

- LLaMA 3.3 70B verstehen
- Was ist Feinabstimmung?
- Was wird für die Feinabstimmung von LLaMA 3 benötigt?
- Ist die RTX 4090 für die lokale Feinabstimmung von LLaMA 3.3 70B geeignet?
- Alternative Lösungen – Cloud-GPU
- Feinabstimmung von LLaMA 3.3 70B: Vergleich lokaler und Cloud-Lösungen
- Fazit
- Häufig gestellte Fragen
Wichtige Highlights
LLaMA 3.3 70B ist ein hochmodernes Sprachmodell mit beeindruckenden Fähigkeiten.
Durch Feinabstimmung kann LLaMA 3.3 70B für spezifische Aufgaben angepasst werden, was Genauigkeit und Relevanz verbessert.
Obwohl die RTX 4090 eine leistungsstarke GPU ist, erschweren ihre Speicherbeschränkungen die Feinabstimmung von LLaMA 3.3 70B.
Parameter-effiziente Feinabstimmungsmethoden (PEFT) wie LoRA und QLoRA können helfen, diese Herausforderungen zu mildern.
Cloud-GPU-Instanzen bieten eine praktikable Alternative für die Feinabstimmung großer Modelle wie LLaMA 3.3 70B. Sie können GPU-Instanzen von Novita AI nutzen – nach der Registrierung stehen 60 GB kostenloser Container-Datenträger und 1 GB kostenloser Volume-Datenträger zur Verfügung; bei Überschreitung des kostenlosen Limits fallen zusätzliche Kosten an.
Große Sprachmodelle (LLMs) wie LLaMA 3.3 70B haben bemerkenswerte Fähigkeiten in der natürlichen Sprachverarbeitung gezeigt. Um ihr volles Potenzial für spezifische Anwendungen auszuschöpfen, ist jedoch oft eine Feinabstimmung erforderlich. Dieser Artikel untersucht die Machbarkeit einer lokalen Feinabstimmung von LLaMA 3.3 70B mit einer NVIDIA RTX 4090, diskutiert die damit verbundenen Herausforderungen und schlägt alternative Lösungen vor, einschließlich cloudbasierter GPU-Instanzen.
LLaMA 3.3 70B verstehen
Modellarchitektur und Umfang
LLaMA 3.3 70B ist ein von Meta entwickeltes großes Sprachmodell, das auf einer Transformer-Architektur basiert. Es wurde mit einem riesigen Datensatz von über 15 Billionen Tokens vortrainiert, was es ihm ermöglicht, menschenähnlichen Text zu verstehen und zu generieren. Die Architektur des Modells besteht aus mehreren Schichten von Aufmerksamkeitsköpfen, die Beziehungen zwischen Wörtern lernen und so kohärente und kontextuell angemessene Ausgaben ermöglichen.
Anwendungsszenarien
LLaMA 3.3 70B kann in verschiedenen Anwendungen eingesetzt werden, darunter:
- Kundensupport
- Inhaltserstellung
- Spezialisierte Bereiche wie Medizin und Recht
- Codegenerierung
Erweiterung der Anwendungen durch Feinabstimmung
Obwohl vortrainierte LLMs vielseitig sind, können sie durch Feinabstimmung für bestimmte Aufgaben oder Domänen spezialisiert werden. Dieser Anpassungsprozess verbessert ihre Leistung und Relevanz für spezifische Anwendungen.
Beispiel: Unternehmen nutzen Llama 3.3, um fortschrittliche Chatbots zu entwickeln, die Kundenanfragen in Echtzeit verstehen und beantworten können. Diese Chatbots werden feinabgestimmt, um bestimmte Absichten zu erkennen und genaue, kontextuell relevante Antworten zu liefern, was die Kundenzufriedenheit erhöht und den Bedarf an menschlichem Eingreifen reduziert.
Was ist Feinabstimmung?
Vorteile der Feinabstimmung
Die Feinabstimmung passt ein vortrainiertes LLM an eine bestimmte Aufgabe oder einen Datensatz an und ermöglicht dem Modell:
- Verbesserung von Genauigkeit und Relevanz durch Spezialisierung auf bestimmte Aufgaben.
