

핵심 요점
LLaMA 3.3 70B는 뛰어난 성능을 가진 최첨단 언어 모델입니다.
파인튜닝을 통해 LLaMA 3.3 70B를 특정 작업에 맞게 사용자 정의하여 정확성과 관련성을 향상시킬 수 있습니다.
RTX 4090은 강력한 GPU이지만 메모리 제한으로 인해 LLaMA 3.3 70B 파인튜닝이 어려울 수 있습니다.
LoRA 및 QLoRA와 같은 매개변수 효율적 파인튜닝(PEFT) 방법이 이러한 문제를 완화하는 데 도움이 될 수 있습니다.
클라우드 GPU 인스턴스는 LLaMA 3.3 70B와 같은 대형 모델을 파인튜닝하기 위한 실행 가능한 대안을 제공합니다. Novita AI의 GPU 인스턴스를 사용할 수 있습니다. — 가입 시 컨테이너 디스크 60GB와 볼륨 디스크 1GB가 무료로 제공되며, 무료 한도를 초과하면 추가 요금이 부과됩니다.
LLaMA 3.3 70B와 같은 대규모 언어 모델(LLM)은 자연어 처리에서 놀라운 잠재력을 보여주었습니다. 그러나 특정 애플리케이션에 대한 기능을 최대한 활용하려면 파인튜닝이 필요한 경우가 많습니다. 이 기사에서는 NVIDIA RTX 4090을 사용하여 로컬에서 LLaMA 3.3 70B를 파인튜닝하는 것이 가능한지 살펴보고, 관련 문제를 논의하며, 클라우드 기반 GPU 인스턴스를 포함한 대체 솔루션을 제안합니다.
LLaMA 3.3 70B 이해하기
모델 아키텍처 및 규모
LLaMA 3.3 70B는 Meta가 개발한 대규모 언어 모델로, Transformer 아키텍처를 기반으로 합니다. 15조 개 이상의 토큰으로 구성된 방대한 데이터셋에서 사전 훈련되어 인간과 유사한 텍스트를 이해하고 생성할 수 있습니다. 모델의 아키텍처는 단어 간의 관계를 학습하는 여러 계층의 어텐션 헤드로 구성되어 일관되고 맥락에 맞는 출력을 가능하게 합니다.
적용 시나리오
LLaMA 3.3 70B는 다음과 같은 다양한 애플리케이션에 활용될 수 있습니다:
- 고객 지원
- 콘텐츠 생성
- 의료 및 법률과 같은 전문 분야
- 코드 생성
파인튜닝을 통한 애플리케이션 확장
사전 훈련된 LLM은 다재다능하지만 특정 작업이나 도메인에 특화되기 위해 파인튜닝의 이점을 얻을 수 있습니다. 이러한 적응 과정은 특정 애플리케이션에 대한 성능과 관련성을 향상시킵니다.
예: 기업은 Llama 3.3을 활용하여 실시간으로 고객 문의를 이해하고 응답할 수 있는 고급 챗봇을 만듭니다. 이러한 챗봇은 특정 의도를 인식하고 정확하고 맥락에 맞는 응답을 제공하도록 파인튜닝되어 고객 만족도를 높이고 인간 개입의 필요성을 줄입니다.
파인튜닝이란?
파인튜닝의 이점
파인튜닝은 사전 훈련된 LLM을 특정 작업이나 데이터셋에 맞게 사용자 정의하는 과정으로, 모델이 다음과 같은 이점을 얻을 수 있습니다:
- 정확성 및 관련성 향상: 특정 작업에 특화됨.
- 편향 감소 및 오류 수정.
- 리소스 사용 최적화: 처음부터 시작하는 대신 기존 지식을 활용.
- 더 큰 기본 모델보다 더 작은 파인튜닝 모델로 더 나은 성능 달성.
- 프롬프트 엔지니어링 필요성 감소.
파인튜닝된 모델의 애플리케이션
파인튜닝된 LLM은 다양한 사용 사례에 적용될 수 있습니다:
- 텍스트 요약
- 텍스트 생성
- 이진 분류 또는 텍스트 분류
- 코드 생성
- 챗봇
파인튜닝은 어떻게 작동하나요?
파인튜닝은 사전 훈련된 모델의 매개변수를 조정하여 주어진 작업에 더 적합하게 만드는 과정으로, 다음과 같은 기술을 사용합니다:
- 자기 지도 학습: 큐레이션된 텍스트 코퍼스로 모델 훈련.
