

- Quels problèmes de codage les gens résolvent-ils avec des modèles IA ?
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Performances de codage
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Architecture
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Benchmarks
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Efficacité
- Comment accéder à GLM 4.6 ou à Qwen3-Coder-480B-A35B-Instruct pour vos tâches de codage ?
Les développeurs modernes font face à des défis croissants en matière de génération de code, de débogage et de maintenance de bases de code à grande échelle. Les outils traditionnels ne peuvent pas gérer efficacement le raisonnement sur des contextes longs ou s’intégrer à des flux de travail complexes. Les modèles de codage IA tels que GLM-4.6 et Qwen3-Coder-480B-A35B-Instruct sont conçus pour combler ces lacunes. Cet article compare leurs architectures, leurs benchmarks et leur efficacité d’inférence pour montrer comment chaque modèle résout des problèmes de codage concrets — du prototypage rapide à l’analyse approfondie de dépôts — et guide les développeurs dans le choix du modèle et de la configuration adaptés à leurs tâches de codage spécifiques.
Quels problèmes de codage les gens résolvent-ils avec des modèles IA ?
Les modèles de codage IA aident principalement les développeurs à générer et à manipuler du code. Ils créent soit de nouveaux fichiers et modules à partir d’instructions en langage naturel, soit lisent des dépôts existants pour les modifier, les refactoriser ou appeler des données et API externes. Le premier type accélère le prototypage et l’automatisation de type agent ; le second améliore la compréhension et la réutilisation de bases de code complexes et de grande taille.
| Type | Génération / Agent basé sur des instructions | Raisonnement sur dépôt / Appel de données |
|---|---|---|
| Entrée | Demande en langage naturel comme « construire cette fonctionnalité » | Code du projet, fichiers du dépôt, API, sources de données |
| Focus | Crée du nouveau contenu (modules, fichiers, interfaces) | Comprend le code existant et l’étend |
| Automatisation | Automatisation élevée (flux de travail de type agent) | Analyse complexe avec intégration de contexte |
| Utilisations typiques | Prototypage rapide, génération d’interface utilisateur, scripts d’installation | Refactorisation, mises à jour de grands dépôts, fonctionnalités pilotées par les données |
| Risques | Qualité de sortie, cohérence de style, erreurs de structure | Faible compréhension du contexte, incohérence des données, bugs d’API |
Ces deux modèles structurent la comparaison des performances de codage de GLM 4.6 et de Qwen3-Coder-480B-A35B-Instruct dans la section suivante.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Performances de codage
Vous pouvez utiliser directement Novita AI sur Hugging Face dans l’interface utilisateur du site pour commencer un essai gratuit et rapide !
Prompt : « Générer un jeu Snake complet en Python avec Pygame, avec redémarrage et contrôle de la vitesse. »

Qwen 3 Coder
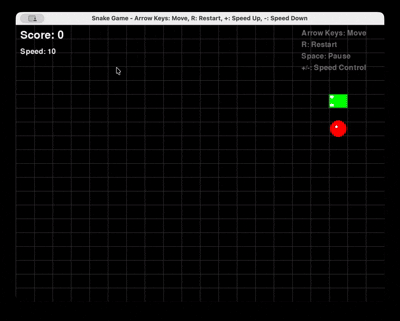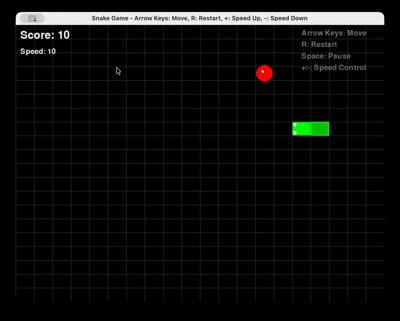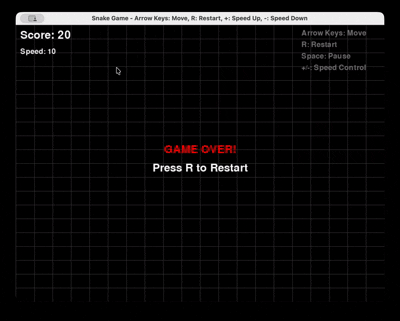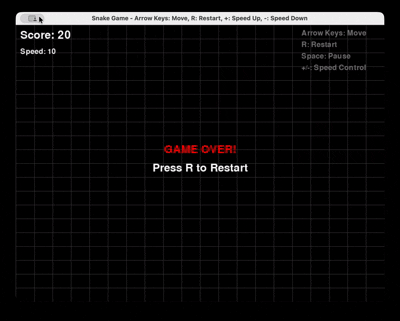
GLM 4.6
Prompt : « Lire tous les fichiers .py de ce dépôt et expliquer le rôle de chaque fichier et ses fonctions clés dans une liste Markdown concise. »https://github.com/pallets/flask/tree/main/examples/tutorial
| Aspect | Qwen3-Coder-480B-A35B | GLM 4.6 |
|---|---|---|