- Reduzierung von Verzerrungen und Korrektur von Fehlern.
- Optimierung der Ressourcennutzung, indem es auf vorhandenem Wissen aufbaut, anstatt bei Null zu beginnen.
- Mit einem kleineren feinabgestimmten Modell eine bessere Leistung zu erzielen als mit einem größeren Basismodell.
- Weniger Prompt-Engineering zu erfordern.
Anwendungen feinabgestimmter Modelle
Feinabgestimmte LLMs können für verschiedene Anwendungsfälle eingesetzt werden:
- Textzusammenfassung
- Textgenerierung
- Binäre oder Textklassifikation
- Codegenerierung
- Chatbots
Wie funktioniert die Feinabstimmung?
Die Feinabstimmung passt die Parameter eines vortrainierten Modells an, um es durch Techniken wie die folgenden besser für eine bestimmte Aufgabe zu geeignet zu machen:
- Selbstüberwachtes Lernen: Training des Modells mit einem kuratierten Textkorpus.
- Überwachtes Lernen: Training mit Eingabe-Ausgabe-Paaren.
- Bestärkendes Lernen: Training eines Belohnungsmodells zur Verbesserung der Ausgabequalität.
- Parameter-effiziente Feinabstimmung (PEFT): Einfrieren der meisten Modellparameter, während nur eine kleine Anzahl zusätzlicher Parameter aktualisiert wird.
https://www.youtube.com/watch?v=9PcV6FCv9eQ
Was wird für die Feinabstimmung von LLaMA 3 benötigt?
Speicheranforderungen der GPU
Die Feinabstimmung großer Modelle wie LLaMA 3.3 70B erfordert erheblichen GPU-Speicher. Das Basismodell belegt etwa 141 GB GPU-RAM, während eine quantisierte Version etwa 40 GB benötigt. Selbst bei Quantisierung kann die Feinabstimmung speicherintensiv sein.
Kostenüberlegungen
Die vollständige Parameter-Feinabstimmung ist ressourcenintensiv und zeitaufwändig und erfordert erhebliche GPU-Ressourcen und längere Bearbeitungszeiten. Die Verwendung einer 80-GB-GPU ist kostengünstiger, da sie größere Batch-Größen ermöglicht und so den Feinabstimmungsprozess beschleunigt.
Anforderungen an den persönlichen Datensatz
Ein qualitativ hochwertiger Datensatz ist für eine erfolgreiche Feinabstimmung entscheidend. Der Datensatz muss:
- relevant für die Aufgabe sein
- groß genug sein, um die Leistung zu verbessern
- abwechslungsreich sein, um Überanpassung zu vermeiden
- korrekt formatiert sein, einschließlich Anweisungen, Eingaben und Ausgaben
Ist die RTX 4090 für die lokale Feinabstimmung von LLaMA 3.3 70B geeignet?
Antwort: Nicht unbedingt geeignet
Obwohl die RTX 4090 eine leistungsstarke GPU mit 24 GB VRAM ist, reicht sie aufgrund ihrer Speicherbeschränkungen möglicherweise nicht für die vollständige Parameter-Feinabstimmung von LLaMA 3.3 70B aus. Die Leistung sinkt erheblich, wenn Modelle den verfügbaren VRAM überschreiten; daher ist die RTX 4090 zwar für die Inferenz geeignet – insbesondere mit quantisierten Modellen –, aber die Feinabstimmung erfordert mehr Speicher.
Wie man das Problem mit anderen Techniken löst
Um die Speicherbeschränkungen der RTX 4090 zu umgehen, können Techniken wie die parameter-effiziente Feinabstimmung (PEFT) eingesetzt werden, darunter:
- LoRA (Low-Rank Adaptation): Lädt das Modell mit quantisierten Gewichten auf die GPU.
- QLoRA (Quantized LoRA): Lädt das Modell mit weiter quantisierten Gewichten auf die GPU.
