

현대 개발자들은 코드 생성, 디버깅 및 대규모 코드베이스 유지 관리에서 점점 더 많은 과제에 직면하고 있습니다. 기존 도구로는 긴 컨텍스트 추론을 효율적으로 처리하거나 복잡한 워크플로우와 통합하기 어렵습니다. GLM-4.6 및 Qwen3-Coder-480B-A35B-Instruct와 같은 AI 코딩 모델은 이러한 격차를 해소하기 위해 설계되었습니다. 이 글에서는 두 모델의 아키텍처, 벤치마크 및 추론 효율성을 비교하여 각 모델이 신속한 프로토타이핑부터 심층 저장소 분석에 이르기까지 실제 코딩 문제를 어떻게 해결하는지 보여주고, 개발자가 특정 코딩 작업에 적합한 모델과 설정을 선택할 수 있도록 안내합니다.
사람들은 AI 모델을 사용하여 어떤 코딩 문제를 해결합니까?
AI 코딩 모델은 주로 개발자가 코드를 생성하고 운영하는 데 도움을 줍니다. 자연어 명령에서 새 파일과 모듈을 생성하거나 기존 저장소를 읽어 수정, 리팩토링하거나 외부 데이터 및 API를 호출합니다. 첫 번째 유형은 프로토타이핑과 에이전트 스타일 자동화를 가속화하고, 두 번째 유형은 크고 복잡한 코드베이스의 이해와 재사용을 개선합니다.
| 유형 | 명령 기반 생성/에이전트 | 저장소 기반 추론/데이터 호출 |
|---|---|---|
| 입력 | "이 기능을 구축해 줘"와 같은 자연어 요청 | 프로젝트 코드, 저장소 파일, API, 데이터 소스 |
| 초점 | 새 콘텐츠(모듈, 파일, 인터페이스) 생성 | 기존 코드를 이해하고 확장 |
| 자동화 | 높은 자동화(에이전트 스타일 워크플로우) | 컨텍스트 통합을 통한 복잡한 분석 |
| 일반적인 용도 | 신속한 프로토타이핑, UI 생성, 설정 스크립트 | 리팩토링, 대규모 저장소 업데이트, 데이터 기반 기능 |
| 위험 | 출력 품질, 스타일 일관성, 구조 오류 | 컨텍스트 이해 부족, 데이터 불일치, API 버그 |
이 두 가지 패턴은 다음 섹션에서 코딩 성능 측면에서 GLM 4.6과 Qwen3-Coder-480B-A35B-Instruct를 비교하는 프레임워크를 제공합니다.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: 코드 성능
Novita AI를 Hugging Face 웹사이트 UI에서 직접 사용하여 무료로 빠르게 체험해보세요!
프롬프트: “Pygame을 사용하여 Python으로 스네이크 게임을 완전히 생성하세요. 다시 시작 및 속도 제어 기능을 포함해야 합니다.”

