

DeepSeek-V4-Pro: контекст 1M токенов, #1 в LiveCodeBench, открытый фронт
Вы оцениваете открытые модели для производственного кодирующего агента. Вам нужна модель, которая работает с большими кодовыми базами — целыми репозиториями, а не отдельными файлами — и реально решает задачи из GitHub без галлюцинаций при вызове инструментов. Любая модель, которую вы пробуете, либо ломается после 128K токенов, либо отстаёт от GPT-4o по бенчмаркам, важным для реальных инженерных задач.
DeepSeek-V4-Pro меняет эти расчёты. Это модель MoE с 1,6 трлн параметров с настоящим окном контекста в 1M токенов, высшим опубликованным баллом на LiveCodeBench (93.5 Pass@1) и рейтингом Codeforces 3206 — оба показателя #1 среди всех оценённых моделей, включая закрытые frontier API. Короче: это лучшая доступная сегодня открытая модель для конкурентного программирования и контекстных агентных задач, выпущенная под лицензией MIT. На сегодняшний день она доступна через Novita AI.
Попробовать DeepSeek-V4-Pro сейчас →
Что такое DeepSeek-V4-Pro?
DeepSeek-V4-Pro — флагманская модель в линейке V4 от DeepSeek, выпущенная 24 апреля 2026 года. Она стоит выше лёгкой DeepSeek-V4-Flash (284B всего / 13B активных) и позиционируется как превью текущих frontier-возможностей DeepSeek — то, что они описывают как «лучшую доступную сегодня открытую модель» для знаний и кодирования. Модель обучена на более чем 32 трлн токенов и дообучена по двухэтапному пайплайну: доменный экспертный SFT + RL на основе GRPO, за которым следует on-policy дистилляция. Полные технические детали указаны в статье DeepSeek DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence.
Ключевые характеристики на glance:
- Архитектура: Смесь экспертов (MoE) с гибридным вниманием — Сжатое разреженное внимание (CSA) + Сильно сжатое внимание (HCA)
- Параметры: 1,6T всего / 49B активированных на один проход вперёд
- Окно контекста: 1 048 576 токенов (1M)
- Точность: FP4 (эксперты MoE) + смешанная FP8
- Режимы рассуждений: Без размышлений (быстрый), С размышлениями (стандартный CoT), Макс (максимальный бюджет рассуждений)
- Возможности: Вызов функций, структурированные выводы, рассуждения, поиск по контексту длиной 1M
- Лицензия: MIT
Ключевые особенности
Гибридное внимание для эффективной работы с контекстом длиной 1M токенов
Большинство моделей, заявляющих о «длинном контексте», либо молча усекают его, либо резко теряют производительность за пределами 128K токенов. Архитектура гибридного внимания DeepSeek-V4-Pro, сочетающая Сжатое разреженное внимание (CSA) и Сильно сжатое внимание (HCA) а также Ограниченные многообразием гиперсвязи (mHC), изначально разработана для эффективной обработки миллионов токенов. На практике: балл MRCR 1M составляет 83,5 (поиск информации в памяти по контексту в 1M токенов), а CorpusQA 1M достигает 62,0 — при этом модель сохраняет связное рассуждение на всём окне контекста. Для агентов, которым нужно обработать целую кодовую базу, логи за целый день или документ объёмом с книгу за один вызов, эта архитектура делает такую задачу выполнимой без специализированной инфраструктуры.
#1 в LiveCodeBench и Codeforces — кодирующая модель, которая действительно конкурирует
DeepSeek-V4-Pro набирает 93,5 на LiveCodeBench (Pass@1) и 3206 в рейтинге Codeforces — оба показателя являются высшими опубликованными баллами в таблице сравнения, опережая Claude Opus 4.6 Max (88,8 / нет рейтинга), Gemini 3.1 Pro High (91,7 / 3052) и GPT-5.4 xHigh (нет балла LCB / 3168). На бенчмарке SWE-Verified (решение реальных задач из GitHub) она набирает 80,6, что наравне с Claude Opus 4.6 Max (80,8) и Gemini 3.1 Pro (80,6). Для команд, создающих кодирующие агенты, где важнее «может ли модель реально исправить баг», чем теоретические баллы MMLU, V4-Pro является открытым вариантом, который напрямую конкурирует с закрытыми frontier API.
