

- ¿Qué Problemas de Codificación Resuelven las Personas con Modelos de IA?
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Rendimiento de Código
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Arquitectura
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Benchmark
- GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Eficiencia
- ¿Cómo Acceder a GLM 4.6 o Qwen3-Coder-480B-A35B-Instruct para tu Trabajo de Código?
Los desarrolladores modernos se enfrentan a desafíos crecientes en la generación de código, depuración y mantenimiento de bases de código a gran escala. Las herramientas tradicionales no pueden manejar eficientemente el razonamiento de contexto largo ni integrarse con flujos de trabajo complejos. Modelos de IA de codificación como GLM-4.6 y Qwen3-Coder-480B-A35B-Instruct están diseñados para resolver estas deficiencias. Este artículo compara sus arquitecturas, benchmarks y eficiencia de inferencia para mostrar cómo cada modelo resuelve problemas de codificación del mundo real, desde prototipado rápido hasta análisis profundo de repositorios, y guía a los desarrolladores en la elección del modelo y configuración adecuados para sus tareas de codificación específicas.
¿Qué Problemas de Codificación Resuelven las Personas con Modelos de IA?
Los modelos de IA de codificación ayudan principalmente a los desarrolladores a generar y operar código. O bien crean nuevos archivos y módulos a partir de instrucciones en lenguaje natural, o leen repositorios existentes para modificar, refactorizar o llamar a datos y API externas. El primer tipo acelera el prototipado y la automatización tipo agente; el segundo mejora la comprensión y reutilización de bases de código grandes y complejas.
| Tipo | Generación basada en instrucciones / Agente | Razonamiento basado en repositorio / Llamada a datos |
|---|---|---|
| Entrada | Solicitud en lenguaje natural como “construye esta funcionalidad” | Código del proyecto, archivos del repo, APIs, fuentes de datos |
| Enfoque | Crea nuevo contenido (módulos, archivos, interfaces) | Entiende el código existente y lo expande |
| Automatización | Alta automatización (flujos de trabajo tipo agente) | Análisis complejo con integración de contexto |
| Usos típicos | Prototipado rápido, generación de UI, scripts de configuración | Refactorización, actualizaciones de repos grandes, funcionalidades basadas en datos |
| Riesgos | Calidad de salida, consistencia de estilo, errores estructurales | Comprensión débil del contexto, desajuste de datos, errores de API |
Estos dos patrones enmarcan cómo la siguiente sección comparará GLM 4.6 y Qwen3-Coder-480B-A35B-Instruct en su rendimiento de codificación.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Rendimiento de Código
¡Puedes usar directamente Novita AI en Hugging Face desde la interfaz web para una prueba rápida y gratuita!
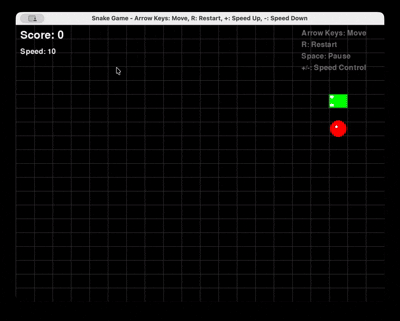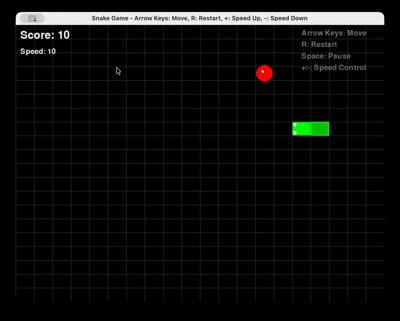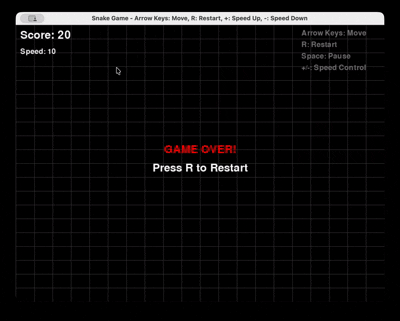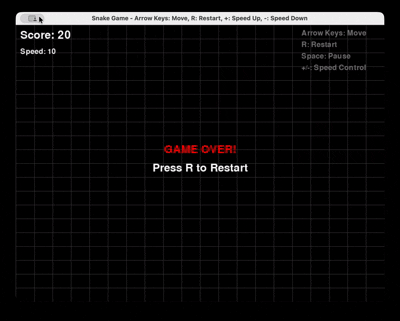
Solicitud: “Genera un juego completo de Snake en Python usando Pygame, con reinicio y control de velocidad.”

