

Die Bereitstellung modernster OCR-Modelle wie PaddleOCR-VL-1.5 kann überwältigend sein – Entwickler stehen vor unklaren Hardwareanforderungen, komplexer Umgebungseinrichtung und Unsicherheit hinsichtlich der GPU-Kosten. PaddleOCR-VL-1.5, Baidus hochmodernes Vision-Language-Modell mit 94,5 % Genauigkeit auf OmniDocBench v1.5, erfordert präzise Bereitstellungskonfigurationen für optimale Leistung.
Dieser Leitfaden führt Sie durch die Bereitstellung von PaddleOCR-VL-1.5 auf Novita AIs GPU-Instanzen, von der Auswahl der richtigen GPU bis zur Ausführung von Inferenzen in der Produktion. Wir behandeln die Einrichtung von Docker-Images, Umgebungskonfiguration, GPU-Auswahl und eine praxisnahe Kostenanalyse.
Was ist PaddleOCR-VL-1.5?
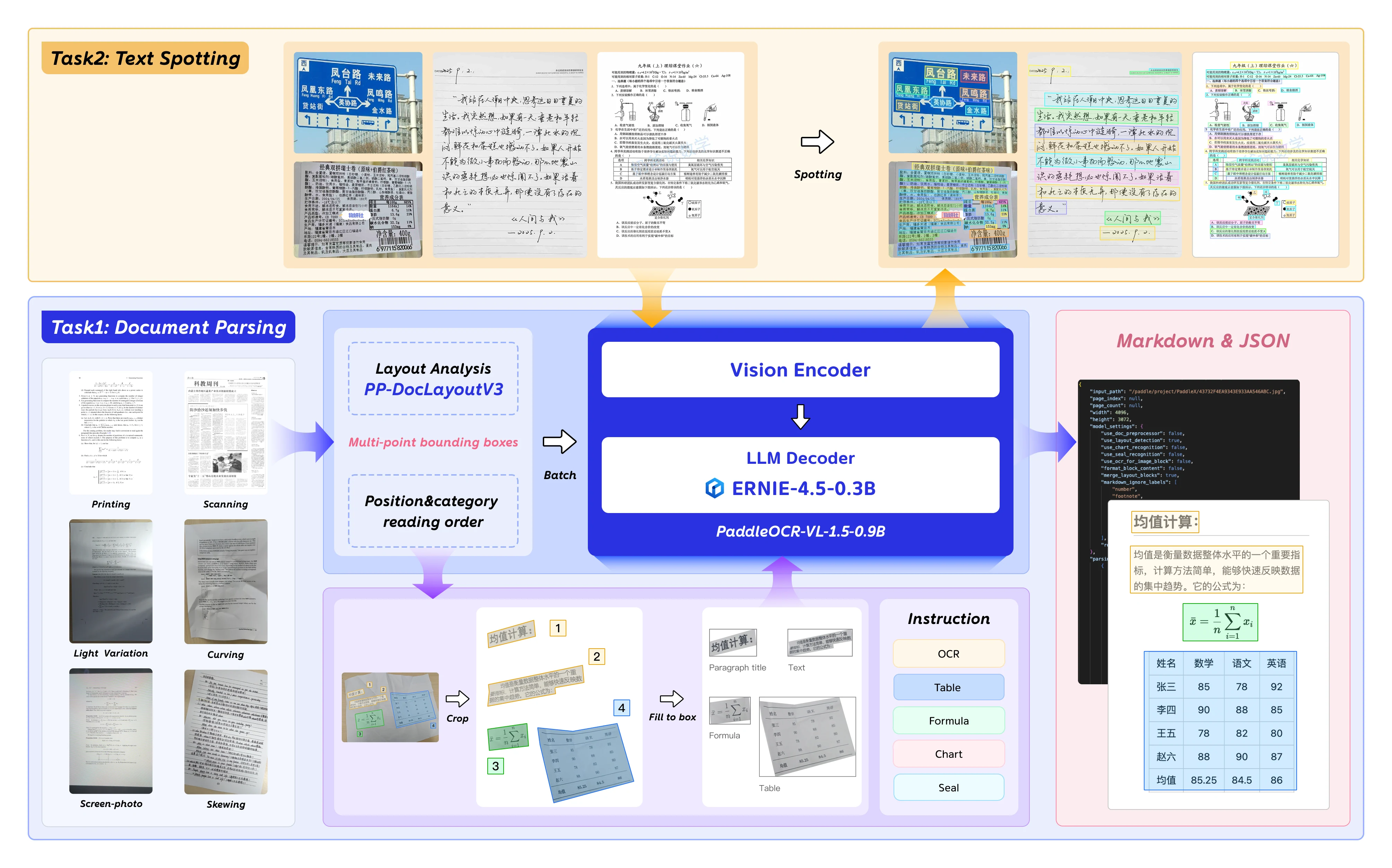
PaddleOCR-VL-1.5 ist Baidus nächstes Vision-Language-Modell, das für Dokumentenanalyse, OCR und Layout-Verständnis optimiert ist. Mit 0.9B Parametern liefert es unternehmensgerechte Genauigkeit und ist dennoch auf Consumer-GPUs einsetzbar.
| Spezifikation | Wert |
|---|---|
| Modelltyp | Vision-Language (VLM) |
| Parameter | 0.9B |
| Kontextfenster | 131.072 Token |