Qwen 3 Coder
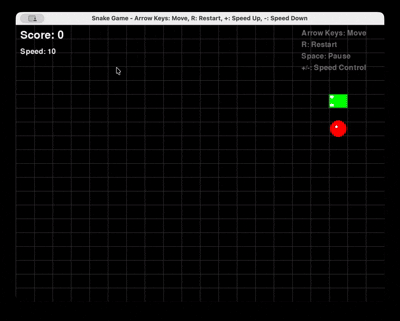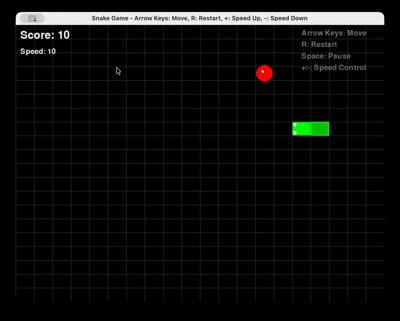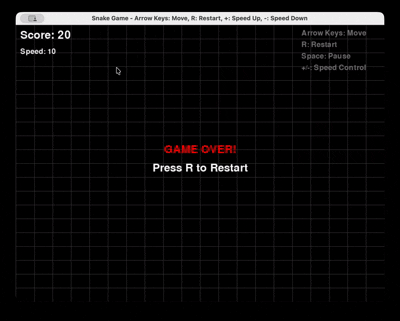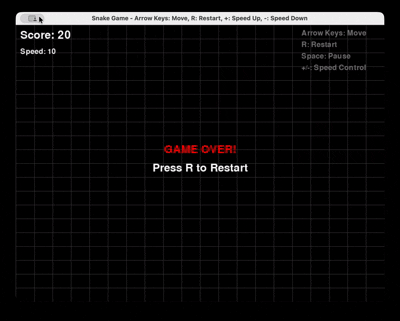
GLM 4.6
프롬프트: "이 저장소의 모든 .py 파일을 읽고 각 파일의 목적과 주요 함수를 간결한 Markdown 목록으로 설명하세요."https://github.com/pallets/flask/tree/main/examples/tutorial
| 측면 | Qwen3-Coder-480B-A35B | GLM 4.6 |
|---|---|---|
| 범위 | 매우 포괄적임. 모든 파일, 템플릿 및 테스트를 상세한 목적과 함수와 함께 나열함. | 주요 구성 요소에만 집중. 마이너 템플릿과 추가 파일은 생략함. |
| 구조 | 계층적이고 철저함. 아키텍처 패턴과 설계 원칙으로 끝맺음. | 간결하고 모듈화되어 있으며 기능(인증, 블로그, 테스트)별로 파일 그룹화. |
| 이해 깊이 | 깊은 저장소 이해와 긴 컨텍스트 추론을 보여줌. | 효율적인 요약과 정보 압축을 보여줌. |
| 가독성 | 밀도가 높고 길며, 전문 독자나 기술 문서에 더 적합. | 읽기 쉬움. 초보자나 빠른 참조 요약에 적합. |
| 사용 사례 적합성 | 대형 컨텍스트 모델의 코드 이해 및 추론 깊이 평가에 이상적. | 제한된 출력에서 요약 품질과 명확성 테스트에 이상적. |
| 강조된 강점 | 긴 컨텍스트 추적, 구조적 추론, 포괄적인 범위. | 정확성, 간결성, 핵심 로직 요약의 명확성. |
| 가장 잘 보여주는 것 | 저장소 분석 및 상세 설명 능력. | 요약 및 간결한 기술 작성 능력. |
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: 아키텍처
GLM-4.6은 355B 파라미터 MoE 모델로, 32B 활성 파라미터와 200K 토큰 컨텍스트 윈도우를 갖습니다.
- 총 파라미터: 약 3550억 개, 활성 파라미터: 약 320억 개.
- 모델 아키텍처: GLM-4.x 시리즈에서 계승된 Mixture-of-Experts(MoE).
- 컨텍스트 윈도우: 기본 200,000 토큰, 최대 출력 약 128K 토큰.
- 이전 모델(GLM-4.5) 대비 주요 개선 사항: 더 긴 컨텍스트 길이, 향상된 코딩 성능, 더 나은 도구 통합.
Qwen3-Coder-480B-A35B는 480B 파라미터 MoE 모델로, 35B 활성 파라미터를 가지며 최대 1M 토큰 컨텍스트를 지원합니다.
- 총 파라미터: 약 4800억 개; 활성 파라미터: 약 350억 개.
- 컨텍스트 윈도우: 기본 약 256K 토큰, 외삽을 통해 약 100만 토큰으로 확장 가능.
- 아키텍처: Mixture-of-Experts, 모델 카드에 따르면 많은 수의 전문가(예: 160개 중 8개 활성).
- 목적: 에이전트 기반 코딩 작업(다중 턴 코드 생성, 도구 호출)을 위해 특별히 구축됨.
