

- Qu'est-ce que Kimi K2.6 ?
- Qu'est-ce qui rend Kimi K2.6 différent des autres modèles open-source ?
- Comment Kimi K2.6 se comporte-t-il sur les benchmarks de codage agentique ?
- Comment utiliser Kimi K2.6 sur Novita AI
- Quand utiliser Kimi K2.6 plutôt que GPT-4o ou Claude ?
- Combien coûte Kimi K2.6 sur Novita AI ?
- Quelles sont les spécifications techniques de Kimi K2.6 ?
- Kimi K2.6 est-il le bon modèle pour votre pipeline d'agents ?
- FAQ
Kimi K2.6 : un agent open-source pour des sessions de codage de 13 heures
Votre agent de codage s’arrête au bout de 20 minutes, épuise le contexte et vous laisse avec une pull request à moitié terminée. Vous passez à un modèle propriétaire de pointe : il dure plus longtemps mais coûte 5 fois plus par exécution. Kimi K2.6, le nouveau modèle open-source de Moonshot AI, a été spécifiquement conçu pour briser ce compromis. Sur plus de 4 000 appels d’outils et des sessions autonomes de 13 heures, il a obtenu 58,6% sur SWE-Bench Pro — devançant GPT-5.4 (57,7%) et surpassant Claude Opus 4.6 (53,4%) — à une fraction du prix des modèles propriétaires. (Benchmarks issus de kimi.com/blog/kimi-k2-6.)
Kimi K2.6 est désormais disponible sur Novita AI via une API compatible OpenAI.
En bref : Kimi K2.6 est un modèle open-source MoE de 1 000 milliards de paramètres (32B activés) de Moonshot AI, spécialisé dans le codage agentique, l’exécution de tâches longue durée et la coordination multi-agents — avec une fenêtre de contexte de 256K et un accès API compatible OpenAI sur Novita AI.
Essayez Kimi K2.6 sur Novita AI →
Qu’est-ce que Kimi K2.6 ?
Kimi K2.6 est un modèle agentique multimodal natif open-source publié par Moonshot AI en avril 2026. C’est une évolution directe de Kimi K2.5 — la même architecture MoE, désormais considérablement améliorée pour les tâches réelles de longue durée, la génération d’interfaces utilisateur par codage et l’exécution multi-agents coordonnée.
À la base, K2.6 est un modèle Mixture-of-Experts (MoE) de 1 000 milliards de paramètres avec seulement 32B paramètres activés par token — offrant un raisonnement de niveau avancé pour un coût de calcul proche d’un modèle dense de 30B. L’architecture utilise l’attention multi-tête latente (MLA), les activations SwiGLU, 384 experts dont 8 sélectionnés par token, et une fenêtre de contexte de 256K tokens. Le modèle est publié sous une licence MIT modifiée.
Principales capacités en un coup d’œil :
- Codage longue durée — exécution autonome soutenue pendant des heures et des milliers d’appels d’outils
- Généralisation multi-langages — bonnes performances en Rust, Go, Python et langages de niche comme Zig
- Conception pilotée par le codage — transforme des invites et des entrées visuelles en interfaces front-end prêtes pour la production
- Évolution du Swarm d’agents — coordonne jusqu’à 300 sous-agents sur 4 000 étapes parallèles
- Multimodal natif — traite les images et le texte de manière native via l’encodeur visuel MoonViT
- Appel de fonctions et sortie structurée — utilisation d’outils compatible OpenAI, idéal pour construire des pipelines d’agents et des systèmes RAG
Qu’est-ce qui rend Kimi K2.6 différent des autres modèles open-source ?
Codage longue durée
La plupart des LLM se dégradent après quelques centaines d’appels d’outils. K2.6 a été explicitement entraîné pour des sessions de plusieurs heures et plusieurs milliers d’appels. Dans une tâche de benchmark, il a déployé un modèle local Qwen3.5-0.8B sur un Mac, réécrit son moteur d’inférence en Zig en 12 heures et plus de 4 000 appels d’outils, et amélioré le débit d’environ 15 à ~193 tokens/seconde — environ 20% plus rapide que LM Studio. Dans un autre test, il a refactorisé de manière autonome un moteur financier vieux de 8 ans (exchange-core) au cours d’une session de 13 heures, exécutant 12 stratégies d’optimisation et modifiant plus de 4 000 lignes de code pour un gain de débit de 185%.

