

- Какие задачи кодирования решают с помощью ИИ-моделей?
- GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Производительность в кодировании
- GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Архитектура
- GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Бенчмарки
- GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Эффективность
- Как получить доступ к GLM 4.6 или Qwen3-Coder-480B-A35B-Instruct для ваших задач кодирования?
Современные разработчики сталкиваются с растущими сложностями в генерации кода, отладке и поддержке крупных кодовых баз. Традиционные инструменты не могут эффективно работать с длинным контекстом или интегрироваться в сложные рабочие процессы. ИИ-модели для кодирования, такие как GLM-4.6 и Qwen3-Coder-480B-A35B-Instruct, созданы для решения этих проблем. В этой статье мы сравниваем их архитектуры, результаты бенчмарков и эффективность инференса, чтобы показать, как каждая модель решает реальные задачи кодирования — от быстрого прототипирования до глубокого анализа репозиториев — и помогаем разработчикам выбрать подходящую модель и конфигурацию для их конкретных задач.
Какие задачи кодирования решают с помощью ИИ-моделей?
ИИ-модели для кодирования в основном помогают разработчикам генерировать код и работать с ним. Они либо создают новые файлы и модули по инструкциям на естественном языке, либо читают существующие репозитории для модификации, рефакторинга или вызова внешних данных и API. Первый тип ускоряет прототипирование и автоматизацию в стиле агентов; второй улучшает понимание и повторное использование крупных, сложных кодовых баз.
| Тип | Генерация по инструкциям / Агент | Работа с репозиторием / Вызов данных |
|---|---|---|
| Входные данные | Запрос на естественном языке, например «создай эту функциональность» | Код проекта, файлы репозитория, API, источники данных |
| Фокус | Создание нового контента (модули, файлы, интерфейсы) | Понимание существующего кода и его расширение |
| Автоматизация | Высокая автоматизация (рабочие процессы в стиле агентов) | Сложный анализ с интеграцией контекста |
| Типичные использования | Быстрое прототипирование, генерация UI, скрипты настройки | Рефакторинг, обновления крупных репозиториев, функциональность на основе данных |
| Риски | Качество вывода, единообразие стиля, ошибки структуры | Слабое понимание контекста, несоответствие данных, ошибки API |
Эти два паттерна определяют, как в следующем разделе мы будем сравнивать GLM 4.6 и Qwen3-Coder-480B-A35B-Instruct по их производительности в кодировании.
GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Производительность в кодировании
Вы можете сразу использовать Novita AI на Hugging Face через веб-интерфейс, чтобы начать бесплатный и быстрый пробный период!
Запрос: «Создай полную игру «Змейка» на Python с использованием Pygame, с возможностью перезапуска и управления скоростью.»

Qwen 3 Coder
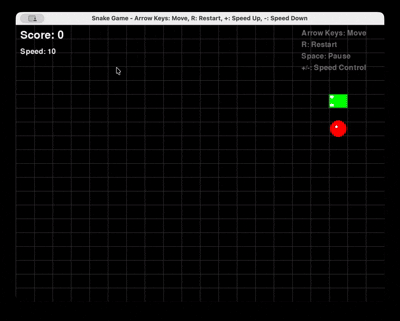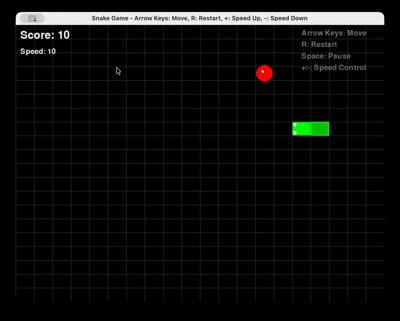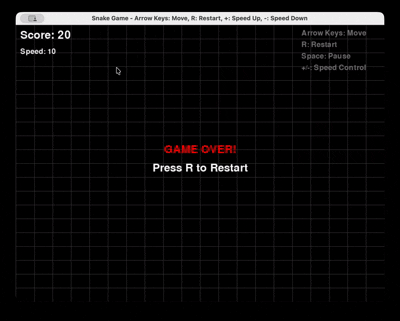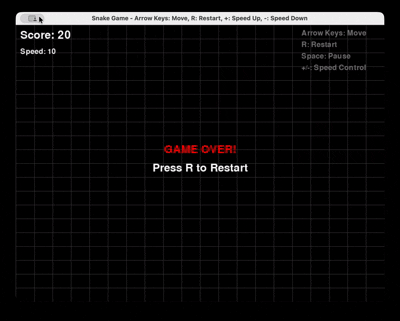
GLM 4.6