- Half-Quadratic Quantization (HQQ): Eine weitere Niedrigpräzisions-Quantisierungsmethode.
Diese Methoden frieren die Gewichte des vortrainierten Modells ein, während ein Adapter darauf feinabgestimmt werden kann. Die Verwendung von bitsandbytes zur Quantisierung kann jedoch im Vergleich zu anderen Methoden zu weniger genauen Ergebnissen führen; daher wird empfohlen, einige Schlüsselmodule für eine bessere Leistung auf float32 upzucasteen.
Herausforderungen bei der Verwendung alternativer Techniken
Während PEFT-Methoden die Ressourcenanforderungen reduzieren, bringen sie Einschränkungen mit sich:
- Der feinabgestimmte Adapter kann nicht in das quantisierte Modell zurückgemergt werden.
- Dequantisierung und Merge können die Leistung erheblich verschlechtern.
- Modelle, die HQQ mit niedrigeren Bit-Tiefen verwenden, konkurrieren möglicherweise nicht effektiv mit kleineren Modellen, die ohne Quantisierung besser abschneiden.
- Die Feinabstimmung mit einer GPU von nur 48 GB VRAM ist möglich, aber auf Batch-Größen von eins und winzige Sequenzen beschränkt.
Alternative Lösungen – Cloud-GPU
Warum Cloud-GPU-Instanzen wählen?
Cloud-GPU-Instanzen bieten eine praktikable Alternative zur lokalen Feinabstimmung, insbesondere für große Modelle wie LLaMA 3.3 70B. Sie bieten:
- Skalierbare GPU-Ressourcen je nach Arbeitslastbedarf
- Zugang zu leistungsstarken GPUs wie NVIDIA A100 oder V100
- Kosteneffiziente Pay-as-you-go-Preismodelle
- Vereinfachte Bereitstellungsworkflows
- Die Möglichkeit, lokale Hardwarebeschränkungen zu umgehen
Novita AI GPU-Instanzdienste
Im Vergleich zu anderen GPU-Clouds hat unser Preis die größten Vorteile. Hier ist eine Tabelle für Sie:
| Anbieter | Preis der RTX 4090 (1x GPU pro Stunde) |
|---|---|
| Novita AI | 0,35 USD |
| Vast AI | 0,316–1,073 USD |
| CoreWeave | Kein Service |
Bereitstellungsschritte und Nutzungsanleitung
Schritt 1: Klicken Sie auf die GPU-Instanz
Wenn Sie ein neuer Abonnent sind, registrieren Sie bitte zuerst unseren Account. Klicken Sie dann auf die Schaltfläche GPU-Instanz auf unserer Webseite.
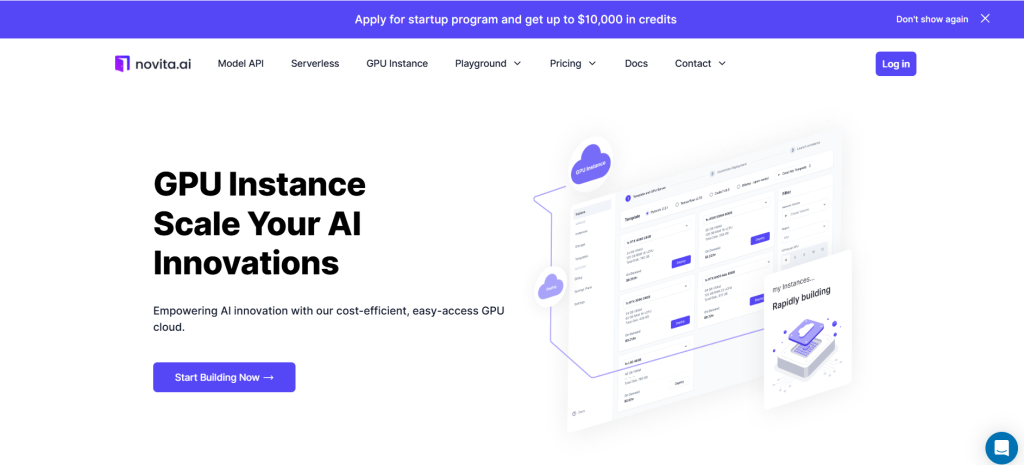
SCHRITT 2: Vorlage und GPU-Server
Sie können Ihre eigene Vorlage auswählen, einschließlich PyTorch, TensorFlow, Cuda, Ollama, entsprechend Ihren spezifischen Anforderungen. Darüber hinaus können Sie auch Ihre eigenen Vorlagendaten erstellen, indem Sie auf die unterste Schaltfläche klicken.