| Präzision | bfloat16 |
| OmniDocBench v1.5 | 94,5 % Genauigkeit |
| Basismodell | ERNIE-4.5-0.3B-Paddle |
Hauptfunktionen
PaddleOCR-VL-1.5 führt bemerkenswerte Funktionen für Dokumenten-KI ein:
- Erkennung unregelmäßiger Formen: Polygonale Lokalisierung für schräge und verzerrte Dokumente – verarbeitet Scan-Artefakte, Bildschirmfotos und Beleuchtungsunterschiede, die am Real5-OmniDocBench-Benchmark getestet wurden.
- Verbesserte Elementerkennung: Deutliche Fortschritte bei der Tabellen-, Formel- und Texterkennung im Vergleich zu Vorgängermodellen.
- Siegel- und Texterkennung: Native Unterstützung für Siegel- und Texterkennungsaufgaben – entscheidend für die Verarbeitung von Rechts- und Behördendokumenten.
- Mehrsprachige Unterstützung: Trainiert mit englischen, chinesischen und mehrsprachigen Datensätzen.
Von Hugging Face
Warum auf Novita AI GPU-Instanzen bereitstellen?
Novita AI GPU-Instanzen bieten eine optimale Umgebung für die Bereitstellung von PaddleOCR-VL-1.5 mit mehreren entscheidenden Vorteilen:
- Vorkonfigurierte CUDA-Umgebung: Novita-Vorlagen unterstützen CUDA 11.x und 12.x, die von PaddlePaddle 3.1.0/3.1.1 benötigt werden.
