

Ключевые моменты
LLaMA 3.3 70B — это современная языковая модель с впечатляющими возможностями.
Тонкая настройка позволяет адаптировать LLaMA 3.3 70B для конкретных задач, повышая точность и релевантность.
Несмотря на то, что RTX 4090 — мощный GPU, его ограничения по памяти могут сделать тонкую настройку LLaMA 3.3 70B сложной задачей.
Методы эффективной настройки параметров (PEFT), такие как LoRA и QLoRA, помогают смягчить эти ограничения.
Облачные GPU-инстансы представляют собой жизнеспособную альтернативу для тонкой настройки больших моделей, таких как LLaMA 3.3 70B. Вы можете использовать GPU-инстансы от Novita AI — при регистрации предоставляется 60 ГБ бесплатно в контейнерном диске и 1 ГБ бесплатно в томе диска. При превышении лимита взимается дополнительная плата.
Большие языковые модели (LLM), такие как LLaMA 3.3 70B, продемонстрировали замечательный потенциал в обработке естественного языка. Однако для полного раскрытия их возможностей в конкретных приложениях часто требуется тонкая настройка. В этой статье рассматривается возможность локальной тонкой настройки LLaMA 3.3 70B с использованием NVIDIA RTX 4090, обсуждаются связанные с этим проблемы и предлагаются альтернативные решения, включая облачные GPU-инстансы.
Понимание LLaMA 3.3 70B
Архитектура и масштаб модели
LLaMA 3.3 70B — это большая языковая модель, разработанная Meta, построенная на архитектуре Transformer. Она предварительно обучена на огромном наборе данных, содержащем более 15 триллионов токенов, что позволяет ей понимать и генерировать человекоподобный текст. Архитектура модели состоит из нескольких слоев голов внимания, которые изучают взаимосвязи между словами, обеспечивая связные и контекстуально уместные результаты.
Сценарии применения
LLaMA 3.3 70B может использоваться в различных приложениях, включая:
- Поддержка клиентов
- Генерация контента
- Специализированные области, такие как медицина и юриспруденция
- Генерация кода
Расширение возможностей с помощью тонкой настройки
Хотя предварительно обученные LLM универсальны, тонкая настройка может улучшить их специализацию для конкретных задач или доменов. Этот процесс адаптации повышает их производительность и релевантность для конкретных приложений.
Например: компании используют Llama 3.3 для создания продвинутых чат-ботов, которые могут понимать и отвечать на запросы клиентов в реальном времени. Эти чат-боты настраиваются для распознавания конкретных намерений и предоставления точных, контекстуально релевантных ответов, повышая удовлетворенность клиентов и снижая потребность в человеческом вмешательстве.
Что такое тонкая настройка?
Преимущества тонкой настройки
Тонкая настройка включает адаптацию предварительно обученной LLM для конкретной задачи или набора данных, что позволяет модели:
- Повысить точность и релевантность за счет специализации на конкретных задачах.
- Уменьшить предвзятость и исправить ошибки.
- Оптимизировать использование ресурсов, опираясь на существующие знания, а не начиная с нуля.
- Достичь лучшей производительности, чем более крупная базовая модель, используя меньшую настроенную модель.
- Требовать меньше проектирования промптов.
Применение настроенных моделей
Настроенные LLM можно применять в различных случаях использования:
- Суммаризация текста
- Генерация текста
- Бинарная или текстовая классификация
- Генерация кода
- Чат-боты
Как работает тонкая настройка?
Тонкая настройка корректирует параметры предварительно обученной модели, чтобы сделать ее более подходящей для конкретной задачи, с помощью таких техник, как:
- Самообучение: Обучение модели на подобранном корпусе текстов.
- Обучение с учителем: Обучение на парах ввод-вывод.
- Обучение с подкреплением: Обучение модели вознаграждения для улучшения качества выводов.
- Эффективная настройка параметров (PEFT): Замораживание большинства параметров модели и обновление только небольшого числа дополнительных параметров.
https://www.youtube.com/watch?v=9PcV6FCv9eQ
Что нужно для тонкой настройки LLaMA 3?