Kimi Code Bench : K2.6 obtient 68,2 contre 57,4 pour K2.5 (+19%). [Source : Blog officiel de Kimi]
Selon le blog de lancement de Moonshot AI, les partenaires bêta, dont Baseten, Blackbox.ai, Factory.ai et Fireworks.ai, ont noté que K2.6 maintient « l’intégrité architecturale sur de longues sessions de codage » et met en évidence des « bogues non évidents qui prendraient normalement beaucoup de temps aux développeurs pour être découverts. »
Conception pilotée par le codage
K2.6 peut générer des mises en page front-end structurées, des éléments interactifs, des animations déclenchées par défilement et des workflows full-stack légers — authentification, gestion de session, opérations de base de données — à partir d’une simple invite textuelle ou image. Le Kimi Design Bench interne de Moonshot AI, qui couvre les tâches d’entrée visuelle, la construction de pages d’atterrissage, le développement d’applications full-stack et la programmation créative générale, montre K2.6 compétitif avec Google AI Studio dans les quatre catégories.
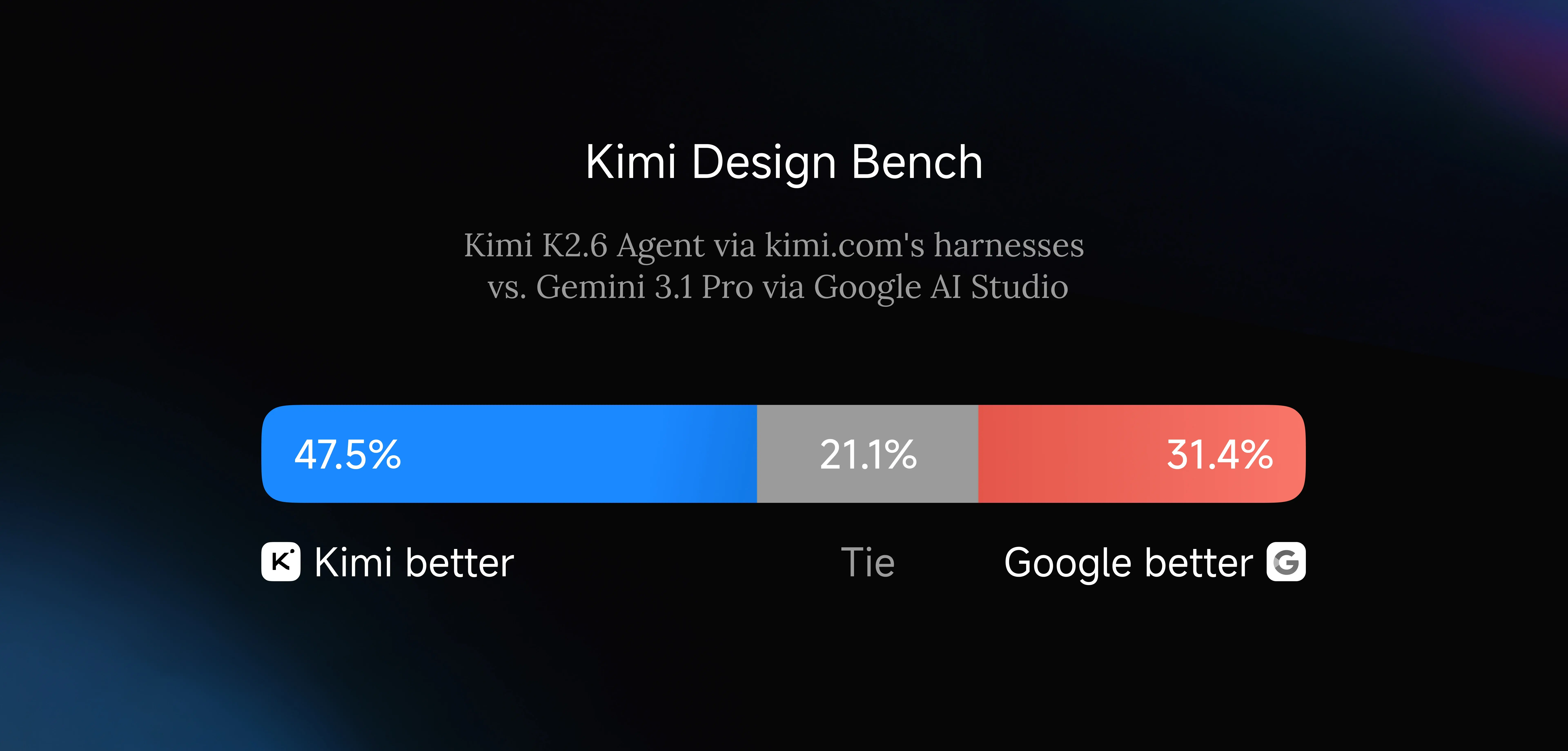
Kimi Design Bench : K2.6 (47,5%) surpasse Google AI Studio (31,4%) sur les tâches de génération d’UI. [Source : Blog officiel de Kimi]
Swarm d’agents amélioré
K2.6 fait passer l’architecture de swarm d’agents de K2.5 (100 sous-agents / 1 500 étapes) à 300 sous-agents exécutant simultanément 4 000 étapes coordonnées. Le coordinateur attribue dynamiquement des tâches aux agents en fonction des profils de compétences, détecte les échecs, réaffecte le travail et gère l’ensemble du cycle de vie, de l’initiation à la validation. Les sorties incluent des documents, des sites Web, des diapositives et des feuilles de calcul — produits en une seule exécution autonome. L’équipe marketing interne de Moonshot AI utilise un Claw Group basé sur K2.6, avec des agents spécialisés pour la création de démos, le benchmarking, les réseaux sociaux et la production vidéo, tous coordonnés par K2.6.

Kimi Claw Bench : K2.6 obtient 65,5 contre 59,6 pour K2.5 (+9,9%) sur des tâches multi-étapes. [Source : Blog officiel de Kimi]
Agents d’arrière-plan proactifs