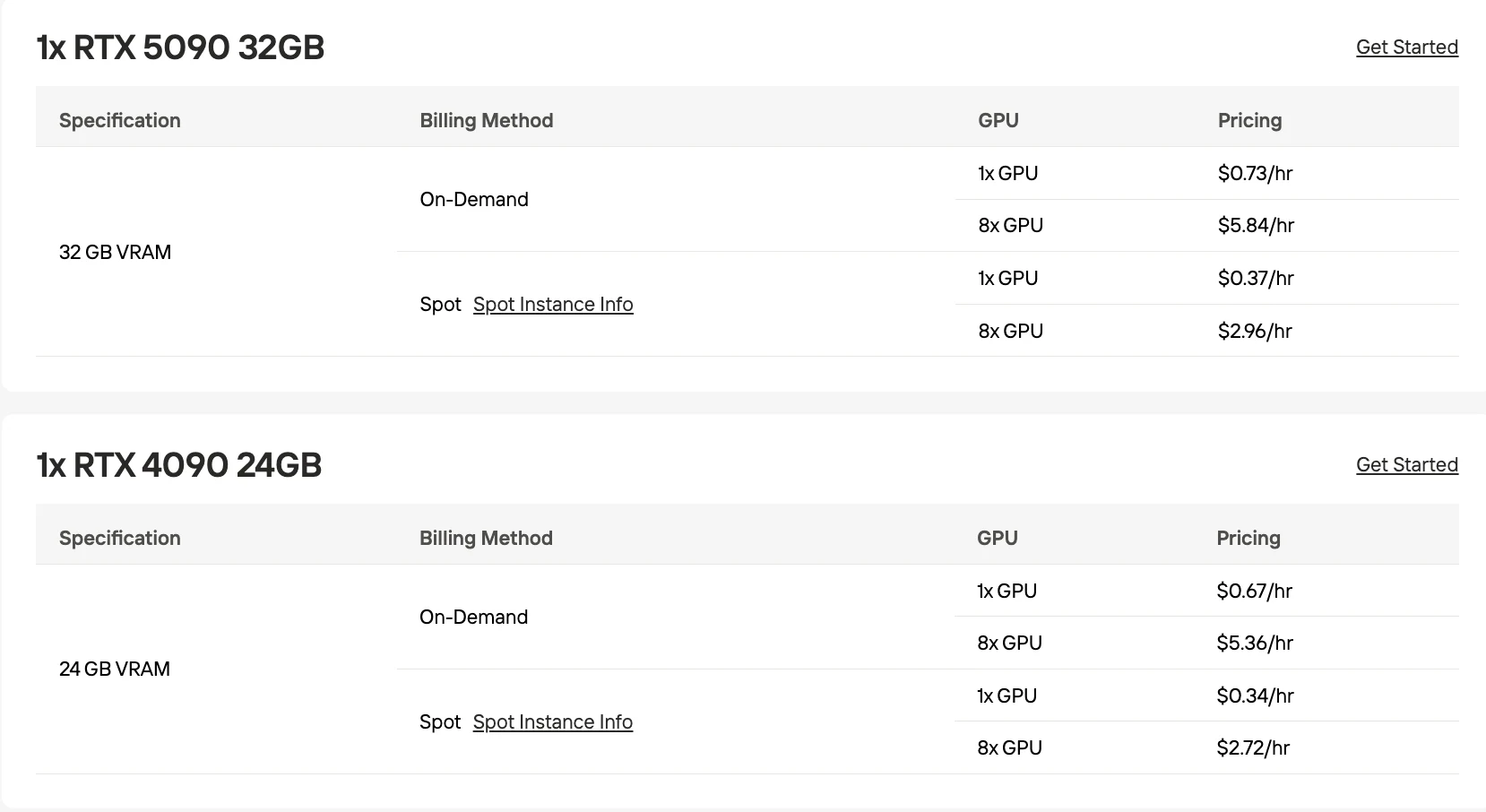
- Kostengünstige GPU-Optionen: RTX 5090 32GB für 0,73 $/Stunde bei Bedarf.
- Flexible Skalierung: Pay-as-you-go-Preise mit Bedarfs- und Spot-Instanzen – skalieren Sie von einzelnen GPUs bis zu 8-fach-GPU-Clustern.
- Docker-native Bereitstellung: Unterstützung für benutzerdefinierte Images mit öffentlichen/privaten Registrierungen beseitigt die Komplexität der Umgebungseinrichtung.
- Netzwerk-Volume-Speicher: Netzwerk-Volumes für 0,002 $/GB/Tag zur dauerhaften Modellspeicherung über Instanzen hinweg.
Jetzt kostengünstige GPUs testen!
PaddleOCR-VL-1.5 auf Novita GPU-Vorlage bereitstellen
Schritt 1: Konsolenzugriff
Starten Sie die GPU-Oberfläche und wählen Sie die Option ‘Get Started’, um auf das Bereitstellungsmanagement zuzugreifen.