Три режима рассуждений — подстраивайте вычислительные ресурсы под задачу
DeepSeek-V4-Pro предоставляет три режима вывода через один и тот же конечный точ API:
- Без размышлений: Без цепочки рассуждений. Быстрый, с низкой задержкой — подходит для задач классификации, извлечения данных, генерации структурированных выводов, где накладные расходы на рассуждения неоправданны.
- С размышлениями: Стандартное рассуждение по цепочке (CoT). Режим по умолчанию для задач кодирования, математики и многошаговых задач.
- Макс (V4-Pro Max): Расширенный бюджет рассуждений. Используйте, когда точность важнее скорости — сложные доказательства, сложные задачи конкурентного программирования, глубокие сессии отладки.
Все три режима доступны через ID модели deepseek/deepseek-v4-pro, поддерживаемый Novita AI. Переключение между ними выполняется инструкцией на уровне промпта, а не через отдельный конечный точ — это значит, что вы можете реализовать адаптивный выбор режима в вашем приложении без изменения конфигурации API.
Производительность в агентных задачах и работе с инструментами
Помимо кодирующих бенчмарков, V4-Pro показывает достойные результаты в агентных оценках. BrowseComp: 83,4 (против 83,7 у Claude Opus, 85,9 у Gemini — отстаёт от frontier всего на 2,5 балла). MCPAtlas Public: 73,6, второе место после Claude Opus 4.6 (73,8). Toolathlon: 51,8, третье место в общем зачёте. Это не результаты, где модель опережает всех остальных, но они подтверждают, что V4-Pro является полноценной универсальной агентной моделью, а не просто кодирующим специалистом, оптимизированным под бенчмарки. В сочетании с нативной поддержкой вызова функций это практичный выбор для агентов, которым нужно выполнять веб-поиск, вызывать инструменты и рассуждать в рамках одной сессии.