| Couverture | Très complète ; liste chaque fichier, modèle et test avec un rôle et des fonctions détaillés. | Se concentre sur les composants principaux uniquement ; omet les modèles mineurs et les fichiers supplémentaires. |
| Structure | Hiérarchique et exhaustive, se terminant par des patterns architecturaux et des principes de conception. | Concise et modulaire, regroupant les fichiers par fonctionnalité (authentification, blog, tests). |
| Profondeur de compréhension | Démontre une compréhension approfondie du dépôt et un raisonnement sur contexte long. | Montre une synthèse efficace et une condensation des informations. |
| Lisibilité | Dense et longue ; mieux adaptée aux lecteurs experts ou à la documentation technique. | Plus facile à lire ; adaptée aux débutants ou aux résumés de référence rapide. |
| Adéquation aux cas d’usage | Idéal pour évaluer la compréhension du code et la profondeur de raisonnement des modèles à contexte long. | Idéal pour tester la qualité de synthèse et la clarté sur des sorties contraintes. |
| Point fort mis en évidence | Suivi de contexte long, raisonnement structurel et couverture complète. | Précision, concision et clarté dans la synthèse de la logique clé. |
| Démontre le mieux | Capacités d’analyse de dépôt et d’explication détaillée. | Capacités de synthèse et d’écriture technique concise. |
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Architecture
GLM-4.6 est un modèle MoE de 355 milliards de paramètres avec 32 milliards de paramètres actifs et une fenêtre de contexte de 200 000 tokens.
- Nombre total de paramètres : ~ 355 milliards, paramètres actifs ~ 32 milliards.
- Architecture du modèle : Mélange d’experts (MoE) héritée de la série GLM-4.x.
- Fenêtre de contexte : 200 000 tokens natifs, sortie maximale ~ 128 000 tokens.
- Les améliorations clés par rapport à son prédécesseur (GLM-4.5) incluent une longueur de contexte plus importante, de meilleures performances de codage, une meilleure intégration d’outils.
Qwen3-Coder-480B-A35B est un modèle MoE de 480 milliards de paramètres avec 35 milliards de paramètres actifs et prend en charge jusqu’à 1 million de tokens de contexte.
- Nombre total de paramètres : ~ 480 milliards ; paramètres actifs ~ 35 milliards.
- Fenêtre de contexte : support natif de ~ 256 000 tokens, extensible par extrapolation à ~ 1 million de tokens.
- Architecture : Mélange d’experts avec de nombreux experts (par exemple, 160 experts avec 8 actifs) selon la fiche technique du modèle.
- Conçu spécifiquement pour les tâches de codage agentiques (génération de code multi-tours, invocation d’outils).
GLM-4.6 est optimisé pour les performances de codage et l’intégration d’outils, ce qui le rend bien adapté au codage rapide, au débogage et à la collaboration multi-outils. À l’inverse, Qwen3-Coder-480B-A35B-Instruct est mieux adapté à la compréhension de bases de code à grande échelle, au raisonnement sur des documents longs et aux tâches de refactorisation inter-fichiers qui nécessitent un contexte ultra-long et un traitement logique complexe.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Benchmarks
| Benchmark | GLM-4.6 | Qwen3-Coder-480B-A35B-Instruct |
|---|---|---|
| SWE-bench Vérifié | 68,0 % | 69,6 % (OpenHands 500 tours) |
| Terminal-Bench | 40,5 % | 37,5 % |
| LiveCodeBench v6 | 84,5 % (avec outils) | – |
| HLE | 30,4 % (avec outils) | – |
| Aider-Polyglot | – | 61,8 % |
| SWE-bench Multilingue | – | 54,7 % |
| WebArena / Mind2Web | ~45–50 % (plage) | 49,9 / 55,8 % |
- GLM-4.6 obtient des scores légèrement inférieurs sur SWE-bench mais devance sur LiveCodeBench et les benchmarks intégrant des outils, montrant sa maturité dans les flux de travail de codage assisté.