Dann bietet unser Dienst Zugang zu leistungsstarken GPUs wie der NVIDIA RTX 4090, jede mit beträchtlichem VRAM und RAM, um sicherzustellen, dass selbst die anspruchsvollsten KI-Modelle effizient trainiert werden können. Sie können basierend auf Ihren Anforderungen auswählen.
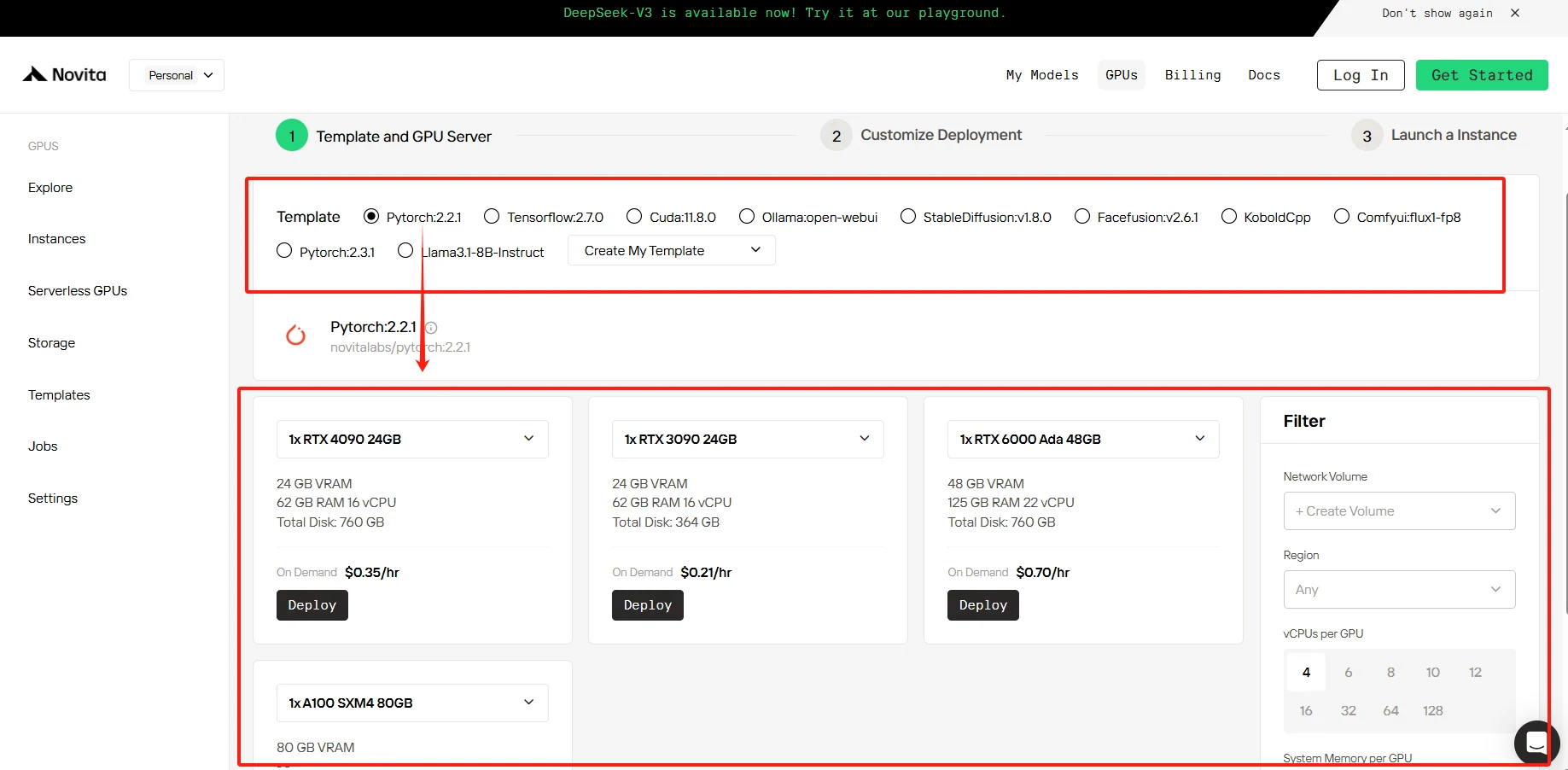
SCHRITT 3: Bereitstellung anpassen
In diesem Abschnitt können Sie diese Daten nach Ihren eigenen Bedürfnissen anpassen. Es gibt 60 GB kostenlosen Container-Datenträger und 1 GB kostenlosen Volume-Datenträger; bei Überschreitung des kostenlosen Limits fallen zusätzliche Kosten an.
