actualiza a H100 SXM 80GB para un rendimiento 2-3 veces mayor en diseños complejos
Desplegar PaddleOCR-VL-1.5 en instancias de GPU de Novita AI ofrece análisis de documentos de nivel de producción. La combinación de eficiencia de 0.9B parámetros y los precios flexibles de GPU de Novita permite a startups y empresas procesar millones de documentos al mes sin sobrecargar el presupuesto.
Conclusión
Desplegar PaddleOCR-VL-1.5 en las plantillas de GPU de Novita AI te brinda análisis de documentos de nivel empresarial en minutos, sin configuración compleja del entorno ni costos de GPU inactivos. Con 0.9B parámetros, 94.5% de precisión en OmniDocBench v1.5 y opciones flexibles de GPU desde $0.73/hora, es una solución eficiente para equipos que procesan grandes volúmenes de documentos a escala.
Conclusión clave: Selecciona tu nivel de GPU según las necesidades de rendimiento, habilita el procesamiento por lotes para cargas de trabajo de producción y usa instancias Spot para reducir costos en un 40–60%. Comienza con Novita AI y despliega PaddleOCR-VL-1.5 hoy.
¿Qué GPU necesito para ejecutar PaddleOCR-VL-1.5?
PaddleOCR-VL-1.5 se ejecuta en cualquier GPU con 8 GB+ de VRAM; se recomienda RTX 5090 32GB a $0.73/hora para producción.
¿Puede PaddleOCR-VL-1.5 manejar documentos escaneados con distorsiones?
Sí, la detección de formas irregulares de PaddleOCR-VL-1.5 maneja sesgos, deformaciones y artefactos de escaneo validados en el benchmark Real5-OmniDocBench.
¿Es PaddleOCR-VL-1.5 adecuado para uso en producción?
Sí. Con 0.9B parámetros y 94.5% de precisión, ofrece un equilibrio sólido entre rendimiento y eficiencia, lo que lo hace adecuado para tuberías de procesamiento de documentos empresariales.
Novita AI es una plataforma en la nube de IA y agentes que ayuda a desarrolladores y startups a construir, desplegar y escalar modelos y aplicaciones de agentes con alto rendimiento, fiabilidad y eficiencia de costos.
Lecturas recomendadas
DeepSeek vs Qwen: Identifica qué ecosistema se adapta a las necesidades de producción
DeepSeek vs Qwen: Identifica qué ecosistema se adapta a las necesidades de producción
DeepSeek R1 0528 Costo: Comparativa de API, GPU y On-Premise