- Qwen3-Coder-480B obtient des résultats plus cohérents sur les tâches multilingues et agentiques multi-tours, ce qui implique une meilleure robustesse dans des sessions de codage complexes et longues.
- Les deux sont proches en termes de pure correction de code, mais GLM-4.6 l’emporte en réactivité en temps réel ; Qwen3-Coder l’emporte en raisonnement soutenu.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct : Efficacité
GLM-4.6 produit plus de sorties et s’exécute plus vite, mais coûte plus cher au global ; Qwen3-Coder-480B est plus lent mais moins cher par exécution, avec un coût de raisonnement plus faible.
1. Volume de sortie
- GLM-4.6 : 86 millions de tokens de sortie
- Qwen3-Coder-480B : 9,7 millions de tokens de sortie GLM-4.6 produit environ neuf fois plus de tokens de sortie.
2. Vitesse de génération
- GLM-4.6 : 82 tokens par seconde
- Qwen3-Coder-480B : 41 tokens par seconde GLM-4.6 génère des réponses environ deux fois plus vite.
3. Coût total
- GLM-4.6 : 221 $ par exécution de benchmark
- Qwen3-Coder-480B : 165 $ par exécution de benchmark GLM-4.6 est environ 34 % plus cher au global.
4. Coût de raisonnement
- GLM-4.6 : utilisation plus élevée de tokens de raisonnement → coût de raisonnement plus élevé
- Qwen3-Coder-480B : moins de tokens de raisonnement → coût de raisonnement plus faible GLM-4.6 « parle plus » pendant le raisonnement ; Qwen3 est plus concis et plus rentable.
5. Exigences matérielles
| Modèle | Paramètres actifs | Configuration recommandée | Profil d’efficacité |
|---|---|---|---|
| GLM-4.6 | 32B | 8× A100 80 Go ou 4× H100 48 Go | VRAM faible, inférence rapide |
| Qwen3-Coder-480B | 35B | 8–16× H100 80 Go | VRAM élevée, optimisé pour les exécutions sur contexte long |
- GLM-4.6 : Sortie la plus élevée, inférence la plus rapide, mais aussi le plus cher et le plus gourmand en raisonnement.
- Qwen3-Coder-480B : Vitesse et sortie plus faibles, mais plus rentable avec une charge de raisonnement réduite.
GLM-4.6 convient aux tâches de codage interactives et à haute vitesse ; Qwen3-Coder convient à l’inférence sur contexte long ou à grande échelle par lots.
Comment accéder à GLM 4.6 ou à Qwen3-Coder-480B-A35B-Instruct pour vos tâches de codage ?
Le site officiel utilise actuellement un modèle d’abonnement mensuel. Si vous souhaitez l’utiliser de manière pratique plutôt que de payer pour du temps inutilisé, vous pouvez essayer Novita AI, qui propose des prix plus bas et des services de support très stables.
