

- Quais Problemas de Codificação as Pessoas Usam Modelos de IA para Resolver?
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Desempenho de Código
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Arquitetura
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Benchmarks
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Eficiência
- Como Acessar o GLM 4.6 ou o Qwen3-Coder-480B-A35B-Instruct para suas Tarefas de Codificação?
Desenvolvedores modernos enfrentam desafios crescentes na geração de código, depuração e manutenção de bases de código em larga escala. Ferramentas tradicionais não conseguem lidar de forma eficiente com raciocínio de longo contexto ou se integrar a fluxos de trabalho complexos. Modelos de codificação com IA, como GLM-4.6 e Qwen3-Coder-480B-A35B-Instruct, foram criados para resolver essas lacunas. Este artigo compara suas arquiteturas, benchmarks e eficiência de inferência para mostrar como cada modelo resolve problemas de codificação do mundo real — desde prototipagem rápida até análise profunda de repositórios — e orienta os desenvolvedores a escolher o modelo e a configuração certos para suas tarefas de codificação específicas.
Quais Problemas de Codificação as Pessoas Usam Modelos de IA para Resolver?
Modelos de codificação com IA ajudam principalmente os desenvolvedores a gerar e operar código. Eles ou criam novos arquivos e módulos a partir de instruções em linguagem natural, ou leem repositórios existentes para modificar, refatorar ou chamar dados e APIs externos. O primeiro tipo acelera a prototipagem e a automação no estilo de agente; o segundo melhora a compreensão e a reutilização de bases de código grandes e complexas.
| Tipo | Geração Baseada em Instruções / Agente | Raciocínio Baseado em Repositório / Chamada de Dados |
|---|---|---|
| Entrada | Solicitação em linguagem natural, como “construa este recurso” | Código do projeto, arquivos de repositório, APIs, fontes de dados |
| Foco | Cria novo conteúdo (módulos, arquivos, interfaces) | Compreende o código existente e o expande |
| Automação | Alta automação (fluxos de trabalho no estilo de agente) | Análise complexa com integração de contexto |
| Usos Típicos | Prototipagem rápida, geração de UI, scripts de configuração | Refatoração, atualizações de repositórios grandes, recursos orientados a dados |
| Riscos | Qualidade da saída, consistência de estilo, erros de estrutura | Compreensão fraca de contexto, incompatibilidade de dados, bugs de API |
Esses dois padrões servem de base para a próxima seção, que comparará o GLM 4.6 e o Qwen3-Coder-480B-A35B-Instruct em seu desempenho de codificação.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Desempenho de Código
Você pode usar diretamente o Novita AI no Hugging Face na interface do site para iniciar um teste gratuito e rápido!
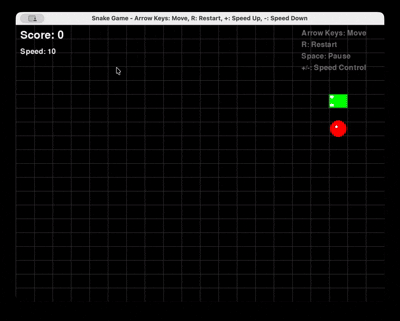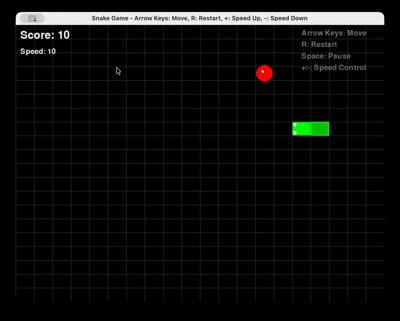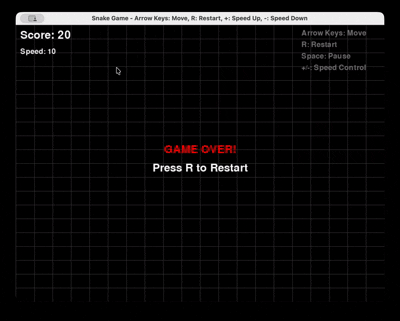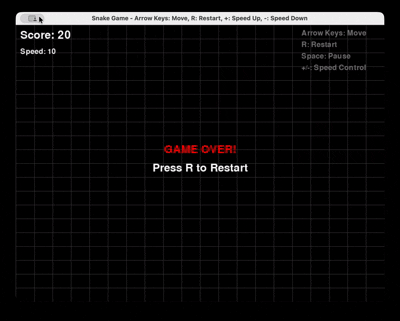
Prompt: “Gere um jogo da Cobra completo em Python usando Pygame, com reinicialização e controle de velocidade.”