Schritt 2: Paketauswahl
Suchen Sie PaddleOCR-VL-1.5 im Vorlagen-Repository und starten Sie den Installationsvorgang.
Schritt 3: Infrastruktureinrichtung
Konfigurieren Sie die Rechenparameter, einschließlich Speicherzuweisung, Speicheranforderungen und Netzwerkeinstellungen. Wählen Sie ‘Bereitstellen’, um die Einrichtung durchzuführen.
Schritt 4: Überprüfen und Erstellen
Überprüfen Sie Ihre Konfigurationsdetails und die Kostenübersicht noch einmal. Wenn Sie zufrieden sind, klicken Sie auf ‘Bereitstellen’, um den Erstellungsprozess zu starten.
Jetzt kostengünstige GPUs testen!
Novita AIs Spot-Modus ist ein kostenoptimiertes GPU-Miet system, das die ungenutzte oder freie GPU-Kapazität der Plattform nutzt. Im Gegensatz zu Bedarfsinstanzen, die dedizierte Hardware für stabile, kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – Ihr Auftrag kann pausiert oder beendet werden, wenn die GPU vom System zurückgefordert wird. Da der Spot-Modus ansonsten ungenutzte GPU-Ressourcen neu zuweist, ist er in der Regel 40–60 % günstiger als Bedarfsinstanzen.
Schritt 5: Auf die Erstellung warten
Nach dem Starten der Bereitstellung werden Sie automatisch zur Instanzverwaltungsseite weitergeleitet. Ihre Instanz wird im Hintergrund erstellt.
Schritt 6: Download-Fortschritt überwachen
Verfolgen Sie den Download-Fortschritt des Images in Echtzeit. Der Status Ihrer Instanz wechselt von ‘Pulling’ zu ‘Running’, sobald die Bereitstellung abgeschlossen ist. Detaillierte Fortschritte können Sie durch Klicken auf das Pfeilsymbol neben dem Instanznamen einsehen.
Schritt 7: Instanzstatus überprüfen
Klicken Sie auf die Schaltfläche ‘Logs’, um die Instanzprotokolle einzusehen und zu bestätigen, dass der PaddleOCR-Dienst ordnungsgemäß gestartet wurde.
Schritt 8: Zugriff auf die Umgebung
Starten Sie den Entwicklungsbereich über die ‘Connect’-Schnittstelle und initialisieren Sie dann das ‘Start Web Terminal’.
Dies ist ein Python-Testfall.
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
Laden Sie das Beispielbild herunter und führen Sie das Testskript aus:
# Download sample image for testing
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
# Copy port mapping address and replace API_URL in test.py, then run:
python test.py
# Expected output:
# Markdown document saved at markdown_0/doc.md
# Output image saved at layout_det_res_0.jpg
Optimierung der Bereitstellung von PaddleOCR-VL-1.5 auf Novita GPU-Vorlage
Stapelverarbeitungskonfiguration
Der AMD-Bereitstellungsleitfaden empfiehlt batch_size: 64 zur Optimierung des Durchsatzes. Passen Sie den Wert je nach Ihrer GPU an:
| GPU | Empfohlene Stapelgröße | Durchsatz (Dokumente/Minute) |
|---|---|---|
| RTX 5090 32GB | 32-48 | ~120-150 |
| RTX 4090 24GB | 24-32 | ~90-120 |
| H100 80GB | 64-96 | ~250-350 |
Layout-Erkennungseinstellungen
Aktivieren Sie use_layout_detection: True für komplexe Dokumente mit Tabellen, Formeln und Diagrammen. Deaktivieren Sie diese Einstellung für reine Textdokumente, um die Latenz um 30–40 % zu senken.
