

Aspectos destacados
LLaMA 3.3 70B es un modelo de lenguaje de última generación con capacidades impresionantes.
El ajuste fino permite personalizar LLaMA 3.3 70B para tareas específicas, mejorando la precisión y la relevancia.
Si bien la RTX 4090 es una GPU potente, sus limitaciones de memoria pueden dificultar el ajuste fino de LLaMA 3.3 70B.
Los métodos de ajuste fino eficiente en parámetros (PEFT) como LoRA y QLoRA pueden ayudar a mitigar estos desafíos.
Las instancias de GPU en la nube ofrecen una alternativa viable para ajustar modelos grandes como LLaMA 3.3 70B. Puedes usar instancias de GPU de Novita AI: al registrarte, obtienes 60 GB gratis en el disco del contenedor y 1 GB gratis en el disco de volumen; si se supera el límite gratuito, se aplicarán cargos adicionales.
Los modelos de lenguaje grandes (LLM) como LLaMA 3.3 70B han demostrado un potencial notable en el procesamiento del lenguaje natural. Sin embargo, para aprovechar al máximo sus capacidades en aplicaciones específicas, a menudo es necesario realizar un ajuste fino. Este artículo explora la viabilidad de ajustar LLaMA 3.3 70B localmente usando una NVIDIA RTX 4090, analiza los desafíos involucrados y sugiere soluciones alternativas, incluidas instancias de GPU en la nube.
Entendiendo LLaMA 3.3 70B
Arquitectura y escala del modelo
LLaMA 3.3 70B es un modelo de lenguaje grande desarrollado por Meta, basado en una arquitectura Transformer. Está preentrenado en un conjunto de datos masivo de más de 15 billones de tokens, lo que le permite comprender y generar texto similar al humano. La arquitectura del modelo consta de múltiples capas de cabezales de atención que aprenden relaciones entre palabras, permitiendo salidas coherentes y contextualmente apropiadas.
Escenarios de aplicación
LLaMA 3.3 70B se puede utilizar en diversas aplicaciones, incluyendo:
- Atención al cliente
- Generación de contenido
- Dominios especializados como los campos médico y legal
- Generación de código
Ampliando sus aplicaciones mediante el ajuste fino
Si bien los LLM preentrenados son versátiles, pueden beneficiarse del ajuste fino para especializarse en tareas o dominios particulares. Este proceso de adaptación mejora su rendimiento y relevancia para aplicaciones específicas.
Por ejemplo: las empresas aprovechan Llama 3.3 para crear chatbots avanzados que pueden comprender y responder a consultas de clientes en tiempo real. Estos chatbots se ajustan para reconocer intenciones específicas y proporcionar respuestas precisas y contextualmente relevantes, mejorando la satisfacción del cliente y reduciendo la necesidad de intervención humana.
¿Qué es el ajuste fino?
Los beneficios del ajuste fino
El ajuste fino implica personalizar un LLM preentrenado para una tarea o conjunto de datos específico, permitiendo que el modelo:
- Mejore la precisión y relevancia al especializarse en tareas específicas.
- Reduzca sesgos y corrija errores.
- Optimice el uso de recursos al basarse en conocimiento existente en lugar de empezar desde cero.
- Logre un mejor rendimiento que un modelo base más grande usando un modelo ajustado más pequeño.
- Requiera menos ingeniería de prompts.
Las aplicaciones de los modelos ajustados
Los LLM ajustados se pueden aplicar a varios casos de uso:
- Resumen de texto
- Generación de texto
- Clasificación binaria o de texto
- Generación de código
- Chatbots
¿Cómo funciona el ajuste fino?
El ajuste fino ajusta los parámetros de un modelo preentrenado para que sea más adecuado para una tarea determinada mediante técnicas como:
- Aprendizaje autosupervisado: Entrenar el modelo en un corpus de texto curado.
- Aprendizaje supervisado: Entrenar con pares de entrada y salida.
- Aprendizaje por refuerzo: Entrenar un modelo de recompensa para mejorar la calidad de la salida.
- Ajuste fino eficiente en parámetros (PEFT): Congelar la mayoría de los parámetros del modelo mientras se actualiza solo un pequeño número de parámetros adicionales.
https://www.youtube.com/watch?v=9PcV6FCv9eQ
¿Qué se necesita para ajustar LLaMA 3?
