

- Was ist Kimi K2.6?
- Was unterscheidet Kimi K2.6 von anderen Open-Source-Modellen?
- Wie schneidet Kimi K2.6 bei agentischen Codierungs-Benchmarks ab?
- So verwenden Sie Kimi K2.6 auf Novita AI
- Wann sollten Sie Kimi K2.6 anstelle von GPT-4o oder Claude verwenden?
- Wie viel kostet Kimi K2.6 auf Novita AI?
- Was sind die technischen Spezifikationen von Kimi K2.6?
- Ist Kimi K2.6 das richtige Modell für Ihre Agent-Pipeline?
- FAQ
Kimi K2.6: Open-Source-Agent für 13-stündige Codierungs-Sessions
Ihr Codierungs-Agent stoppt nach 20 Minuten, verbraucht den Kontext und hinterlässt einen halbfertigen PR. Sie wechseln zu einem geschlossenen Frontier-Modell – es hält länger, kostet aber 5× mehr pro Durchlauf. Kimi K2.6, Moonshot AIs neu veröffentlichtes Open-Source-Modell, wurde speziell entwickelt, um diesen Kompromiss zu durchbrechen. Bei über 4.000 Tool-Aufrufen und 13-stündigen autonomen Sitzungen erreichte es 58,6 % auf SWE-Bench Pro – und übertraf damit GPT-5.4 (57,7 %) und Claude Opus 4.6 (53,4 %) zu einem Bruchteil des Preises geschlossener Modelle. (Benchmarks stammen von kimi.com/blog/kimi-k2-6.)
Kimi K2.6 ist jetzt auf Novita AI über eine OpenAI-kompatible API verfügbar.
Kurz gesagt: Kimi K2.6 ist ein Open-Source-MoE-Modell mit 1 Billion Parametern (32B aktiviert) von Moonshot AI, spezialisiert auf agentisches Programmieren, langanhaltende Aufgabenausführung und Multi-Agent-Koordination – mit einem 256K-Kontextfenster und OpenAI-kompatiblem API-Zugang auf Novita AI.
Kimi K2.6 auf Novita AI testen →
Was ist Kimi K2.6?
Kimi K2.6 ist ein Open-Source-, natives multimodales agentisches Modell, das im April 2026 von Moonshot AI veröffentlicht wurde. Es ist eine direkte Weiterentwicklung von Kimi K2.5 – die gleiche MoE-Architektur, jetzt deutlich verbessert für reale langanhaltende Aufgaben, codierungsgesteuerte UI-Generierung und koordinierte Multi-Agent-Ausführung.
Im Kern ist K2.6 ein Mixture-of-Experts (MoE)-Modell mit 1 Billion Parametern, von denen nur 32B Parameter pro Token aktiviert werden – was ihm Reasoning auf Frontier-Niveau bei Rechenkosten ermöglicht, die näher an einem dichten 30B-Modell liegen. Die Architektur verwendet Multi-head Latent Attention (MLA), SwiGLU-Aktivierungen, 384 Experten mit 8 ausgewählten pro Token und ein 256K-Token-Kontextfenster. Das Modell wird unter einer modifizierten MIT-Lizenz veröffentlicht.
Wichtige Fähigkeiten auf einen Blick:
- Langanhaltendes Codieren – dauerhafte autonome Ausführung über Stunden und Tausende von Tool-Aufrufen
- Mehrsprachige Generalisierung – starke Leistung in Rust, Go, Python und Nischensprachen wie Zig
- Codierungsgesteuertes Design – wandelt Prompts und visuelle Eingaben in produktionsreife Frontend-Schnittstellen um
- Agentenschwarm-Skalierung – koordiniert bis zu 300 Sub-Agenten über 4.000 parallele Schritte
- Nativ multimodal – verarbeitet Bilder und Text nativ über den MoonViT-Visionsencoder
- Funktionsaufruf & strukturierte Ausgabe – OpenAI-kompatible Tool-Nutzung, ideal für den Aufbau von Agent-Pipelines und RAG-Systemen
Was unterscheidet Kimi K2.6 von anderen Open-Source-Modellen?
