

Points clés
LLaMA 3.3 70B est un modèle de langage de pointe aux capacités impressionnantes.
Le fine-tuning permet de personnaliser LLaMA 3.3 70B pour des tâches spécifiques, améliorant ainsi la précision et la pertinence.
Bien que le RTX 4090 soit un GPU puissant, ses limitations mémoire peuvent rendre le fine-tuning de LLaMA 3.3 70B difficile.
Les méthodes de fine-tuning efficaces en termes de paramètres (PEFT) comme LoRA et QLoRA peuvent aider à atténuer ces difficultés.
Les instances GPU cloud offrent une alternative viable pour le fine-tuning de grands modèles comme LLaMA 3.3 70B. Vous pouvez utiliser les instances GPU de [Novita AI](https://novita.ai/?utm_source=blog_GPU&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) — Lors de l’inscription, vous bénéficiez de 60 Go gratuits dans le disque conteneur et 1 Go gratuit dans le disque de volume ; si la limite gratuite est dépassée, des frais supplémentaires seront facturés.
Les grands modèles de langage (LLM) comme LLaMA 3.3 70B ont démontré un potentiel remarquable en traitement du langage naturel. Cependant, pour exploiter pleinement leurs capacités dans des applications spécifiques, un fine-tuning est souvent nécessaire. Cet article explore la faisabilité du fine-tuning local de LLaMA 3.3 70B avec un NVIDIA RTX 4090, aborde les défis rencontrés et propose des solutions alternatives, notamment les instances GPU cloud.
Comprendre LLaMA 3.3 70B
Architecture et échelle du modèle
LLaMA 3.3 70B est un grand modèle de langage développé par Meta, basé sur une architecture Transformer. Il est pré-entraîné sur un vaste ensemble de données de plus de 15 000 milliards de tokens, ce qui lui permet de comprendre et de générer un texte semblable à celui d’un humain. L’architecture du modèle est constituée de plusieurs couches de têtes d’attention qui apprennent les relations entre les mots, permettant des sorties cohérentes et contextuellement appropriées.
Scénarios d’application
LLaMA 3.3 70B peut être utilisé dans diverses applications, notamment :
- Support client
- Génération de contenu
- Domaines spécialisés comme les domaines médical et juridique
- Génération de code
Élargir ses applications grâce au fine-tuning
Bien que les LLM pré-entraînés soient polyvalents, ils peuvent bénéficier d’un fine-tuning pour se spécialiser dans des tâches ou domaines particuliers. Ce processus d’adaptation améliore leurs performances et leur pertinence pour des applications spécifiques.
Par exemple : Les entreprises utilisent Llama 3.3 pour créer des chatbots avancés capables de comprendre et de répondre aux demandes des clients en temps réel. Ces chatbots sont affinés pour reconnaître des intentions spécifiques et fournir des réponses précises et contextuellement pertinentes, améliorant ainsi la satisfaction client et réduisant le besoin d’intervention humaine.
Qu’est-ce que le fine-tuning ?
Les avantages du fine-tuning
Le fine-tuning consiste à personnaliser un LLM pré-entraîné pour une tâche ou un ensemble de données spécifique, permettant au modèle de :
- Améliorer la précision et la pertinence en se spécialisant dans des tâches spécifiques.
- Réduire les biais et corriger les erreurs.
- Optimiser l’utilisation des ressources en s’appuyant sur des connaissances existantes plutôt que de repartir de zéro.
- Obtenir de meilleures performances qu’un modèle de base plus volumineux avec un modèle affiné plus petit.
- Nécessiter moins d’ingénierie de prompt.
Applications des modèles affinés
Les LLM affinés peuvent être appliqués à divers cas d’utilisation :
- Résumé de texte
- Génération de texte
- Classification binaire ou textuelle
- Génération de code
- Chatbots
Comment fonctionne le fine-tuning ?
Le fine-tuning ajuste les paramètres d’un modèle pré-entraîné pour l’adapter à une tâche donnée grâce à des techniques telles que :
- Apprentissage auto-supervisé : Entraînement du modèle sur un corpus de texte sélectionné.
- Apprentissage supervisé : Entraînement avec des paires entrée-sortie.
- Apprentissage par renforcement : Entraînement d’un modèle de récompense pour améliorer la qualité des sorties.