Производительность по бенчмаркам
В таблице ниже представлены бенчмарки из официального сравнения DeepSeek. «V4-Pro» относится к режиму DeepSeek-V4-Pro Max (расширенное рассуждение) — той же модели, которая доступна через ID API deepseek/deepseek-v4-pro на Novita.
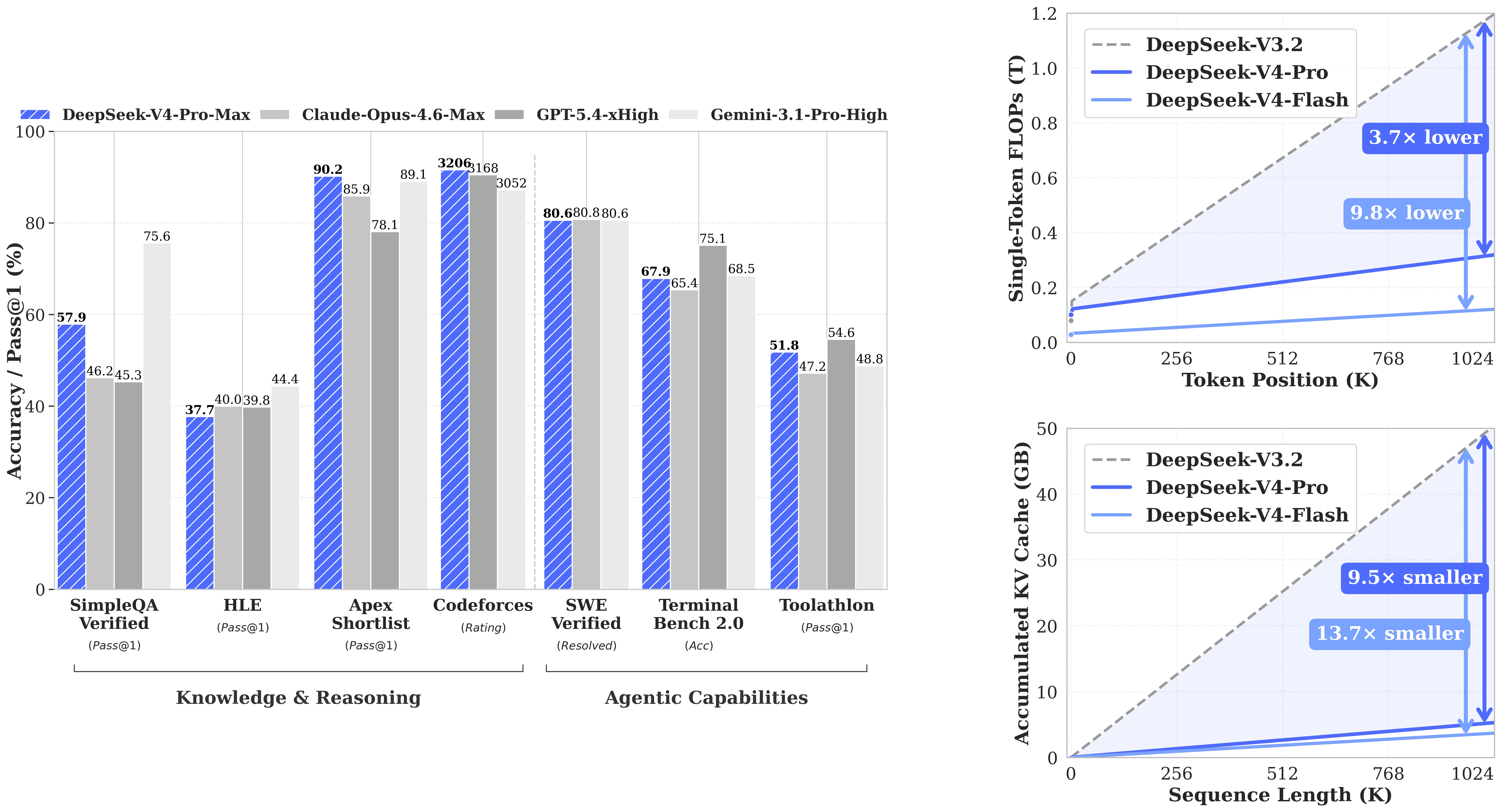
Производительность DeepSeek-V4-Pro по кодирующим, рассуждающим и агентным бенчмаркам. [Источник: DeepSeek HuggingFace]
| Бенчмарк | DeepSeek-V4-Pro | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93,5 ✓ | 88,8 | 91,7 | — |
| Рейтинг Codeforces | 3206 ✓ | — | 3052 | 3168 |
| SWE-Verified | 80,6 | 80,8 | 80,6 | — |
| SWE Pro | 55,4 | 57,3 | 54,2 | 57,7 |
| BrowseComp | 83,4 | 83,7 | 85,9 | 82,7 |
| MCPAtlas Public | 73,6 | 73,8 | 69,2 | 67,2 |
| GPQA Diamond | 90,1 | 91,3 | 94,3 | 93,0 |
| HLE (Pass@1) | 37,7 | 40,0 | 44,4 | 39,8 |
| IMOAnswerBench | 89,8 | 75,3 | 81,0 | 91,4 |
| HMMT 2026 Feb | 95,2 | 96,2 | 94,7 | 97,7 |
| MRCR 1M (MMR) | 83,5 | 92,9 | 76,3 | — |
| CorpusQA 1M | 62,0 | 71,7 | 53,8 | — |
| Terminal Bench 2.0 | 67,9 | 65,4 | 68,5 | 75,1 |
✓ = высший опубликованный балл в этом сравнении. Последняя проверка: 2026-04-25. Баллы отражают режим «Макс» / расширенное рассуждение, где это применимо. Источник: карточка модели DeepSeek на HuggingFace.
Честный анализ: На бенчмарках знаний (GPQA Diamond, HLE) Gemini 3.1 Pro и GPT-5.4 явно опережают. Преимущество V4-Pro — в кодировании: баллы LiveCodeBench и Codeforces являются однозначно высшими, а также в поиске по длинному контексту среди других открытых моделей. В математических рассуждениях разрыв неоднородный: V4-Pro опережает GPT-5.4 на IMOAnswerBench (89,8 против 91,4, близко), но отстаёт на HMMT 2026 (95,2 против 97,7).