Langanhaltendes Codieren
Die meisten LLMs lassen nach einigen hundert Tool-Aufrufen nach. K2.6 wurde explizit für mehrstündige Sitzungen mit mehreren tausend Aufrufen trainiert. In einer Benchmark-Aufgabe stellte es ein lokales Qwen3.5-0.8B-Modell auf einem Mac bereit, schrieb seine Inference-Engine in Zig über 12 Stunden und über 4.000 Tool-Aufrufe um und verbesserte den Durchsatz von ~15 auf ~193 Tokens/Sekunde – etwa 20 % schneller als LM Studio. In einer anderen Aufgabe refaktorierte es autonom eine 8 Jahre alte Finanz-Matching-Engine (exchange-core) in einer 13-stündigen Sitzung, führte 12 Optimierungsstrategien aus und modifizierte über 4.000 Zeilen Code für eine Durchsatzsteigerung von 185 %.

Kimi Code Bench: K2.6 erreicht 68.2 gegenüber 57.4 von K2.5 (+19 %). [Quelle: Kimi Official Blog]
Laut dem Launch-Blog von Moonshot AI stellten Beta-Partner wie Baseten, Blackbox.ai, Factory.ai und Fireworks.ai fest, dass K2.6 „die architektonische Integrität über längere Codierungs-Sitzungen hinweg bewahrt“ und „nicht offensichtliche Fehler aufdeckt, die normalerweise erhebliche Entwicklerzeit in Anspruch nehmen würden“.
Codierungsgesteuertes Design
K2.6 kann strukturierte Frontend-Layouts, interaktive Elemente, scroll-ausgelöste Animationen und schlanke Full-Stack-Workflows – Authentifizierung, Sitzungsverwaltung, Datenbankoperationen – aus einem einfachen Text- oder Bild-Prompt generieren. Moonshot AIs interner Kimi Design Bench, der visuelle Eingabeaufgaben, Landing-Page-Konstruktion, Full-Stack-App-Entwicklung und allgemeines kreatives Programmieren abdeckt, zeigt K2.6 wettbewerbsfähig mit Google AI Studio in allen vier Kategorien.