- Fine-tuning efficace en paramètres (PEFT) : Gel de la plupart des paramètres du modèle tout en mettant à jour un petit nombre de paramètres supplémentaires.
https://www.youtube.com/watch?v=9PcV6FCv9eQ
De quoi a-t-on besoin pour affiner LLaMA 3 ?
Exigences mémoire du GPU
Le fine-tuning de grands modèles comme LLaMA 3.3 70B nécessite une mémoire GPU importante. Le modèle de base occupe environ 141 Go de RAM GPU, tandis qu’une version quantifiée nécessite environ 40 Go. Même avec la quantification, le fine-tuning peut être gourmand en mémoire.
Considérations de coût
Le fine-tuning complet des paramètres est exigeant en ressources et en temps, nécessitant des ressources GPU importantes et des temps d’achèvement plus longs. L’utilisation d’un GPU de 80 Go est plus rentable car elle permet des tailles de lots plus grandes, accélérant ainsi le processus de fine-tuning.
Exigences en matière d’ensemble de données personnelles
Un ensemble de données de haute qualité est essentiel pour un fine-tuning réussi. L’ensemble de données doit être :
- Pertinent pour la tâche
- Suffisamment volumineux pour améliorer les performances
- Varié pour éviter le surapprentissage
- Formaté correctement pour inclure les instructions, les entrées et les sorties
Le RTX 4090 est-il adapté au fine-tuning local de LLaMA 3.3 70B ?
Réponse : Pas nécessairement adapté
Bien que le RTX 4090 soit un GPU puissant avec 24 Go de VRAM, il peut ne pas suffire pour un fine-tuning complet des paramètres de LLaMA 3.3 70B en raison de ses limitations mémoire. Les performances chutent considérablement lorsque les modèles dépassent la VRAM disponible ; ainsi, si le RTX 4090 peut convenir pour l’inférence – en particulier avec des modèles quantifiés – le fine-tuning nécessite plus de mémoire.
Comment résoudre le problème avec d’autres techniques
Pour contourner les limitations mémoire du RTX 4090, des techniques telles que le fine-tuning efficace en paramètres (PEFT) peuvent être utilisées, notamment :
- LoRA (Low-Rank Adaptation) : Charge le modèle sur le GPU avec des poids quantifiés.
- QLoRA (Quantized LoRA) : Charge le modèle sur le GPU avec des poids encore plus quantifiés.
- Half-Quadratic Quantization (HQQ) : Une autre méthode de quantification en basse précision.
Ces méthodes gèlent les poids du modèle pré-entraîné tout en permettant à un adaptateur d’être affiné par-dessus. Cependant, l’utilisation de bitsandbytes pour la quantification peut donner des résultats moins précis que d’autres méthodes ; il est donc recommandé de remonter certains modules clés en float32 pour de meilleures performances.
Défis liés à l’utilisation de techniques alternatives
Bien que les méthodes PEFT réduisent les besoins en ressources, elles présentent des limitations :
- L’adaptateur affiné ne peut pas être fusionné dans le modèle quantifié.
- La déquantification et la fusion peuvent dégrader considérablement les performances.
- Les modèles utilisant HQQ à des profondeurs de bits inférieures peuvent ne pas être compétitifs par rapport à des modèles plus petits qui fonctionnent mieux sans quantification.
- Le fine-tuning avec un GPU de seulement 48 Go de VRAM est possible mais limité à des tailles de lots de un et à de très petites séquences.
Solutions alternatives – GPU cloud
Pourquoi choisir des instances GPU cloud ?
Les instances GPU cloud constituent une alternative viable au fine-tuning local, en particulier pour les grands modèles comme LLaMA 3.3 70B. Elles offrent :
- Des ressources GPU évolutives en fonction de la charge de travail
- L’accès à des GPU haute performance comme le NVIDIA A100 ou V100
- Des modèles de tarification à l’utilisation rentables
- Des flux de déploiement simplifiés
- La possibilité de contourner les limitations matérielles locales
Services d’instances GPU Novita AI
Comparé à d’autres cloud GPU, notre prix présente les plus grands avantages. Voici un tableau :
| Fournisseur de services | Prix du rtx 4090 (1x GPU par heure) |
|---|---|
| Novita AI | 0,35 $ |
| Vast AI | 0,316 $ - 1,073 $ |
| CoreWeave | Pas de service |
Étapes de déploiement et guide d’utilisation
Étape 1 : Cliquez sur l’instance GPU
Si vous êtes un nouvel abonné, veuillez d’abord créer un compte. Cliquez ensuite sur le bouton [GPU Instance](https://novita.ai/gpus/?utm_source=blogs_gpu&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) sur notre page Web.
