

主なポイント
LLaMA 3.3 70B は、優れた性能を備えた最先端の言語モデルです。
ファインチューニングにより、LLaMA 3.3 70B を特定のタスクにカスタマイズし、精度と関連性を向上させることができます。
RTX 4090 は強力な GPU ですが、メモリ制限により LLaMA 3.3 70B のファインチューニングは困難を伴います。
LoRA や QLoRA などのパラメータ効率的ファインチューニング(PEFT)手法は、これらの課題を軽減するのに役立ちます。
クラウド GPU インスタンスは、LLaMA 3.3 70B のような大規模モデルのファインチューニングに有効な代替手段となります。Novita AI の GPU インスタンスをご利用いただけます。登録時点でコンテナディスク 60GB、ボリュームディスク 1GB が無料で提供され、無料枠を超えた場合は追加料金が発生します。
大規模言語モデル(LLM)、特に LLaMA 3.3 70B は、自然言語処理において目覚ましい可能性を示しています。しかし、特定のアプリケーションでその能力を最大限に活用するには、ファインチューニングがしばしば必要です。この記事では、NVIDIA RTX 4090 をローカルで使用して LLaMA 3.3 70B をファインチューニングする実現可能性を探り、関連する課題を議論し、クラウドベースの GPU インスタンスを含む代替ソリューションを提案します。
LLaMA 3.3 70B を理解する
モデルのアーキテクチャと規模
LLaMA 3.3 70B は Meta が開発した大規模言語モデルで、Transformer アーキテクチャに基づいています。15 兆トークン以上の膨大なデータセットで事前学習されており、人間らしいテキストを理解し生成することができます。モデルのアーキテクチャは、単語間の関係を学習する複数のアテンションヘッド層で構成され、首尾一貫した文脈に適した出力を可能にします。
アプリケーションシナリオ
LLaMA 3.3 70B は、以下のようなさまざまなアプリケーションで利用できます。
- カスタマーサポート
- コンテンツ生成
- 医療や法律などの専門分野
- コード生成
ファインチューニングによるアプリケーションの拡大
事前学習済み LLM は汎用的ですが、特定のタスクやドメインに特化させるためにファインチューニングを行うことで、その性能と関連性が向上します。
例:企業は Llama 3.3 を活用して、リアルタイムで顧客の問い合わせを理解し応答できる高度なチャットボットを作成しています。これらのチャットボットはファインチューニングにより特定の意図を認識し、正確で文脈に沿った応答を提供し、顧客満足度を高め、人間の介入の必要性を減らしています。
ファインチューニングとは?
ファインチューニングの利点
ファインチューニングとは、事前学習済み LLM を特定のタスクやデータセットに合わせてカスタマイズするプロセスであり、モデルは以下の恩恵を受けます。
- 精度と関連性の向上:特定のタスクに特化することで実現。
- バイアスの低減 と誤りの修正。
- リソースの最適化:ゼロから始めるのではなく、既存の知識を活用。
- より小さなファインチューニング済みモデルを使用して、より大きなベースモデルよりも優れた性能を達成。
- プロンプトエンジニアリングの必要性が低減。
ファインチューニング済みモデルの応用
ファインチューニング済み LLM は、さまざまなユースケースに適用できます。
- テキスト要約
- テキスト生成
- 二値分類またはテキスト分類
- コード生成
- チャットボット
ファインチューニングの仕組み
ファインチューニングでは、以下の手法を用いて事前学習済みモデルのパラメータを調整し、特定のタスクに適したものにします。
- 自己教師あり学習:厳選されたテキストコーパスでモデルを学習。
- 教師あり学習:入力と出力のペアを使用して学習。
- 強化学習:報酬モデルを学習して出力の品質を向上。
- パラメータ効率的ファインチューニング(PEFT):ほとんどのモデルパラメータを固定し、少数の追加パラメータのみを更新。
https://www.youtube.com/watch?v=9PcV6FCv9eQ
LLaMA 3 のファインチューニングに必要なもの
GPU のメモリ要件
LLaMA 3.3 70B のような大規模モデルのファインチューニングには、大量の GPU メモリが必要です。ベースモデルは約 141 GB の GPU RAM を占有し、量子化バージョンでも約 40 GB が必要です。量子化を適用しても、ファインチューニングはメモリ集約的です。
コストの考慮
全パラメータのファインチューニングはリソースと時間を大量に消費し、大きな GPU リソースと長い完了時間が必要です。80 GB GPU を使用すると、より大きなバッチサイズが可能になりファインチューニングプロセスが加速されるため、コスト効率が向上します。
個人データセットの要件
成功するファインチューニングには高品質なデータセットが不可欠です。データセットは以下の条件を満たす必要があります。
- タスクに 関連 していること
- 性能向上に十分な サイズ であること
- 過学習を避けるために 多様 であること
- 指示、入力、出力を含む正しい形式であること
RTX 4090 は LLaMA 3.3 70B のローカルファインチューニングに適しているか?