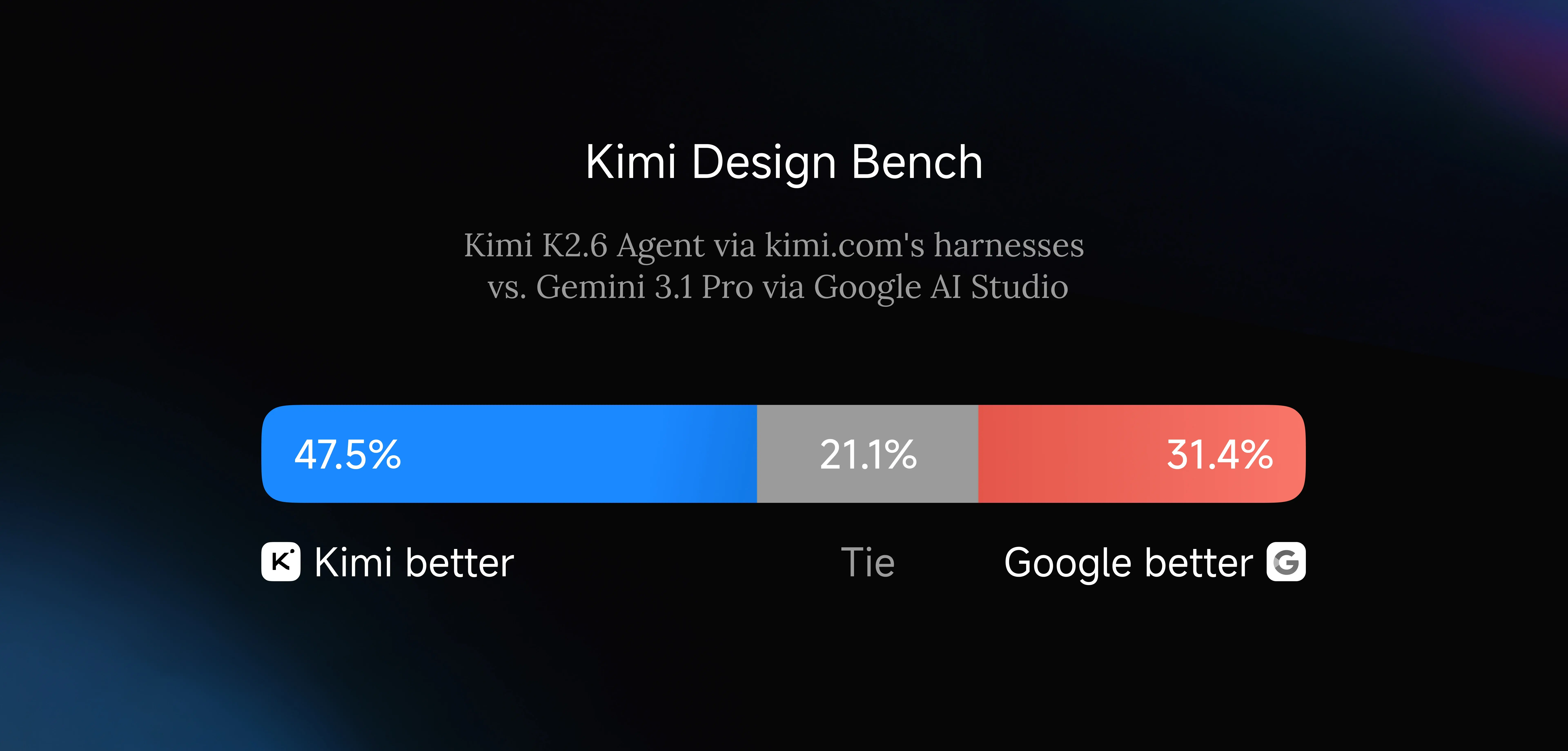
Kimi Design Bench: K2.6 (47.5 %) übertrifft Google AI Studio (31.4 %) bei UI-Generierungsaufgaben. [Quelle: Kimi Official Blog]
Erweiterter Agentenschwarm
K2.6 skaliert die Agentenschwarm-Architektur von K2.5s 100 Sub-Agenten / 1.500 Schritten auf 300 Sub-Agenten, die gleichzeitig über 4.000 koordinierte Schritte ausgeführt werden. Der Koordinator weist Agenten basierend auf Fähigkeitsprofilen dynamisch Aufgaben zu, erkennt Fehler, weist Arbeiten neu zu und verwaltet den gesamten Lebenszyklus von der Initiierung bis zur Validierung. Die Ergebnisse umfassen Dokumente, Websites, Folien und Tabellenkalkulationen – erstellt in einem einzigen autonomen Durchlauf. Moonshot AIs eigenes Marketingteam verwendet intern eine K2.6-gestützte Claw Group mit spezialisierten Agenten für Demo-Erstellung, Benchmarking, soziale Medien und Videoproduktion, die alle von K2.6 koordiniert werden.

Kimi Claw Bench: K2.6 erreicht 65.5 gegenüber 59.6 von K2.5 (+9.9 %) bei mehrstufigen Agentenaufgaben. [Quelle: Kimi Official Blog]
Proaktive Hintergrundagenten
Einer der beeindruckendsten Anwendungsfälle von K2.6 aus Moonshots eigenem RL-Infrastrukturteam: Ein K2.6-gestützter Agent lief autonom 5 Tage lang und übernahm Monitoring, Incident Response und Systemoperationen – persistenter Kontext, Multithread-Aufgabenverwaltung und vollständige Ausführung vom Alarm bis zur Lösung, ohne menschliches Eingreifen. Diese Art von persistentem 24/7-Hintergrundagenten ist ein spezifisches Designziel von K2.6.