- 지도 학습: 입력-출력 쌍으로 훈련.
- 강화 학습: 보상 모델을 훈련하여 출력 품질 개선.
- 매개변수 효율적 파인튜닝(PEFT): 대부분의 모델 매개변수를 고정하고 소수의 추가 매개변수만 업데이트.
https://www.youtube.com/watch?v=9PcV6FCv9eQ
LLaMA 3 파인튜닝에 필요한 것은?
GPU 메모리 요구 사항
LLaMA 3.3 70B와 같은 대형 모델을 파인튜닝하려면 상당한 GPU 메모리가 필요합니다. 기본 모델은 약 141GB의 GPU RAM을 차지하는 반면, 양자화된 버전은 약 40GB가 필요합니다. 양자화를 사용하더라도 파인튜닝은 메모리 집약적일 수 있습니다.
비용 고려 사항
전체 매개변수 파인튜닝은 리소스 집약적이고 시간이 많이 소요되며, 상당한 GPU 리소스와 더 긴 완료 시간이 필요합니다. 80GB GPU를 사용하면 배치 크기를 더 크게 할 수 있어 파인튜닝 프로세스를 가속화할 수 있으므로 비용 효율적입니다.
개인 데이터셋 요구 사항
성공적인 파인튜닝을 위해서는 고품질 데이터셋이 필수적입니다. 데이터셋은 다음 조건을 충족해야 합니다:
- 작업과 관련 되어야 함
- 성능 향상을 위해 충분히 커야 함
- 과적합을 피하기 위해 다양해야 함
- 지침, 입력 및 출력을 포함하도록 올바르게 형식화되어야 함
RTX 4090이 LLaMA 3.3 70B 로컬 파인튜닝에 적합한가요?
답변: 반드시 적합하지는 않음
RTX 4090은 24GB VRAM을 가진 강력한 GPU이지만, 메모리 제한으로 인해 LLaMA 3.3 70B의 전체 매개변수 파인튜닝에는 충분하지 않을 수 있습니다. 모델이 사용 가능한 VRAM을 초과하면 성능이 크게 저하됩니다. 따라서 RTX 4090은 추론(특히 양자화된 모델)에는 적합할 수 있지만, 파인튜닝에는 더 많은 메모리가 필요합니다.
다른 기술을 사용하여 문제 해결 방법
RTX 4090의 메모리 제한을 해결하기 위해 LoRA(저순위 적응), QLoRA(양자화된 LoRA), HQQ(반사분 양자화)와 같은 매개변수 효율적 파인튜닝(PEFT) 기술을 사용할 수 있습니다. 이러한 방법은 사전 훈련된 모델의 가중치는 고정하고, 그 위에서 어댑터를 파인튜닝할 수 있도록 합니다. 그러나 bitsandbytes를 사용한 양자화는 다른 방법에 비해 정확도가 떨어질 수 있으므로, 더 나은 성능을 위해 일부 주요 모듈을 float32로 업캐스트하는 것이 좋습니다.
대체 기술 사용의 문제점
PEFT 방법은 리소스 요구 사항을 줄이지만 다음과 같은 제한 사항이 있습니다:
- 파인튜닝된 어댑터를 양자화된 모델에 다시 병합할 수 없습니다.
- 역양자화 및 병합은 성능을 크게 저하시킬 수 있습니다.
- 낮은 비트 깊이에서 HQQ를 사용하는 모델은 양자화 없이 더 잘 작동하는 더 작은 모델에 비해 경쟁력이 떨어질 수 있습니다.
- 48GB VRAM만 있는 GPU로 파인튜닝하는 것은 가능하지만 배치 크기 1과 매우 작은 시퀀스로 제한됩니다.
대체 솔루션 – 클라우드 GPU
클라우드 GPU 인스턴스를 선택해야 하는 이유?
클라우드 GPU 인스턴스는 특히 LLaMA 3.3 70B와 같은 대형 모델의 경우 로컬 파인튜닝에 대한 실행 가능한 대안을 제공합니다. 다음을 제공합니다:
- 워크로드 수요에 기반한 확장 가능한 GPU 리소스
- NVIDIA A100 또는 V100과 같은 고성능 GPU에 대한 액세스
- 비용 효율적인 종량제 가격 모델
- 간소화된 배포 워크플로우
- 로컬 하드웨어 제한을 우회하는 능력
Novita AI GPU 인스턴스 서비스
다른 GPU 클라우드와 비교할 때, 당사 가격이 가장 큰 장점 을 가지고 있습니다. 다음은 표입니다:
| 서비스 제공자 | rtx 4090 가격 (1x GPU 시간당) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | No service |
배포 단계 및 사용 가이드
1단계: GPU 인스턴스 클릭
신규 가입자라면 먼저 계정을 등록하세요. 그런 다음 웹페이지에서 GPU Instance 버튼을 클릭하세요.