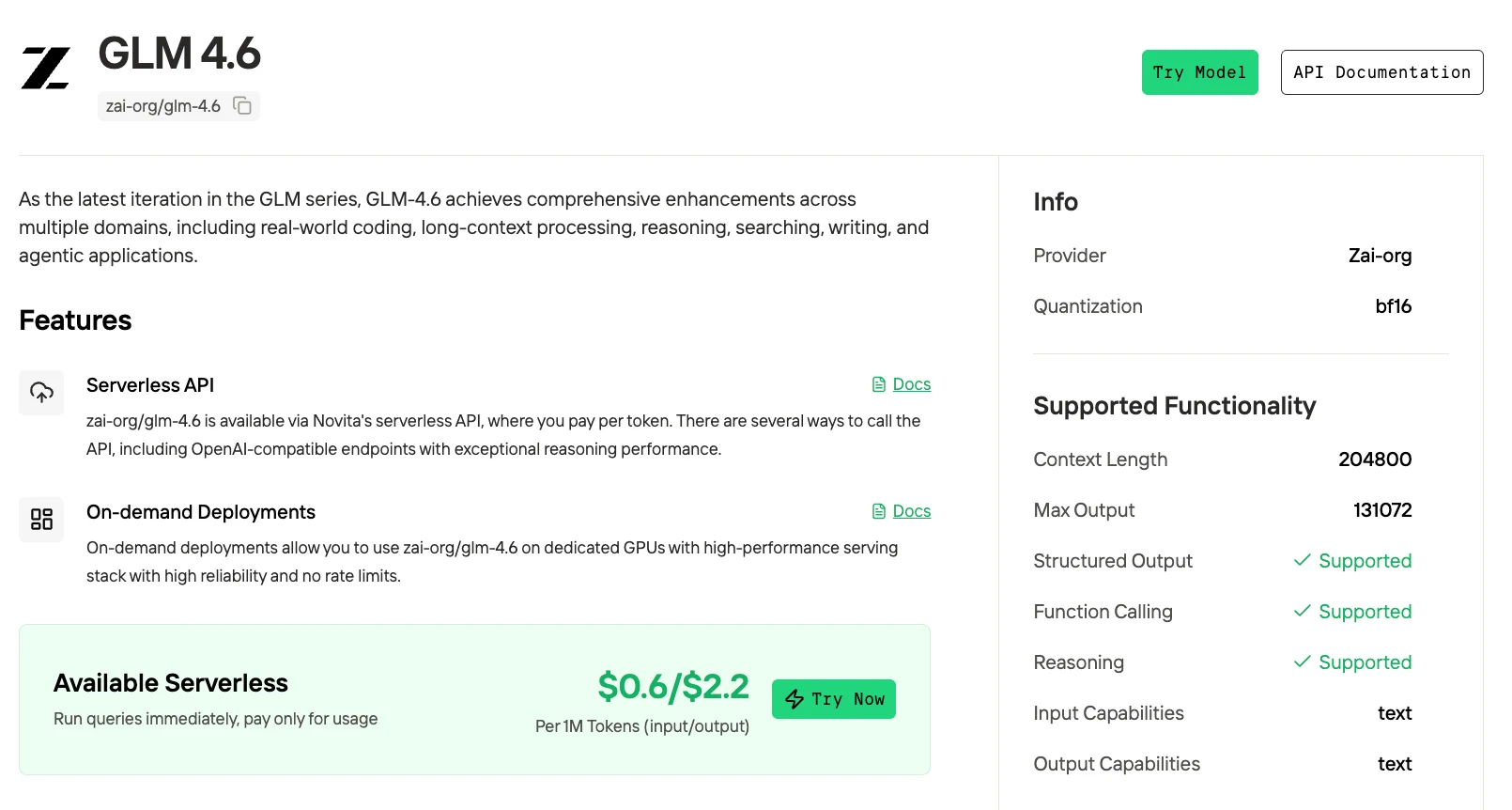
Novita AI propose des API Qwen3-Coder avec une fenêtre de contexte de 262K à 0,29 $ par entrée et 1,2 $ par sortie. Il propose également des API GLM-4.6V avec une fenêtre de contexte de 208K à 0,60 $ par entrée et 2,20 $ par sortie, prenant en charge les sorties structurées et l’appel de fonctions.
En utilisant le service de Novita AI, vous pouvez contourner les restrictions régionales de Claude Code. Novita propose également des garanties SLA avec 99 % de stabilité de service, ce qui le rend particulièrement adapté aux scénarios à haute fréquence tels que la génération de code et les tests automatisés. Novita AI propose également des guides d’accès pour Trae et Qwen Code, que vous pouvez trouver dans les articles suivants.