Wie schneidet Kimi K2.6 bei agentischen Codierungs-Benchmarks ab?
K2.6 konkurriert direkt mit den besten Closed-Source-Modellen. Es führt bei den Benchmarks, die für agentische Codierungs-Workflows am relevantesten sind:
Codierungs-Benchmarks (Zuletzt geprüft: 2026-04-21, Quelle: kimi.com/blog/kimi-k2-6)
| Benchmark | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max) | Gemini 3.1 Pro (thinking) | Kimi K2.5 |
|---|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | 54.2 | 50.7 |
| SWE-Bench Verified | 80.2 | — | 80.8 | 80.6 | 76.8 |
| SWE-Bench Multilingual | 76.7 | — | 77.8 | 76.9 | 73.0 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | 65.4 | 68.5 | 50.8 |
| LiveCodeBench (v6) | 89.6 | — | 88.8 | 91.7 | 85.0 |
Agentische Benchmarks (Zuletzt geprüft: 2026-04-21)
| Benchmark | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max) | Gemini 3.1 Pro | Kimi K2.5 |
|---|---|---|---|---|---|
| HLE-Full w/ tools | 54.0 | 52.1 | 53.0 | 51.4 | 50.2 |
| DeepSearchQA (f1-score) | 92.5 | 78.6 | 91.3 | 81.9 | 89.0 |
| BrowseComp | 83.2 | 82.7 | 83.7 | 85.9 | 74.9 |
| OSWorld-Verified | 73.1 | 75.0 | 72.7 | — | 63.3 |
| Toolathlon | 50.0 | 54.6 | 47.2 | 48.8 | 27.8 |
Die Schlagzeile: K2.6 führt bei SWE-Bench Pro (58.6 %) vor allen Modellen und übertrifft GPT-5.4 und Claude Opus 4.6 bei Terminal-Bench 2.0 und DeepSearchQA mit bemerkenswertem Abstand. Gemini 3.1 Pro liegt bei Terminal-Bench (68.5 vs. 66.7) und LiveCodeBench knapp vorn. Seine Reasoning-Ergebnisse (AIME 2026: 96.4 %, GPQA-Diamond: 90.5 %) sind wettbewerbsfähig, liegen aber hinter Gemini und GPT-5.4 – dies ist ein codierungsorientiertes Modell, kein Mathe-Olympiade-Spezialist.
So verwenden Sie Kimi K2.6 auf Novita AI
Option 1: Playground
Navigieren Sie zu Kimi K2.6 auf Novita AI und klicken Sie Try in Playground. Es ist kein API-Schlüssel erforderlich, um zu beginnen.
Option 2: API (Python)
Kimi K2.6 ist vollständig OpenAI-kompatibel. Tauschen Sie die Novita-Basis-URL und Ihren API-Schlüssel ein:
pip install openai
from openai import OpenAI
client = OpenAI(
api_key="IHR_NOVITA_API_SCHLÜSSEL",
base_url="https://api.novita.ai/v3/openai",
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[
{"role": "system", "content": "Sie sind ein hilfreicher Assistent."},
{"role": "user", "content": "Ihr Prompt hier"}
],
max_tokens=8192,
temperature=0.7,
)
print(response.choices[0].message.content)
Holen Sie sich Ihren API-Schlüssel unter novita.ai/settings.
Option 3: Drittanbieter-Tools
Da Novitas API OpenAI-kompatibel ist, funktioniert Kimi K2.6 sofort mit LangChain, LlamaIndex, OpenWebUI und Codierungsassistenten wie Cursor oder Continue. Setzen Sie die Basis-URL auf https://api.novita.ai/v3/openai und den Modellnamen auf moonshotai/kimi-k2.6.
Wann sollten Sie Kimi K2.6 anstelle von GPT-4o oder Claude verwenden?