回答:必ずしも適していない
RTX 4090 は 24 GB の VRAM を備えた強力な GPU ですが、LLaMA 3.3 70B の全パラメータファインチューニングにはメモリ制限があるため不十分な場合があります。モデルが利用可能な VRAM を超えると性能が大幅に低下するため、RTX 4090 は推論(特に量子化モデル)には適しているかもしれませんが、ファインチューニングにはより多くのメモリが必要です。
他の手法を使用して問題を解決する方法
RTX 4090 のメモリ制限に対処するには、パラメータ効率的ファインチューニング(PEFT)手法を採用できます。これには以下が含まれます。
- LoRA(Low-Rank Adaptation):量子化された重みでモデルを GPU にロード。
- QLoRA(Quantized LoRA):さらに量子化された重みでモデルを GPU にロード。
- Half-Quadratic Quantization(HQQ):別の低精度量子化手法。
これらの手法は、事前学習済みモデルの重みを固定し、その上でアダプターをファインチューニングできるようにします。ただし、bitsandbytes を使用した量子化は、他の手法と比較して精度が低くなる可能性があるため、一部の主要モジュールを float32 にアップキャストして性能を向上させることを推奨します。
代替手法を使用する際の課題
PEFT 手法はリソース要件を削減しますが、次のような制限があります。
- ファインチューニングされたアダプターは量子化済みモデルにマージできない。
- 量子化解除とマージにより性能が大幅に低下する可能性がある。
- 低ビット深度で HQQ を使用したモデルは、量子化なしで性能を発揮するより小規模なモデルと競合できない場合がある。