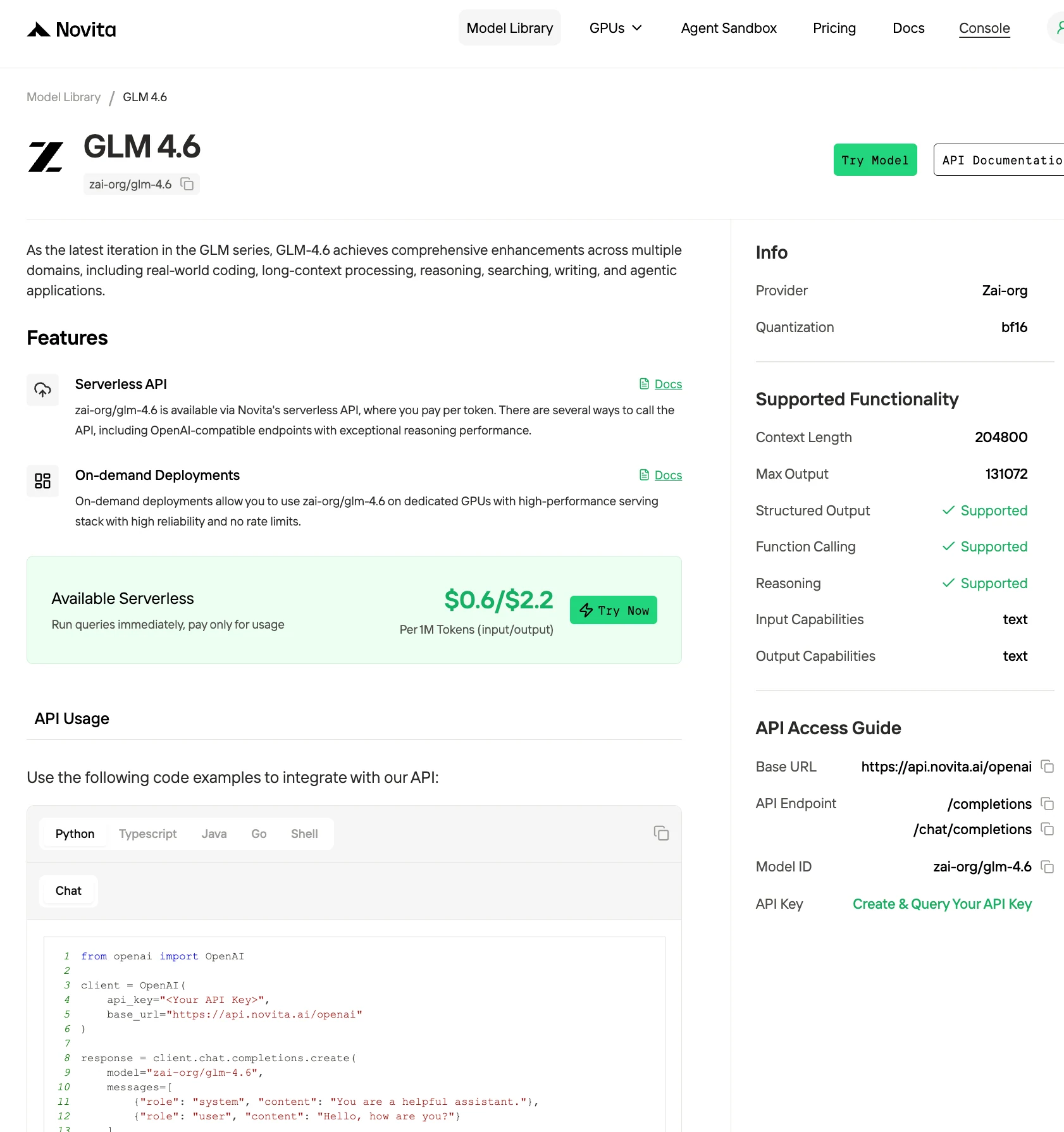
La première : obtenir une clé API (en utilisant GLM-4.6 comme exemple)
Étape 1 : Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.