Запрос: «Прочитай все файлы .py в этом репозитории и объясни назначение каждого файла и его ключевые функции в кратком списке Markdown.»https://github.com/pallets/flask/tree/main/examples/tutorial
| Аспект | Qwen3-Coder-480B-A35B | GLM 4.6 |
|---|---|---|
| Полнота охвата | Очень полная; перечисляет каждый файл, шаблон и тест с подробным описанием назначения и функций. | Сосредоточена только на основных компонентах; пропускает незначительные шаблоны и дополнительные файлы. |
| Структура | Иерархическая и исчерпывающая, завершается архитектурными паттернами и принципами проектирования. | Лаконичная и модульная, группирует файлы по функциональности (аутентификация, блог, тесты). |
| Глубина понимания | Демонстрирует глубокое понимание репозитория и работу с длинным контекстом. | Показывает эффективное обобщение и сжатие информации. |
| Читаемость | Плотная и длинная; лучше подходит для опытных читателей или технической документации. | Легче читается; подходит для новичков или кратких справочных резюме. |
| Соответствие use-case | Идеальна для оценки понимания кода и глубины рассуждений в моделях с большим контекстом. | Идеальна для тестирования качества обобщения и ясности при ограниченном выводе. |
| Выделенная сильная сторона | Отслеживание длинного контекста, структурные рассуждения и полный охват. | Точность, краткость и ясность при обобщении ключевой логики. |
| Лучше всего демонстрирует | Возможности анализа репозиториев и детального объяснения кода. | Навыки обобщения и лаконичного технического письма. |
GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Архитектура
GLM-4.6 — это модель MoE с 355 млрд параметров, 32 млрд активных параметров и окном контекста в 200 тыс. токенов.
- Общее количество параметров: ~ 355 млрд, активных параметров ~ 32 млрд.
- Архитектура модели: Mixture-of-Experts (MoE), унаследованная от серии GLM-4.x.
- Окно контекста: нативное 200 000 токенов, максимальный вывод ~128 тыс. токенов.
- Ключевые улучшения по сравнению с предшественником (GLM-4.5): увеличенная длина контекста, улучшенная производительность в кодировании, лучшая интеграция с инструментами.
Qwen3-Coder-480B-A35B — это модель MoE с 480 млрд параметров, 35 млрд активных параметров и поддержкой контекста до 1 млн токенов.
- Общее количество параметров: ~ 480 млрд; активных параметров ~ 35 млрд.
- Окно контекста: нативная поддержка ~256 тыс. токенов, масштабируемая за счет экстраполяции до ~1 млн токенов.
- Архитектура: Mixture-of-Experts с большим количеством экспертов (например, 160 экспертов, 8 активных) согласно карточке модели.
- Создана специально для задач агентного кодирования (многоходовая генерация кода, вызов инструментов).
GLM-4.6 оптимизирована для производительности в кодировании и интеграции с инструментами, что делает её идеальной для быстрого кодирования, отладки и совместной работы с несколькими инструментами. В отличие от неё, Qwen3-Coder-480B-A35B-Instruct лучше подходит для понимания крупных кодовых баз, рассуждений над длинными документами и задач рефакторинга между файлами, которые требуют ультрадлинного контекста и сложной логической обработки.
GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Бенчмарки
| Бенчмарк | GLM-4.6 | Qwen3-Coder-480B-A35B-Instruct |
|---|---|---|
| SWE-bench Verified | 68,0 % | 69,6 % (OpenHands, 500 ходов) |
| Terminal-Bench | 40,5 % | 37,5 % |
| LiveCodeBench v6 | 84,5 % (с инструментами) | – |
| HLE | 30,4 % (с инструментами) | – |
| Aider-Polyglot | – | 61,8 % |
| SWE-bench Multilingual | – | 54,7 % |
| WebArena / Mind2Web | ~45–50 % (диапазон) | 49,9 / 55,8 % |
- GLM-4.6 показывает незначительно более низкие результаты на SWE-bench, но лидирует на LiveCodeBench и бенчмарках с интеграцией инструментов, что говорит о зрелости в рабочих процессах вспомогательного кодирования.
- Qwen3-Coder-480B демонстрирует более высокую стабильность в многоязычных и многоходовых агентных задачах, что указывает на лучшую устойчивость при сложном кодировании в длинных сессиях.
- Обе модели близки по чистоте корректности кода, но GLM-4.6 выигрывает в оперативности отклика; Qwen3-Coder выигрывает в устойчивости рассуждений.
GLM 4.6 против Qwen3-Coder-480B-A35B-Instruct: Эффективность
GLM-4.6 выводит больше токенов и работает быстрее, но в целом стоит дороже; Qwen3-Coder-480B медленнее, но дешевле за один запуск, с более низкой стоимостью рассуждений.
1. Объем вывода
- GLM-4.6: 86 млн выходных токенов
- Qwen3-Coder-480B: 9,7 млн выходных токенов
GLM-4.6 выводит примерно в девять раз больше токенов.
2. Скорость генерации
- GLM-4.6: 82 токена в секунду
- Qwen3-Coder-480B: 41 токен в секунду
GLM-4.6 генерирует ответы примерно в два раза быстрее.
3. Общая стоимость
- GLM-4.6: $221 за один прогон бенчмарка
- Qwen3-Coder-480B: $165 за один прогон бенчмарка
GLM-4.6 примерно на 34% дороже в целом.
4. Стоимость рассуждений
- GLM-4.6: более высокое использование токенов для рассуждений → более высокая стоимость рассуждений
- Qwen3-Coder-480B: меньше токенов для рассуждений → более низкая стоимость рассуждений
GLM-4.6 «говорит больше» во время рассуждений; Qwen3 более лаконичен и экономичен.
5. Требования к оборудованию
| Модель | Активные параметры | Рекомендуемая конфигурация | Профиль эффективности |
|---|---|---|---|
| GLM-4.6 | 32B | 8× A100 80 ГБ или 4× H100 48 ГБ | Низкое количество VRAM, быстрый инференс |
| Qwen3-Coder-480B | 35B | 8–16× H100 80 ГБ | Высокое количество VRAM, оптимизирована для запусков с длинным контекстом |
- GLM-4.6: Максимальный объем вывода, самый быстрый инференс, но также самая дорогая и требовательная к рассуждениям.
- Qwen3-Coder-480B: Более низкая скорость и объем вывода, но более экономичная с сокращенными накладными расходами на рассуждения.
GLM-4.6 подходит для интерактивных задач кодирования с высокой скоростью; Qwen3-Coder подходит для задач с длинным контекстом или крупномасштабного пакетного инференса.
Как получить доступ к GLM 4.6 или Qwen3-Coder-480B-A35B-Instruct для ваших задач кодирования?
На официальном сайте сейчас используется модель месячной подписки. Если вы хотите использовать модель практическим образом, а не платить за неиспользуемое время, вы можете попробовать Novita AI, которая предлагает более низкие цены и высокостабильные службы поддержки.
Novita AI предлагает API Qwen3-Coder с окном контекста 262K по $0,29 за входной токен и $1,2 за выходной. Также доступны API GLM-4.6V с окном контекста 208K по $0,60 за входной токен и $2,20 за выходной, с поддержкой структурированного вывода и вызова функций.
Используя сервис Novita AI, вы можете обойти региональные ограничения Claude Code. Novita также предоставляет гарантии SLA с 99% стабильностью сервиса, что делает её особенно подходящей для сценариев с высокой частотой использования, таких как генерация кода и автоматизированное тестирование. Novita AI также предоставляет руководства по доступу для Trae и Qwen Code, которые можно найти в следующих статьях.
Шаг 1: Получить API-ключ (на примере GLM-4.6)
Шаг 1: Войдите в свой аккаунт и нажмите кнопку «Библиотека моделей».