GLM-4.6은 코딩 성능과 도구 통합에 최적화되어 빠른 코딩, 디버깅 및 다중 도구 협업에 적합합니다. 반면 Qwen3-Coder-480B-A35B-Instruct는 초장기 컨텍스트와 복잡한 논리 처리를 요구하는 대규모 코드베이스 이해, 긴 문서 추론 및 교차 파일 리팩토링 작업에 더 적합합니다.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: 벤치마크
| 벤치마크 | GLM-4.6 | Qwen3-Coder-480B-A35B-Instruct |
|---|---|---|
| SWE-bench Verified | 68.0% | 69.6% (OpenHands 500턴) |
| Terminal-Bench | 40.5% | 37.5% |
| LiveCodeBench v6 | 84.5% (도구 포함) | – |
| HLE | 30.4% (도구 포함) | – |
| Aider-Polyglot | – | 61.8% |
| SWE-bench Multilingual | – | 54.7% |
| WebArena / Mind2Web | ~45–50% (범위) | 49.9 / 55.8% |
- GLM-4.6은 SWE-bench에서 약간 낮은 성능을 보이지만 LiveCodeBench 및 도구 통합 벤치마크에서 선두를 달리며, 보조 코딩 워크플로우에서의 성숙도를 보여줍니다.
- Qwen3-Coder-480B는 다국어 및 다중 턴 에이전트 작업에서 더 높은 일관성을 달성하여 복잡하고 긴 세션 코딩에서 더 나은 견고성을 의미합니다.
- 순수 코드 정확성에서는 두 모델이 비슷하지만, GLM-4.6은 실시간 응답성에서 승리하고 Qwen3-Coder는 지속적인 추론에서 승리합니다.
GLM 4.6 VS Qwen3-Coder-480B-A35B-Instruct: 효율성
GLM-4.6은 출력량이 더 많고 속도가 더 빠르지만 전체 비용은 더 높습니다. Qwen3-Coder-480B는 느리지만 실행당 비용이 저렴하고 추론 비용이 낮습니다.
1. 출력량
- GLM-4.6: 8600만 출력 토큰
- Qwen3-Coder-480B: 970만 출력 토큰
GLM-4.6이 약 9배 더 많은 출력 토큰을 생성합니다.
2. 생성 속도
- GLM-4.6: 초당 82 토큰
- Qwen3-Coder-480B: 초당 41 토큰
GLM-4.6이 약 2배 빠르게 응답을 생성합니다.
3. 총 비용
- GLM-4.6: 벤치마크 실행당 $221
- Qwen3-Coder-480B: 벤치마크 실행당 $165
GLM-4.6이 전체적으로 약 34% 더 비쌉니다.
4. 추론 비용
- GLM-4.6: 추론 토큰 사용량 ↑ → 추론 비용 ↑
- Qwen3-Coder-480B: 추론 토큰 사용량 ↓ → 추론 비용 ↓
GLM-4.6은 추론 중에 “더 많이 말하고”, Qwen3는 더 간결하고 비용 효율적입니다.
5. 하드웨어 요구 사항
| 모델 | 활성 파라미터 | 권장 구성 | 효율성 프로필 |
|---|---|---|---|
| GLM-4.6 | 32B | 8× A100 80 GB 또는 4× H100 48 GB | 낮은 VRAM, 빠른 추론 |
| Qwen3-Coder-480B | 35B | 8–16× H100 80 GB | 높은 VRAM, 긴 컨텍스트 실행에 최적화 |
- GLM-4.6: 가장 높은 출력, 가장 빠른 추론, 그러나 가장 비싸고 추론 오버헤드가 큼.
- Qwen3-Coder-480B: 낮은 속도와 출력, 그러나 감소된 추론 오버헤드로 비용 효율성 높음.