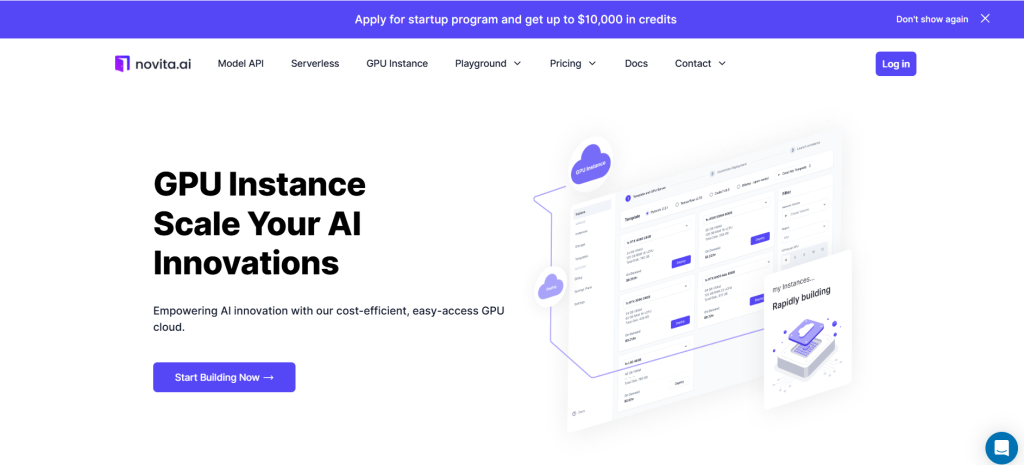
2단계: 템플릿 및 GPU 서버
Pytorch, Tensorflow, Cuda, Ollama 등 자신의 특정 요구에 따라 템플릿을 선택할 수 있습니다. 또한 맨 아래를 클릭하여 자신만의 템플릿 데이터를 만들 수도 있습니다. 그런 다음 당사 서비스는 NVIDIA RTX 4090과 같은 고성능 GPU에 대한 액세스를 제공하며, 각각 상당한 VRAM과 RAM을 갖추고 있어 가장 까다로운 AI 모델도 효율적으로 훈련할 수 있습니다. 필요에 따라 선택하세요.
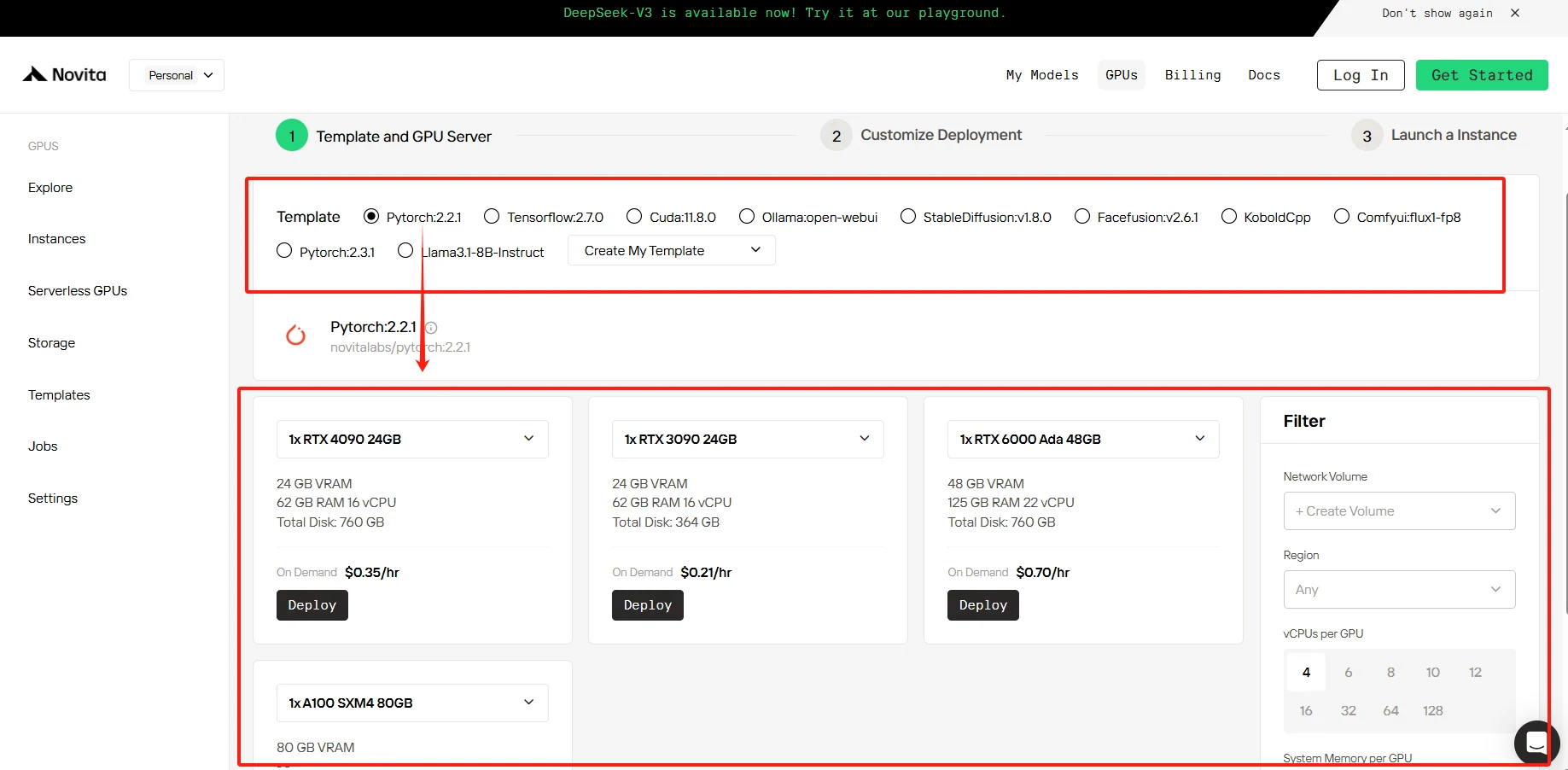
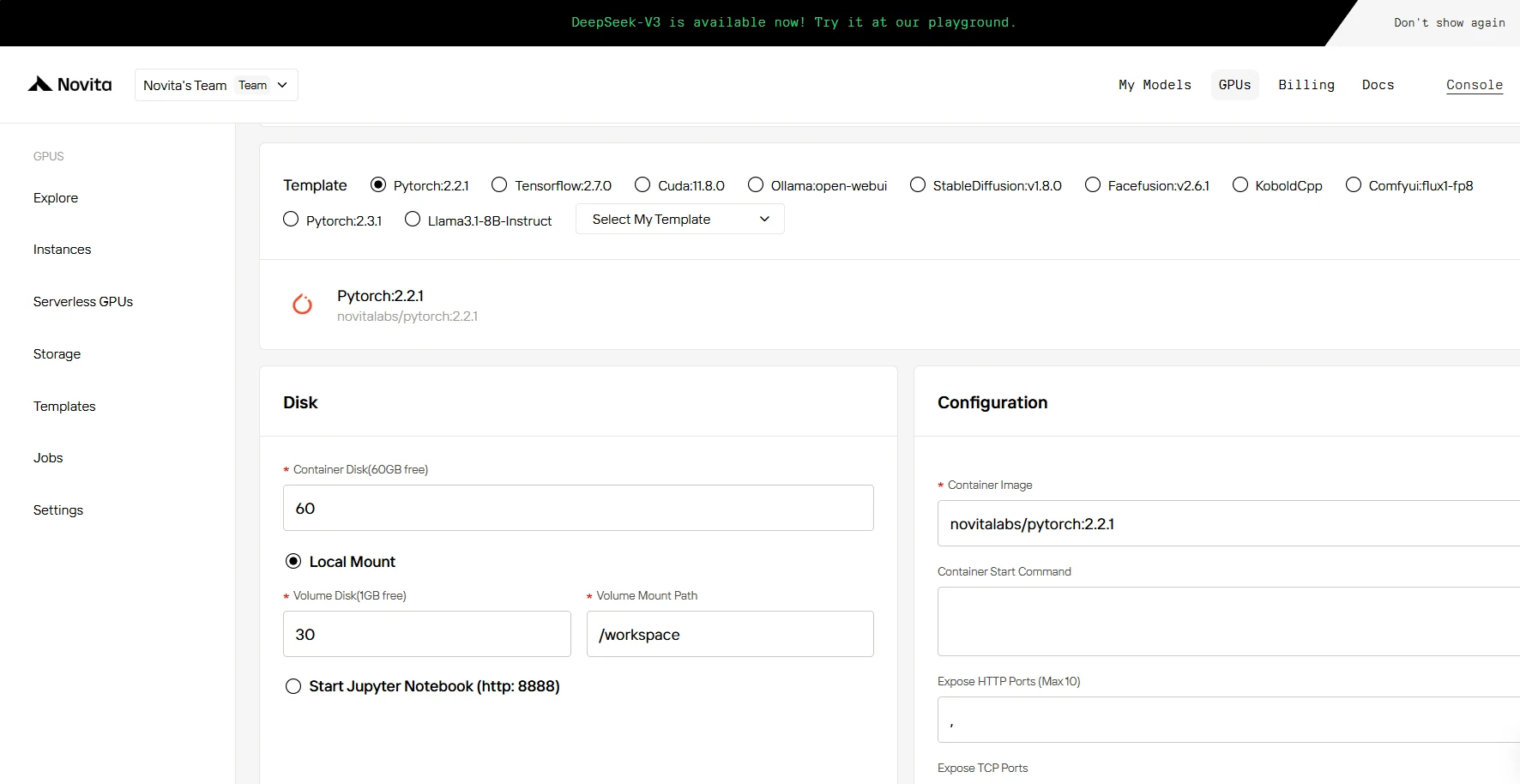
3단계: 배포 사용자 지정