GLM-4.6 в Cursor
Шаг 1: Установить и активировать Cursor
- Скачайте новейшую версию IDE Cursor с cursor.com
- Оформите подписку на план Pro, чтобы включить функции на основе API
- Откройте приложение и завершите начальную конфигурацию
Шаг 2: Открыть расширенные настройки моделей
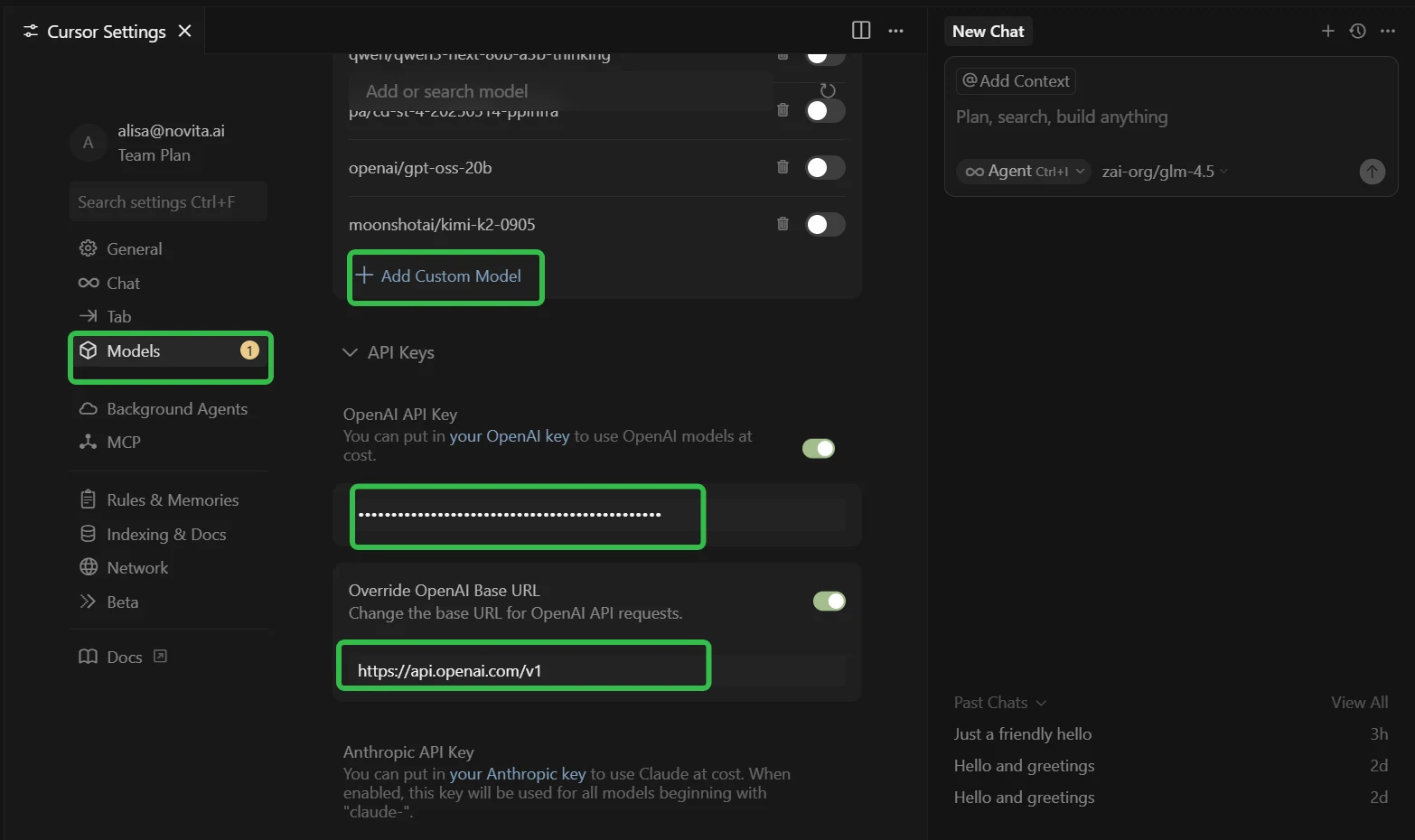
- Откройте Настройки Cursor (используйте Ctrl + F для быстрого поиска)
- Перейдите на вкладку «Модели» в левом меню
- Найдите раздел «Конфигурация API»
Шаг 3: Настроить интеграцию с Novita AI
- Разверните раздел «API-ключи»
- ✅ Включите переключатель «OpenAI API Key»
- ✅ Включите переключатель «Override OpenAI Base URL»
- В поле «OpenAI API Key» вставьте ваш API-ключ Novita AI
- В поле «Override OpenAI Base URL» замените значение по умолчанию на:
https://api.novita.ai/openai
Шаг 4: Добавить несколько ИИ-моделей для кодирования
Нажмите «+ Добавить пользовательскую модель» и добавьте каждую модель:
qwen/qwen3-coder-480b-a35b-instructzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Шаг 5: Протестировать интеграцию
- Начните новый чат в режиме «Запроса» или «Агента»
- Протестируйте разные модели для различных задач кодирования
- Убедитесь, что все модели отвечают корректно
GLM-4.6 в Claude Code
Для Windows
Откройте Командную строку и задайте следующие переменные окружения:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Novita API Key>