Un cas d’usage frappant de K2.6 rapporté par l’équipe d’infrastructure RL de Moonshot : un agent basé sur K2.6 a fonctionné de manière autonome pendant 5 jours, gérant la surveillance, la réponse aux incidents et les opérations système — contexte persistant, gestion de tâches multi-thread et exécution complète du cycle de l’alerte à la résolution, sans intervention humaine. Ce type d’agent d’arrière-plan persistant 24h/24 et 7j/7 est une cible de conception spécifique pour K2.6.
Comment Kimi K2.6 se comporte-t-il sur les benchmarks de codage agentique ?
K2.6 concurrence directement les meilleurs modèles propriétaires. Il est en tête sur les benchmarks les plus pertinents pour les workflows de codage agentique :
Benchmarks de codage (Dernière vérification : 21/04/2026, source : kimi.com/blog/kimi-k2-6)
| Benchmark | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max) | Gemini 3.1 Pro (thinking) | Kimi K2.5 |
|---|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | 54.2 | 50.7 |
| SWE-Bench Verified | 80.2 | — | 80.8 | 80.6 | 76.8 |
| SWE-Bench Multilingual | 76.7 | — | 77.8 | 76.9 | 73.0 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | 65.4 | 68.5 | 50.8 |
| LiveCodeBench (v6) | 89.6 | — | 88.8 | 91.7 | 85.0 |
Benchmarks agentiques (Dernière vérification : 21/04/2026)
| Benchmark | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max) | Gemini 3.1 Pro | Kimi K2.5 |
|---|---|---|---|---|---|
| HLE-Full avec outils | 54.0 | 52.1 | 53.0 | 51.4 | 50.2 |
| DeepSearchQA (f1-score) | 92.5 | 78.6 | 91.3 | 81.9 | 89.0 |
| BrowseComp | 83.2 | 82.7 | 83.7 | 85.9 | 74.9 |
| OSWorld-Verified | 73.1 | 75.0 | 72.7 | — | 63.3 |
| Toolathlon | 50.0 | 54.6 | 47.2 | 48.8 | 27.8 |
Le principal enseignement : K2.6 est en tête de tous les modèles sur SWE-Bench Pro (58,6%) et surpasse GPT-5.4 et Claude Opus 4.6 sur Terminal-Bench 2.0 et DeepSearchQA avec une marge notable. Gemini 3.1 Pro le devance sur Terminal-Bench (68.5 contre 66.7) et LiveCodeBench. Ses scores de raisonnement (AIME 2026 : 96,4%, GPQA-Diamond : 90,5%) sont compétitifs mais derrière Gemini et GPT-5.4 — c’est un modèle axé sur le codage, pas un spécialiste des olympiades de mathématiques.