이 섹션에서는 필요에 따라 데이터를 사용자 지정할 수 있습니다. 컨테이너 디스크 60GB와 볼륨 디스크 1GB가 무료로 제공되며, 무료 한도를 초과하면 추가 요금이 부과됩니다.
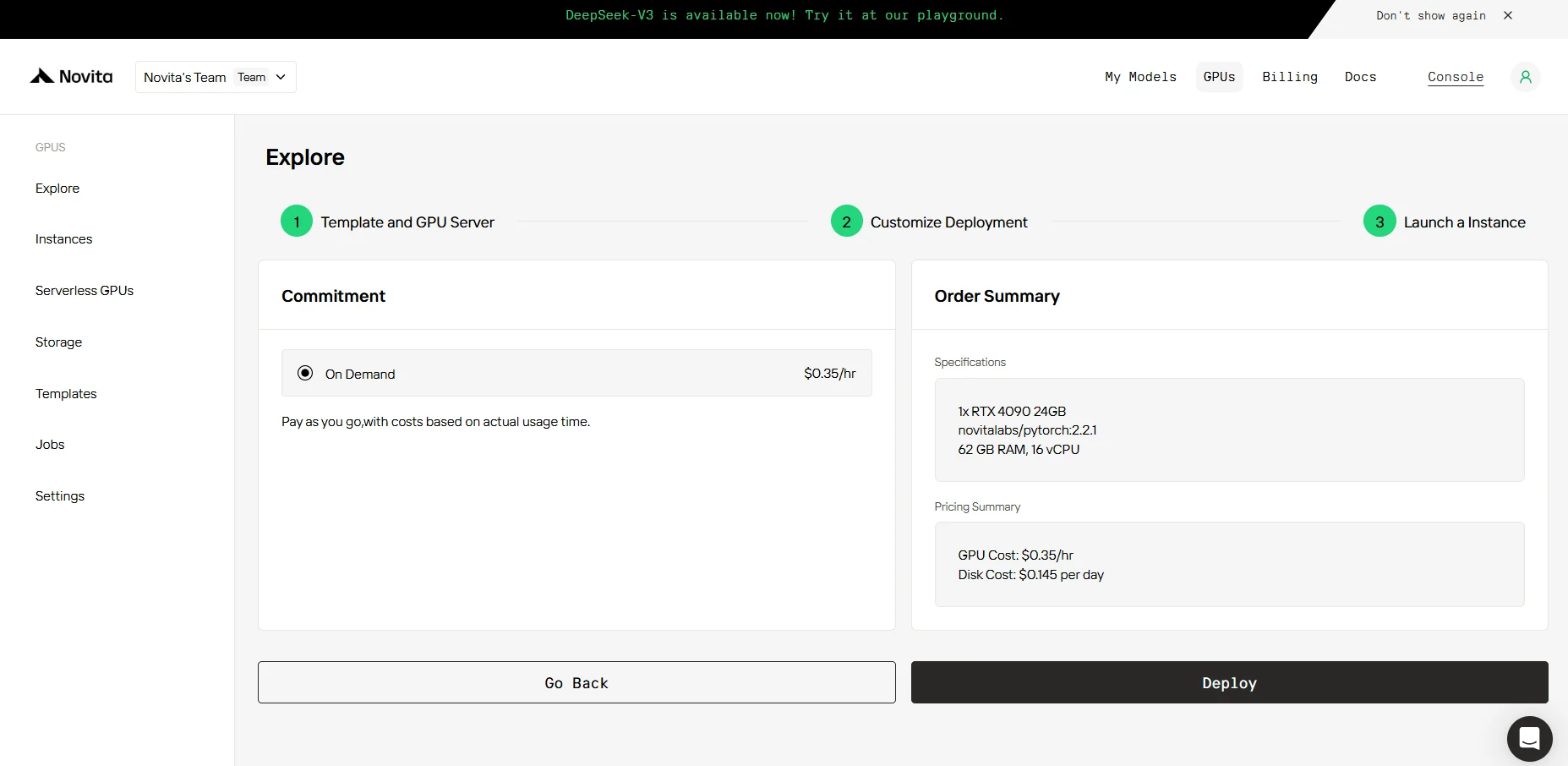
4단계: 인스턴스 시작
AI 애플리케이션의 연구, 개발 또는 배포를 위해, CUDA 12가 탑재된 Novita AI GPU 인스턴스는 클라우드에서 강력하고 효율적인 GPU 컴퓨팅 경험을 제공합니다.
LLaMA 3.3 70B 파인튜닝: 로컬 및 클라우드 솔루션 비교
로컬 파인튜닝: 장단점
| 장점 | 단점 |
|---|---|
| 하드웨어 및 데이터에 대한 완전한 제어 | 메모리 제한 및 제한된 처리 능력으로 인한 느린 훈련 시간 |
| 인터넷 연결에 의존하지 않음 | 설정이 어려울 수 있음; 클라우드 솔루션에 비해 더 많은 기술 숙련도 필요 |
| 소규모 파인튜닝 작업의 경우 잠재적으로 낮은 비용 |