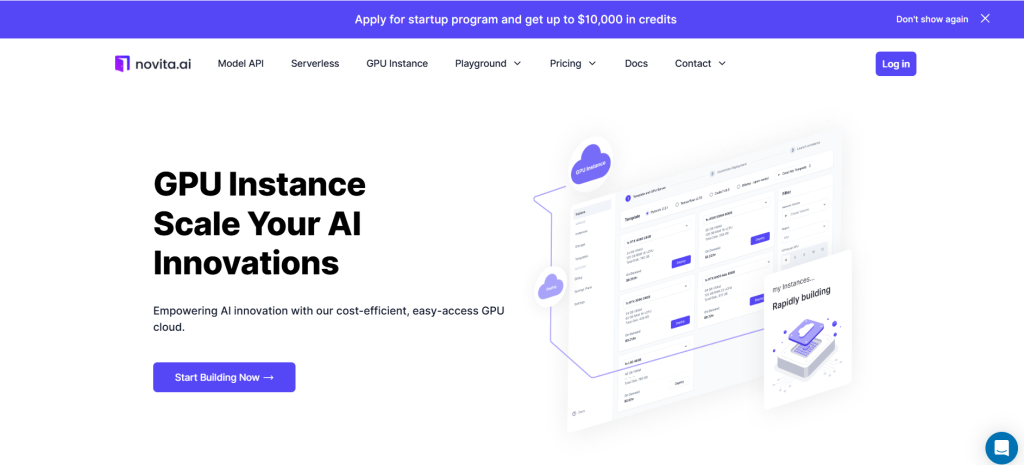
ÉTAPE 2 : Modèle et serveur GPU
Vous pouvez choisir votre propre modèle, notamment Pytorch, Tensorflow, Cuda, Ollama, en fonction de vos besoins spécifiques. De plus, vous pouvez créer vos propres données de modèle en cliquant sur le dernier bouton.
Ensuite, notre service donne accès à des GPU haute performance tels que le NVIDIA RTX 4090, chacun avec une VRAM et une RAM substantielles, garantissant que même les modèles d’IA les plus exigeants peuvent être entraînés efficacement. Vous pouvez le sélectionner en fonction de vos besoins.
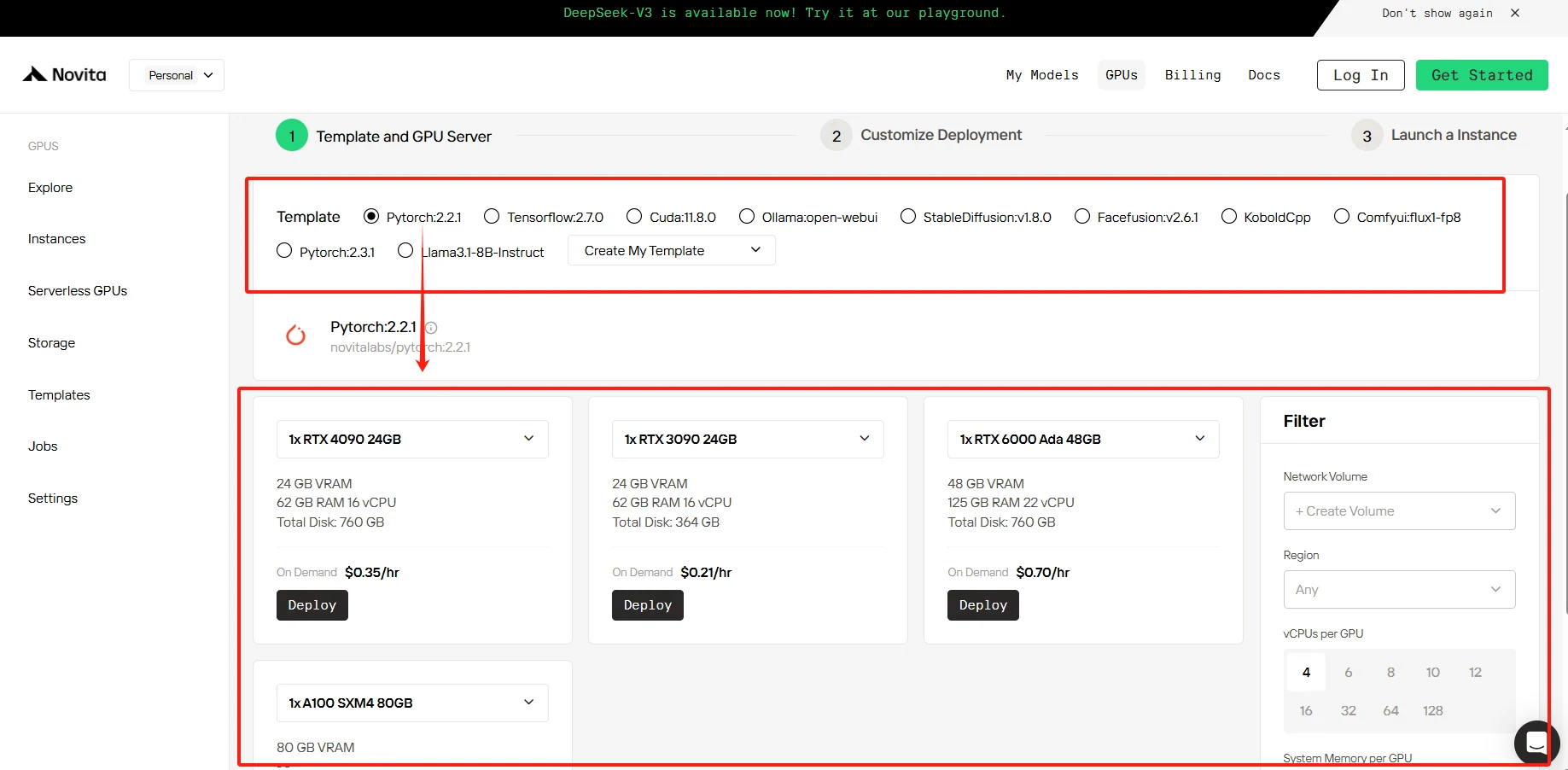
ÉTAPE 3 : Personnalisation du déploiement
Dans cette section, vous pouvez personnaliser ces données selon vos propres besoins. Vous disposez de 60 Go gratuits dans le disque conteneur et 1 Go gratuit dans le disque de volume ; si la limite gratuite est dépassée, des frais supplémentaires seront facturés.
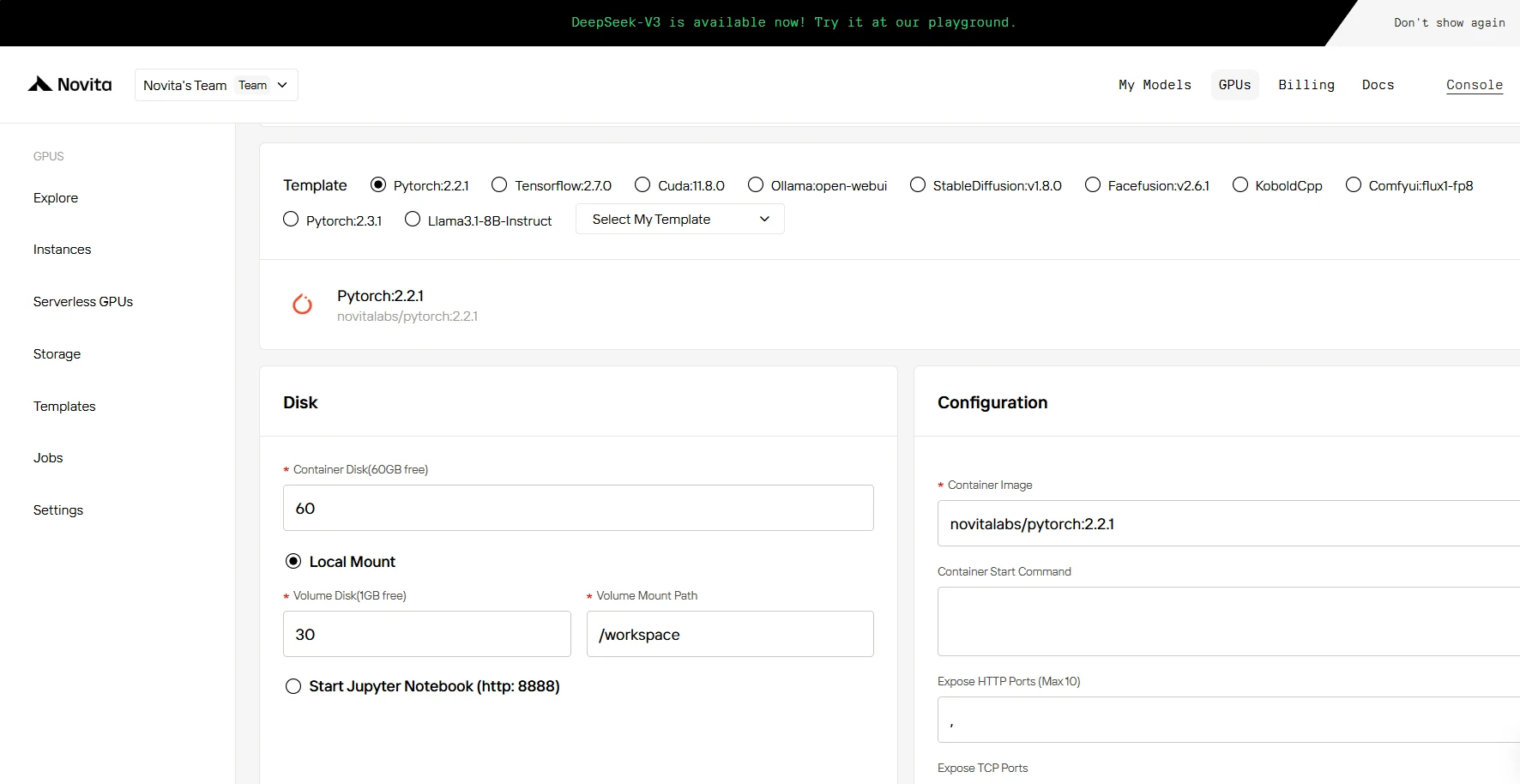
ÉTAPE 4 : Lancer une instance
Que ce soit pour la recherche, le développement ou le déploiement d’applications d’IA, l’instance GPU Novita AI équipée de CUDA 12 offre une expérience de calcul GPU puissante et efficace dans le cloud.
Fine-tuning de LLaMA 3.3 70B : Comparaison des solutions locales et cloud
