

النقاط الرئيسية
LLaMA 3.3 70B هو نموذج لغوي حديث بقدرات مذهلة.
يسمح الضبط الدقيق بتخصيص LLaMA 3.3 70B لمهام محددة، مما يحسن الدقة والملاءمة.
على الرغم من أن RTX 4090 هي وحدة معالجة رسومية قوية، إلا أن قيود ذاكرتها تجعل الضبط الدقيق لـ LLaMA 3.3 70B صعبًا.
يمكن أن تساعد طرق الضبط الدقيق الفعالة من حيث المعلمات (PEFT) مثل LoRA و QLoRA في تخفيف هذه التحديات.
توفر مثيلات وحدة المعالجة الرسومية السحابية بديلاً قابلاً للتطبيق للضبط الدقيق للنماذج الكبيرة مثل LLaMA 3.3 70B. يمكنك استخدام مثيلات GPU من Novita AI — عند التسجيل، هناك 60 جيجابايت مجانًا في قرص الحاوية و 1 جيجابايت مجانًا في قرص الحجم، وإذا تم تجاوز الحد المجاني، سيتم فرض رسوم إضافية.
أظهرت نماذج اللغة الكبيرة (LLMs) مثل LLaMA 3.3 70B إمكانات رائعة في معالجة اللغة الطبيعية. ومع ذلك، للاستفادة الكاملة من قدراتها في تطبيقات محددة، غالبًا ما يكون الضبط الدقيق ضروريًا. تستكشف هذه المقالة جدوى ضبط LLaMA 3.3 70B محليًا باستخدام NVIDIA RTX 4090، وتناقش التحديات التي تنطوي عليها، وتقترح حلولاً بديلة، بما في ذلك مثيلات وحدة المعالجة الرسومية السحابية.
فهم LLaMA 3.3 70B
بنية النموذج وحجمه
LLaMA 3.3 70B هو نموذج لغة كبير طورته Meta، مبني على بنية Transformer. تم تدريبه مسبقًا على مجموعة بيانات ضخمة تزيد عن 15 تريليون رمز مميز، مما يمكنه من فهم وإنتاج نص يشبه الإنسان. تتكون بنية النموذج من طبقات متعددة من رؤوس الانتباه التي تتعلم العلاقات بين الكلمات، مما يسمح بمخرجات متماسكة ومناسبة سياقيًا.
سيناريوهات التطبيق
يمكن استخدام LLaMA 3.3 70B في تطبيقات متنوعة تشمل:
- دعم العملاء
- إنشاء المحتوى
- المجالات المتخصصة مثل المجالات الطبية والقانونية
- إنشاء الكود
توسيع تطبيقاته من خلال الضبط الدقيق
على الرغم من أن نماذج اللغة الكبيرة المدربة مسبقًا متعددة الاستخدامات، إلا أنها يمكن أن تستفيد من الضبط الدقيق للتخصص في مهام أو مجالات معينة. تعزز عملية التكيف هذه أدائها وملاءمتها للتطبيقات المحددة.
على سبيل المثال: تستفيد الشركات من Llama 3.3 لإنشاء روبوتات محادثة متقدمة يمكنها فهم والرد على استفسارات العملاء في الوقت الفعلي. يتم ضبط هذه الروبوتات بدقة للتعرف على نوايا محددة وتقديم ردود دقيقة وذات صلة سياقيًا، مما يعزز رضا العملاء ويقلل الحاجة إلى التدخل البشري.
ما هو الضبط الدقيق؟
فوائد الضبط الدقيق
يتضمن الضبط الدقيق تخصيص نموذج لغة كبير مدرب مسبقًا لمهمة أو مجموعة بيانات محددة، مما يسمح للنموذج بـ:
- تحسين الدقة والملاءمة من خلال التخصص في مهام محددة.
- تقليل التحيز وتصحيح الأخطاء.
- تحسين استخدام الموارد من خلال البناء على المعرفة الحالية بدلاً من البدء من الصفر.
- تحقيق أداء أفضل من نموذج أساسي أكبر باستخدام نموذج مضبوط بدقة أصغر.
