

重點摘要
LLaMA 3.3 70B 是一款最先進的語言模型,具有令人印象深刻的能力。
微調可以針對特定任務自訂 LLaMA 3.3 70B,提升準確性和相關性。
雖然 RTX 4090 是一款強大的 GPU,但其記憶體限制使得微調 LLaMA 3.3 70B 極具挑戰性。
參數高效微調(PEFT)方法(如 LoRA 和 QLoRA)有助於緩解這些挑戰。
雲端 GPU 實例為微調 LLaMA 3.3 70B 這類大型模型提供了可行的替代方案。您可以使用 Novita AI 的 GPU 實例——註冊後可獲得容器磁碟 60GB 免費空間及卷磁碟 1GB 免費空間,若超過免費限制將產生額外費用。
大型語言模型(LLM)如 LLaMA 3.3 70B 在自然語言處理方面展現了驚人的潛力。然而,為了充分發揮其在特定應用中的能力,往往需要進行微調。本文探討使用 NVIDIA RTX 4090 在本機微調 LLaMA 3.3 70B 的可行性、所涉及的挑戰,並提出替代解決方案,包括雲端 GPU 實例。
認識 LLaMA 3.3 70B
模型架構與規模
LLaMA 3.3 70B 是由 Meta 開發的大型語言模型,基於 Transformer 架構。它在超過 15 兆個 token 的龐大數據集上進行預訓練,使其能夠理解並生成類似人類的文字。模型的架構由多層注意力頭組成,這些注意力頭學習詞語之間的關係,從而產生連貫且符合上下文的輸出。
應用場景
LLaMA 3.3 70B 可應用於多種場景,包括:
- 客戶支援
- 內容生成
- 專業領域(如醫療和法律)
- 程式碼生成
透過微調擴展應用
雖然預訓練的 LLM 用途廣泛,但透過微調可以使其專門處理特定任務或領域。這個適應過程能提升其在特定應用中的效能和相關性。
例如:公司利用 Llama 3.3 建立先進的聊天機器人,能夠即時理解並回覆客戶詢問。這些聊天機器人經過微調,可辨識特定意圖並提供準確、符合上下文的回應,從而提升客戶滿意度並減少人工干預的需求。
什麼是微調?
微調的好處
微調涉及為特定任務或數據集自訂預訓練的 LLM,使模型能夠:
- 提升準確性和相關性,透過專注於特定任務。
- 減少偏差 並修正錯誤。
- 最佳化資源使用,因為它建立在既有知識之上,無需從頭開始。
- 用較小的微調模型獲得比大型基礎模型更好的效能。
- 減少提示工程的負擔。
微調模型的應用
微調後的 LLM 可應用於多種情境:
- 文字摘要
- 文字生成
- 二元或文字分類
- 程式碼生成
- 聊天機器人
微調如何運作?
微調透過以下技術調整預訓練模型的參數,使其更適合特定任務:
- 自監督學習: 在精選文字語料庫上訓練模型。
- 監督式學習: 使用輸入-輸出配對進行訓練。
- 強化學習: 訓練獎勵模型以改善輸出品質。
- 參數高效微調(PEFT): 凍結大部分模型參數,僅更新少量額外參數。
https://www.youtube.com/watch?v=9PcV6FCv9eQ
微調 LLaMA 3 需要什麼?
GPU 的記憶體需求
微調 LLaMA 3.3 70B 這類大型模型需要大量 GPU 記憶體。基礎模型約佔用 141 GB 的 GPU RAM,而量化版本約需 40 GB。即使使用量化,微調仍會消耗大量記憶體。
成本考量
全參數微調耗費資源且耗時,需要大量的 GPU 資源和較長的完成時間。使用 80 GB 的 GPU 更具成本效益,因為它可以支援更大的批次大小,從而加速微調過程。
個人數據集需求
高品質的數據集對於成功的微調至關重要。數據集必須:
- 與任務相關
- 夠大 以提升效能
- 多樣化 以避免過度擬合
- 格式正確,包含指令、輸入和輸出
RTX 4090 是否適合在本機微調 LLaMA 3.3 70B?