GLM-4.6 dans Cursor
Étape 1 : Installer et activer Cursor
- Téléchargez la version la plus récente de l’IDE Cursor depuis cursor.com
- Abonnez-vous au plan Pro pour activer les fonctionnalités basées sur l’API
- Ouvrez l’application et terminez la configuration initiale
Étape 2 : Accéder aux paramètres avancés des modèles
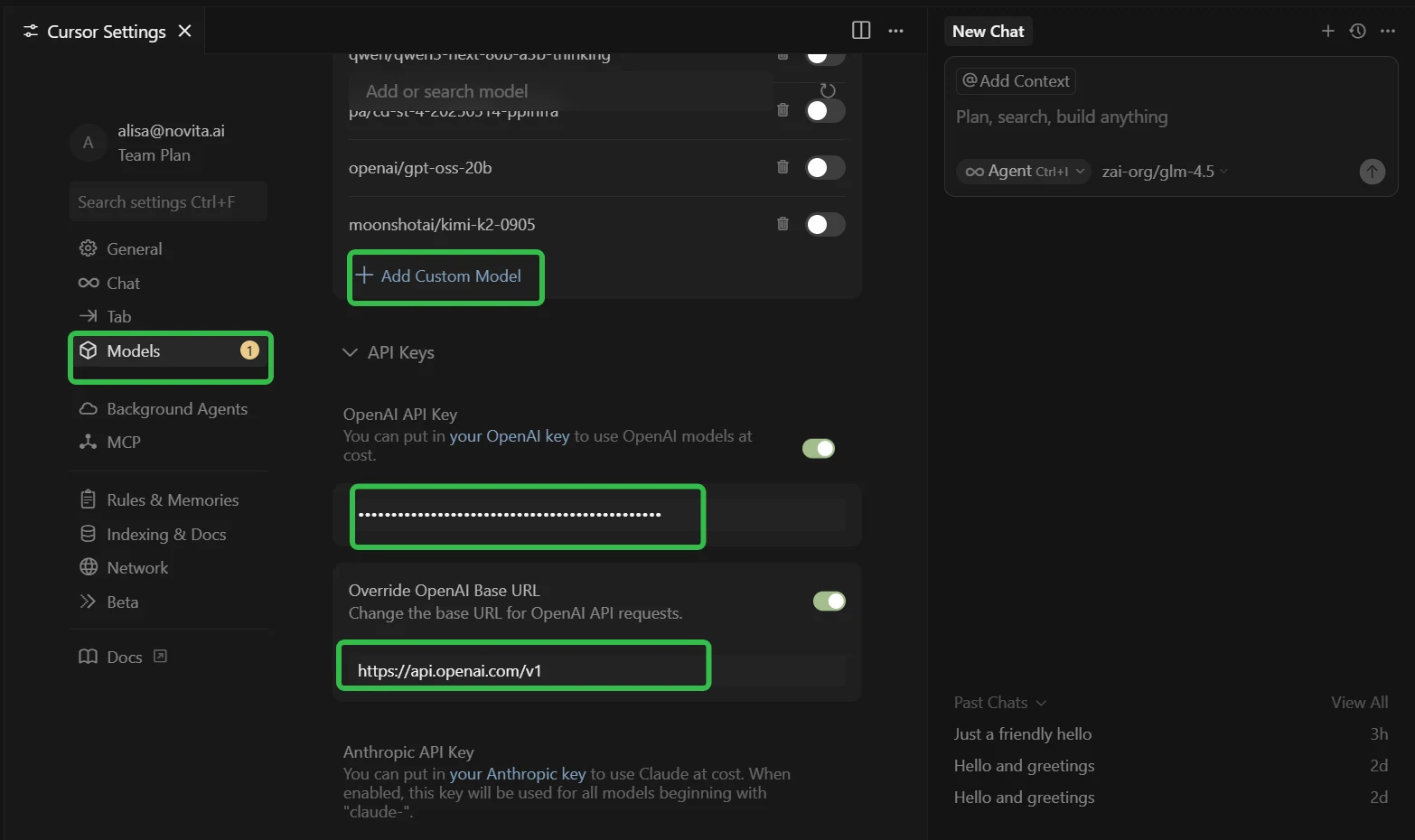
- Ouvrez les Paramètres Cursor (utilisez Ctrl + F pour le trouver rapidement)
- Allez dans l’onglet « Modèles » du menu de gauche
- Trouvez la section « Configuration API »
Étape 3 : Configurer l’intégration Novita AI
- Développez la section « Clés API »
- ✅ Activez l’option « Clé API OpenAI »
- ✅ Activez l’option « Remplacer l’URL de base OpenAI »
- Dans le champ « Clé API OpenAI » : Collez votre clé API Novita AI
- Dans le champ « Remplacer l’URL de base OpenAI » : Remplacez la valeur par défaut par :
https://api.novita.ai/openai
Étape 4 : Ajouter plusieurs modèles de codage IA
Cliquez sur « + Ajouter un modèle personnalisé » et ajoutez chaque modèle :
qwen/qwen3-coder-480b-a35b-instructzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Étape 5 : Tester votre intégration
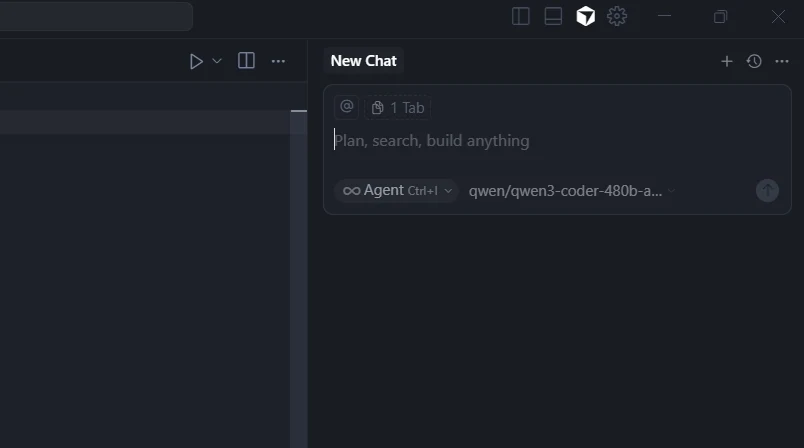
- Démarrez une nouvelle discussion en mode Demande ou en mode Agent
- Testez différents modèles pour diverses tâches de codage
- Vérifiez que tous les modèles répondent correctement