- VRAM 48 GB の GPU でのファインチューニングは可能ですが、バッチサイズ 1 と小さなシーケンスに制限される。
代替ソリューション – クラウド GPU
クラウド GPU インスタンスを選ぶ理由
クラウド GPU インスタンスは、特に LLaMA 3.3 70B のような大規模モデルにおいて、ローカルファインチューニングの有力な代替手段です。以下の利点があります。
- ワークロードに応じて拡張可能な GPU リソース
- NVIDIA A100 や V100 などの高性能 GPU へのアクセス
- コスト効率の良い従量課金モデル
- 簡素化されたデプロイメントワークフロー
- ローカルハードウェアの制限を回避できる
Novita AI GPU インスタンスサービス
他の GPU クラウドと比較して、当社の価格は最大の利点 です。以下の表をご覧ください。
| サービスプロバイダー | rtx 4090 の価格(1x GPU 1時間あたり) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | サービスなし |
デプロイ手順と使用ガイド
ステップ1: GPU インスタンスをクリック
新規登録の場合は、まずアカウントを登録してください。次に、Web ページ上の GPU インスタンス ボタンをクリックします。
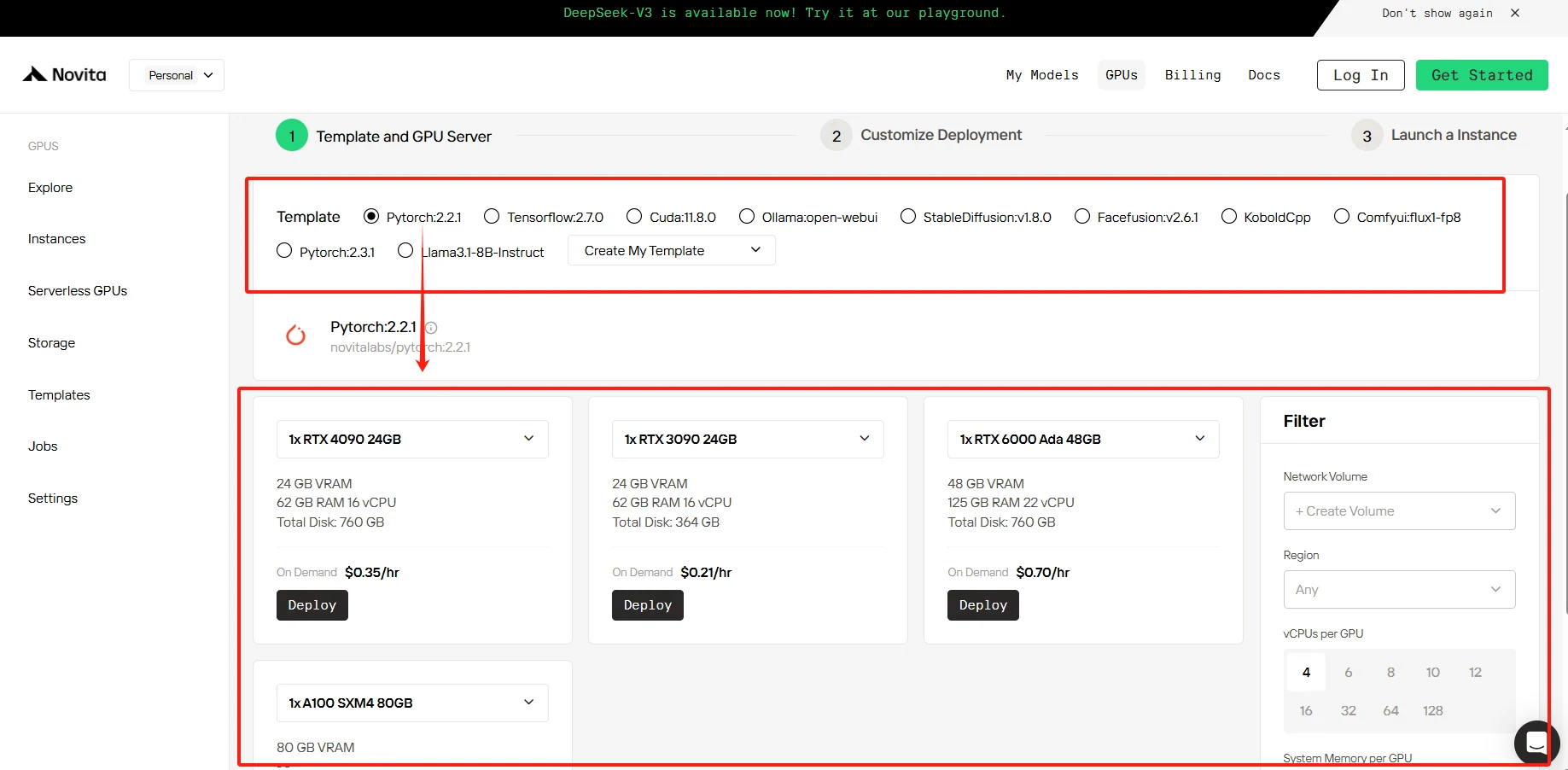
ステップ2: テンプレートと GPU サーバー
特定のニーズに応じて、Pytorch、Tensorflow、Cuda、Ollama を含む独自のテンプレートを選択できます。さらに、一番下のボタンをクリックして独自のテンプレートデータを作成することもできます。