- يتطلب هندسة استفسارات أقل.
تطبيقات النماذج المضبوطة بدقة
يمكن تطبيق نماذج اللغة الكبيرة المضبوطة بدقة على حالات استخدام متنوعة:
- تلخيص النص
- إنشاء النص
- التصنيف الثنائي أو النصي
- إنشاء الكود
- روبوتات المحادثة
كيف يعمل الضبط الدقيق؟
يضبط الضبط الدقيق معلمات النموذج المدرب مسبقًا لجعله أكثر ملاءمة لمهمة معينة من خلال تقنيات مثل:
- التعلم الذاتي الإشراف: تدريب النموذج على مجموعة نصوص منسقة.
- التعلم الخاضع للإشراف: التدريب بأزواج المدخلات والمخرجات.
- التعلم التعزيزي: تدريب نموذج مكافأة لتحسين جودة المخرجات.
- الضبط الدقيق الفعال من حيث المعلمات (PEFT): تجميد معظم معلمات النموذج مع تحديث عدد صغير فقط من المعلمات الإضافية.
https://www.youtube.com/watch?v=9PcV6FCv9eQ
ما المطلوب لضبط LLaMA 3 بدقة؟
متطلبات ذاكرة GPU
يتطلب الضبط الدقيق للنماذج الكبيرة مثل LLaMA 3.3 70B ذاكرة GPU كبيرة. يشغل النموذج الأساسي حوالي 141 جيجابايت من ذاكرة الوصول العشوائي لوحدة معالجة الرسوميات، بينما تتطلب النسخة الكمية حوالي 40 جيجابايت. حتى مع التكميم، يمكن أن يكون الضبط الدقيق كثيفًا في استخدام الذاكرة.
اعتبارات التكلفة
الضبط الدقيق الكامل للمعلمات هو عملية كثيفة الموارد وتستغرق وقتًا طويلاً، وتتطلب موارد GPU كبيرة وأوقات إنجاز أطول. استخدام GPU بسعة 80 جيجابايت أكثر فعالية من حيث التكلفة لأنه يسمح بأحجام دفعات أكبر، مما يسرع عملية الضبط الدقيق.
متطلبات مجموعة البيانات الشخصية
مجموعة البيانات عالية الجودة ضرورية للضبط الدقيق الناجح. يجب أن تكون مجموعة البيانات:
- ذات صلة بالمهمة
- كبيرة بما يكفي لتحسين الأداء
- متنوعة لتجنب الإفراط في التجهيز
- منسقة بشكل صحيح لتشمل التعليمات والمدخلات والمخرجات
هل RTX 4090 مناسبة للضبط الدقيق المحلي لـ LLaMA 3.3 70B؟
الإجابة: ليست مناسبة بالضرورة
على الرغم من أن RTX 4090 هي وحدة معالجة رسومية قوية بذاكرة VRAM سعة 24 جيجابايت، إلا أنها قد لا تكون كافية للضبط الدقيق الكامل للمعلمات لـ LLaMA 3.3 70B بسبب قيود الذاكرة. ينخفض الأداء بشكل كبير عندما تتجاوز النماذج VRAM المتاحة؛ وبالتالي، في حين أن RTX 4090 قد تكون مناسبة للاستدلال—خاصة مع النماذج المكممة—فإن الضبط الدقيق يتطلب ذاكرة أكبر.
كيفية حل المشكلة باستخدام تقنيات أخرى
لمعالجة قيود الذاكرة لـ RTX 4090، يمكن استخدام تقنيات مثل الضبط الدقيق الفعال من حيث المعلمات (PEFT)، بما في ذلك:
- LoRA (التكيف منخفض الرتبة): تحميل النموذج على GPU بأوزان مكممة.
- QLoRA (LoRA المكمم): تحميل النموذج على GPU بأوزان مكممة بشكل أكبر.
- التكميم النصفي التربيعي (HQQ): طريقة تكميم منخفضة الدقة أخرى.