GLM-4.6 dans Claude Code
Pour Windows
Ouvrez l’invite de commandes et définissez les variables d’environnement suivantes :
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Clé API Novita>
set ANTHROPIC_MODEL=moonshotai/glm-4.6
set ANTHROPIC_SMALL_FAST_MODEL=moonshotai/glm-4.6
Remplacez <[Clé API Novita](https://novita.ai/settings/key-management)> par votre véritable clé API obtenue sur la plateforme Novita AI. Ces variables restent actives pour la session en cours et doivent être réinitialisées si vous fermez l’invite de commandes.
Pour Mac et Linux
Ouvrez le Terminal et exportez les variables d’environnement suivantes :
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Clé API Novita>"
export ANTHROPIC_MODEL="moonshotai/glm-4.6"
export ANTHROPIC_SMALL_FAST_MODEL="moonshotai/glm-4.6"
Démarrer Claude Code
Une fois l’installation et la configuration terminées, vous pouvez maintenant démarrer Claude Code dans le répertoire de votre projet. Accédez à l’emplacement de votre projet souhaité avec la commande cd :
cd <répertoire-de-votre-projet>
claude .
GLM-4.6 dans Trae
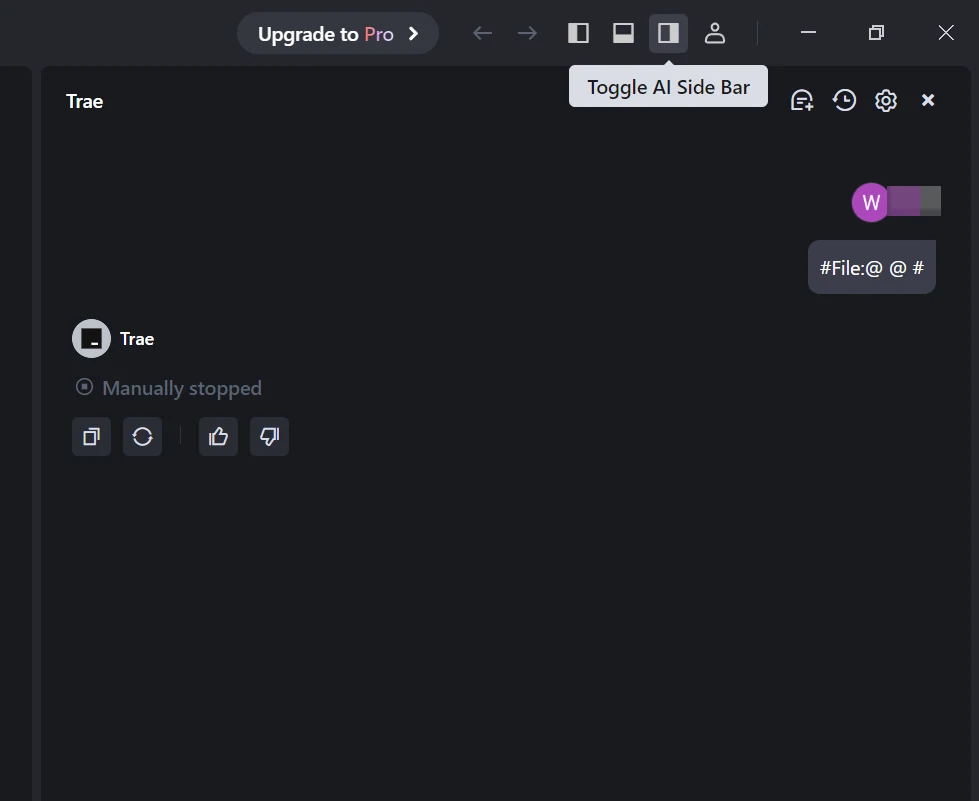
Étape 1 : Ouvrir Trae et accéder aux modèles
Lancez l’application Trae. Cliquez sur le bouton Basculer la barre latérale IA dans le coin supérieur droit pour ouvrir la barre latérale IA. Accédez ensuite à Gestion IA et sélectionnez Modèles.