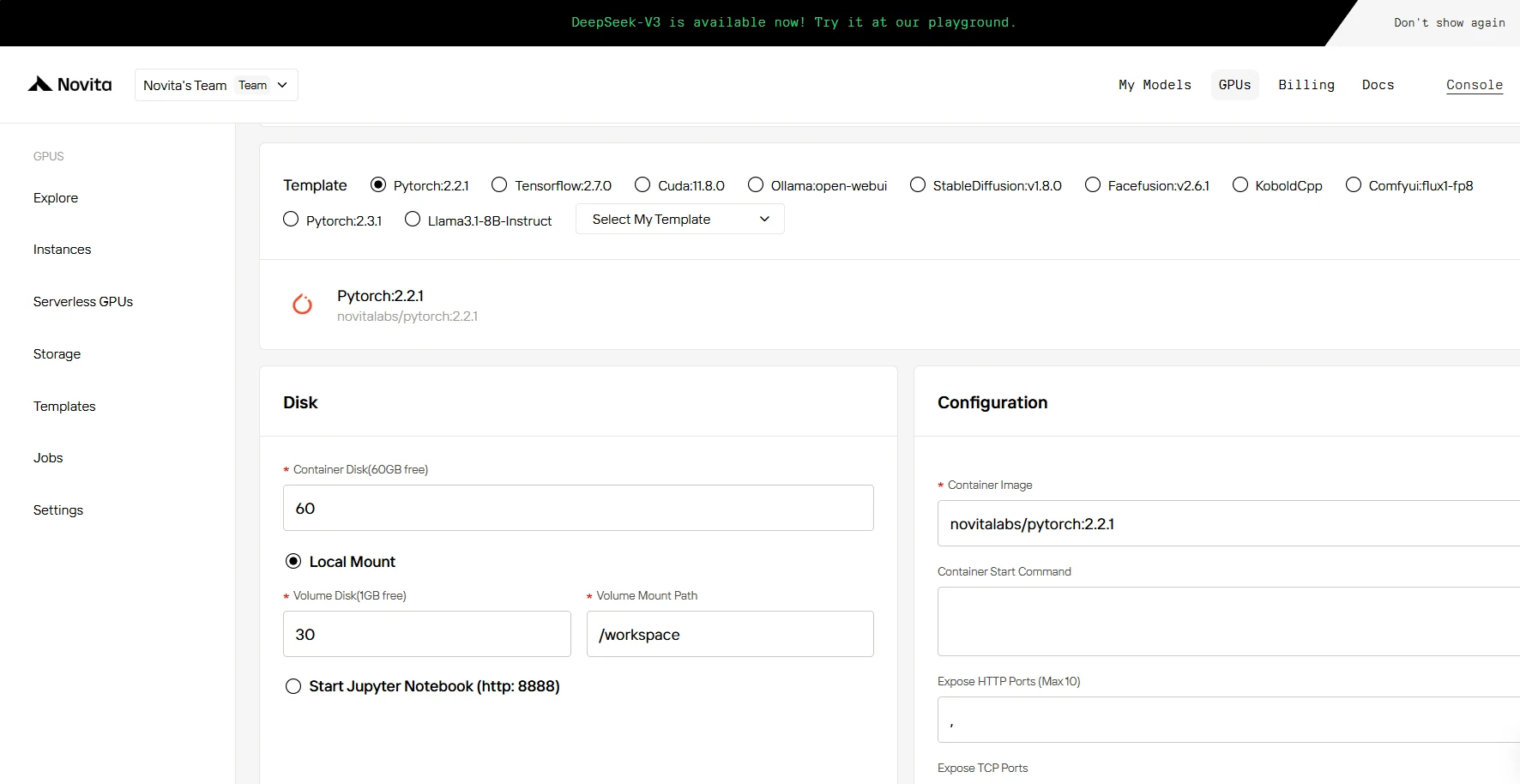
SCHRITT 4: Eine Instanz starten
Ob für Forschung, Entwicklung oder Bereitstellung von KI-Anwendungen – die Novita AI GPU-Instanz mit CUDA 12 bietet ein leistungsstarkes und effizientes GPU-Computing-Erlebnis in der Cloud.
Feinabstimmung von LLaMA 3.3 70B: Vergleich lokaler und Cloud-Lösungen
Lokale Feinabstimmung: Vor- und Nachteile
| Vorteile | Nachteile |
|---|---|
| Volle Kontrolle über Hardware und Daten | Längere Trainingszeiten aufgrund von Speicherbeschränkungen und begrenzter Rechenleistung |
| Keine Abhängigkeit von einer Internetverbindung | Kann schwierig einzurichten sein; erfordert mehr technische Fähigkeiten im Vergleich zu Cloud-Lösungen |
| Potenziell geringere Kosten für kleine Feinabstimmungsaufgaben |
Cloud-Feinabstimmung: Vor- und Nachteile
| Vorteile | Nachteile |
|---|---|
| Skalierbare Ressourcen für große Modelle und Datensätze | Potenziell höhere Kosten je nach Nutzung |
| Schnellere Trainingszeiten durch Zugang zu leistungsstarken GPUs | |
| Vereinfachte Bereitstellung und einfachere Verwaltung | |
| Möglichkeit, mehrere GPUs für verteiltes Training zu nutzen |
Fazit