Qwen 3 Coder
GLM 4.6
Solicitud: “Lee todos los archivos .py de este repositorio y explica el propósito de cada archivo y sus funciones clave en una lista Markdown concisa.” https://github.com/pallets/flask/tree/main/examples/tutorial
| Aspecto | Qwen3-Coder-480B-A35B | GLM 4.6 |
|---|---|---|
| Cobertura | Muy completa; lista cada archivo, plantilla y prueba con propósito y funciones detallados. | Se centra solo en los componentes principales; omite plantillas menores y archivos adicionales. |
| Estructura | Jerárquica y exhaustiva, terminando con patrones arquitectónicos y principios de diseño. | Concisa y modular, agrupando archivos por funcionalidad (auth, blog, tests). |
| Profundidad de comprensión | Demuestra comprensión profunda del repositorio y razonamiento de contexto largo. | Muestra resumen eficiente y condensación de información. |
| Legibilidad | Densa y larga; más adecuada para lectores expertos o documentación técnica. | Más fácil de leer; adecuada para principiantes o resúmenes de referencia rápida. |
| Adecuación al caso de uso | Ideal para evaluar la comprensión de código y la profundidad de razonamiento en modelos de contexto largo. | Ideal para probar la calidad del resumen y la claridad bajo salidas restringidas. |
| Fortaleza destacada | Seguimiento de contexto largo, razonamiento estructural y cobertura completa. | Precisión, brevedad y claridad al resumir la lógica clave. |
| Mejor demuestra | Capacidades de análisis de repositorio y explicación detallada. | Habilidades de resumen y escritura técnica concisa. |
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Arquitectura
GLM-4.6 es un modelo MoE de 355B parámetros con 32B parámetros activos y una ventana de contexto de 200K tokens.
- Parámetros totales: ~ 355 mil millones, parámetros activos ~ 32 mil millones.
- Arquitectura del modelo: Mixture-of-Experts (MoE) heredada de la serie GLM-4.x.
- Ventana de contexto: nativa de 200,000 tokens, salida máxima ~128K tokens.
- Mejoras clave sobre su predecesor (GLM-4.5) incluyen mayor longitud de contexto, mejor rendimiento de codificación y mejor integración de herramientas.
Qwen3-Coder-480B-A35B es un modelo MoE de 480B parámetros con 35B parámetros activos y soporta hasta 1 M de tokens de contexto.
- Parámetros totales: ~ 480 mil millones; parámetros activos ~ 35 mil millones.
- Ventana de contexto: soporte nativo para ~256 K tokens, escalable mediante extrapolación a ~1 millón de tokens.
- Arquitectura: Mixture-of-Experts con muchos expertos (por ejemplo, 160 expertos con 8 activos) según la tarjeta del modelo.
- Diseñado específicamente para tareas de codificación agentivas (generación de código multi-turno, invocación de herramientas).
GLM-4.6 está optimizado para rendimiento de codificación e integración de herramientas, lo que lo hace muy adecuado para codificación rápida, depuración y colaboración multiherramienta. En contraste, Qwen3-Coder-480B-A35B-Instruct es más adecuado para la comprensión de bases de código a gran escala, razonamiento de documentos largos y tareas de refactorización entre archivos que requieren contexto ultralargo y procesamiento lógico complejo.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Benchmark
| Benchmark | GLM-4.6 | Qwen3-Coder-480B-A35B-Instruct |
|---|---|---|
| SWE-bench Verificado | 68.0 % | 69.6 % (OpenHands 500 turnos) |
| Terminal-Bench | 40.5 % | 37.5 % |
| LiveCodeBench v6 | 84.5 % (con herramientas) | – |
| HLE | 30.4 % (con herramientas) | – |
| Aider-Polyglot | – | 61.8 % |
| SWE-bench Multilingüe | – | 54.7 % |
| WebArena / Mind2Web | ~45–50 % (rango) | 49.9 / 55.8 % |
- GLM-4.6 obtiene un rendimiento ligeramente inferior en SWE-bench pero lidera en LiveCodeBench y benchmarks integrados con herramientas, mostrando madurez en flujos de trabajo de codificación asistida.