Étape 2 : Ajouter un modèle personnalisé et choisir Novita comme fournisseur
Cliquez sur le bouton Ajouter un modèle pour créer une entrée de modèle personnalisé. Dans la boîte de dialogue d’ajout de modèle, sélectionnez Fournisseur = Novita dans le menu déroulant.


Étape 3 : Sélectionner ou saisir le modèle
Dans le menu déroulant Modèle, choisissez le modèle souhaité (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324, MiniMax-M1-80k ou GLM 4.6). Si le modèle exact n’est pas listé, saisissez simplement l’ID du modèle que vous avez noté dans la bibliothèque Novita. Assurez-vous de choisir la variante correcte du modèle que vous souhaitez utiliser.
GLM 4.6 dans Codex
Configuration du fichier de configuration
Codex CLI utilise un fichier de configuration TOML situé à :
- macOS/Linux :
~/.codex/config.toml - Windows :
%USERPROFILE%\.codex\config.toml
Modèle de configuration de base
model = "glm-4.6"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer YOUR_NOVITA_API_KEY"}
wire_api = "chat"
Lancer Codex CLI
codex
Exemples d’utilisation de base
Génération de code :
> Créer une classe Python pour gérer les réponses d'API REST avec gestion des erreurs
Analyse de projet :
> Examiner cette base de code et suggérer des améliorations de performance
Correction de bugs :
> Corriger l'erreur d'authentification dans la fonction de connexion
Tests :
> Générer des tests unitaires complets pour le module de service utilisateur
Pour résoudre des tâches de codage, GLM-4.6 excelle dans le développement interactif rapide, le débogage automatisé et la génération de code basée sur des outils. Sa vitesse et sa réactivité plus élevées en font un outil idéal pour les développeurs qui itèrent rapidement. Qwen3-Coder-480B-A35B-Instruct se concentre sur le raisonnement sur les grands dépôts, la compréhension de contexte long et la refactorisation structurée, lui permettant de gérer des tâches de codage complexes et inter-fichiers. Ensemble, ils démontrent comment l’IA peut accélérer le développement logiciel — GLM-4.6 privilégiant la vitesse et la précision, et Qwen3-Coder mettant l’accent sur l’échelle et la profondeur de raisonnement.
Foire aux questions
Comment GLM-4.6 aide-t-il à résoudre des tâches de codage concrètes ?
GLM-4.6 peut générer, déboguer et refactoriser du code de manière interactive en utilisant le langage naturel. Il est optimisé pour des contextes de code courts à moyens, aidant les développeurs à tester, corriger et publier des fonctionnalités rapidement dans des IDE comme Cursor ou Claude Code.
Quand Qwen3-Coder-480B-A35B-Instruct est-il un meilleur choix ?
Utilisez Qwen3-Coder-480B-A35B-Instruct pour des problèmes de codage à grande échelle ou au niveau du dépôt. Son contexte étendu de 1M de tokens permet un raisonnement approfondi sur plusieurs fichiers, idéal pour analyser l’architecture, tracer les dépendances ou refactoriser des systèmes complexes.
Quel modèle effectue les tâches de codage plus vite ?
GLM-4.6 génère environ 82 tokens par seconde, soit environ deux fois la vitesse de Qwen3-Coder-480B-A35B-Instruct, ce qui le rend meilleur pour les flux de travail de développement itératifs et sensibles au temps.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.