答案:不一定適合
雖然 RTX 4090 是一款擁有 24 GB VRAM 的強大 GPU,但由於其記憶體限制,可能不足以進行 LLaMA 3.3 70B 的全參數微調。當模型超過可用 VRAM 時,效能會顯著下降;因此,儘管 RTX 4090 可能適用於推論(尤其是使用量化模型),但微調需要更多記憶體。
如何利用其他技術解決問題
為了解決 RTX 4090 的記憶體限制,可以採用參數高效微調(PEFT)技術,包括:
- LoRA(低秩適應): 以量化權重將模型載入 GPU。
- QLoRA(量化 LoRA): 以進一步量化的權重將模型載入 GPU。
- 半二次量化(HQQ): 另一種低精度量化方法。
這些方法凍結預訓練模型的權重,同時允許在頂層微調一個適配器。然而,使用 bitsandbytes 進行量化可能比其他方法產生較不準確的結果;因此建議將某些關鍵模組提升為 float32 以獲得更好的效能。
使用替代技術的挑戰
雖然 PEFT 方法降低了資源需求,但它們也存在限制:
- 微調後的適配器無法合併回量化模型。
- 反量化與合併可能顯著降低效能。
- 使用較低位元深度 HQQ 的模型可能無法與未量化但效能更好的較小模型競爭。
- 使用僅有 48 GB VRAM 的 GPU 進行微調是可行的,但僅限於批次大小為 1 且序列極短的情況。
替代解決方案 – 雲端 GPU
為什麼選擇雲端 GPU 實例?
雲端 GPU 實例是本地微調的可行替代方案,尤其適合 LLaMA 3.3 70B 這類大型模型。它們提供:
- 根據工作負載需求可擴展的 GPU 資源
- 使用高效能 GPU,如 NVIDIA A100 或 V100
- 具成本效益的按需付費定價模式
- 簡化的部署工作流程
- 繞過本地硬體限制的能力
Novita AI GPU 實例服務
與其他 GPU 雲端相比,我們的價格具有最大優勢。以下表格供您參考:
| 服務提供商 | RTX 4090 價格(每小時 1x GPU) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | 無服務 |
部署步驟與使用指南
步驟 1: 點擊 GPU 實例
如果您是新訂閱者,請先註冊我們的帳號。然後點擊我們網頁上的 [GPU 實例](https://novita.ai/gpus/?utm_source=blogs_gpu&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) 按鈕。
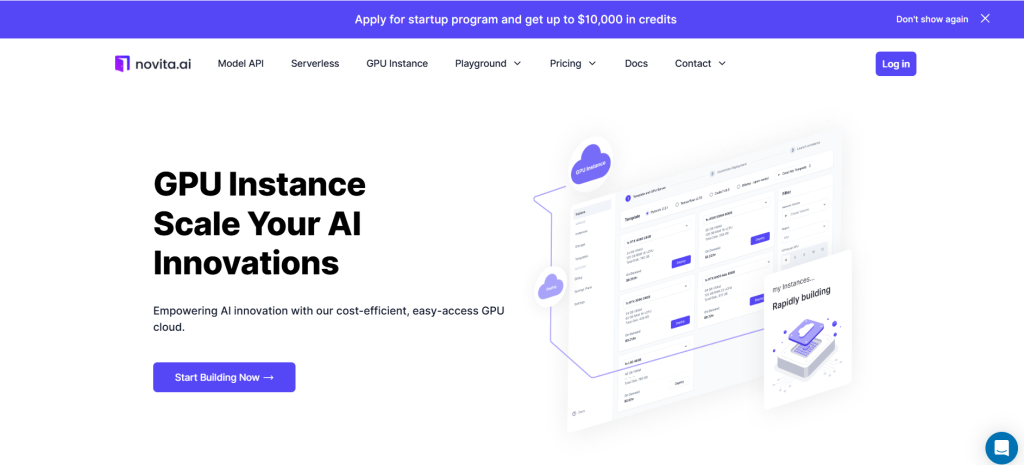
步驟 2: 範本與 GPU 伺服器
您可以根據特定需求選擇自己的範本,包括 Pytorch、Tensorflow、Cuda、Ollama。此外,您也可以點擊最下方的按鈕建立自己的範本資料。
接著,我們的服務提供高效能 GPU 的存取,例如 NVIDIA RTX 4090,每個 GPU 都配備充足的 VRAM 和 RAM,確保即使是最嚴苛的 AI 模型也能高效訓練。您可以根據需求選擇。
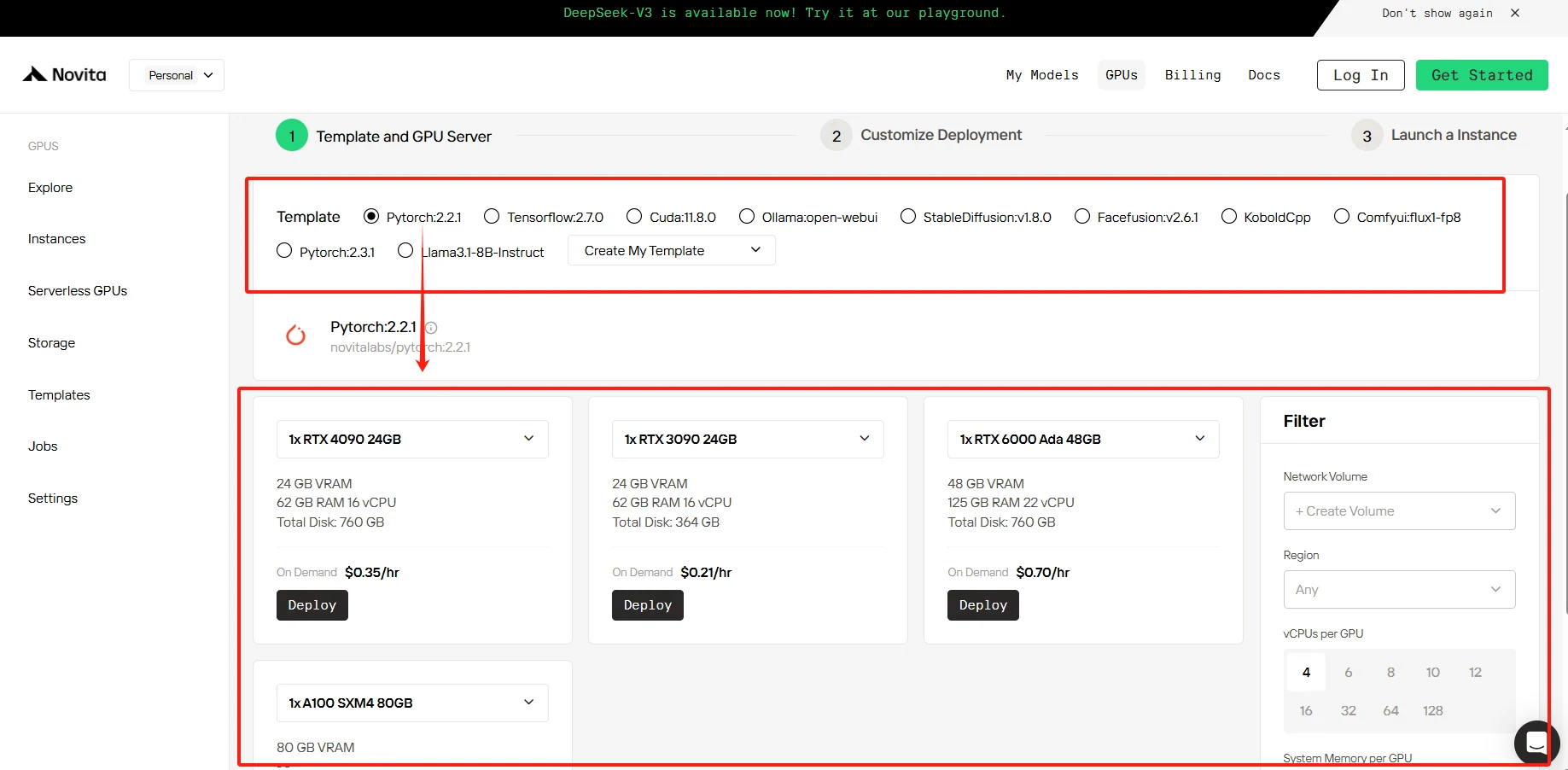
步驟 3: 自訂部署
在此部分,您可以根據自身需求自訂這些資料。容器磁碟有 60GB 免費空間,卷磁碟有 1GB 免費空間,若超過免費限制將產生額外費用。
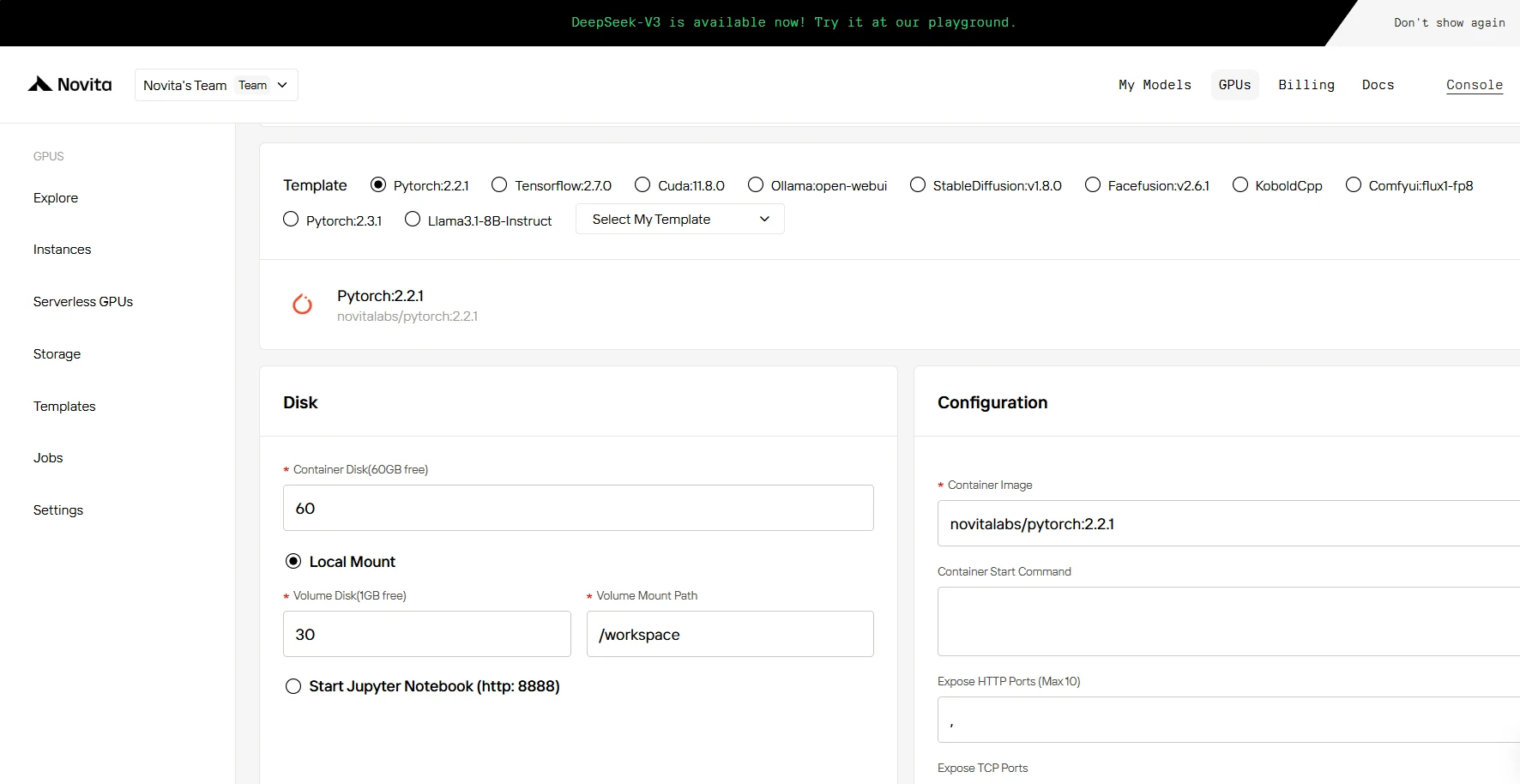
步驟 4: 啟動 ** 一個 ** 實例
無論是用於研究、開發或部署 AI 應用程式,配備 CUDA 12 的 Novita AI GPU 實例都能在雲端提供強大且高效的 GPU 運算體驗。
微調 LLaMA 3.3 70B:比較本地與雲端方案
本地微調:優點與缺點
| 優點 | 缺點 |