- Qwen3-Coder-480B logra una mayor consistencia en tareas multilingües y agentivas de múltiples turnos, lo que implica una mejor robustez en codificación compleja y de sesiones largas.
- Ambos están cerca en corrección de código pura, pero GLM-4.6 gana en capacidad de respuesta en tiempo real; Qwen3-Coder gana en razonamiento sostenido.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: Eficiencia
GLM-4.6 produce más y es más rápido, pero cuesta más en general; Qwen3-Coder-480B es más lento pero más barato por ejecución, con menor costo de razonamiento.
1. Volumen de Salida
- GLM-4.6: 86 millones de tokens de salida
- Qwen3-Coder-480B: 9.7 millones de tokens de salida
GLM-4.6 produce aproximadamente nueve veces más tokens de salida.
2. Velocidad de Generación
- GLM-4.6: 82 tokens por segundo
- Qwen3-Coder-480B: 41 tokens por segundo
GLM-4.6 genera respuestas aproximadamente el doble de rápido.
3. Costo Total
- GLM-4.6: $221 por ejecución de benchmark
- Qwen3-Coder-480B: $165 por ejecución de benchmark
GLM-4.6 es aproximadamente un 34% más caro en general.
4. Costo de Razonamiento
- GLM-4.6: mayor uso de tokens de razonamiento → mayor costo de razonamiento
- Qwen3-Coder-480B: menos tokens de razonamiento → menor costo de razonamiento
GLM-4.6 “habla más” durante el razonamiento; Qwen3 es más conciso y eficiente en costos.
5. Requisitos de Hardware
| Modelo | Parámetros Activos | Configuración Recomendada | Perfil de Eficiencia |
|---|---|---|---|
| GLM-4.6 | 32B | 8× A100 80 GB o 4× H100 48 GB | Bajo VRAM, inferencia rápida |
| Qwen3-Coder-480B | 35B | 8–16× H100 80 GB | Alto VRAM, optimizado para ejecuciones de contexto largo |
- GLM-4.6: Mayor salida, inferencia más rápida, pero también el más caro y con mayor uso de razonamiento.
- Qwen3-Coder-480B: Menor velocidad y salida, pero más eficiente en costos con menor sobrecarga de razonamiento.
GLM-4.6 se adapta a tareas de codificación interactivas y de alta velocidad; Qwen3-Coder se adapta a la inferencia de contexto largo o a gran escala.
¿Cómo Acceder a GLM 4.6 o Qwen3-Coder-480B-A35B-Instruct para tu Trabajo de Código?
El sitio web oficial actualmente utiliza un modelo de suscripción mensual. Si solo quieres usarlo de manera práctica sin pagar por tiempo no utilizado, puedes probar Novita AI, que ofrece precios más bajos y servicios de soporte altamente estables.
Novita AI ofrece APIs de Qwen3-Coder con una ventana de contexto de 262K a $0.29 por entrada y $1.2 por salida. También proporciona APIs de GLM-4.6V con una ventana de contexto de 208K a $0.60 por entrada y $2.20 por salida, soportando salidas estructuradas y llamadas a funciones.