Qwen 3 Coder
GLM 4.6
Prompt: “Leia todos os arquivos .py neste repositório e explique o propósito e as funções principais de cada arquivo em uma lista Markdown concisa.”https://github.com/pallets/flask/tree/main/examples/tutorial
| Aspecto | Qwen3-Coder-480B-A35B | GLM 4.6 |
|---|---|---|
| Cobertura | Muito abrangente; lista todos os arquivos, modelos e testes com propósito e funções detalhados. | Focado nos componentes principais apenas; omite modelos menores e arquivos extras. |
| Estrutura | Hierárquica e exaustiva, terminando com padrões arquiteturais e princípios de design. | Concisa e modular, agrupando arquivos por funcionalidade (auth, blog, testes). |
| Profundidade de Compreensão | Demonstra compreensão profunda do repositório e raciocínio de longo contexto. | Mostra resumo eficiente e condensação de informações. |
| Legibilidade | Densa e longa; mais adequada para leitores especializados ou documentação técnica. | Mais fácil de ler; adequada para iniciantes ou resumos de referência rápida. |
| Adequação ao Caso de Uso | Ideal para avaliar a compreensão de código e a profundidade de raciocínio em modelos de grande contexto. | Ideal para testar a qualidade do resumo e a clareza com saídas limitadas. |
| Força Destacada | Acompanhamento de longo contexto, raciocínio estrutural e cobertura abrangente. | Precisão, brevidade e clareza ao resumir a lógica principal. |
| Melhor Demonstra | Análise de repositórios e capacidades de explicação detalhada. | Habilidades de resumo e redação técnica concisa. |
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Arquitetura
O GLM-4.6 é um modelo MoE com 355 bilhões de parâmetros, 32 bilhões de parâmetros ativos e uma janela de contexto de 200 mil tokens.
- Parâmetros totais: ~ 355 bilhões, parâmetros ativos ~ 32 bilhões.
- Arquitetura do modelo: Mixture-of-Experts (MoE) herdada da série GLM-4.x.
- Janela de contexto: nativa de 200 mil tokens, saída máxima de ~128 mil tokens.
- Principais melhorias em relação ao seu antecessor (GLM-4.5) incluem comprimento de contexto maior, desempenho de codificação aprimorado e melhor integração com ferramentas.
O Qwen3-Coder-480B-A35B é um modelo MoE com 480 bilhões de parâmetros, 35 bilhões de parâmetros ativos e suporta contexto de até 1 milhão de tokens.
- Parâmetros totais: ~ 480 bilhões; parâmetros ativos ~ 35 bilhões.
- Janela de contexto: suporte nativo a ~256 mil tokens, escalonável por extrapolação para ~1 milhão de tokens.
- Arquitetura: Mixture-of-Experts com muitos especialistas (ex: 160 especialistas com 8 ativos) de acordo com a ficha do modelo.
- Criado especificamente para tarefas de codificação autônomas (geração de código multissetorial, invocação de ferramentas).
O GLM-4.6 é otimizado para desempenho de codificação e integração com ferramentas, sendo adequado para codificação rápida, depuração e colaboração com múltiplas ferramentas. Por outro lado, o Qwen3-Coder-480B-A35B-Instruct é mais adequado para compreensão de bases de código em larga escala, raciocínio com documentos longos e tarefas de refatoração entre arquivos que exigem contexto ultra longo e processamento lógico complexo.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Benchmarks
| Benchmark | GLM-4.6 | Qwen3-Coder-480B-A35B-Instruct |
|---|---|---|
| SWE-bench Verified | 68,0 % | 69,6 % (OpenHands 500 turnos) |
| Terminal-Bench | 40,5 % | 37,5 % |
| LiveCodeBench v6 | 84,5 % (com ferramentas) | – |
| HLE | 30,4 % (com ferramentas) | – |
| Aider-Polyglot | – | 61,8 % |
| SWE-bench Multilingual | – | 54,7 % |
| WebArena / Mind2Web | ~45–50 % (intervalo) | 49,9 / 55,8 % |
- O GLM-4.6 tem desempenho ligeiramente inferior no SWE-bench, mas lidera no LiveCodeBench e em benchmarks integrados com ferramentas, demonstrando maturidade em fluxos de trabalho de codificação assistida.
- O Qwen3-Coder-480B obtém maior consistência em tarefas multilíngues e multissetoriais autônomas, implicando melhor robustez em codificação complexa e de longa duração.