さらに、当サービスでは NVIDIA RTX 4090 などの高性能 GPU へのアクセスを提供し、各 GPU は十分な VRAM と RAM を備えており、最も要求の厳しい AI モデルでも効率的にトレーニングできます。ニーズに基づいて選択してください。
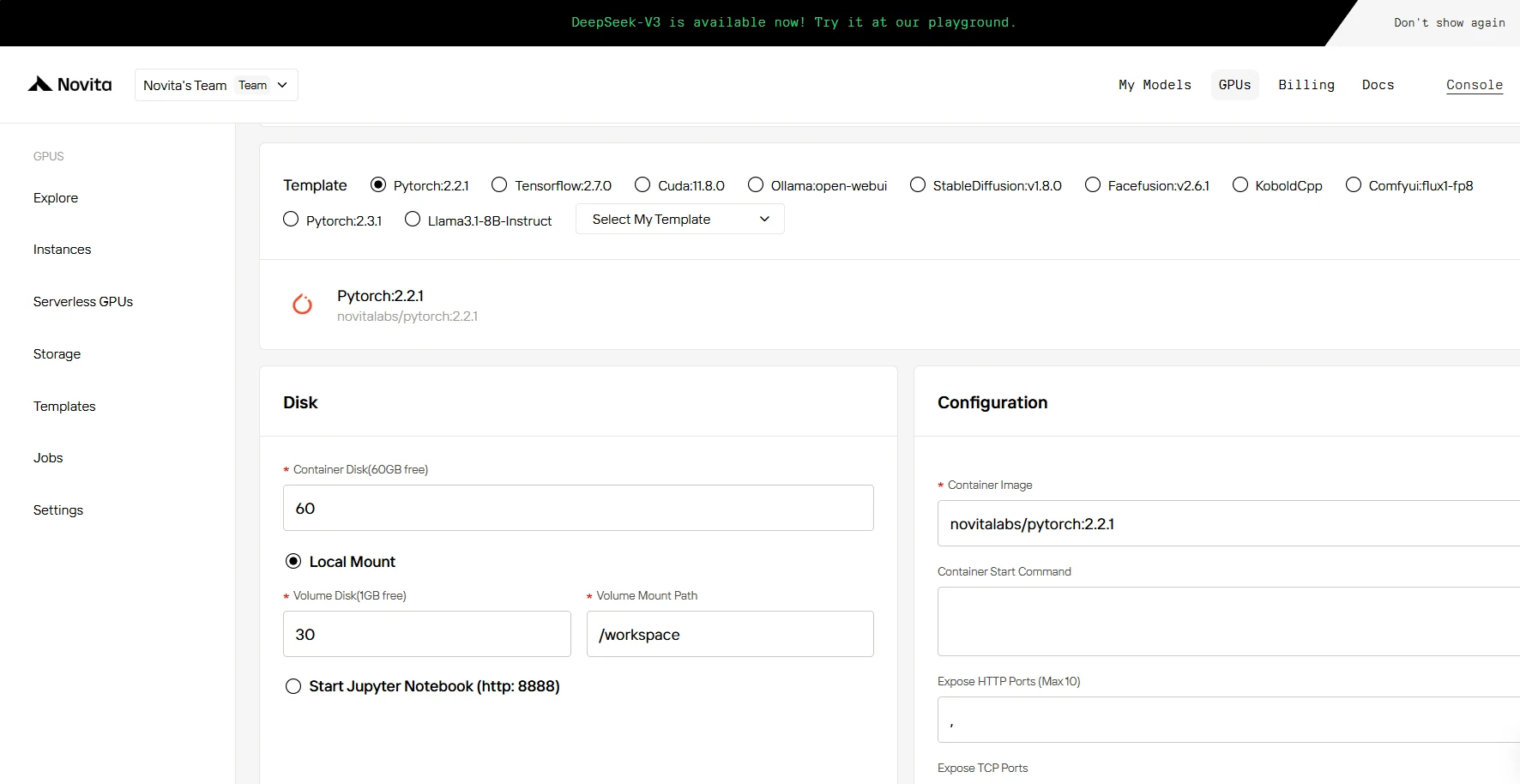
ステップ3: デプロイのカスタマイズ
このセクションでは、必要に応じてデータをカスタマイズできます。コンテナディスク 60GB、ボリュームディスク 1GB が無料で提供され、無料枠を超えた場合は追加料金が発生します。
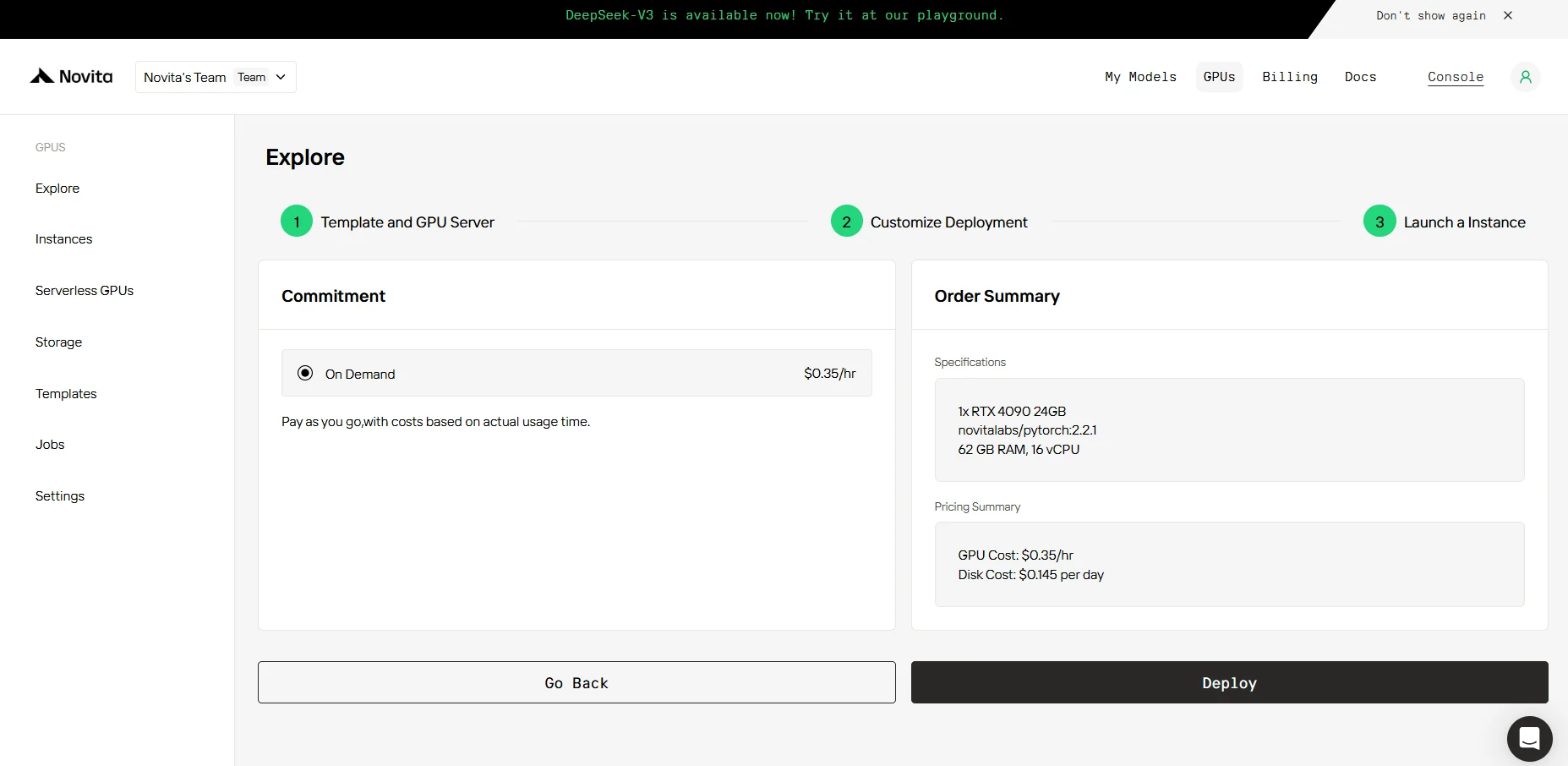
ステップ4: インスタンスを起動
AI アプリケーションの研究、開発、デプロイを問わず、CUDA 12 を搭載した Novita AI GPU インスタンスは、クラウド上で強力かつ効率的な GPU コンピューティング体験を提供します。
LLaMA 3.3 70B のファインチューニング:ローカルソリューションとクラウドソリューションの比較
ローカルファインチューニング:長所と短所
| 長所 | 短所 |
|---|---|
| ハードウェアとデータを完全に制御できる | メモリ制限と処理能力の制限により学習時間が長い |
| インターネット接続が不要 | セットアップが難しい場合があり、クラウドソリューションよりも技術的なスキルが必要 |
| 小規模なファインチューニングジョブではコストが低くなる可能性がある |
クラウドファインチューニング:長所と短所
| 長所 | 短所 |
|---|---|
| 大規模なモデルやデータセットに拡張可能なリソース | 使用状況によってはコストが高くなる可能性がある |