Szenario 1: Langlaufende Engineering-Agenten
K2.6 eignet sich gut für langlaufende Engineering-Agenten – Refactoring von Legacy-Codebasen, CI/CD-Pipeline-Debugging und Infrastrukturoptimierung. Seine Kimi Code Bench-Ergebnisse und die exchange-core-Fallstudie zeigen, dass es die Aufgabenkohärenz über Tausende von Tool-Aufrufen hinweg bewahrt, ohne vom ursprünglichen Ziel abzuweichen.
Szenario 2: Design-to-Code-Pipelines
Designer geben einen Mockup ab; K2.6 produziert eine funktionierende React/HTML/CSS-Implementierung mit Animationen und responsiven Layouts. Der native multimodale Input des Modells (über MoonViT) bedeutet, dass es die Bildreferenz direkt verarbeitet, anstatt sich auf eine verbale Beschreibung zu verlassen. Dies macht es zu einem starken Backbone für KI-gestützte UI-Generierungs-Workflows.
Szenario 3: Multi-Agent-Orchestrierung
Wenn Sie spezialisierte Agenten parallel koordinieren müssen – einer scraped Daten, ein anderer schreibt Analysen, ein dritter formatiert die Ausgabe – fungiert K2.6 als Koordinationsschicht. Seine Architektur mit 300 Agenten / 4.000 Schritten macht es zu einer praktischen Wahl für Content-Pipelines, Research-Workflows oder jede Aufgabe, bei der parallele Spezialisierung die Latenz im Vergleich zu sequenziellen Einzelagentenläufen reduziert.
Szenario 4: Migration von Claude- oder GPT-4o-Agent-Pipelines
Wenn Sie agentische Codierungs-Workflows auf Claude Opus oder GPT-4o betreiben und Kosten senken möchten, ohne die Zuverlässigkeit zu opfern, ist K2.6 ein starker Open-Source-Drop-In-Ersatz. Sein SWE-Bench Pro-Score (58.6 %) übertrifft sowohl Claude Opus 4.6 (53.4 %) als auch GPT-5.4 (57.7 %) im gleichen Benchmark. Die OpenAI-kompatible API bedeutet, dass die Migration eine Änderung in einer Zeile ist.
Wie viel kostet Kimi K2.6 auf Novita AI?
Kimi K2.6 auf Novita AI ist wie folgt bepreist (Zuletzt geprüft: 2026-04-21):
| Modell | Eingabe ($/M Tokens) | Cache-Lesen ($/M Tokens) | Ausgabe ($/M Tokens) | Kontext |
|---|---|---|---|---|
| Kimi K2.6 | $0.95 | $0.16 | $4.00 | 262K |
| Kimi K2.5 | $0.60 | $0.10 | $3.00 | 262K |
Bei langanhaltenden agentischen Läufen mit hohen Cache-Trefferquoten macht der Preis von $0.16/M für Cache-Lesen verlängerte autonome Sitzungen materiell günstiger, als der nominelle Eingabepreis vermuten lässt.
Was sind die technischen Spezifikationen von Kimi K2.6?
| Eigenschaft | Wert |
|---|---|
| Architektur | Mixture-of-Experts (MoE) |
| Parameter gesamt | 1T |
| Aktivierte Parameter | 32B |
| Anzahl der Schichten | 61 (inkl. 1 dichte Schicht) |
| Anzahl der Experten | 384 |
| Ausgewählte Experten pro Token | 8 |
| Kontextlänge | 256K Tokens |
| Aufmerksamkeitsmechanismus | MLA (Multi-head Latent Attention) |
| Visionsencoder | MoonViT |
| Vokabulargröße | 160K |
| Lizenz | Modifizierte MIT-Lizenz |
Vollständige Architekturdetails, Gewichte und Evaluierungscode sind auf der Kimi K2.6 HuggingFace-Modellkarte verfügbar. Die Benchmark-Methodik wurde im Moonshot AI Blog veröffentlicht.
Ist Kimi K2.6 das richtige Modell für Ihre Agent-Pipeline?