GLM-4.6은 대화형, 고속 코딩 작업에 적합; Qwen3-Coder는 긴 컨텍스트 또는 대규모 배치 추론에 적합.
코드 작업을 위해 GLM 4.6 또는 Qwen3-Coder-480B-A35B-Instruct에 액세스하는 방법?
공식 웹사이트는 현재 월간 구독 모델을 사용합니다. 사용하지 않는 시간에 대해 비용을 지불하지 않고 실용적으로 사용하려면 Novita AI를 시도해 보세요. Novita AI는 더 낮은 가격과 매우 안정적인 지원 서비스를 제공합니다.
Novita AI는 262K 컨텍스트 윈도우의 Qwen3-Coder API를 입력당 $0.29, 출력당 $1.2에 제공합니다. 또한 208K 컨텍스트 윈도우의 GLM-4.6V API를 입력당 $0.60, 출력당 $2.20에 제공하며, 구조화된 출력 및 함수 호출을 지원합니다.
Novita AI의 서비스를 사용하면 Claude Code의 지역 제한을 우회할 수 있습니다. Novita는 99% 서비스 안정성을 갖춘 SLA 보장을 제공하므로 코드 생성 및 자동화된 테스트와 같은 고주파 시나리오에 특히 적합합니다. Novita AI는 Trae 및 Qwen Code에 대한 액세스 가이드도 제공하며, 다음 문서에서 확인할 수 있습니다.
첫 번째: API 키 가져오기(GLM-4.6을 예시로 사용)
1단계: 계정에 로그인하고 모델 라이브러리 버튼을 클릭합니다.
GLM-4.6을 Cursor에서 사용하기
1단계: Cursor 설치 및 활성화
- cursor.com에서 최신 버전의 Cursor IDE 다운로드
- Pro 플랜에 가입하여 API 기반 기능 활성화
- 앱을 열고 초기 구성 완료
2단계: 고급 모델 설정 액세스
- Cursor 설정 열기 (빠르게 찾으려면 Ctrl + F 사용)
- 왼쪽 메뉴에서 “Models” 탭으로 이동
- “API Configuration” 섹션 찾기
3단계: Novita AI 통합 구성
- “API Keys” 섹션 확장
- ✅ “OpenAI API Key” 토글 활성화
- ✅ “Override OpenAI Base URL” 토글 활성화
- “OpenAI API Key” 필드: Novita AI API 키 붙여넣기
- “Override OpenAI Base URL” 필드: 기본값을
https://api.novita.ai/openai로 변경
4단계: 여러 AI 코딩 모델 추가
**“+ Add Custom Model”**을 클릭하고 각 모델 추가:
qwen/qwen3-coder-480b-a35b-instructzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
5단계: 통합 테스트
- Ask Mode 또는 Agent Mode에서 새 채팅 시작
- 다양한 코딩 작업에 대해 다른 모델 테스트
- 모든 모델이 올바르게 응답하는지 확인
GLM-4.6을 Claude Code에서 사용하기
Windows용
명령 프롬프트를 열고 다음 환경 변수를 설정합니다.
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Novita API Key>
set ANTHROPIC_MODEL=moonshotai/glm-4.6
set ANTHROPIC_SMALL_FAST_MODEL=moonshotai/glm-4.6
<[Novita API 키](https://novita.ai/settings/key-management)>를 Novita AI 플랫폼에서 얻은 실제 API 키로 바꾸세요. 이 변수들은 현재 세션 동안 활성화되며 명령 프롬프트를 닫으면 다시 설정해야 합니다.
Mac 및 Linux용
터미널을 열고 다음 환경 변수를 내보냅니다.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
export ANTHROPIC_MODEL="moonshotai/glm-4.6"
export ANTHROPIC_SMALL_FAST_MODEL="moonshotai/glm-4.6"
Claude Code 시작
설치 및 구성이 완료되면 프로젝트 디렉토리에서 Claude Code를 시작할 수 있습니다. cd 명령을 사용하여 원하는 프로젝트 위치로 이동합니다.
cd <your-project-directory>
claude .
