

DeepSeek-V4-Pro : 1M de contexte, n°1 au LiveCodeBench, une frontière open-source
Vous évaluez des modèles open-source pour un agent de codage en production. Vous avez besoin de quelque chose qui gère de grandes bases de code — des dépôts entiers, pas seulement des fichiers isolés — et qui résolve réellement les issues GitHub sans halluciner d’appels d’outils. Tous les modèles que vous essayez soit s’effondrent au-delà de 128K tokens, soit sont à la traîne par rapport à GPT-4o sur les benchmarks qui comptent pour les tâches d’ingénierie réelles.
DeepSeek-V4-Pro change la donne. C’est un modèle MoE (Mixture of Experts) de 1,6 billion de paramètres avec une véritable fenêtre de contexte d’1 million de tokens, le meilleur score publié sur LiveCodeBench (93,5 Pass@1) et un rating Codeforces de 3206 — soit la première place parmi tous les modèles évalués, y compris les API fermées les plus avancées. En bref : c’est le meilleur modèle open-source disponible aujourd’hui pour le codage compétitif et les tâches agentiques avec grand contexte, publié sous licence MIT. Dès aujourd’hui, il est disponible via Novita AI.
Essayez DeepSeek-V4-Pro maintenant →
Qu’est-ce que DeepSeek-V4-Pro ?
DeepSeek-V4-Pro est le modèle phare de la série V4 de DeepSeek, publié le 24 avril 2026. Il se situe au-dessus du modèle léger DeepSeek-V4-Flash (284B total / 13B actifs) et est positionné comme un aperçu des capacités frontières actuelles de DeepSeek — ce qu’ils décrivent comme le « meilleur modèle open-source disponible aujourd’hui » pour la connaissance et le codage. Le modèle est entraîné sur plus de 32 billions de tokens et affiné via un pipeline en deux étapes : SFT (Supervised Fine-Tuning) par domaine expert + apprentissage par renforcement GRPO, suivi d’une distillation sur politique. Les détails techniques complets se trouvent dans le document de DeepSeek DeepSeek-V4 : Towards Highly Efficient Million-Token Context Intelligence.
Principales spécifications en un coup d’œil :
- Architecture : Mixture of Experts (MoE) avec attention hybride — Compressed Sparse Attention (CSA) + Heavily Compressed Attention (HCA)
- Paramètres : 1,6T total / 49B activés par passage avant
- Fenêtre de contexte : 1 048 576 tokens (1M)
- Précision : FP4 (experts MoE) + FP8 mixte
- Modes de raisonnement : Non-think (rapide), Think (CoT standard), Max (budget de raisonnement maximal)
- Capacités : Appel de fonctions, sorties structurées, raisonnement, recherche dans contexte 1M
- Licence : MIT
Fonctionnalités clés
Attention hybride pour un traitement efficace d’1 million de tokens
La plupart des modèles qui revendiquent un « long contexte » soit tronquent silencieusement, soit se dégradent fortement au-delà de 128K tokens. L’architecture d’attention hybride de DeepSeek-V4-Pro — combinant Compressed Sparse Attention (CSA) et Heavily Compressed Attention (HCA) avec des connexions hyper-connectées sous contrainte de variété (mHC) — est conçue dès le départ pour un traitement efficace d’un million de tokens. Concrètement : MRCR 1M obtient 83,5 (rappel mémoire sur 1M de contexte) et CorpusQA 1M atteint 62,0, tout en maintenant un raisonnement cohérent sur toute la fenêtre. Pour les agents qui doivent ingérer une base de code entière, une journée de logs ou un document de la taille d’un livre en un seul appel, c’est l’architecture qui rend cela viable sans infrastructure spécialisée.
n°1 sur LiveCodeBench et Codeforces — Le modèle de codage qui rivalise vraiment
DeepSeek-V4-Pro obtient 93,5 sur LiveCodeBench (Pass@1) et 3206 sur le rating Codeforces — les deux meilleurs scores publiés dans le tableau de comparaison, battant Claude Opus 4.6 Max (88,8 / pas de rating), Gemini 3.1 Pro High (91,7 / 3052) et GPT-5.4 xHigh (pas de score LCB / 3168). Sur SWE-Verified (résolution d’issues GitHub réelles), il atteint 80,6, à égalité avec Claude Opus 4.6 Max (80,8) et Gemini 3.1 Pro (80,6). Pour les équipes qui construisent des agents de codage où « peut-il vraiment corriger le bug » importe plus que les scores MMLU théoriques, V4-Pro est l’option open-source qui rivalise directement avec les API fermées.