Requisitos de memoria de la GPU
El ajuste fino de modelos grandes como LLaMA 3.3 70B requiere una memoria de GPU significativa. El modelo base ocupa aproximadamente 141 GB de RAM de GPU, mientras que una versión cuantizada requiere alrededor de 40 GB. Incluso con cuantización, el ajuste fino puede consumir mucha memoria.
Consideraciones de costos
El ajuste fino completo de parámetros consume muchos recursos y tiempo, lo que requiere recursos de GPU sustanciales y tiempos de finalización más largos. Usar una GPU de 80 GB es más rentable, ya que permite lotes más grandes, acelerando así el proceso de ajuste fino.
Requisitos del conjunto de datos personal
Un conjunto de datos de alta calidad es fundamental para un ajuste fino exitoso. El conjunto de datos debe ser:
- Relevante para la tarea
- Suficientemente grande para mejorar el rendimiento
- Variado para evitar el sobreajuste
- Formateado correctamente para incluir instrucciones, entradas y salidas
¿Es la RTX 4090 adecuada para ajustar LLaMA 3.3 70B localmente?
Respuesta: No necesariamente adecuada
Si bien la RTX 4090 es una GPU potente con 24 GB de VRAM, puede no ser suficiente para el ajuste fino completo de parámetros de LLaMA 3.3 70B debido a sus limitaciones de memoria. El rendimiento disminuye significativamente cuando los modelos superan la VRAM disponible; por lo tanto, aunque la RTX 4090 puede ser adecuada para inferencia—especialmente con modelos cuantizados—el ajuste fino requiere más memoria.
Cómo resolver el problema usando otras técnicas
Para abordar las limitaciones de memoria de la RTX 4090, se pueden emplear técnicas como el ajuste fino eficiente en parámetros (PEFT), que incluyen:
- LoRA (Adaptación de bajo rango): Carga el modelo en la GPU con pesos cuantizados.
- QLoRA (LoRA cuantizado): Carga el modelo en la GPU con pesos aún más cuantizados.
- Cuantización de medio cuadrático (HQQ): Otro método de cuantización de baja precisión.
Estos métodos congelan los pesos del modelo preentrenado mientras permiten ajustar un adaptador sobre él. Sin embargo, usar bitsandbytes para la cuantización puede producir resultados menos precisos en comparación con otros métodos; por lo tanto, se recomienda ascender algunos módulos clave a float32 para un mejor rendimiento.
Desafíos del uso de técnicas alternativas
Si bien los métodos PEFT reducen los requisitos de recursos, tienen limitaciones:
- El adaptador ajustado no se puede fusionar nuevamente en el modelo cuantizado.
- La descuantización y fusión pueden degradar significativamente el rendimiento.
- Los modelos que usan HQQ con profundidades de bits más bajas pueden no competir eficazmente con modelos más pequeños que funcionan mejor sin cuantización.
- El ajuste fino con una GPU que tenga solo 48 GB de VRAM es posible pero limitado a lotes de tamaño uno y secuencias muy pequeñas.
Soluciones alternativas – GPU en la nube
¿Por qué elegir instancias de GPU en la nube?
Las instancias de GPU en la nube presentan una alternativa viable al ajuste fino local, especialmente para modelos grandes como LLaMA 3.3 70B. Proporcionan:
- Recursos de GPU escalables según la demanda de la carga de trabajo
- Acceso a GPU de alto rendimiento como NVIDIA A100 o V100
- Modelos de precios de pago por uso rentables
- Flujos de trabajo de implementación simplificados
- La capacidad de sortear las limitaciones del hardware local
Servicios de instancias de GPU de Novita AI
En comparación con otras GPU en la nube, nuestro precio tiene las mayores ventajas. Aquí tienes una tabla:
| Proveedor de servicios | Precio de rtx 4090 (1 GPU por hora) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | Sin servicio |
Pasos de implementación y guía de uso
Paso 1: Haz clic en GPU Instance
Si eres nuevo suscriptor, primero regístrate en nuestra cuenta. Luego haz clic en el botón GPU Instance en nuestra página web.