클라우드 파인튜닝: 장단점
| 장점 | 단점 |
|---|---|
| 대형 모델 및 데이터셋을 위한 확장 가능한 리소스 | 사용량에 따라 잠재적으로 높은 비용 |
| 강력한 GPU에 액세스하여 더 빠른 훈련 시간 | |
| 간소화된 배포 및 쉬운 관리 | |
| 분산 훈련을 위한 여러 GPU 처리 능력 |
결론
LLaMA 3.3 70B 파인튜닝은 특정 애플리케이션에 대한 기능을 크게 향상시킬 수 있습니다. RTX 4090은 추론 및 PEFT 기술을 사용한 일부 제한된 파인튜닝에는 적합하지만, 메모리 제한으로 인해 이렇게 큰 모델의 전체 규모 튜닝에는 덜 이상적입니다. Novita AI에서 제공하는 것과 같은 클라우드 GPU 인스턴스는 확장 가능한 리소스와 간소화된 배포 옵션을 제공하여 이러한 요구를 효과적으로 충족할 수 있습니다. 궁극적으로 로컬 솔루션과 클라우드 솔루션 중에서 선택하는 것은 특정 요구 사항, 사용 가능한 리소스 및 기술 전문 지식에 따라 달라집니다.
자주 묻는 질문(FAQ)
Llama 3.3 70B 크기(GB)?
Llama 3.3 70B 모델은 양자화 수준과 다운로드한 특정 버전에 따라 약 40-42GB 크기입니다. 가장 일반적으로 약 42GB로 보고됩니다.
Llama 3.3 70B 토큰 제한?
따라서 프롬프트의 최대 토큰 제한은 8196 대신 130K 입니다. 그러나 매우 긴 프롬프트 입력을 사용하면 더 많은 GPU 메모리를 소비합니다.
Novita AI 는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 구축 및 확장을 위해 저렴하고 안정적인 GPU 클라우드를 제공합니다.
추천 읽을거리
LLM 추론을 위한 최고의 GPU 선택 방법: 벤치마킹 인사이트