تعمل هذه الطرق على تجميد أوزان النموذج المدرب مسبقًا مع السماح بضبط محول أعلى النموذج بدقة. ومع ذلك، قد يؤدي استخدام bitsandbytes للتكميم إلى نتائج أقل دقة مقارنة بالطرق الأخرى؛ لذلك، يوصى برفع بعض الوحدات الرئيسية إلى float32 للحصول على أداء أفضل.
تحديات استخدام التقنيات البديلة
بينما تقلل طرق PEFT من متطلبات الموارد، إلا أنها تأتي مع قيود:
- لا يمكن دمج المحول المضبوط بدقة مرة أخرى في النموذج المكمم.
- يمكن أن يؤدي إلغاء التكميم والدمج إلى تدهور الأداء بشكل كبير.
- النماذج التي تستخدم HQQ بأعماق بت أقل قد لا تنافس بفعالية النماذج الأصغر التي تؤدي بشكل أفضل بدون تكميم.
- الضبط الدقيق باستخدام GPU بسعة 48 جيجابايت VRAM فقط ممكن ولكنه يقتصر على أحجام دفعات واحدة وتسلسلات صغيرة جدًا.
حلول بديلة – وحدة معالجة رسومية سحابية
لماذا تختار مثيلات وحدة المعالجة الرسومية السحابية؟
توفر مثيلات وحدة المعالجة الرسومية السحابية بديلاً قابلاً للتطبيق للضبط الدقيق المحلي، خاصة للنماذج الكبيرة مثل LLaMA 3.3 70B. توفر:
- موارد GPU قابلة للتوسع بناءً على عبء العمل
- الوصول إلى وحدات معالجة رسومية عالية الأداء مثل NVIDIA A100 أو V100
- نماذج تسعير فعالة من حيث التكلفة (الدفع أولاً بأول)
- سير عمل نشر مبسط
- القدرة على تجاوز قيود الأجهزة المحلية
خدمات مثيلات GPU من Novita AI
مقارنة مع سحابات GPU الأخرى، سعرنا يتمتع بأكبر المزايا. إليك جدول للمقارنة:
| مزود الخدمة | سعر rtx 4090 (1 GPU في الساعة) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | لا توجد خدمة |
خطوات النشر ودليل الاستخدام
الخطوة 1: انقر على مثيل GPU
إذا كنت مشتركًا جديدًا، يرجى تسجيل حسابنا أولاً. ثم انقر على زر مثيل GPU في صفحة الويب الخاصة بنا.
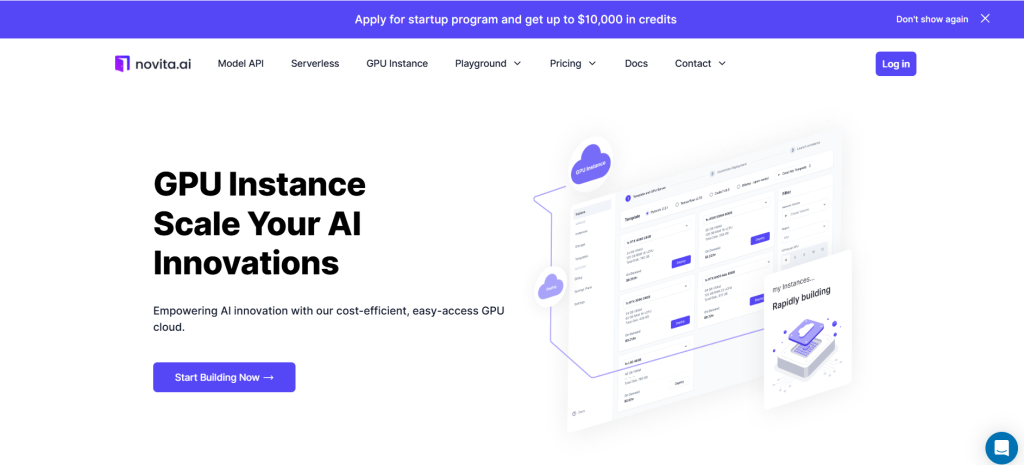
الخطوة 2: القالب وخادم GPU
يمكنك اختيار القالب الخاص بك، بما في ذلك Pytorch و Tensorflow و Cuda و Ollama، وفقًا لاحتياجاتك المحددة. علاوة على ذلك، يمكنك أيضًا إنشاء بيانات القالب الخاصة بك بالنقر على الزر السفلي الأخير.