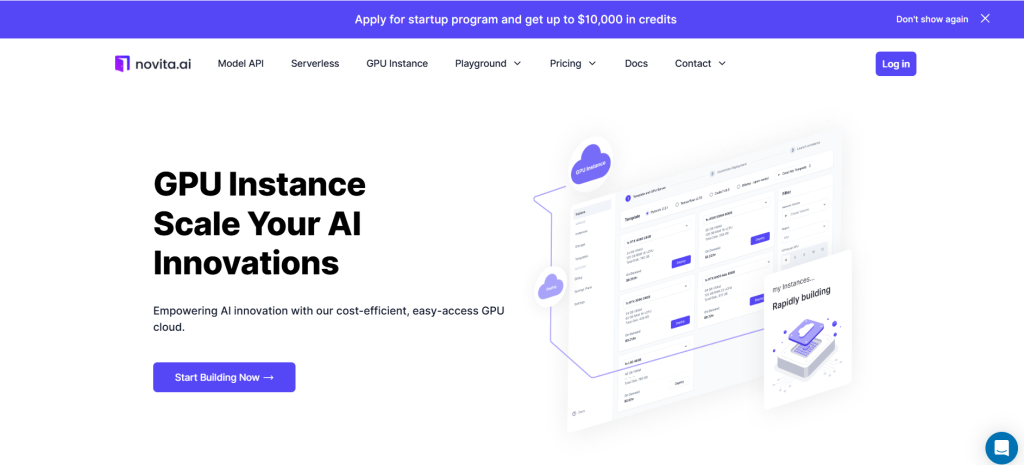
PASO 2: Plantilla y servidor GPU
Puedes elegir tu propia plantilla, incluyendo Pytorch, Tensorflow, Cuda, Ollama, según tus necesidades específicas. Además, también puedes crear tus propios datos de plantilla haciendo clic en el último botón.
Luego, nuestro servicio proporciona acceso a GPU de alto rendimiento como la NVIDIA RTX 4090, cada una con VRAM y RAM sustanciales, lo que garantiza que incluso los modelos de IA más exigentes puedan entrenarse de manera eficiente. Puedes seleccionarla según tus necesidades.
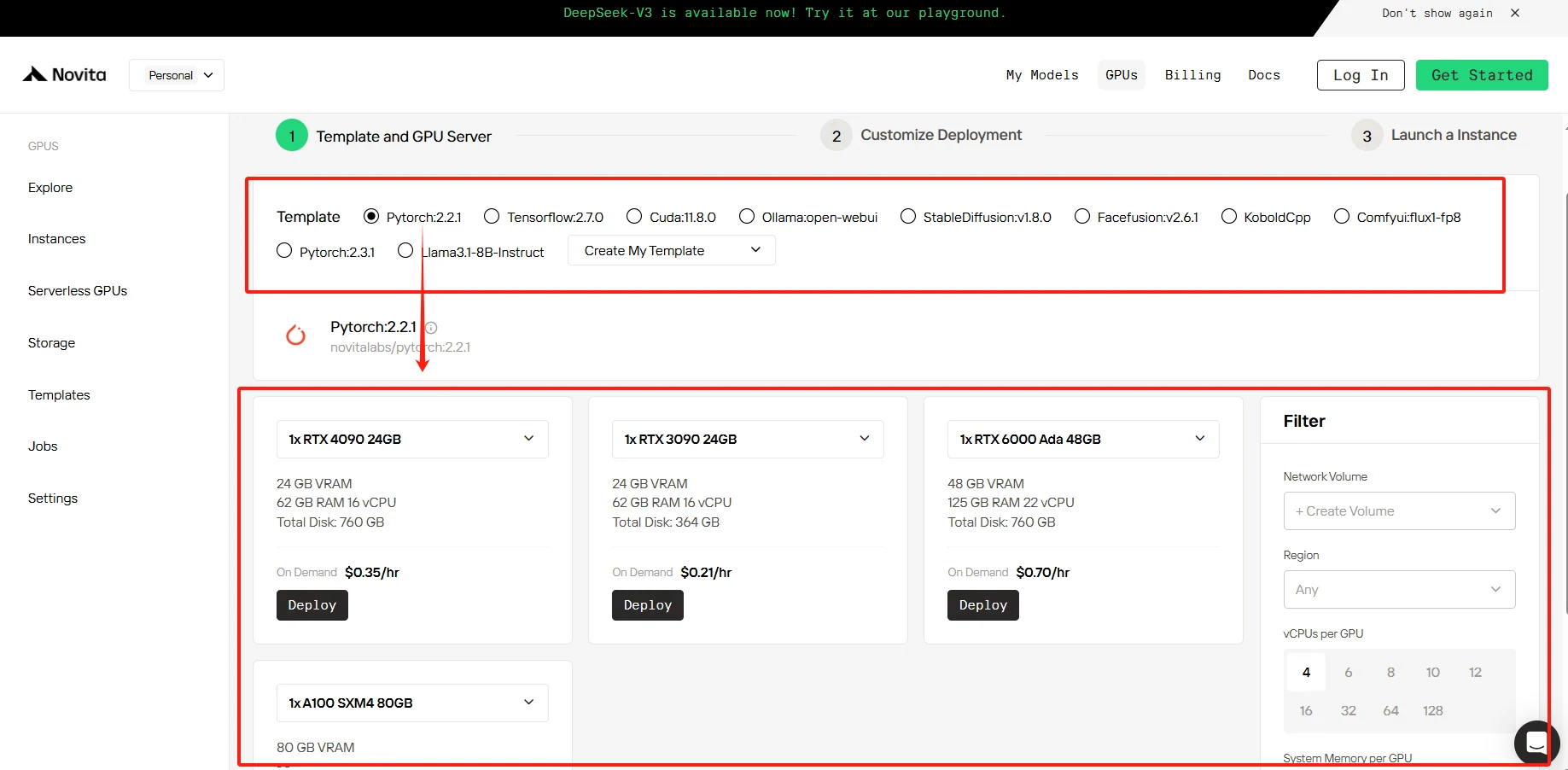
PASO 3: Personalizar la implementación
En esta sección, puedes personalizar estos datos según tus propias necesidades. Hay 60 GB gratis en el disco del contenedor y 1 GB gratis en el disco de volumen; si se supera el límite gratuito, se aplicarán cargos adicionales.
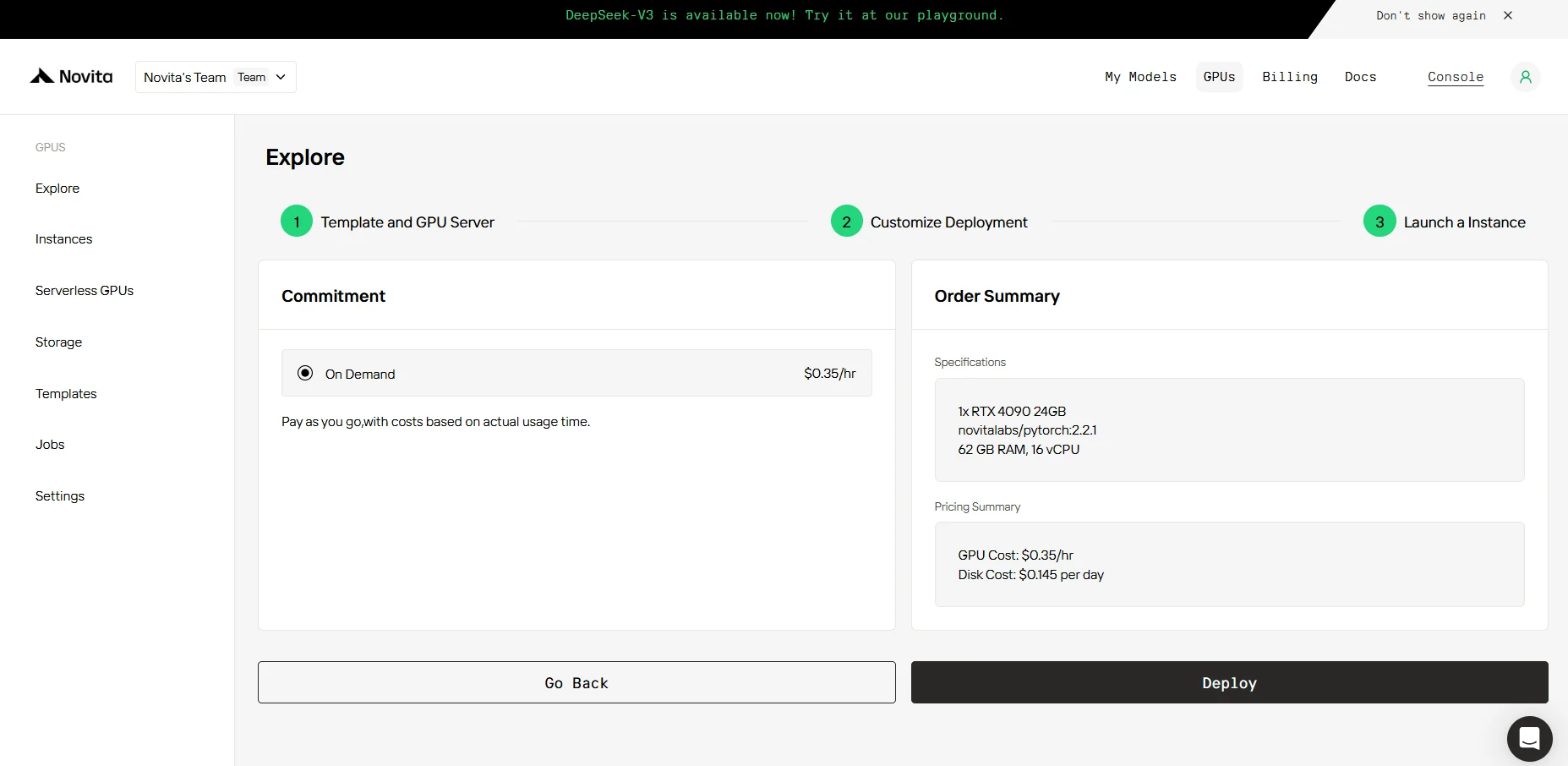
PASO 4: Iniciar una instancia
Ya sea para investigación, desarrollo o implementación de aplicaciones de IA, la instancia de GPU de Novita AI equipada con CUDA 12 ofrece una experiencia de computación GPU potente y eficiente en la nube.