- Ambos são próximos em correção de código puro, mas o GLM-4.6 vence em responsividade em tempo real; o Qwen3-Coder vence em raciocínio sustentado.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Eficiência
O GLM-4.6 gera mais saídas e executa mais rápido, mas custa mais no geral; o Qwen3-Coder-480B é mais lento, mas mais barato por execução, com custo de raciocínio menor.
1. Volume de Saída
- GLM-4.6: 86 milhões de tokens de saída
- Qwen3-Coder-480B: 9,7 milhões de tokens de saída
O GLM-4.6 produz cerca de nove vezes mais tokens de saída.
2. Velocidade de Geração
- GLM-4.6: 82 tokens por segundo
- Qwen3-Coder-480B: 41 tokens por segundo
O GLM-4.6 gera respostas aproximadamente duas vezes mais rápido.
3. Custo Total
- GLM-4.6: $221 por execução de benchmark
- Qwen3-Coder-480B: $165 por execução de benchmark
O GLM-4.6 é cerca de 34% mais caro no geral.
4. Custo de Raciocínio
- GLM-4.6: maior uso de tokens de raciocínio → custo de raciocínio maior
- Qwen3-Coder-480B: menos tokens de raciocínio → custo de raciocínio menor
O GLM-4.6 “fala mais” durante o raciocínio; o Qwen3 é mais conciso e econômico.
5. Requisitos de Hardware
| Modelo | Parâmetros Ativos | Configuração Recomendada | Perfil de Eficiência |
|---|---|---|---|
| GLM-4.6 | 32B | 8× A100 80 GB ou 4× H100 48 GB | VRAM baixa, inferência rápida |
| Qwen3-Coder-480B | 35B | 8–16× H100 80 GB | VRAM alta, otimizado para execuções de longo contexto |
- GLM-4.6: Maior saída, inferência mais rápida, mas também o mais caro e com maior carga de raciocínio.
- Qwen3-Coder-480B: Velocidade e saída menores, porém mais econômico com sobrecarga de raciocínio reduzida.
O GLM-4.6 se adapta a tarefas de codificação interativas e de alta velocidade; o Qwen3-Coder se adapta a inferência de longo contexto ou em lote em larga escala.
Como Acessar o GLM 4.6 ou o Qwen3-Coder-480B-A35B-Instruct para suas Tarefas de Codificação?
O site oficial usa atualmente um modelo de assinatura mensal. Se você só quer usá-lo de forma prática, em vez de pagar por tempo não utilizado, pode experimentar o Novita AI, que oferece preços mais baixos e serviços de suporte altamente estáveis.
O Novita AI oferece APIs do Qwen3-Coder com janela de contexto de 262 mil tokens a $0,29 por entrada e $1,2 por saída. Também fornece APIs do GLM-4.6V com janela de contexto de 208 mil tokens a $0,60 por entrada e $2,20 por saída, com suporte a saídas estruturadas e chamada de funções.
Ao usar o serviço do Novita AI, você pode contornar as restrições regionais do Claude Code. O Novita também oferece garantias de SLA com 99% de estabilidade do serviço, tornando-o especialmente adequado para cenários de alta frequência, como geração de código e testes automatizados. O Novita AI também fornece guias de acesso para o Trae e o Qwen Code, que podem ser encontrados nos artigos a seguir.
Primeiro: Obtenha a Chave de API (Usando o GLM-4.6 como Exemplo)
Passo 1: Faça login na sua conta e clique no botão da Biblioteca de Modelos.
GLM-4.6 no Cursor
Passo 1: Instale e Ative o Cursor
- Baixe a versão mais recente do Cursor IDE em cursor.com
- Assine o plano Pro para habilitar os recursos baseados em API
- Abra o aplicativo e conclua a configuração inicial
Passo 2: Acesse as Configurações Avançadas de Modelo
- Abra as Configurações do Cursor (use Ctrl + F para encontrá-las rapidamente)
- Vá para a aba “Modelos” no menu à esquerda
- Encontre a seção “Configuração de API”
Passo 3: Configure a Integração com o Novita AI
- Expanda a seção “Chaves de API”
- ✅ Ative a alternância “Chave de API do OpenAI”
- ✅ Ative a alternância “Substituir URL Base do OpenAI”
- No campo “Chave de API do OpenAI”: Cole sua chave de API do Novita AI
- No campo “Substituir URL Base do OpenAI”: Substitua o padrão por:
https://api.novita.ai/openai
Passo 4: Adicione Vários Modelos de Codificação com IA
Clique em “+ Adicionar Modelo Personalizado” e adicione cada modelo:
qwen/qwen3-coder-480b-a35b-instructzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Passo 5: Teste Sua Integração
- Inicie um novo chat no Modo Pergunta ou Modo Agente
- Teste diferentes modelos para várias tarefas de codificação
- Verifique se todos os modelos respondem corretamente
GLM-4.6 no Claude Code
Para Windows
Abra o Prompt de Comando e defina as seguintes variáveis de ambiente:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Novita API Key>
set ANTHROPIC_MODEL=moonshotai/glm-4.6
set ANTHROPIC_SMALL_FAST_MODEL=moonshotai/glm-4.6
Substitua <[chave de API do Novita](https://novita.ai/settings/key-management)> pela sua chave de API real obtida na plataforma Novita AI. Essas variáveis permanecem ativas para a sessão atual e devem ser redefinidas se você fechar o Prompt de Comando.