Trois modes de raisonnement — Adaptez le calcul à la tâche
DeepSeek-V4-Pro expose trois modes d’inférence via la même API :
- Non-think : Pas de chaîne de pensée. Rapide, faible latence — adapté pour la classification, l’extraction, les tâches de sortie structurée où le surcoût de raisonnement est inutile.
- Think : Raisonnement CoT standard. Le mode par défaut pour le codage, les mathématiques et les tâches multi-étapes.
- Max (V4-Pro Max) : Budget de raisonnement étendu. À utiliser quand la précision prime sur la vitesse — preuves complexes, problèmes de programmation compétitive difficiles, sessions de débogage approfondies.
Les trois modes sont accessibles via l’ID de modèle deepseek/deepseek-v4-pro soutenu par Novita AI. Passer de l’un à l’autre est une instruction au niveau du prompt, pas un point d’accès différent — ce qui signifie que vous pouvez implémenter une sélection adaptative des modes dans votre application sans modifier la configuration API.
Performances agentiques et utilisation d’outils
Au-delà des benchmarks de codage, V4-Pro tient ses promesses sur les évaluations agentiques. BrowseComp : 83,4 (contre 83,7 pour Claude Opus, 85,9 pour Gemini — à moins de 2,5 points de la frontière). MCPAtlas Public : 73,6, deuxième seulement derrière Claude Opus 4.6 (73,8). Toolathlon : 51,8, troisième au classement général. Ce ne sont pas des résultats qui « mènent tous les modèles », mais ils confirment que V4-Pro est un modèle agentique généraliste compétent, pas seulement un spécialiste du codage optimisé pour les benchmarks. Combiné avec la prise en charge native des appels de fonction, c’est un choix pratique pour les agents qui doivent naviguer, appeler des outils et raisonner en une seule session.
Performances sur les benchmarks