ثم، توفر خدمتنا الوصول إلى وحدات معالجة رسومية عالية الأداء مثل NVIDIA RTX 4090، لكل منها سعة VRAM و RAM كبيرة، مما يضمن إمكانية تدريب حتى نماذج الذكاء الاصطناعي الأكثر تطلبًا بكفاءة. يمكنك اختيارها بناءً على احتياجاتك.
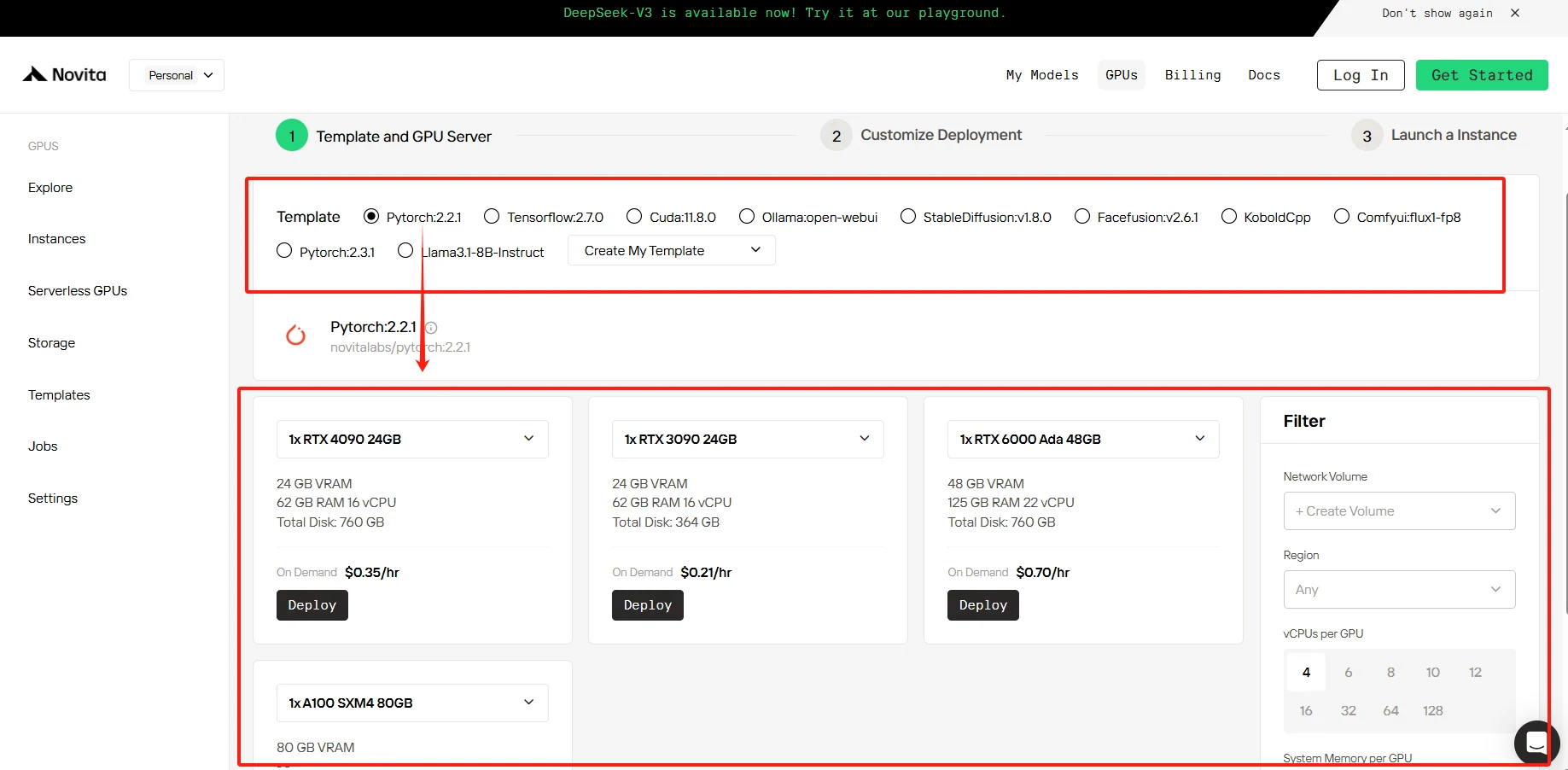
الخطوة 3: تخصيص النشر
في هذا القسم، يمكنك تخصيص هذه البيانات وفقًا لاحتياجاتك الخاصة. هناك 60 جيجابايت مجانًا في قرص الحاوية و 1 جيجابايت مجانًا في قرص الحجم، وإذا تم تجاوز الحد المجاني، سيتم فرض رسوم إضافية.