| 強力な GPU へのアクセスによる高速な学習時間 | |
| 簡素化されたデプロイと管理の容易さ | |
| 分散トレーニングのための複数 GPU の処理能力 |
結論
LLaMA 3.3 70B のファインチューニングは、特定のアプリケーションにおけるその能力を大幅に向上させることができます。RTX 4090 は推論や PEFT 手法を使用した限定的なファインチューニングには適していますが、そのメモリ制限により、このような大規模モデルのフルスケールチューニングには理想的ではありません。Novita AI が提供するようなクラウド GPU インスタンスは、スケーラブルなリソースと簡素化されたデプロイオプションを提供し、これらのニーズを効果的に満たすことができます。最終的にローカルソリューションとクラウドソリューションのどちらを選択するかは、特定の要件、利用可能なリソース、技術的な専門知識に依存します。
よくある質問
Llama 3.3 70B のサイズ(GB)は?
Llama 3.3 70B モデルのサイズは、量子化レベルとダウンロードする特定のバージョンによって約 40~42 GB です。最も一般的には約 42 GB と報告されています。
Llama 3.3 70B のトークン制限は?
プロンプトの最大トークン制限は 130K であり、8196 ではありません。ただし、非常に長いプロンプト入力を使用する場合は、より多くの GPU メモリを消費します。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、手頃な価格で信頼性の高い GPU クラウドも提供しています。
おすすめの記事
LLM 推論に最適な GPU の選び方:ベンチマークインサイト