Le tableau ci-dessous couvre les benchmarks de la comparaison officielle de DeepSeek. « V4-Pro » fait référence au mode DeepSeek-V4-Pro Max (raisonnement étendu) — le même modèle accessible via l’ID d’API deepseek/deepseek-v4-pro sur Novita.
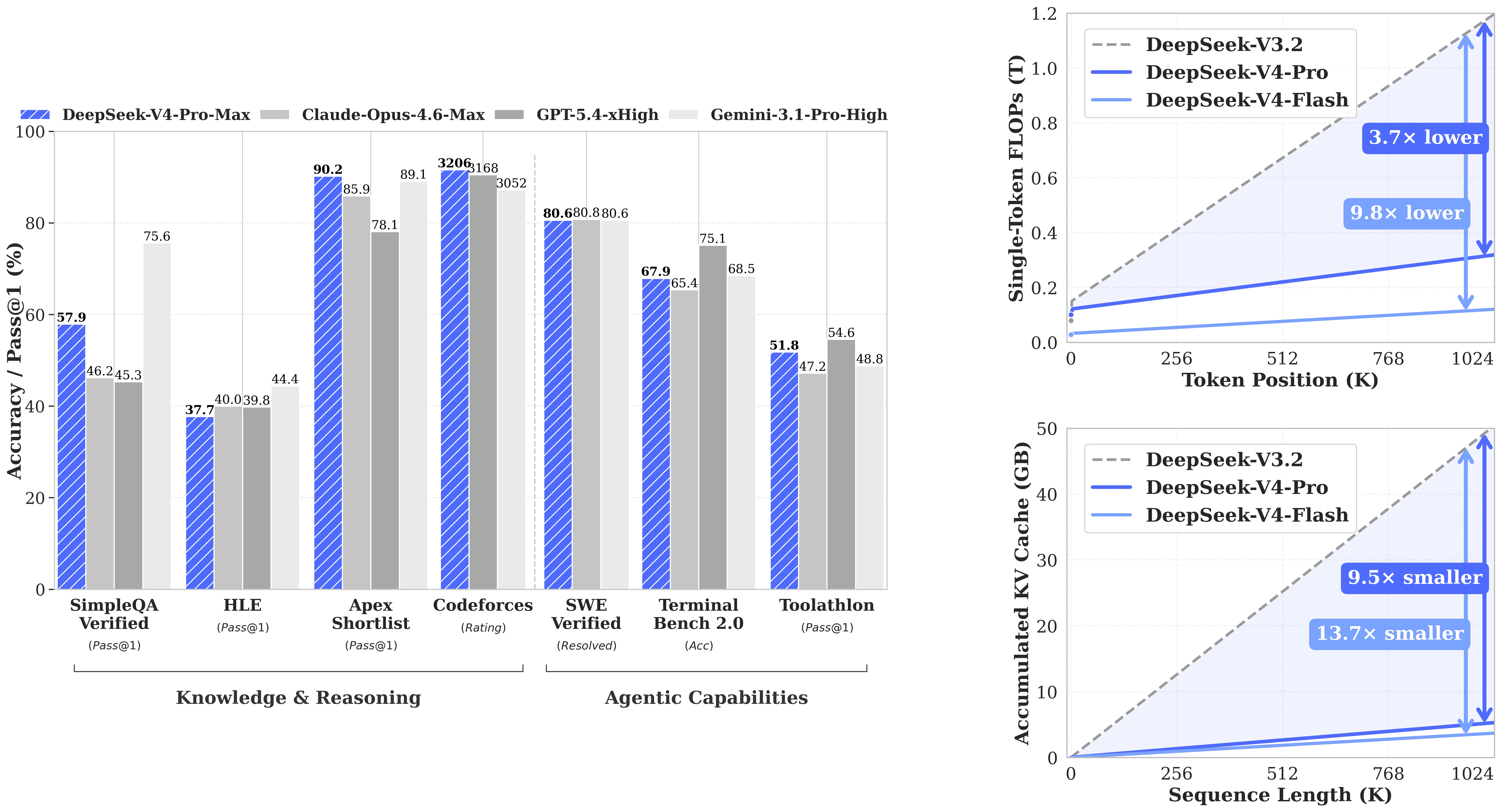
Performances de DeepSeek-V4-Pro sur les benchmarks de codage, raisonnement et agentiques. [Source : DeepSeek HuggingFace]
| Benchmark | DeepSeek-V4-Pro | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93,5 ✓ | 88,8 | 91,7 | — |
| Rating Codeforces | 3206 ✓ | — | 3052 | 3168 |
| SWE-Verified | 80,6 | 80,8 | 80,6 | — |
| SWE Pro | 55,4 | 57,3 | 54,2 | 57,7 |
| BrowseComp | 83,4 | 83,7 | 85,9 | 82,7 |
| MCPAtlas Public | 73,6 | 73,8 | 69,2 | 67,2 |
| GPQA Diamond | 90,1 | 91,3 | 94,3 | 93,0 |
| HLE (Pass@1) | 37,7 | 40,0 | 44,4 | 39,8 |
| IMOAnswerBench | 89,8 | 75,3 | 81,0 | 91,4 |
| HMMT 2026 Fév | 95,2 | 96,2 | 94,7 | 97,7 |
| MRCR 1M (MMR) | 83,5 | 92,9 | 76,3 | — |
| CorpusQA 1M | 62,0 | 71,7 | 53,8 | — |
| Terminal Bench 2.0 | 67,9 | 65,4 | 68,5 | 75,1 |
✓ = meilleur score publié dans cette comparaison. Dernière vérification : 25/04/2026. Les scores reflètent le mode « Max » / raisonnement étendu le cas échéant. Source : Fiche modèle DeepSeek HuggingFace.
Lecture honnête : Sur les benchmarks de connaissances (GPQA Diamond, HLE), Gemini 3.1 Pro et GPT-5.4 sont clairement en tête. L’avantage de V4-Pro réside dans le codage — LiveCodeBench et Codeforces sont des scores n°1 sans équivoque — et dans la recherche à long contexte par rapport aux autres modèles open-source. Pour le raisonnement mathématique, l’écart est mitigé : V4-Pro bat GPT-5.4 sur IMOAnswerBench (89,8 contre 91,4, serré) mais est en retard sur HMMT 2026 (95,2 contre 97,7).