Ajuste fino de LLaMA 3.3 70B: Comparación de soluciones locales y en la nube
Ajuste fino local: Pros y contras
| Pros | Contras |
|---|---|
| Control total sobre el hardware y los datos | Tiempos de entrenamiento más lentos debido a limitaciones de memoria y potencia de procesamiento limitada |
| Sin dependencia de conexión a internet | Puede ser difícil de configurar; requiere más habilidad técnica en comparación con soluciones en la nube |
| Costo potencialmente menor para trabajos de ajuste fino pequeños |
Ajuste fino en la nube: Pros y contras
| Pros | Contras |
|---|---|
| Recursos escalables para modelos y conjuntos de datos grandes | Costos potencialmente más altos según el uso |
| Tiempos de entrenamiento más rápidos con acceso a GPU potentes | |
| Implementación simplificada y gestión más fácil | |
| Capacidad de manejar múltiples GPU para entrenamiento distribuido |
Conclusión
El ajuste fino de LLaMA 3.3 70B puede mejorar significativamente sus capacidades para aplicaciones específicas. Si bien la RTX 4090 es adecuada para inferencia y algunos ajustes finos limitados usando técnicas PEFT, sus limitaciones de memoria la hacen menos ideal para el ajuste a gran escala de un modelo tan grande. Las instancias de GPU en la nube, como las que ofrece Novita AI, proporcionan recursos escalables y opciones de implementación simplificadas que pueden satisfacer estas necesidades de manera efectiva. En última instancia, la elección entre soluciones locales y en la nube dependerá de los requisitos específicos, los recursos disponibles y la experiencia técnica.
Preguntas frecuentes
¿Tamaño de Llama 3.3 70B en GB?
El modelo Llama 3.3 70B tiene aproximadamente 40-42 GB de tamaño, dependiendo del nivel de cuantización y la versión específica descargada; lo más común es que se reporte alrededor de 42 GB.
¿Límite de tokens de Llama 3.3 70B?
El límite máximo de tokens para un prompt es de 130K, en lugar de 8196. Sin embargo, si se usa una entrada de prompt muy larga, consumirá más memoria de GPU.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera fácil de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Lectura recomendada
Cómo seleccionar la mejor GPU para inferencia de LLM: Benchmarking Información
Por qué los requisitos de VRAM de LLaMA 3.3 70B son un desafío para servidores domésticos
Llama 3.3 70B: Características, guía de acceso y comparación de modelos