Требования к памяти GPU
Тонкая настройка больших моделей, таких как LLaMA 3.3 70B, требует значительного объема памяти GPU. Базовая модель занимает около 141 ГБ видеопамяти GPU, а квантизованная версия — около 40 ГБ. Даже с квантизацией тонкая настройка может быть ресурсоемкой.
Стоимость
Полная настройка параметров требует много ресурсов и времени, что влечет за собой существенные затраты на GPU и более длительное время выполнения. Использование 80 ГБ GPU более экономически эффективно, так как позволяет использовать большие размеры батчей, тем самым ускоряя процесс тонкой настройки.
Требования к личному набору данных
Высококачественный набор данных критически важен для успешной тонкой настройки. Набор данных должен быть:
- Релевантным задаче
- Достаточно большим для улучшения производительности
- Разнообразным во избежание переобучения
- Правильно отформатирован, включая инструкции, входные данные и выходные
Подходит ли RTX 4090 для локальной тонкой настройки LLaMA 3.3 70B?
Ответ: не обязательно подходит
Хотя RTX 4090 является мощным GPU с 24 ГБ видеопамяти, его может не хватить для полной настройки параметров LLaMA 3.3 70B из-за ограничений по памяти. Производительность значительно падает, когда модели превышают доступную видеопамять; таким образом, RTX 4090 может подходить для инференса — особенно с квантизованными моделями, — но для тонкой настройки требуется больше памяти.
Как решить проблему с помощью других техник
Для преодоления ограничений памяти RTX 4090 можно использовать такие методы, как эффективная настройка параметров (PEFT), включая:
- LoRA (Low-Rank Adaptation): Загрузка модели на GPU с квантизованными весами.
- QLoRA (Quantized LoRA): Загрузка модели на GPU с дополнительно квантизованными весами.
- Half-Quadratic Quantization (HQQ): Еще один метод низкоточной квантизации.
Эти методы замораживают веса предварительно обученной модели, позволяя адаптеру настраиваться поверх нее. Однако использование bitsandbytes для квантизации может дать менее точные результаты по сравнению с другими методами; поэтому рекомендуется повышать точность некоторых ключевых модулей до float32 для лучшей производительности.
Проблемы использования альтернативных техник
Хотя методы PEFT снижают требования к ресурсам, у них есть ограничения:
- Настроенный адаптер нельзя объединить обратно с квантизованной моделью.
- Декантизация и объединение могут значительно ухудшить производительность.
- Модели, использующие HQQ с меньшей разрядностью, могут не конкурировать эффективно с меньшими моделями, которые работают лучше без квантизации.
- Тонкая настройка на GPU с 48 ГБ видеопамяти возможна, но ограничена размером батча в один и крошечными последовательностями.
Альтернативные решения – Облачный GPU
Почему стоит выбрать облачные GPU-инстансы?
Облачные GPU-инстансы являются жизнеспособной альтернативой локальной тонкой настройке, особенно для больших моделей, таких как LLaMA 3.3 70B. Они предоставляют:
- Масштабируемые ресурсы GPU в зависимости от рабочей нагрузки
- Доступ к высокопроизводительным GPU, таким как NVIDIA A100 или V100
- Экономичные модели оплаты по мере использования
- Упрощенные рабочие процессы развертывания
- Возможность обойти ограничения локального оборудования
Услуги GPU-инстансов Novita AI
По сравнению с другими облачными GPU, наши цены имеют самые большие преимущества. Вот таблица для вас:
| Провайдер | Цена RTX 4090 (1x GPU в час) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | Нет услуги |
Шаги развертывания и руководство по использованию
Шаг 1: Нажмите на GPU Instance
Если вы новый пользователь, сначала зарегистрируйте аккаунт. Затем нажмите кнопку GPU Instance на нашей веб-странице.