Para Mac e Linux
Abra o Terminal e exporte as seguintes variáveis de ambiente:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
export ANTHROPIC_MODEL="moonshotai/glm-4.6"
export ANTHROPIC_SMALL_FAST_MODEL="moonshotai/glm-4.6"
Iniciando o Claude Code
Com a instalação e a configuração concluídas, você agora pode iniciar o Claude Code no diretório do seu projeto. Navegue até o local do projeto desejado usando o comando cd:
cd <your-project-directory>
claude .
GLM-4.6 no Trae
Passo 1: Abra o Trae e Acesse os Modelos
Inicie o aplicativo Trae. Clique na Alternância da Barra Lateral de IA no canto superior direito para abrir a Barra Lateral de IA. Em seguida, vá para o Gerenciamento de IA e selecione Modelos.

Passo 2: Adicione um Modelo Personalizado e Escolha o Novita como Provedor
Clique no botão Adicionar Modelo para criar uma entrada de modelo personalizado. Na caixa de diálogo de adição de modelo, selecione Provedor = Novita no menu suspenso.


Passo 3: Selecione ou Insira o Modelo
No menu suspenso Modelo, escolha o modelo desejado (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324, ou MiniMax-M1-80k, GLM 4.6). Se o modelo exato não estiver listado, basta digitar o ID do modelo que você anotou da biblioteca Novita. Certifique-se de escolher a variante correta do modelo que deseja usar.
GLM 4.6 no Codex
Configurar Arquivo de Configuração
O Codex CLI usa um arquivo de configuração TOML localizado em:
- macOS/Linux:
~/.codex/config.toml - Windows:
%USERPROFILE%\.codex\config.toml
Modelo de Configuração Básica
model = "glm-4.6"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer YOUR_NOVITA_API_KEY"}
wire_api = "chat"
Iniciar o Codex CLI
codex
Exemplos de Uso Básico
Geração de Código:
> Create a Python class for handling REST API responses with error handling
Análise de Projeto:
> Review this codebase and suggest improvements for performance
Correção de Bugs:
> Fix the authentication error in the login function
Testes:
> Generate comprehensive unit tests for the user service module
Para resolver tarefas de codificação, o GLM-4.6 se destaca no desenvolvimento rápido e interativo, depuração automatizada e geração de código baseada em ferramentas. Sua maior velocidade e responsividade o tornam ideal para desenvolvedores que iteram rapidamente. O Qwen3-Coder-480B-A35B-Instruct se concentra no raciocínio em repositórios grandes, compreensão de longo contexto e refatoração estruturada, permitindo que ele lide com tarefas de código complexas e entre arquivos. Juntos, eles demonstram como a IA pode acelerar o desenvolvimento de software — o GLM-4.6 priorizando velocidade e precisão, e o Qwen3-Coder enfatizando escala e profundidade de raciocínio.
Perguntas Frequentes
Como o GLM-4.6 ajuda a resolver tarefas de codificação reais?
O GLM-4.6 pode gerar, depurar e refatorar código de forma interativa usando linguagem natural. Ele é otimizado para contextos de código curtos a médios, ajudando os desenvolvedores a testar, corrigir e lançar recursos rapidamente dentro de IDEs como Cursor ou Claude Code.
Quando o Qwen3-Coder-480B-A35B-Instruct é uma escolha melhor?
Use o Qwen3-Coder-480B-A35B-Instruct para problemas de codificação em larga escala ou em nível de repositório. Seu contexto estendido de 1 milhão de tokens permite raciocínio profundo em vários arquivos, sendo ideal para analisar arquitetura, rastrear dependências ou refatorar sistemas complexos.
Qual modelo executa tarefas de codificação mais rápido?
O GLM-4.6 gera cerca de 82 tokens por segundo, aproximadamente duas vezes mais rápido que o Qwen3-Coder-480B-A35B-Instruct, tornando-o melhor para fluxos de trabalho de desenvolvimento iterativos e sensíveis ao tempo.
O Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