Comment utiliser DeepSeek-V4-Pro avec Novita AI
Option 1 : Playground (sans code)
Testez directement sur novita.ai/models/model-detail/deepseek-deepseek-v4-pro. Aucune clé API requise pour explorer. Définissez le prompt système pour activer le mode Think ou Non-think.
Option 2 : API (Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="VOTRE_CLE_API_NOVITA",
)
# Mode standard (Think)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-pro",
messages=[
{"role": "user", "content": "Implémente un runtime asynchrone Rust à partir de zéro."}
],
)
print(response.choices[0].message.content)
Obtenez votre clé API sur novita.ai/settings. Le même ID de modèle fonctionne pour les trois modes de raisonnement — passez les instructions de mode dans le prompt système ou utilisez la syntaxe de changement de mode documentée par DeepSeek.
Option 3 : Outils tiers
Comme Novita AI est compatible avec l’API OpenAI, vous pouvez utiliser deepseek/deepseek-v4-pro comme ID de modèle dans Cursor (fournisseur OpenAI personnalisé), les configurations compatibles Claude Code, LangChain, LlamaIndex, ou tout framework basé sur le SDK OpenAI. Il suffit de pointer base_url vers https://api.novita.ai/v3/openai.
curl https://api.novita.ai/v3/openai/chat/completions \
-H "Authorization: Bearer VOTRE_CLE_API_NOVITA" \
-H "Content-Type: application/json" \
-d '{"model":"deepseek/deepseek-v4-pro","messages":[{"role":"user","content":"Implémente un runtime asynchrone Rust."}]}'
Cas d’usage
Analyse et refactoring de bases de code complètes : Avec un contexte d’1M de tokens, vous pouvez passer un dépôt de taille moyenne en un seul appel. Demandez à V4-Pro de trouver des problèmes architecturaux, de générer des guides de migration ou de refactoriser des motifs sur plus de 50 fichiers simultanément — sans découpage ni astuces de récupération.
Programmation compétitive et problèmes algorithmiques complexes : Un rating Codeforces de 3206 place V4-Pro dans le haut du panier pour la résolution de problèmes algorithmiques. Utilisez-le pour générer des solutions à des défis de programmation compétitive, vérifier des preuves de complexité ou tester les cas limites dans des algorithmes de production.
Agents de résolution d’issues GitHub : SWE-Verified 80,6 place V4-Pro à égalité avec Claude Opus 4.6 pour la correction de bugs réels. Combiné avec les appels de fonctions et le long contexte, il peut lire les descriptions d’issues, parcourir l’historique du code et générer des correctifs sans perdre le fil dans les grands dépôts.
Raisonnement sur des documents longs : Contrats juridiques, articles de recherche, spécifications techniques, journaux d’audit — le contexte 1M de V4-Pro signifie que vous n’êtes pas obligé de résumer ou de découper avant l’analyse. CorpusQA 1M (62,0) et MRCR 1M (83,5) confirment que la précision de recherche se maintient à pleine longueur de contexte.
Tutorat en mathématiques et sciences / génération de problèmes : IMOAnswerBench 89,8 (bat tous les modèles fermés sauf GPT-5.4 avec 91,4) fait de V4-Pro un excellent choix pour générer des problèmes de mathématiques de niveau compétition, vérifier des preuves ou construire des outils pédagogiques en STEM où le raisonnement mathématique est le goulot d’étranglement.
Tarifs
| Modèle | Entrée ($/M tokens) | Lecture cache ($/M tokens) | Sortie ($/M tokens) |
|---|---|---|---|
| DeepSeek-V4-Pro (Novita) | 1,74 $ | 0,145 $ | 3,48 $ |
| DeepSeek-V4-Flash (Novita) | 0,10 $ | — | 0,50 $ |
| Claude Opus 4.6 (Anthropic) | 15,00 $ | 1,50 $ | 75,00 $ |
| Gemini 3.1 Pro (Google) | 1,25 $ | 0,31 $ | 10,00 $ |
| GPT-5.4 (OpenAI) | 10,00 $ | 2,50 $ | 40,00 $ |
Dernière vérification : 25/04/2026. Tarifs Novita provenant de novita.ai/pricing. Tarifs concurrents : Claude de anthropic.com (non vérifié), Gemini de ai.google.dev (non vérifié), GPT-5.4 de platform.openai.com (non vérifié).