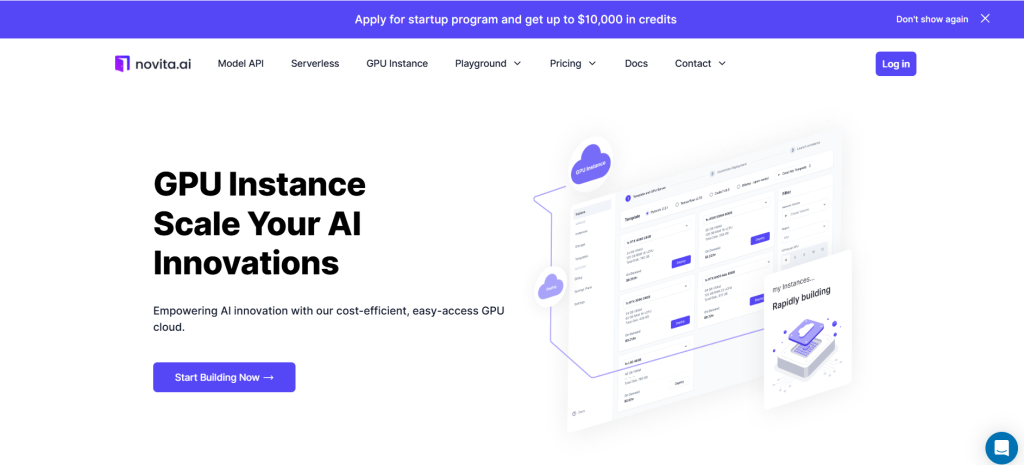
Шаг 2: Шаблон и GPU-сервер
Вы можете выбрать свой собственный шаблон, включая Pytorch, Tensorflow, Cuda, Ollama, в соответствии с вашими конкретными потребностями. Кроме того, вы можете создать свои собственные данные шаблона, нажав на нижнюю кнопку.
Затем наш сервис предоставляет доступ к высокопроизводительным GPU, таким как NVIDIA RTX 4090, каждый с достаточным объемом видеопамяти и оперативной памяти, что гарантирует эффективное обучение даже самых требовательных моделей ИИ. Вы можете выбрать его в соответствии с вашими потребностями.
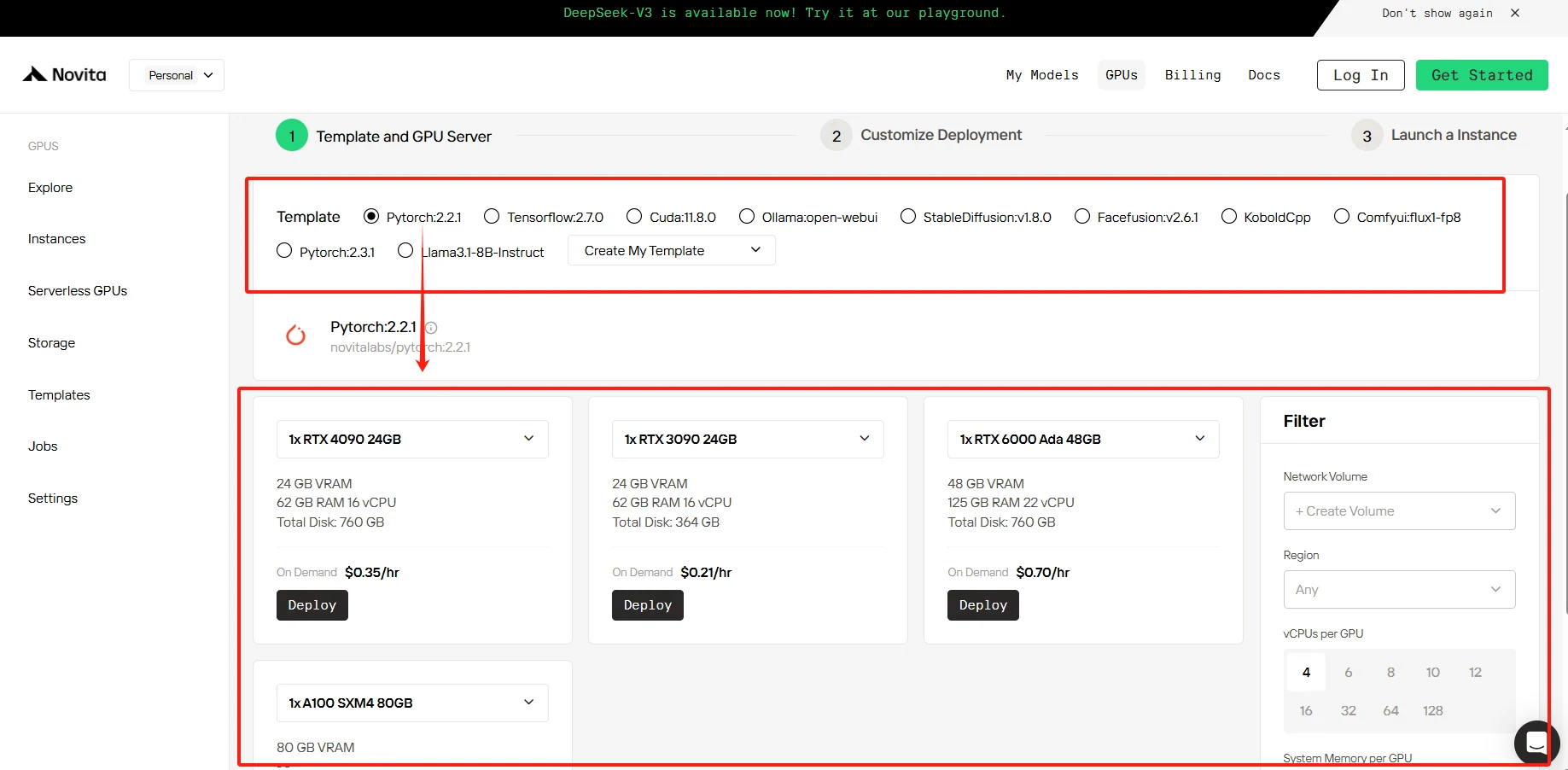
Шаг 3: Настройка развертывания
В этом разделе вы можете настроить данные в соответствии с вашими потребностями. Предоставляется 60 ГБ бесплатно в контейнерном диске и 1 ГБ бесплатно в томе диска. При превышении бесплатного лимита взимается дополнительная плата.
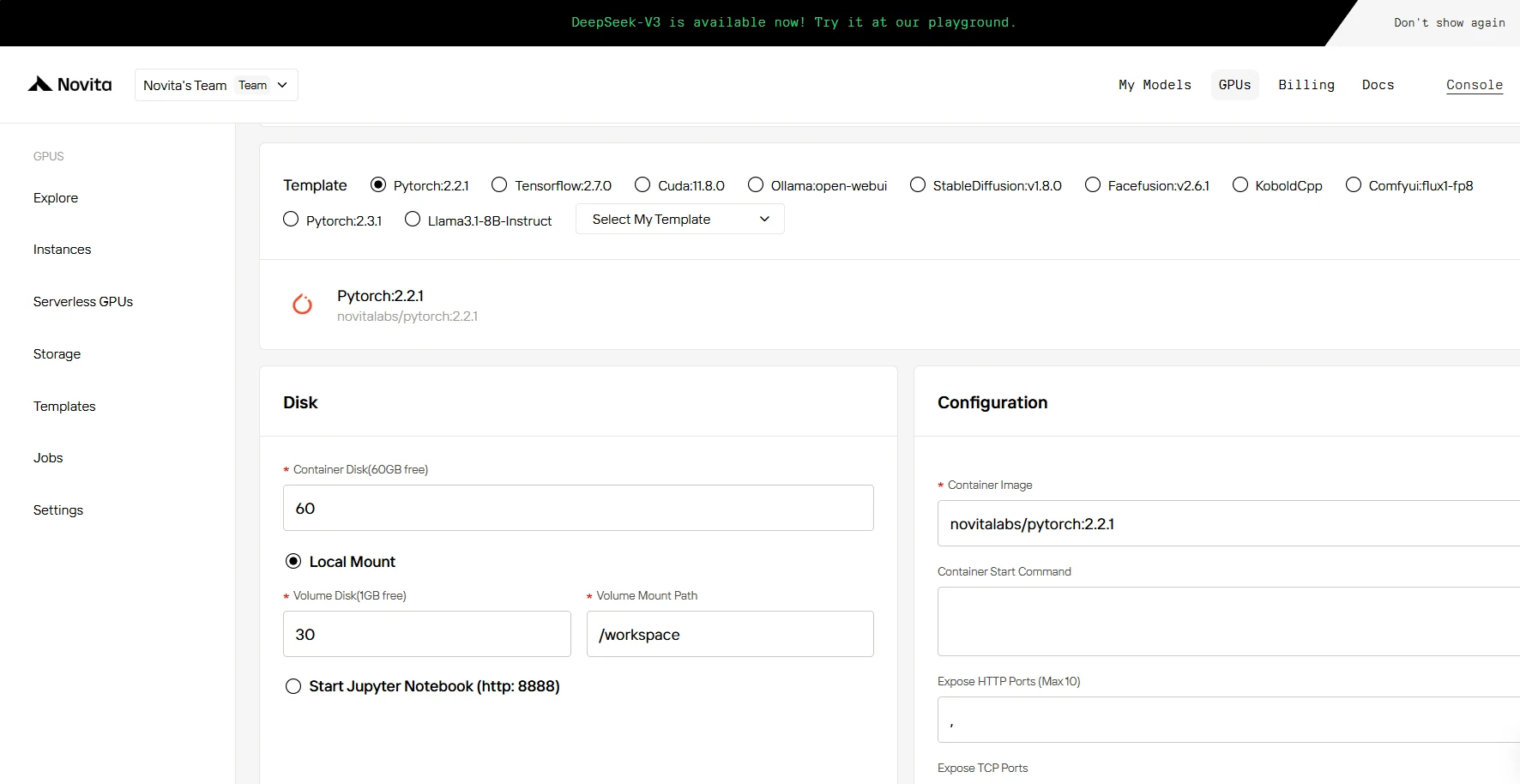
Шаг 4: Запуск инстанса
Будь то для исследований, разработки или развертывания AI-приложений, GPU-инстанс Novita AI, оснащенный CUDA 12, обеспечивает мощный и эффективный опыт GPU-вычислений в облаке.