Comment utiliser Kimi K2.6 sur Novita AI
Option 1 : Playground
Accédez à Kimi K2.6 sur Novita AI et cliquez sur Essayer dans le Playground. Aucune clé API requise pour commencer.
Option 2 : API (Python)
Kimi K2.6 est entièrement compatible OpenAI. Remplacez l’URL de base de Novita et votre clé API :
pip install openai
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API_NOVITA",
base_url="https://api.novita.ai/v3/openai",
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[
{"role": "system", "content": "Vous êtes un assistant utile."},
{"role": "user", "content": "Votre invite ici"}
],
max_tokens=8192,
temperature=0.7,
)
print(response.choices[0].message.content)
Obtenez votre clé API sur novita.ai/settings.
Option 3 : Outils tiers
Comme l’API de Novita est compatible OpenAI, Kimi K2.6 fonctionne directement avec LangChain, LlamaIndex, OpenWebUI et des assistants de codage comme Cursor ou Continue. Pointez l’URL de base vers https://api.novita.ai/v3/openai et définissez le nom du modèle sur moonshotai/kimi-k2.6.
Quand utiliser Kimi K2.6 plutôt que GPT-4o ou Claude ?
Scénario 1 : Agents d’ingénierie longue durée
K2.6 est bien adapté pour les agents d’ingénierie longue durée — refactorisation de code legacy, débogage de pipelines CI/CD et optimisation d’infrastructure. Ses résultats sur Kimi Code Bench et l’étude de cas exchange-core montrent qu’il maintient la cohérence des tâches sur des milliers d’appels d’outils sans s’écarter de l’objectif initial.
Scénario 2 : Pipelines conception-vers-code
Les designers déposent une maquette ; K2.6 produit une implémentation React/HTML/CSS fonctionnelle avec animations et mises en page responsives. L’entrée multimodale native du modèle (via MoonViT) lui permet de traiter directement l’image de référence plutôt que de se fier à une description verbale. Cela en fait un socle solide pour les workflows de génération d’UI assistée par IA.
Scénario 3 : Orchestration multi-agents
Lorsque vous devez coordonner des agents spécialisés en parallèle — l’un collecte des données, un autre rédige une analyse, un troisième formate la sortie — K2.6 agit comme la couche de coordination. Son architecture de 300 agents / 4 000 étapes en fait un choix pratique pour les pipelines de contenu, les workflows de recherche ou toute tâche où la spécialisation parallèle réduit la latence par rapport aux exécutions séquentielles à agent unique.
Scénario 4 : Migration depuis les pipelines agents Claude ou GPT-4o
Si vous utilisez des workflows de codage agentique sur Claude Opus ou GPT-4o et cherchez à réduire les coûts sans sacrifier la fiabilité, K2.6 est une alternative open-source puissante. Son score SWE-Bench Pro (58,6%) dépasse à la fois Claude Opus 4.6 (53,4%) et GPT-5.4 (57,7%) sur le même benchmark. L’API compatible OpenAI rend la migration aussi simple qu’un changement de ligne.
Combien coûte Kimi K2.6 sur Novita AI ?
Les tarifs de Kimi K2.6 sur Novita AI sont les suivants (Dernière vérification : 21/04/2026) :
| Modèle | Entrée ($/M tokens) | Cache Read ($/M tokens) | Sortie ($/M tokens) | Contexte |
|---|---|---|---|---|
| Kimi K2.6 | 0,95 $ | 0,16 $ | 4,00 $ | 262K |
| Kimi K2.5 | 0,60 $ | 0,10 $ | 3,00 $ | 262K |
Pour les exécutions agentiques longue durée où les taux de cache hit sont élevés, le prix de 0,16 $/M pour la lecture du cache rend les sessions autonomes étendues considérablement moins chères que le prix d’entrée affiché ne le suggère.