Fine-tuning local : Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Contrôle total du matériel et des données | Temps d’entraînement plus lents en raison des limitations mémoire et de la puissance de traitement limitée |
| Pas de dépendance à une connexion Internet | Peut être difficile à configurer ; nécessite plus de compétences techniques que les solutions cloud |
| Coût potentiellement plus bas pour de petits travaux de fine-tuning |
Fine-tuning cloud : Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Ressources évolutives pour les grands modèles et ensembles de données | Coûts potentiellement plus élevés selon l’utilisation |
| Temps d’entraînement plus rapides grâce à l’accès à des GPU puissants | |
| Déploiement simplifié et gestion plus facile | |
| Possibilité de gérer plusieurs GPU pour un entraînement distribué |
Conclusion
Le fine-tuning de LLaMA 3.3 70B peut améliorer considérablement ses capacités pour des applications spécifiques. Bien que le RTX 4090 soit adapté à l’inférence et à un fine-tuning limité utilisant des techniques PEFT, ses limitations mémoire le rendent moins idéal pour un réglage à grande échelle d’un modèle aussi volumineux. Les instances GPU cloud, comme celles proposées par Novita AI, offrent des ressources évolutives et des options de déploiement simplifiées qui peuvent répondre efficacement à ces besoins. En fin de compte, le choix entre les solutions locales et cloud dépendra des exigences spécifiques, des ressources disponibles et de l’expertise technique.
Foire aux questions
Taille de Llama 3.3 70B en Go ?
Le modèle Llama 3.3 70B fait environ 40 à 42 Go, selon le niveau de quantification et la version spécifique téléchargée ; la taille la plus couramment rapportée est d’environ 42 Go.
Limite de tokens de Llama 3.3 70B ?
En tant que tel, le nombre maximum de tokens pour une invite est de 130K, au lieu de 8196. Cependant, si vous utilisez une invite très longue, cela consommera plus de mémoire GPU.
[Novita AI](https://novita.ai/?utm_source=blog_GPU&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également le cloud GPU abordable et fiable pour la construction et le passage à l’échelle.
Lecture recommandée
Comment sélectionner le meilleur GPU pour l’inférence LLM : analyse comparative Aperçus
Pourquoi les exigences VRAM de LLaMA 3.3 70B sont un défi pour les serveurs domestiques ?
Llama 3.3 70B : Fonctionnalités, guide d’accès et comparaison de modèles