|---|---|
| 完全掌控硬體與資料 | 由於記憶體限制和處理能力有限,訓練時間較長 |
| 無需依賴網路連線 | 設定可能較為困難,需要比雲端方案更高的技術能力 |
| 對於小型微調任務可能成本較低 |
雲端微調:優點與缺點
| 優點 | 缺點 |
|---|---|
| 可擴展的資源,適用於大型模型和數據集 | 根據使用情況可能成本較高 |
| 透過存取強大 GPU 獲得更快的訓練時間 | |
| 簡化的部署和更易於管理 | |
| 能夠使用多個 GPU 進行分散式訓練 |
結論
微調 LLaMA 3.3 70B 可以顯著增強其在特定應用中的能力。雖然 RTX 4090 適用於推論以及使用 PEFT 技術進行有限的微調,但其記憶體限制使其不太適合對此類大型模型進行全面微調。雲端 GPU 實例(如 Novita AI 提供的服務)提供了可擴展的資源和簡化的部署選項,能夠有效滿足這些需求。最終,選擇本地或雲端方案將取決於具體需求、可用資源和技術專業知識。
常見問題
Llama 3.3 70B 的大小是多少 GB?
Llama 3.3 70B 模型的大小約為 40–42 GB,具體取決於量化程度和下載的特定版本;最常見的報告約為 42 GB。
Llama 3.3 70B 的 token 限制是多少?
因此,提示的最大 token 限制為 130K,而非 8196。然而,如果您使用非常長的提示輸入,將會消耗更多 GPU 記憶體。
[Novita AI](https://novita.ai/?utm_source=blog_GPU&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) 是一個 AI 雲端平台,為開發人員提供透過簡單 API 部署 AI 模型的簡易方式,同時也提供價格實惠且可靠的 GPU 雲端,用於建立和擴展應用程式。