Как использовать DeepSeek-V4-Pro через Novita AI
Вариант 1: Плейграунд (без кода)
Тестируйте напрямую на novita.ai/models/model-detail/deepseek-deepseek-v4-pro. Для исследования не требуется API-ключ. Установите системный промпт для активации режима «С размышлениями» или «Без размышлений».
Вариант 2: API (Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# Standard (Think mode)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-pro",
messages=[
{"role": "user", "content": "Implement a Rust async runtime from scratch."}
],
)
print(response.choices[0].message.content)
Получите ваш API-ключ на novita.ai/settings. Тот же ID модели работает для всех трёх режимов рассуждений — передавайте инструкции по переключению режима в системном промпте или используйте документированный синтаксис переключения режимов от DeepSeek.
Вариант 3: Сторонние инструменты
Поскольку Novita AI совместима с OpenAI API, вы можете использовать deepseek/deepseek-v4-pro как ID модели в Cursor (кастомный провайдер OpenAI), конфигурациях, совместимых с Claude Code, LangChain, LlamaIndex или любом фреймворке на основе SDK OpenAI. Просто укажите base_url равным https://api.novita.ai/v3/openai.
curl https://api.novita.ai/v3/openai/chat/completions \\
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{"model":"deepseek/deepseek-v4-pro","messages":[{"role":"user","content":"Implement a Rust async runtime."}]}'
Сценарии использования
Полный анализ и рефакторинг кодовой базы: С контекстом в 1M токенов вы можете передать целый репозиторий среднего размера за один вызов. Попросите V4-Pro найти архитектурные проблемы, сгенерировать руководства по миграции или рефакторить паттерны сразу в 50+ файлах — без разбиения на части или ухищрений с поиском по контексту.
Конкурентное программирование и сложные алгоритмические задачи: Рейтинг Codeforces 3206 ставит V4-Pro в топовый ряд для решения алгоритмических задач. Используйте её для генерации решений задач конкурентного программирования, проверки доказательств сложности или стресс-тестирования крайних случаев в производственных алгоритмах.
Агенты для решения задач из GitHub: Балл SWE-Verified 80,6 ставит V4-Pro наравне с Claude Opus 4.6 в решении реальных багов. В сочетании с вызовом функций и длинным контекстом она может читать описания задач, просматривать историю кода и генерировать патчи, не теряя контекст в больших репозиториях.
Рассуждения по длинным документам: Юридические контракты, научные статьи, технические спецификации, аудиторские логи — контекст V4-Pro в 1M токенов означает, что вам не нужно принудительно суммировать или разбивать документ на части перед анализом. Баллы CorpusQA 1M (62,0) и MRCR 1M (83,5) подтверждают, что точность поиска сохраняется на полной длине контекста.
Математическое и научное обучение / генерация задач: Балл IMOAnswerBench 89,8 (опережает все закрытые модели кроме GPT-5.4 с 91,4) делает V4-Pro сильным выбором для генерации задач уровня математических олимпиад, проверки доказательств или создания инструментов для STEM-образования, где математические рассуждения являются узким местом.
Цены
| Модель | Ввод ($/M токенов) | Чтение из кэша ($/M токенов) | Вывод ($/M токенов) |
|---|---|---|---|
| DeepSeek-V4-Pro (Novita) | $1,74 | $0,145 | $3,48 |
| DeepSeek-V4-Flash (Novita) | $0,10 | — | $0,50 |
| Claude Opus 4.6 (Anthropic) | $15,00 | $1,50 | $75,00 |
| Gemini 3.1 Pro (Google) | $1,25 | $0,31 | $10,00 |
| GPT-5.4 (OpenAI) | $10,00 | $2,50 | $40,00 |
Последняя проверка: 2026-04-25. Цены Novita взяты с novita.ai/pricing. Цены конкурентов: Claude с anthropic.com (непроверенные), Gemini с ai.google.dev (непроверенные), GPT-5.4 с platform.openai.com (непроверенные).