Тонкая настройка LLaMA 3.3 70B: сравнение локальных и облачных решений
Локальная тонкая настройка: плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Полный контроль над оборудованием и данными | Более медленное время обучения из-за ограничений памяти и вычислительной мощности |
| Не требует подключения к интернету | Может быть сложна в настройке; требует больше технических навыков по сравнению с облачными решениями |
| Потенциально более низкая стоимость для небольших задач настройки |
Облачная тонкая настройка: плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Масштабируемые ресурсы для больших моделей и наборов данных | Потенциально более высокие затраты в зависимости от использования |
| Более быстрое время обучения благодаря доступу к мощным GPU | |
| Упрощенное развертывание и более легкое управление | |
| Возможность использования нескольких GPU для распределенного обучения |
Заключение
Тонкая настройка LLaMA 3.3 70B может значительно повысить ее возможности для конкретных приложений. Хотя RTX 4090 подходит для инференса и некоторой ограниченной настройки с использованием методов PEFT, его ограничения по памяти делают его менее идеальным для полномасштабной настройки такой большой модели. Облачные GPU-инстансы, такие как предлагаемые Novita AI, предоставляют масштабируемые ресурсы и упрощенные варианты развертывания, которые могут эффективно удовлетворить эти потребности. В конечном итоге выбор между локальным и облачным решением будет зависеть от конкретных требований, доступных ресурсов и технических знаний.
Часто задаваемые вопросы
Часто задаваемые вопросы
Какой размер LLaMA 3.3 70B в ГБ?
Модель LLaMA 3.3 70B имеет размер приблизительно 40-42 ГБ, в зависимости от уровня квантизации и конкретной загруженной версии; чаще всего сообщается, что около 42 ГБ.
Лимит токенов LLaMA 3.3 70B?
Таким образом, максимальный лимит токенов для промпта составляет 130K, а не 8196. Однако если вы используете очень длинный промпт, это будет потреблять больше памяти GPU.
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для создания и масштабирования.
Рекомендуемое чтение
Как выбрать лучший GPU для инференса LLM: бенчмаркинг Инсайты
Почему требования к видеопамяти LLaMA 3.3 70B являются проблемой для домашних серверов?
Llama 3.3 70B: возможности, руководство по доступу и сравнение моделей