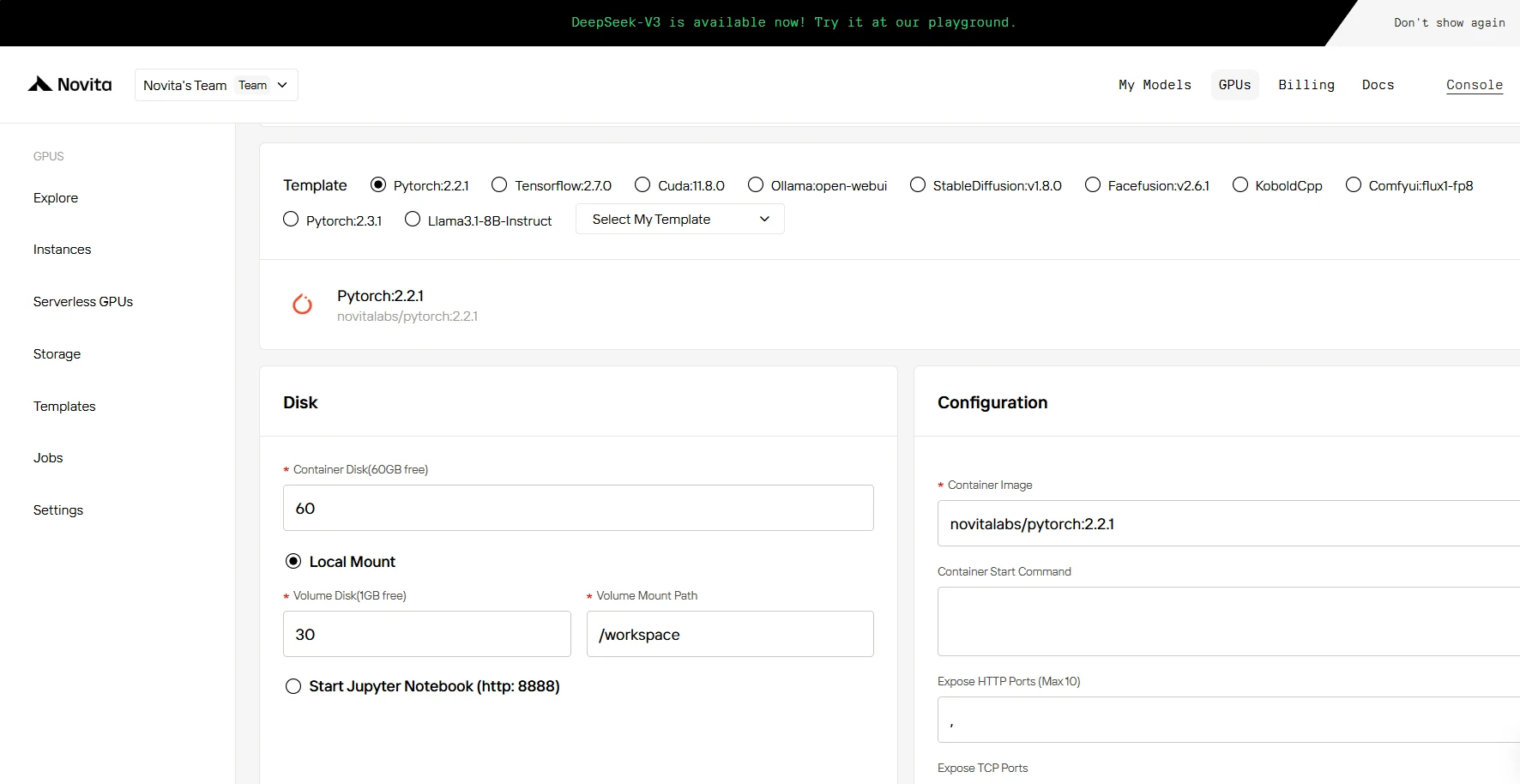
الخطوة 4: إطلاق مثيل ****
سواء كان ذلك للبحث أو التطوير أو نشر تطبيقات الذكاء الاصطناعي، فإن مثيل GPU من Novita AI المجهز بـ CUDA 12 يوفر تجربة حوسبة GPU قوية وفعالة في السحابة.