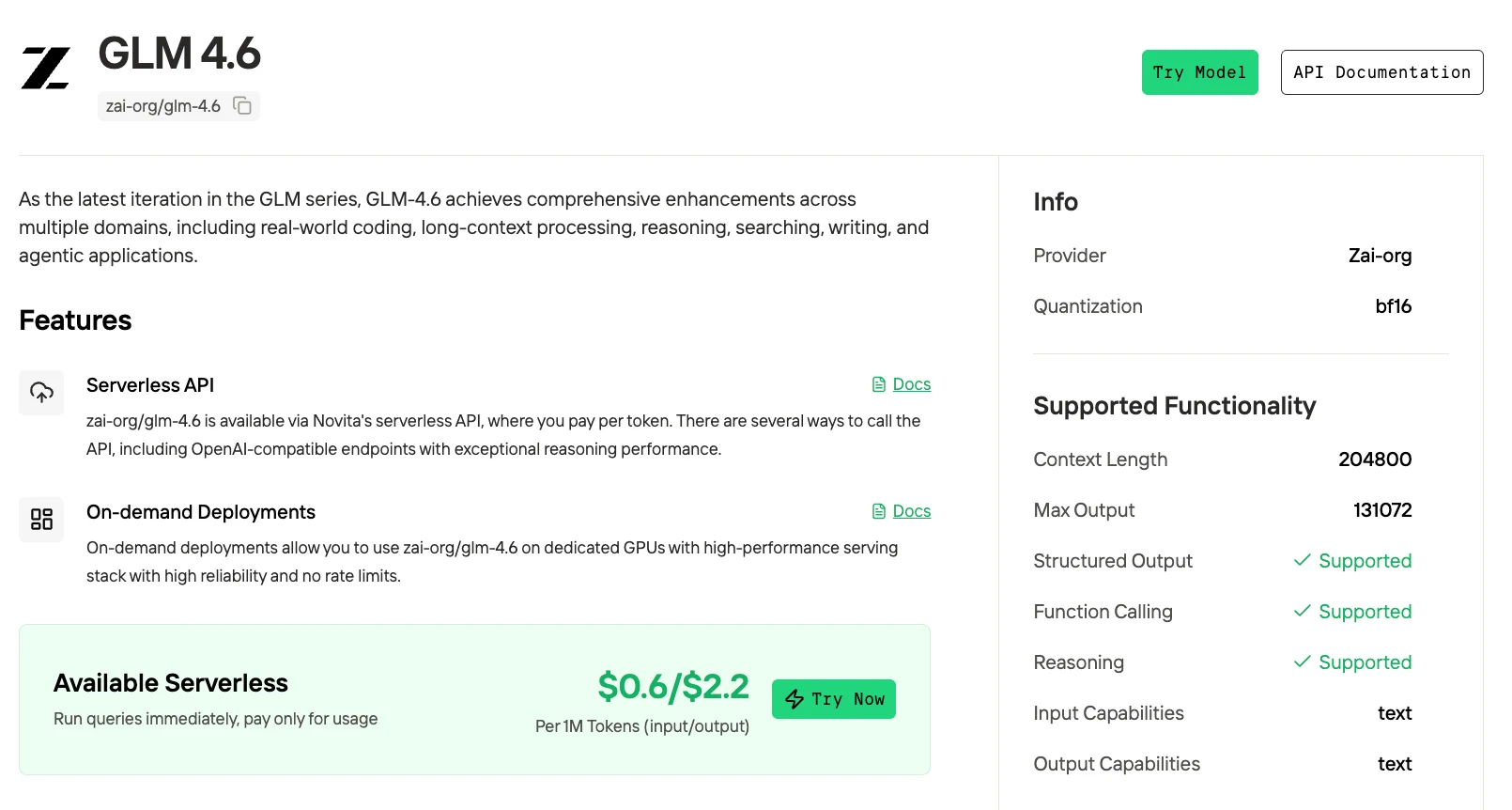
Al usar el servicio de Novita AI, puedes evitar las restricciones regionales de Claude Code. Novita también ofrece garantías de SLA con un 99% de estabilidad del servicio, lo que lo hace especialmente adecuado para escenarios de alta frecuencia como generación de código y pruebas automatizadas. Novita AI también proporciona guías de acceso para Trae y Qwen Code, que se pueden encontrar en los siguientes artículos.
Lo Primero: Obtén la Clave API (Usando GLM-4.6 como Ejemplo)
Paso 1: Inicia sesión en tu cuenta y haz clic en el botón de la Biblioteca de Modelos.