Через Novita AI V4-Pro примерно в 8 раз дешевле Claude Opus 4.6 на входные токены и в 21 раз дешевле на выходные. По сравнению с Gemini 3.1 Pro цены на вход схожи, но вывод в 2,9 раза дешевле. Для кодирующих агентов с длинным контекстом и многошаговыми сессиями — где доминируют выходные токены — этот разрыв быстро накапливается.
Миграция с DeepSeek-V3 или DeepSeek-R1
Если вы сейчас используете DeepSeek-V3 или R1 на Novita, обновление до V4-Pro — это изменение ID модели в одной строке. API совместимо с OpenAI, тот же конечный точ, тот же формат запроса. Три режима рассуждений V4-Pro дают вам гибкость воспроизвести как V3 (режим «Без размышлений»), так и глубокие рассуждения в стиле R1 (режим «Макс») на одной модели — без поддержки отдельных развёртываний. Если вы мигрируете с модели другого провайдера (GPT-4o, Claude 3.5 и т.д.), направьте ваш существующий клиент OpenAI SDK на base_url="https://api.novita.ai/v3/openai" и поменяйте ID модели.
Заключение
Ключевой вывод: DeepSeek-V4-Pro — сильнейшая доступная открытая модель для задач кодирования с однозначными баллами #1 на LiveCodeBench и Codeforces, а также единственная модель в своём классе, которая поддерживает настоящее окно контекста в 1M токенов. Она не лидирует во всех бенчмарках — Gemini 3.1 Pro опережает в поиске знаний, а Claude Opus лидирует в поиске по длинному контексту — но для команд, создающих кодирующие агенты, исправляющих задачи из GitHub в масштабе или обрабатывающих большие объёмы документов, V4-Pro предоставляет производительность уровня frontier при доле стоимости API закрытых моделей. Уже доступна при поддержке Novita AI — 200+ API моделей и инфраструктура, совместимая с OpenAI.
Попробовать DeepSeek-V4-Pro через Novita AI →
Часто задаваемые вопросы
Что такое DeepSeek-V4-Pro?
DeepSeek-V4-Pro — это языковая модель смеси экспертов (MoE) от DeepSeek AI с 1,6 трлн параметров, выпущенная в апреле 2026 года. Она активирует 49B параметров на один проход вперёд, поддерживает контекст длиной 1 048 576 токенов и в настоящее время лидирует среди всех публично оценённых моделей на LiveCodeBench (93,5) и в рейтинге Codeforces (3206). Доступна под лицензией MIT и через Novita AI.
Как получить доступ к DeepSeek-V4-Pro через API?
Используйте ID модели deepseek/deepseek-v4-pro с base_url="https://api.novita.ai/v3/openai" и вашим API-ключом Novita с страницы novita.ai/settings. Конечный точка совместима с SDK OpenAI — не требуется кастомный SDK.
Как DeepSeek-V4-Pro сравнивается с Claude Opus 4.6 и Gemini 3.1 Pro?
V4-Pro лидирует в кодировании: LiveCodeBench 93,5 (против 88,8 у Opus 4.6, 91,7 у Gemini) и Codeforces 3206 (против 3052 у Gemini). На бенчмарках знаний вроде GPQA Diamond и HLE лидирует Gemini 3.1 Pro. В поиске по длинному контексту (MRCR 1M) лидирует Claude Opus. V4-Pro — лучший открытый выбор для нагрузок с упором на кодирование и агентные задачи — закрытые модели сохраняют преимущество в сыстом фактологическом поиске.
Каково окно контекста DeepSeek-V4-Pro?
1 048 576 токенов (1M). Модель специально спроектирована для эффективной работы с длинным контекстом с использованием гибридного внимания (CSA + HCA). Баллы MRCR 1M составляют 83,5, а CorpusQA 1M достигает 62,0, что подтверждает пригодную точность поиска на полной длине контекста.
Сколько стоит DeepSeek-V4-Pro при поддержке Novita AI?
$1,74 за миллион входных токенов, $3,48 за миллион выходных токенов, $0,145 за миллион токенов чтения из кэша. Это делает её примерно в 8 раз дешевле Claude Opus 4.6 на входные токены и в 21 раз дешевле на выходные. Последняя проверка: 2026-04-25.