Via Novita AI, V4-Pro est environ 8× moins cher que Claude Opus 4.6 pour les tokens d’entrée, et 21× moins cher pour la sortie. Comparé à Gemini 3.1 Pro, le prix d’entrée est similaire mais la sortie est 2,9× moins chère. Pour les agents de codage avec long contexte et sessions multi-tours — où les tokens de sortie dominent les coûts — l’écart se creuse rapidement.
Migration depuis DeepSeek-V3 ou DeepSeek-R1
Si vous utilisez actuellement DeepSeek-V3 ou R1 sur Novita, passer à V4-Pro est un changement d’ID de modèle en une ligne. L’API est compatible OpenAI, même point d’accès, même format de requête. Les trois modes de raisonnement de V4-Pro vous offrent la flexibilité de reproduire à la fois V3 (mode non-think) et le raisonnement profond de style R1 (mode Max) à partir d’un seul modèle — sans maintenir des déploiements séparés. Si vous migrez depuis un modèle d’un autre fournisseur (GPT-4o, Claude 3.5, etc.), pointez votre client SDK OpenAI existant vers base_url="https://api.novita.ai/v3/openai" et changez l’ID du modèle.
Conclusion
En résumé : DeepSeek-V4-Pro est le modèle open-source le plus puissant disponible pour les tâches de codage, avec des scores n°1 incontestés sur LiveCodeBench et Codeforces, et c’est le seul modèle de sa catégorie qui gère une véritable fenêtre de contexte d’1 million de tokens. Il ne domine pas tous les benchmarks — Gemini 3.1 Pro conserve l’avantage sur le rappel de connaissances, et Claude Opus mène sur la recherche à long contexte — mais pour les équipes construisant des agents de codage, corrigeant des issues GitHub à grande échelle ou traitant des documents massifs, V4-Pro offre des performances de classe frontière à une fraction du coût des API fermées. Maintenant disponible avec Novita AI — plus de 200 API de modèles et une infrastructure compatible OpenAI.
Essayez DeepSeek-V4-Pro via Novita AI →
FAQ
Qu’est-ce que DeepSeek-V4-Pro ?
DeepSeek-V4-Pro est un modèle de langage Mixture of Experts de 1,6 billion de paramètres de DeepSeek AI, publié en avril 2026. Il active 49B paramètres par passage avant, prend en charge 1 048 576 tokens de contexte et mène actuellement tous les modèles évalués publiquement sur LiveCodeBench (93,5) et le rating Codeforces (3206). Il est disponible sous licence MIT et via Novita AI.
Comment accéder à DeepSeek-V4-Pro via l’API ?
Utilisez l’ID de modèle deepseek/deepseek-v4-pro avec base_url="https://api.novita.ai/v3/openai" et votre clé API Novita depuis novita.ai/settings. Le point d’accès est compatible avec le SDK OpenAI — aucun SDK personnalisé requis.
Comment DeepSeek-V4-Pro se compare-t-il à Claude Opus 4.6 et Gemini 3.1 Pro ?
V4-Pro mène sur le codage : LiveCodeBench 93,5 (contre Opus 4.6 88,8, Gemini 91,7) et Codeforces 3206 (contre Gemini 3052). Sur les benchmarks de connaissances comme GPQA Diamond et HLE, Gemini 3.1 Pro mène. Sur la recherche à long contexte (MRCR 1M), Claude Opus mène. V4-Pro est le meilleur choix open-source pour les charges de travail de codage et agentiques — les modèles fermés conservent des avantages dans le rappel factuel brut.
Quelle est la fenêtre de contexte de DeepSeek-V4-Pro ?
1 048 576 tokens (1M). Le modèle est spécifiquement architecturé pour l’efficacité en long contexte grâce à l’attention hybride (CSA + HCA). MRCR 1M atteint 83,5 et CorpusQA 1M obtient 62,0, confirmant une précision de recherche utilisable à pleine longueur de contexte.
Combien coûte DeepSeek-V4-Pro avec Novita AI ?
1,74 $/M tokens d’entrée, 3,48 $/M tokens de sortie, 0,145 $/M tokens de lecture cache. Cela le rend environ 8× moins cher que Claude Opus 4.6 pour l’entrée et 21× moins cher pour la sortie. Dernière vérification : 25/04/2026.