GLM-4.6 en Cursor
Paso 1: Instala y Activa Cursor
- Descarga la última versión de Cursor IDE desde cursor.com
- Suscríbete al plan Pro para habilitar funciones basadas en API
- Abre la aplicación y completa la configuración inicial
Paso 2: Accede a la Configuración Avanzada del Modelo
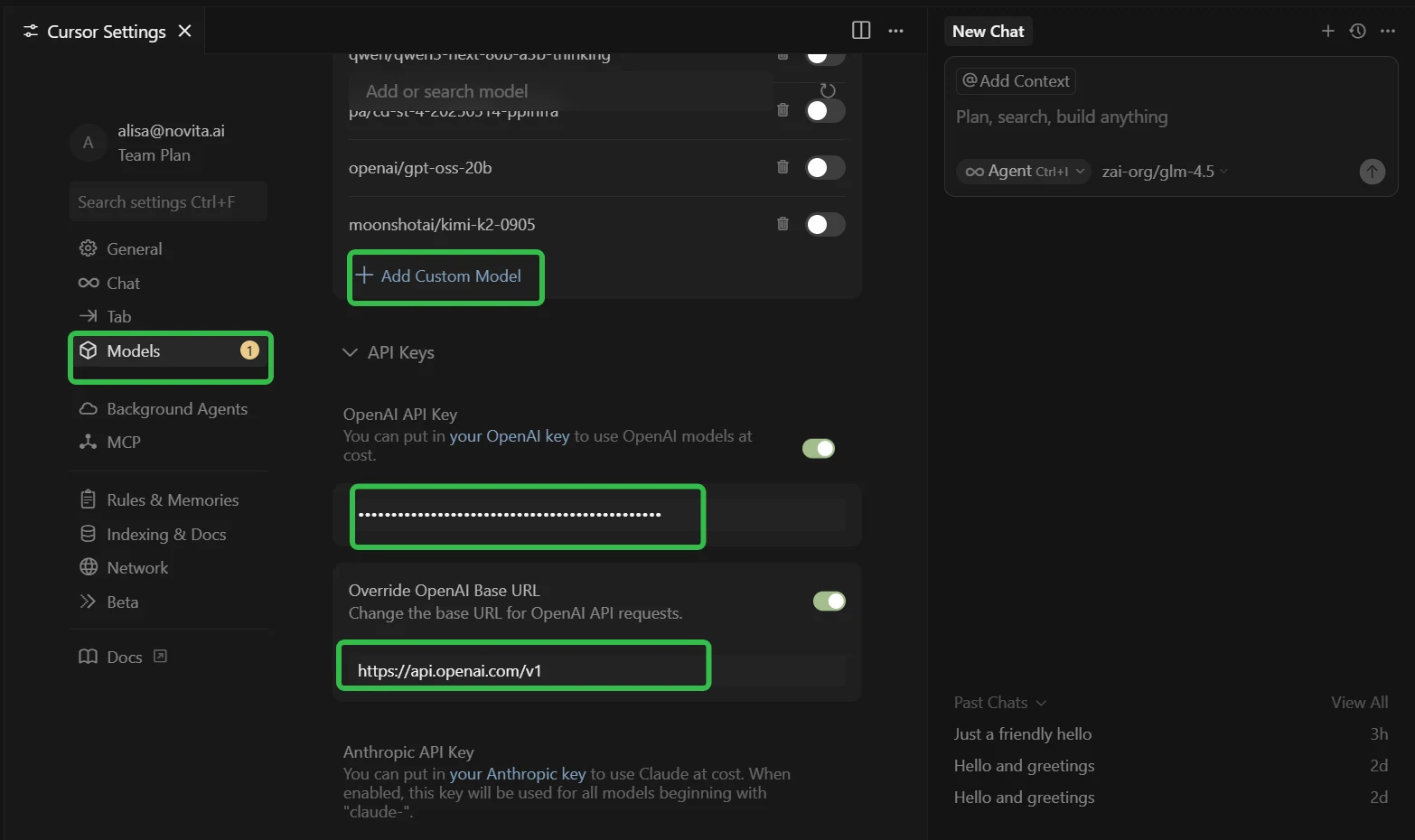
- Abre Cursor Settings (usa Ctrl + F para encontrarlo rápidamente)
- Ve a la pestaña “Models” en el menú izquierdo
- Busca la sección “API Configuration”
Paso 3: Configura la Integración con Novita AI
- Expande la sección “API Keys”
- ✅ Activa la opción “OpenAI API Key”
- ✅ Activa la opción “Override OpenAI Base URL”
- En el campo “OpenAI API Key”: Pega tu clave API de Novita AI
- En el campo “Override OpenAI Base URL”: Reemplaza el valor predeterminado con:
https://api.novita.ai/openai
Paso 4: Agrega Múltiples Modelos de Codificación de IA
Haz clic en “+ Add Custom Model” y agrega cada modelo:
qwen/qwen3-coder-480b-a35b-instructzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Paso 5: Prueba tu Integración
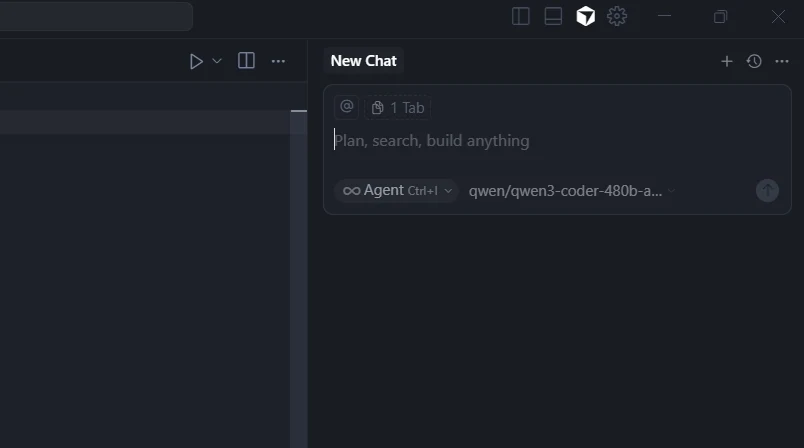
- Inicia un nuevo chat en Ask Mode o Agent Mode
- Prueba diferentes modelos para varias tareas de codificación
- Verifica que todos los modelos respondan correctamente
GLM-4.6 en Claude Code
Para Windows
Abre el Símbolo del sistema y establece las siguientes variables de entorno:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Clave API de Novita>