Fazit: Kimi K2.6 ist eines der stärksten Open-Source-Modelle für langanhaltendes agentisches Programmieren im April 2026. Sein SWE-Bench Pro-Score von 58.6 % übertrifft mehrere Closed-Source-Modelle in diesen Benchmarks, sein 256K-Kontext und die MoE-Architektur halten die Inferenzkosten angemessen, was es zu einer überzeugenden Alternative zu Claude oder GPT-4o für Entwickler von Agent-Pipelines macht.
Es ist nicht das insgesamt beste Reasoning-Modell – GPT-5.4 und Gemini 3.1 Pro führen bei reiner Mathematik (AIME, HLE ohne Tools). Aber für Entwickler, die Codierungs-Agenten, Design-to-Code-Pipelines oder Multi-Agent-Orchestrierungssysteme bauen, ist K2.6 eine starke Open-Source-Option, die heute auf der Novita AI API verfügbar ist.
Empfohlene Lektüre
- So greifen Sie auf Kimi K2.5 zu: Web, API, Claude Code, Self-Host
- Die 8 besten KI-Inferenzplattformen im Jahr 2026
- Qwen3 Coder vs DeepSeek V3.1: Das richtige LLM für Ihr Programm auswählen
FAQ
Was ist Kimi K2.6?
Kimi K2.6 ist ein Open-Source-, natives multimodales agentisches Modell von Moonshot AI, veröffentlicht im April 2026. Es ist ein Mixture-of-Experts-Modell mit 1 Billion Parametern (32B aktiviert) mit einem 256K-Kontextfenster, entwickelt für langanhaltendes Codieren, autonome Agentenausführung und Multi-Agent-Schwarmkoordination.
Wie greife ich über die API auf Novita AI auf Kimi K2.6 zu?
Verwenden Sie das OpenAI Python SDK mit base_url="https://api.novita.ai/v3/openai" und der Modell-ID moonshotai/kimi-k2.6. Holen Sie sich Ihren API-Schlüssel unter novita.ai/settings. Es ist kein spezielles SDK oder Wrapper erforderlich.
Wie schneidet Kimi K2.6 im Vergleich zu Claude Opus 4.6 bei Codierungsaufgaben ab?
Bei SWE-Bench Pro erreicht Kimi K2.6 58.6 % vs. Claude Opus 4.6s 53.4 % – eine Lücke von 5 Punkten bei realen Softwareentwicklungsaufgaben. K2.6 übertrifft Claude auch bei DeepSearchQA (92.5 % vs. 91.3 %) und Terminal-Bench 2.0 (66.7 % vs. 65.4 %); Gemini 3.1 Pro führt Terminal-Bench mit 68.5 % an. Bei reinen Reasoning-Benchmarks wie AIME oder HLE ohne Tools hat Claude Opus 4.6 einen leichten Vorteil.
Wie groß ist das Kontextfenster von Kimi K2.6?
Kimi K2.6 unterstützt ein Kontextfenster von 256K Tokens (262.144 Tokens). Auf Novita AI sind sowohl die Kontextlänge als auch die maximale Ausgabe auf 262.144 Tokens eingestellt, was es für die Analyse langer Dokumente und langanhaltende mehrschrittige agentische Sitzungen geeignet macht.
Wie ist die Preisgestaltung für Kimi K2.6 auf Novita AI?
Auf Novita AI kostet Kimi K2.6 $0.95 pro Million Eingabe-Tokens, $0.16 pro Million Cache-Lese-Tokens und $4.00 pro Million Ausgabe-Tokens. Das 256K-Kontextfenster und die maximale Ausgabe sind beide enthalten. Aktuelle Preise auf Novita AI ansehen.
Novita AI ist eine AI & Agent Cloud für Entwickler – bietet über 200 Modelle über serverlose API sowie Agent Sandbox-Infrastruktur und GPU Cloud. Bauen, skalieren und bereitstellen Sie KI-Anwendungen, ohne Infrastruktur zu verwalten. Erste Schritte bei novita.ai.