Fehlerbehebung bei häufigen Problemen
Problem 1: Zeitüberschreitung beim Modell-Download
Symptom: Der Container startet nicht mit der Meldung “Connection timeout to huggingface.co”
Lösung: Laden Sie das Modell im Voraus auf ein Novita-Netzwerk-Volume herunter und binden Sie es ein:
# On a temporary instance:
pip install huggingface-hub
huggingface-cli download PaddlePaddle/PaddleOCR-VL-1.5 --local-dir /mnt/models
# In Dockerfile:
ENV HF_HOME=/mnt/models
VOLUME /mnt/models
Problem 2: Speichermangel-Fehler
Symptom: CUDA out of memory während der Inferenz
Lösung: Reduzieren Sie die batch_size in Ihrer Konfiguration:
batch_size: 16 # Down from 64
gpu_memory_utilization: 0.85 # Leave 15% headroom
Problem 3: Langsame Inferenz bei komplexen Dokumenten
Symptom: Verarbeitungszeit von mehr als 5 Sekunden pro Dokument
Lösung: Deaktivieren Sie nicht benötigte Funktionen gemäß dem AMD-Optimierungsleitfaden:
- Setzen Sie
use_layout_detection: Falsefür reine Textdokumente (30–40 % schneller) - Setzen Sie
merge_layout_blocks: False, wenn Sie rohe Elementpositionen benötigen - Aktualisieren Sie auf H100 SXM 80GB für einen 2–3 Mal höheren Durchsatz bei komplexen Layouts
Die Bereitstellung von PaddleOCR-VL-1.5 auf Novita AI GPU-Instanzen ermöglicht eine produktionsgerechte Dokumentenanalyse. Die Kombination aus der Effizienz von 0.9B Parametern und Novitas flexiblen GPU-Preisen ermöglicht es Startups und Unternehmen, monatlich Millionen von Dokumenten zu verarbeiten, ohne das Budget zu sprengen.
Fazit
Die Bereitstellung von PaddleOCR-VL-1.5 auf Novita AI GPU-Vorlagen ermöglicht Ihnen eine unternehmensgerechte Dokumentenanalyse in Minuten – keine komplexe Umgebungseinrichtung, keine Kosten für ungenutzte GPUs. Mit 0.9B Parametern, 94,5 % Genauigkeit auf OmniDocBench v1.5 und flexiblen GPU-Optionen ab 0,73 $/Stunde ist es eine effiziente Lösung für Teams, die große Mengen an Dokumenten im großen Maßstab verarbeiten.
Hauptvorteil: Wählen Sie Ihre GPU-Stufe basierend auf Ihren Durchsatzanforderungen, aktivieren Sie die Stapelverarbeitung für Produktionsworkloads und nutzen Sie Spot-Instanzen, um Kosten um 40–60 % zu senken. Starten Sie jetzt auf Novita AI und stellen Sie PaddleOCR-VL-1.5 noch heute bereit.
Welche GPU benötige ich, um PaddleOCR-VL-1.5 auszuführen?
PaddleOCR-VL-1.5 läuft auf jeder GPU mit 8 GB+ VRAM; für den Produktivbetrieb wird die RTX 5090 32GB für 0,73 $/Stunde empfohlen.
Kann PaddleOCR-VL-1.5 gescannte Dokumente mit Verzerrungen verarbeiten?
Ja, die Erkennung unregelmäßiger Formen von PaddleOCR-VL-1.5 verarbeitet Schräglage, Verzerrungen und Scan-Artefakte, die am Real5-OmniDocBench-Benchmark validiert wurden.
Ist PaddleOCR-VL-1.5 für den Produktivbetrieb geeignet?
Ja. Mit 0.9B Parametern und 94,5 % Genauigkeit bietet es eine ausgewogene Balance zwischen Leistung und Effizienz, die es für unternehmensweite Dokumentenverarbeitungspipelines geeignet macht.
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu entwickeln, bereitzustellen und zu skalieren.
Empfohlene Lektüre
DeepSeek vs Qwen: Welches Ökosystem passt zu Produktionsanforderungen?
DeepSeek vs Qwen: Welches Ökosystem passt zu Produktionsanforderungen?