set ANTHROPIC_MODEL=moonshotai/glm-4.6
set ANTHROPIC_SMALL_FAST_MODEL=moonshotai/glm-4.6
Reemplaza <[Clave API de Novita](https://novita.ai/settings/key-management)> con tu clave API real obtenida de la plataforma Novita AI. Estas variables permanecen activas durante la sesión actual y deben restablecerse si cierras el Símbolo del sistema.
Para Mac y Linux
Abre la Terminal y exporta las siguientes variables de entorno:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Clave API de Novita>"
export ANTHROPIC_MODEL="moonshotai/glm-4.6"
export ANTHROPIC_SMALL_FAST_MODEL="moonshotai/glm-4.6"
Iniciar Claude Code
Con la instalación y configuración completas, ahora puedes iniciar Claude Code en el directorio de tu proyecto. Navega a la ubicación de tu proyecto deseada usando el comando cd:
cd <tu-directorio-del-proyecto>
claude .
GLM-4.6 en Trae
Paso 1: Abre Trae y Accede a los Modelos
Inicia la aplicación Trae. Haz clic en el botón Toggle AI Side Bar en la esquina superior derecha para abrir la barra lateral de IA. Luego, ve a AI Management y selecciona Models.
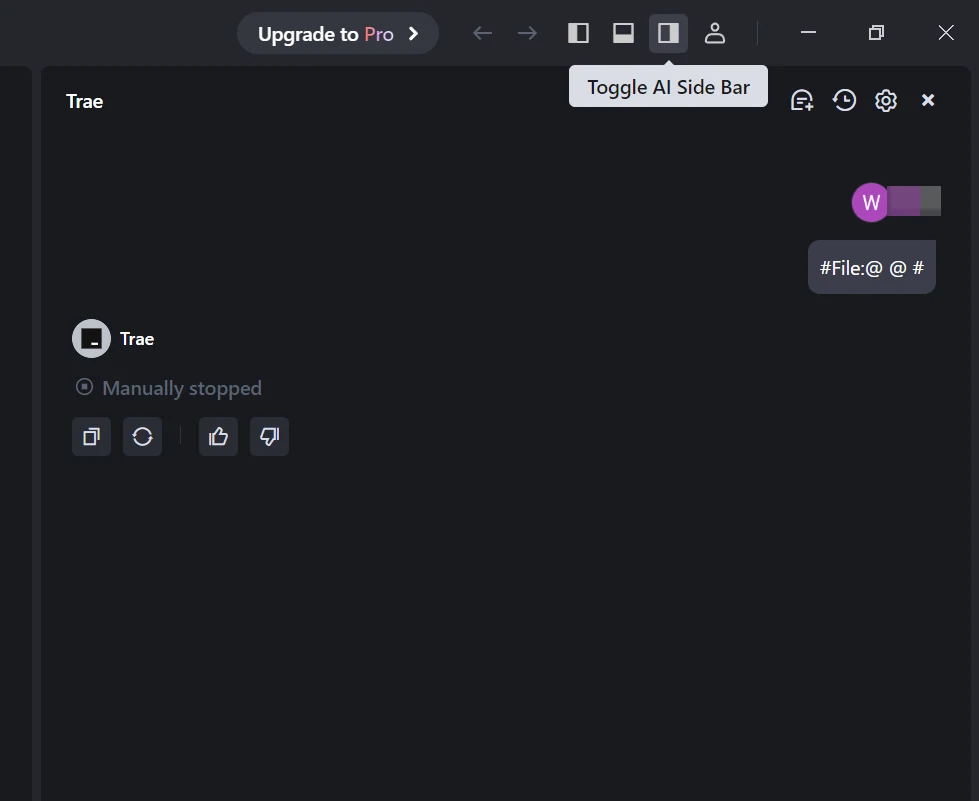

Paso 2: Agrega un Modelo Personalizado y Elige Novita como Proveedor
Haz clic en el botón Add Model para crear una entrada de modelo personalizado. En el cuadro de diálogo de agregar modelo, selecciona Provider = Novita en el menú desplegable.