الضبط الدقيق لـ LLaMA 3.3 70B: مقارنة الحلول المحلية والسحابية
الضبط الدقيق المحلي: الإيجابيات والسلبيات
| الإيجابيات | السلبيات |
|---|---|
| التحكم الكامل في الأجهزة والبيانات | أوقات تدريب أبطأ بسبب قيود الذاكرة وقوة المعالجة المحدودة |
| لا حاجة للاعتماد على اتصال الإنترنت | يمكن أن يكون الإعداد صعبًا؛ يتطلب مهارات تقنية أكثر مقارنة بالحلول السحابية |
| تكلفة أقل محتملة لمهام الضبط الدقيق الصغيرة |
الضبط الدقيق السحابي: الإيجابيات والسلبيات
| الإيجابيات | السلبيات |
|---|---|
| موارد قابلة للتوسع للنماذج ومجموعات البيانات الكبيرة | تكاليف أعلى محتملة حسب الاستخدام |
| أوقات تدريب أسرع مع الوصول إلى وحدات معالجة رسومية قوية | |
| نشر مبسط وإدارة أسهل | |
| القدرة على التعامل مع عدة وحدات معالجة رسومية للتدريب الموزع |
الاستنتاج
يمكن أن يعزز الضبط الدقيق لـ LLaMA 3.3 70B قدراته بشكل كبير للتطبيقات المحددة. بينما تعتبر RTX 4090 مناسبة للاستدلال وبعض الضبط الدقيق المحدود باستخدام تقنيات PEFT، فإن قيود ذاكرتها تجعلها أقل مثالية للضبط الدقيق الكامل لمثل هذا النموذج الكبير. توفر مثيلات وحدة المعالجة الرسومية السحابية، مثل تلك التي تقدمها Novita AI، موارد قابلة للتوسع وخيارات نشر مبسطة يمكن أن تلبي هذه الاحتياجات بفعالية. في النهاية، يعتمد الاختيار بين الحلول المحلية والسحابية على المتطلبات المحددة والموارد المتاحة والخبرة التقنية.
الأسئلة المتكررة
حجم LLaMA 3.3 70B بالجيجابايت؟
يبلغ حجم نموذج LLaMA 3.3 70B حوالي 40-42 جيجابايت، اعتمادًا على مستوى التكميم والإصدار المحدد الذي تم تنزيله؛ الأكثر شيوعًا هو حوالي 42 جيجابايت.
حد الرموز المميزة لـ LLaMA 3.3 70B؟
على هذا النحو، الحد الأقصى لعدد الرموز المميزة للاستفسار هو 130 ألف، بدلاً من 8196. ومع ذلك، إذا كنت تستخدم إدخال استفسار طويل جدًا، فإنه سيستهلك المزيد من ذاكرة GPU.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
قراءات موصى بها
كيفية اختيار أفضل GPU لاستدلال LLM: قياس الأداء رؤى
لماذا تعد متطلبات VRAM لـ LLaMA 3.3 70B تحديًا للخوادم المنزلية؟