set ANTHROPIC_MODEL=moonshotai/glm-4.6
set ANTHROPIC_SMALL_FAST_MODEL=moonshotai/glm-4.6
Замените <[API-ключ Novita AI](https://novita.ai/settings/key-management)> на ваш фактический API-ключ, полученный на платформе Novita AI. Эти переменные остаются активными в течение текущей сессии и должны быть заданы заново, если вы закроете Командную строку.
Для Mac и Linux
Откройте Терминал и экспортируйте следующие переменные окружения:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
export ANTHROPIC_MODEL="moonshotai/glm-4.6"
export ANTHROPIC_SMALL_FAST_MODEL="moonshotai/glm-4.6"
Запуск Claude Code
После завершения установки и конфигурации вы можете теперь запустить Claude Code в директории вашего проекта. Перейдите в нужное вам местоположение проекта с помощью команды cd:
cd <your-project-directory>
claude .
GLM-4.6 в Trae
Шаг 1: Открыть Trae и перейти к моделям
Запустите приложение Trae. Нажмите кнопку «Переключить боковую панель ИИ» в правом верхнем углу, чтобы открыть боковую панель ИИ. Затем перейдите в «Управление ИИ» и выберите «Модели».
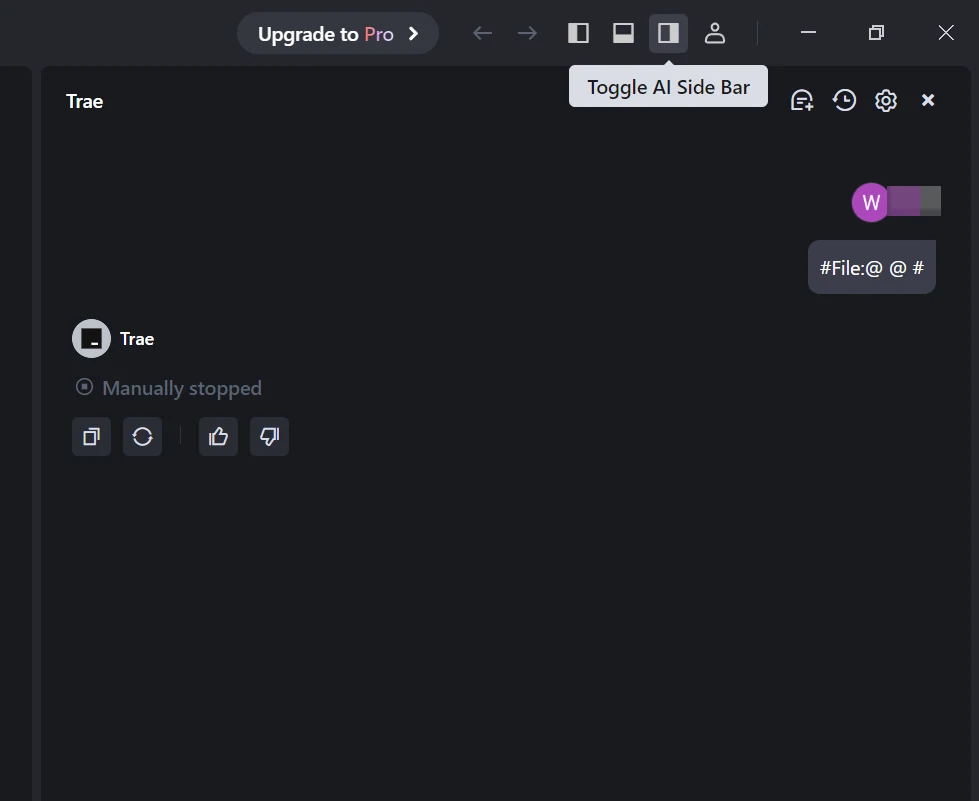

Шаг 2: Добавить пользовательскую модель и выбрать Novita в качестве провайдера
Нажмите кнопку «Добавить модель», чтобы создать запись пользовательской модели. В диалоговом окне добавления модели выберите Провайдер = Novita из выпадающего меню.