Die Feinabstimmung von LLaMA 3.3 70B kann seine Fähigkeiten für bestimmte Anwendungen erheblich verbessern. Während die RTX 4090 für die Inferenz und einige begrenzte Feinabstimmungen mit PEFT-Techniken geeignet ist, machen ihre Speicherbeschränkungen sie weniger ideal für eine vollständige Skalierung eines so großen Modells. Cloud-GPU-Instanzen, wie sie von Novita AI angeboten werden, bieten skalierbare Ressourcen und vereinfachte Bereitstellungsoptionen, die diesen Anforderungen effektiv gerecht werden können. Letztendlich hängt die Wahl zwischen lokalen und Cloud-Lösungen von den spezifischen Anforderungen, verfügbaren Ressourcen und der technischen Expertise ab.
Häufig gestellte Fragen
Llama 3.3 70B Größe in GB?
Das Llama 3.3 70B-Modell ist je nach Quantisierungsstufe und heruntergeladener spezifischer Version etwa 40–42 GB groß; am häufigsten wird es mit etwa 42 GB angegeben.
Llama 3.3 70B Token-Limit?
Das maximale Token-Limit für einen Prompt beträgt 130K, statt 8196. Wenn Sie jedoch sehr lange Prompt-Eingaben verwenden, wird mehr GPU-Speicher verbraucht.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig die erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Empfohlene Lektüre
So wählen Sie die beste GPU für LLM-Inferenz aus: Benchmarking-Einblicke
Warum die VRAM-Anforderungen von LLaMA 3.3 70B eine Herausforderung für Heimserver darstellen
Llama 3.3 70B: Funktionen, Zugriffsanleitung & Modellvergleich