GLM-4.6을 Trae에서 사용하기
1단계: Trae 열기 및 모델 액세스
Trae 앱을 시작합니다. 오른쪽 상단의 Toggle AI Side Bar를 클릭하여 AI 사이드바를 엽니다. 그런 다음 AI Management로 이동하여 Models를 선택합니다.

2단계: 사용자 정의 모델 추가 및 제공자로 Novita 선택
Add Model 버튼을 클릭하여 사용자 정의 모델 항목을 만듭니다. 모델 추가 대화상자에서 드롭다운 메뉴에서 Provider = Novita를 선택합니다.


3단계: 모델 선택 또는 입력
Model 드롭다운에서 원하는 모델(DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324, MiniMax-M1-80k, GLM 4.6)을 선택합니다. 정확한 모델이 목록에 없으면 Novita 라이브러리에서 확인한 모델 ID를 입력하면 됩니다. 사용하려는 모델의 올바른 변형을 선택했는지 확인하세요.
GLM 4.6을 Codex에서 사용하기
설정 구성 파일
Codex CLI는 다음 위치에 있는 TOML 구성 파일을 사용합니다.
- macOS/Linux:
~/.codex/config.toml - Windows:
%USERPROFILE%\.codex\config.toml
기본 구성 템플릿
model = "glm-4.6"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer YOUR_NOVITA_API_KEY"}
wire_api = "chat"
Codex CLI 실행
codex
기본 사용 예제
코드 생성:
> Create a Python class for handling REST API responses with error handling
프로젝트 분석:
> Review this codebase and suggest improvements for performance
버그 수정:
> Fix the authentication error in the login function
테스트:
> Generate comprehensive unit tests for the user service module
코딩 작업 해결을 위해 GLM-4.6은 빠르고 대화형 개발, 자동화된 디버깅 및 도구 기반 코드 생성에 탁월합니다. 더 높은 속도와 응답성 덕분에 빠르게 반복하는 개발자에게 이상적입니다. Qwen3-Coder-480B-A35B-Instruct는 대규모 저장소 추론, 긴 컨텍스트 이해 및 구조화된 리팩토링에 중점을 두어 복잡한 교차 파일 코드 작업을 처리할 수 있습니다. 이 두 모델은 AI가 소프트웨어 개발을 어떻게 가속화할 수 있는지 보여줍니다. GLM-4.6은 속도와 정밀도를 우선시하고, Qwen3-Coder는 규모와 추론 깊이를 강조합니다.
자주 묻는 질문
GLM-4.6은 실제 코딩 작업 해결에 어떻게 도움이 되나요?
GLM-4.6은 자연어를 사용하여 대화형으로 코드를 생성, 디버그 및 리팩토링할 수 있습니다. 짧거나 중간 길이의 코드 컨텍스트에 최적화되어 있어 개발자가 Cursor 또는 Claude Code와 같은 IDE 내에서 기능을 신속하게 테스트, 수정 및 출시할 수 있도록 돕습니다.
Qwen3-Coder-480B-A35B-Instruct는 언제 더 나은 선택인가요?
대규모 또는 저장소 수준의 코딩 문제에는 Qwen3-Coder-480B-A35B-Instruct를 사용하세요. 확장된 1M 토큰 컨텍스트는 여러 파일에 걸친 깊은 추론을 가능하게 하여 아키텍처 분석, 종속성 추적 또는 복잡한 시스템 리팩토링에 이상적입니다.
어느 모델이 코딩 작업을 더 빠르게 수행하나요?
GLM-4.6은 초당 약 82 토큰을 생성하여 Qwen3-Coder-480B-A35B-Instruct보다 약 2배 빠르므로 반복적이고 시간에 민감한 개발 워크플로우에 더 적합합니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.