Шаг 3: Выбрать или ввести модель
Из выпадающего списка «Модель» выберите нужную вам модель (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324, MiniMax-M1-80k, GLM 4.6). Если точная модель не указана в списке, просто введите идентификатор модели, который вы записали из библиотеки Novita. Убедитесь, что вы выбираете правильный вариант нужной вам модели.
GLM 4.6 в Codex
Настройка конфигурационного файла
Codex CLI использует конфигурационный файл TOML, расположенный по следующим путям:
- macOS/Linux:
~/.codex/config.toml - Windows:
%USERPROFILE%\.codex\config.toml
Базовый шаблон конфигурации
model = "glm-4.6"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer YOUR_NOVITA_API_KEY"}
wire_api = "chat"
Запуск Codex CLI
codex
Примеры базового использования
Генерация кода:
> Create a Python class for handling REST API responses with error handling
Анализ проекта:
> Review this codebase and suggest improvements for performance
Исправление ошибок:
> Fix the authentication error in the login function
Тестирование:
> Generate comprehensive unit tests for the user service module
Для решения задач кодирования GLM-4.6 превосходит в быстрой интерактивной разработке, автоматизированной отладке и генерации кода на основе инструментов. Её более высокая скорость и отзывчивость делают её идеальной для разработчиков, которые быстро итерационно работают над кодом. Qwen3-Coder-480B-A35B-Instruct сосредоточена на рассуждениях над крупными репозиториями, понимании длинного контекста и структурированном рефакторинге, что позволяет ей справляться со сложными задачами с кодом между несколькими файлами. Вместе они демонстрируют, как ИИ может ускорить разработку программного обеспечения: GLM-4.6 делает акцент на скорости и точности, а Qwen3-Coder — на масштабе и глубине рассуждений.
Часто задаваемые вопросы
Как GLM-4.6 помогает решать реальные задачи кодирования?
GLM-4.6 может генерировать, отлаживать и рефакторить код в интерактивном режиме с использованием естественного языка. Она оптимизирована для контекстов с коротким и средним кодом, помогая разработчикам быстро тестировать, исправлять и выпускать функциональность в IDE таких как Cursor или Claude Code.
Когда Qwen3-Coder-480B-A35B-Instruct является лучшим выбором?
Используйте Qwen3-Coder-480B-A35B-Instruct для крупномасштабных задач кодирования или задач на уровне всего репозитория. Её расширенный контекст в 1 млн токенов позволяет проводить глубокие рассуждения сразу по нескольким файлам, что идеально подходит для анализа архитектуры, отслеживания зависимостей или рефакторинга сложных систем.
Какая модель выполняет задачи кодирования быстрее?
GLM-4.6 генерирует около 82 токенов в секунду, что примерно в два раза быстрее, чем Qwen3-Coder-480B-A35B-Instruct, что делает её лучшим выбором для итерационных рабочих процессов разработки, требующих скорости.
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывать ИИ-модели с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.