Quelles sont les spécifications techniques de Kimi K2.6 ?
| Propriété | Valeur |
|---|---|
| Architecture | Mixture-of-Experts (MoE) |
| Paramètres totaux | 1T |
| Paramètres activés | 32B |
| Nombre de couches | 61 (dont 1 couche dense) |
| Nombre d’experts | 384 |
| Experts sélectionnés par token | 8 |
| Longueur du contexte | 256K tokens |
| Mécanisme d’attention | MLA (Multi-head Latent Attention) |
| Encodeur visuel | MoonViT |
| Taille du vocabulaire | 160K |
| Licence | MIT modifiée |
Détails complets de l’architecture, poids et code d’évaluation disponibles sur la fiche du modèle Kimi K2.6 sur HuggingFace. La méthodologie des benchmarks est publiée sur le blog de Moonshot AI.
Kimi K2.6 est-il le bon modèle pour votre pipeline d’agents ?
En résumé : Kimi K2.6 est l’un des modèles open-source les plus puissants pour le codage agentique longue durée en avril 2026. Son score SWE-Bench Pro de 58,6% surpasse plusieurs modèles propriétaires sur ces benchmarks, son contexte de 256K et son architecture MoE maintiennent des coûts d’inférence raisonnables, ce qui en fait une alternative convaincante à Claude ou GPT-4o pour les développeurs de pipelines d’agents.
Ce n’est pas le meilleur modèle de raisonnement global — GPT-5.4 et Gemini 3.1 Pro sont en tête sur les mathématiques pures (AIME, HLE sans outils). Mais pour les développeurs construisant des agents de codage, des pipelines conception-vers-code ou des systèmes d’orchestration multi-agents, K2.6 est une option open-source solide disponible aujourd’hui sur l’API Novita AI.
Lectures recommandées
- Comment accéder à Kimi K2.5 : Web, API, Claude Code, auto-hébergement
- Top 8 des plateformes d’inférence IA en 2026
- Qwen3 Coder vs DeepSeek V3.1 : choisir le bon LLM pour votre programme
Essayez Kimi K2.6 gratuitement →
FAQ
Qu’est-ce que Kimi K2.6 ?
Kimi K2.6 est un modèle agentique multimodal natif open-source de Moonshot AI, publié en avril 2026. C’est un modèle Mixture-of-Experts de 1 000 milliards de paramètres (32B activés) avec une fenêtre de contexte de 256K, conçu pour le codage longue durée, l’exécution autonome d’agents et la coordination de swarms multi-agents.
Comment accéder à Kimi K2.6 via l’API sur Novita AI ?
Utilisez le SDK Python OpenAI avec base_url="https://api.novita.ai/v3/openai" et l’ID du modèle moonshotai/kimi-k2.6. Obtenez votre clé API sur novita.ai/settings. Aucun SDK ou wrapper spécial n’est requis.
Comment Kimi K2.6 se compare-t-il à Claude Opus 4.6 pour les tâches de codage ?
Sur SWE-Bench Pro, Kimi K2.6 obtient 58,6% contre 53,4% pour Claude Opus 4.6 — un écart de 5 points sur des tâches d’ingénierie logicielle réelles. K2.6 bat également Claude sur DeepSearchQA (92,5% contre 91,3%) et Terminal-Bench 2.0 (66,7% contre 65,4%) ; Gemini 3.1 Pro est en tête sur Terminal-Bench avec 68,5%. Pour les benchmarks de raisonnement pur comme AIME ou HLE sans outils, Claude Opus 4.6 conserve un léger avantage.
Quelle est la fenêtre de contexte de Kimi K2.6 ?
Kimi K2.6 prend en charge une fenêtre de contexte de 256K tokens (262 144 tokens). Sur Novita AI, la longueur du contexte et la sortie maximale sont toutes deux fixées à 262 144 tokens, ce qui le rend adapté à l’analyse de longs documents et aux sessions agentiques multi-tours soutenues.
Quels sont les tarifs de Kimi K2.6 sur Novita AI ?
Sur Novita AI, Kimi K2.6 est proposé à 0,95 $ par million de tokens d’entrée, 0,16 $ par million de tokens de cache lus et 4,00 $ par million de tokens de sortie. La fenêtre de contexte de 256K et la sortie maximale sont incluses. Consultez les tarifs actuels sur Novita AI.
Novita AI est un cloud IA et d’agents pour les développeurs — offrant plus de 200 modèles via une API serverless, ainsi qu’une infrastructure Agent Sandbox et un cloud GPU. Créez, déployez et scalez des applications IA sans gérer d’infrastructure. Commencez sur novita.ai.