Paso 3: Selecciona o Ingresa el Modelo
En el menú desplegable de Model, elige el modelo deseado (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324, o MiniMax-M1-80k, GLM 4.6). Si el modelo exacto no aparece en la lista, simplemente escribe el ID del modelo que anotaste de la biblioteca de Novita. Asegúrate de elegir la variante correcta del modelo que deseas usar.
GLM 4.6 en Codex
Configuración del Archivo de Configuración
Codex CLI utiliza un archivo de configuración TOML ubicado en:
- macOS/Linux:
~/.codex/config.toml - Windows:
%USERPROFILE%\.codex\config.toml
Plantilla de Configuración Básica
model = "glm-4.6"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer TU_CLAVE_API_DE_NOVITA"}
wire_api = "chat"
Iniciar Codex CLI
codex
Ejemplos de Uso Básico
Generación de Código:
> Crea una clase de Python para manejar respuestas de API REST con manejo de errores
Análisis de Proyecto:
> Revisa esta base de código y sugiere mejoras para el rendimiento
Corrección de Errores:
> Arregla el error de autenticación en la función de inicio de sesión
Pruebas:
> Genera pruebas unitarias completas para el módulo de servicio de usuario
Para resolver tareas de codificación, GLM-4.6 destaca en desarrollo rápido e interactivo, depuración automatizada y generación de código basada en herramientas. Su mayor velocidad y capacidad de respuesta lo hacen ideal para desarrolladores que iteran rápidamente. Qwen3-Coder-480B-A35B-Instruct se centra en el razonamiento de repositorios grandes, comprensión de contexto largo y refactorización estructurada, lo que le permite manejar tareas de código complejas entre archivos. Juntos, demuestran cómo la IA puede acelerar el desarrollo de software: GLM-4.6 prioriza velocidad y precisión, mientras que Qwen3-Coder enfatiza la escala y la profundidad del razonamiento.
Preguntas Frecuentes
¿Cómo ayuda GLM-4.6 a resolver tareas de codificación reales?
GLM-4.6 puede generar, depurar y refactorizar código de forma interactiva usando lenguaje natural. Está optimizado para contextos de código de corta a media duración, ayudando a los desarrolladores a probar, corregir y lanzar funciones rápidamente dentro de IDE como Cursor o Claude Code.
¿Cuándo es mejor elegir Qwen3-Coder-480B-A35B-Instruct?
Usa Qwen3-Coder-480B-A35B-Instruct para problemas de codificación a gran escala o a nivel de repositorio. Su contexto extendido de 1M de tokens permite un razonamiento profundo a través de múltiples archivos, ideal para analizar arquitectura, rastrear dependencias o refactorizar sistemas complejos.
¿Qué modelo realiza tareas de codificación más rápido?
GLM-4.6 genera aproximadamente 82 tokens por segundo, aproximadamente el doble de velocidad que Qwen3-Coder-480B-A35B-Instruct, lo que lo hace mejor para flujos de trabajo iterativos y sensibles al tiempo.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera fácil de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



